Автор: Денис Аветисян
Исследователи представили ViDoRe V3 — комплексную платформу для оценки систем, объединяющих поиск информации и генерацию текста на основе визуальных документов.

ViDoRe V3 — это новый масштабный бенчмарк для всесторонней оценки систем Retrieval-Augmented Generation (RAG) в реальных сценариях, связанных с визуальными документами и разнообразными типами запросов.
Несмотря на прогресс в области генеративных моделей, оценка их способности эффективно работать с комплексными, визуально насыщенными документами остается сложной задачей. В данной работе, ‘ViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios’, представлен новый многоязычный бенчмарк для всесторонней оценки систем генерации на основе извлечения (RAG) в реальных сценариях. Результаты масштабного анализа показывают, что визуальные методы извлечения превосходят текстовые, а поздние механизмы взаимодействия и текстовое переранжирование значительно повышают качество генерируемых ответов. Какие дальнейшие шаги необходимы для преодоления текущих ограничений моделей в понимании нетекстовых элементов и обеспечении точной локализации визуальной информации?
Преодолевая Ограничения: Необходимость Визуально Богатого RAG
Традиционные системы RAG (Retrieval-Augmented Generation) часто демонстрируют ограниченную эффективность при работе со сложными визуальными документами, что существенно снижает их применимость в реальных условиях. Проблема заключается в том, что эти системы, как правило, оптимизированы для обработки текста, и испытывают трудности с интерпретацией информации, представленной в виде диаграмм, таблиц, изображений и других визуальных элементов, разбросанных по страницам. В результате, способность извлекать релевантные сведения и генерировать осмысленные ответы на вопросы, требующие понимания визуального контекста, значительно ухудшается. Это особенно критично в таких областях, как техническая документация, научные отчеты и финансовые материалы, где визуальная информация играет ключевую роль в передаче сложных концепций и данных.
Существующие эталоны оценки систем визуального понимания документов (VDU) традиционно концентрируются на анализе отдельных страниц, что существенно ограничивает их применимость к реальным сценариям, где информация распределена по многостраничным, визуально насыщенным материалам. Такой подход не позволяет адекватно оценить способность систем RAG (Retrieval-Augmented Generation) эффективно извлекать и синтезировать знания из сложных документов, содержащих таблицы, диаграммы, изображения и текстовые блоки, расположенные на нескольких страницах. В результате, оценка ограничивается лишь поверхностным пониманием, не отражающим способность системы к полноценному анализу и интеграции информации в контексте всего документа.
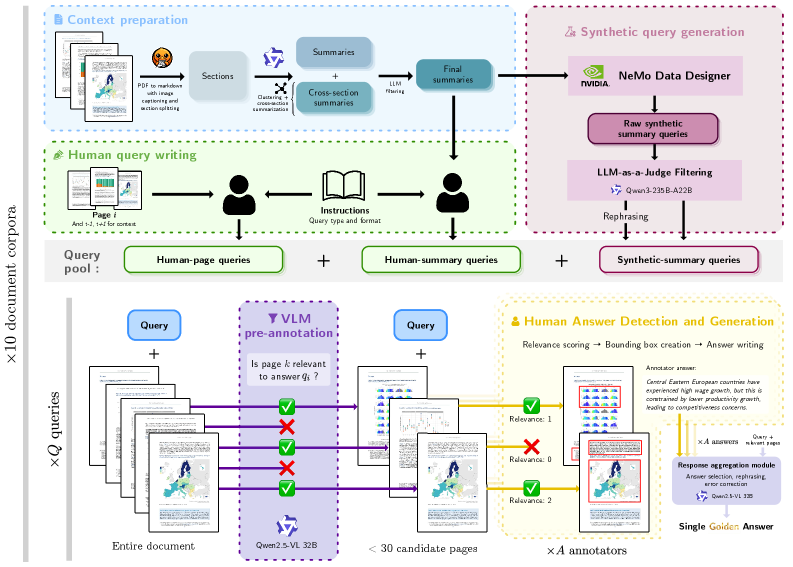
Для всесторонней оценки систем извлечения и генерации ответов (RAG) при работе со сложными визуальными документами необходим надежный эталонный набор данных. В связи с этим был разработан ViDoRe V3 — масштабный корпус, состоящий из 26,000 страниц и 3,099 вопросов, призванный подтолкнуть границы информационного поиска и генерации. Этот набор данных позволяет оценить способность RAG-систем не просто извлекать текст, но и понимать взаимосвязи между различными визуальными элементами и текстом на протяжении нескольких страниц документа, что критически важно для работы с реальными материалами, такими как научные отчеты, финансовые документы и технические руководства. ViDoRe V3 предоставляет исследователям возможность создавать и тестировать более интеллектуальные и эффективные системы, способные справляться со сложностью визуально насыщенных документов.

ViDoRe V3: Эталон для Сложных RAG-Систем
ViDoRe V3 представляет собой комплексный набор данных для оценки систем извлечения и генерации ответов (RAG) на основе визуально насыщенных документов. В отличие от традиционных бенчмарков, ViDoRe V3 включает в себя многостраничные документы, содержащие разнообразные визуальные элементы, такие как диаграммы, таблицы и изображения. Это требует от оцениваемых систем способности не только извлекать информацию из текста, но и интерпретировать визуальный контент для формирования точных и полных ответов на запросы пользователей. Набор данных предназначен для всесторонней оценки возможностей RAG систем в обработке сложных документов, которые часто встречаются в реальных сценариях, например, в технических руководствах, научных статьях и финансовых отчетах.
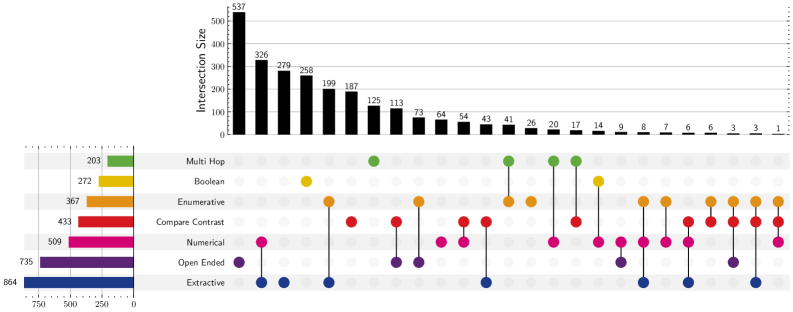
В основе ViDoRe V3 лежит детализированная таксономия запросов, классифицирующая их по степени сложности. Эта таксономия включает в себя запросы, требующие простого извлечения информации (extractive), многошагового рассуждения (multi-hop), когда ответ формируется на основе нескольких источников, и запросы, требующие открытого рассуждения (open-ended reasoning), подразумевающие генерацию развернутого ответа, а не простого извлечения фактов. Такая классификация позволяет всесторонне оценить возможности систем RAG в решении различных типов задач и выявить их слабые места.
Конструкция ViDoRe V3 специально разработана таким образом, чтобы требовать от систем использования как текстового, так и визуального контекста для точной генерации ответов, что выходит за рамки простого текстового поиска. Это достигается за счет включения вопросов, требующих анализа визуальных элементов документов для выявления необходимой информации. Надежность аннотаций, используемых в наборе данных, подтверждается высоким значением межэкспертного согласия (Gwet’s AC2), равным 0.760, что указывает на стабильность и объективность данных для оценки систем извлечения информации.
Оценка Производительности RAG: Метрики и Валидация Экспертов
Для оценки точности визуального обоснования в ViDoRe V3 используются стандартные метрики информационного поиска, такие как NDCG@10, которые измеряют ранжирование релевантных результатов. Помимо этого, применяется локализация ограничивающими рамками (bounding box localization) для определения точности позиционирования визуальных элементов, соответствующих ответу на запрос. NDCG@10 оценивает качество ранжирования первых 10 результатов, а локализация ограничивающими рамками позволяет количественно оценить, насколько точно система определяет местоположение релевантных объектов на изображении.
Оценка качества генерируемых ответов, особенно на сложные запросы, требующие рассуждений и синтеза информации, критически важна и требует привлечения экспертов-аннотаторов. Для визуального обоснования (visual grounding) продемонстрирован уровень согласованности между аннотаторами, равный 0.602 по метрике F1. Этот показатель подтверждает надежность и воспроизводимость оценок, полученных в ходе анализа, и позволяет минимизировать влияние субъективных факторов при определении эффективности систем извлечения информации и генерации ответов.
Согласованность между аннотаторами (Inter-Annotator Agreement) является критически важным фактором для обеспечения достоверности и надежности оценок, полученных в результате ручной экспертизы. Низкая согласованность указывает на субъективность оценок и может приводить к искажению результатов. Для количественной оценки согласованности используются различные метрики, такие как коэффициент Каппа Коэна или F1-мера. Высокие значения этих метрик подтверждают, что оценки, данные разными аннотаторами, соответствуют друг другу, что позволяет получить более объективные и воспроизводимые результаты оценки производительности системы, например, при оценке качества визуального обоснования ответов.
Влияние на Будущее: Кросс-языковая Эффективность RAG
Оценка кросс-языковых систем извлечения информации с последующим генерированием ответа (RAG) является ключевым аспектом современной обработки естественного языка. В условиях растущей глобализации и увеличения объемов многоязычных данных, способность эффективно извлекать и понимать информацию из различных источников на разных языках становится критически важной. Такие системы позволяют пользователям получать ответы на вопросы, используя знания, содержащиеся в документах на языках, отличных от языка запроса. Это значительно расширяет доступ к информации и способствует более полному и точному пониманию сложных тем, преодолевая языковые барьеры и открывая возможности для анализа данных в глобальном масштабе.
Для эффективного кросс-языкового поиска информации ключевую роль играют надежные модели эмбеддингов. В рамках текущих исследований активно применяются модели, такие как ColEmbed-3B-v2, которые преобразуют текст в векторные представления, позволяющие находить релевантные документы вне зависимости от языка запроса и содержания документа. Эти модели демонстрируют способность эффективно улавливать семантическое сходство между текстами на разных языках, что критически важно для систем, работающих с многоязычными данными. Качество этих эмбеддингов напрямую влияет на точность и скорость извлечения информации, делая разработку и оптимизацию таких моделей приоритетной задачей в области обработки естественного языка.
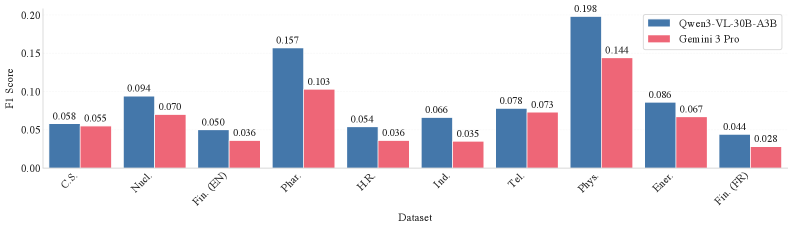
Оценочная платформа ViDoRe V3 продемонстрировала свою гибкость, будучи расширена для анализа эффективности моделей, объединяющих зрение и язык, таких как Qwen3-VL-30B-A3B, в контексте кросс-языковой обработки визуальной информации. Исследования показали, что применение текстового переранжировщика значительно повышает точность поиска и извлечения информации из визуальных данных, обеспечивая прирост в 13.2 процентных пункта по метрике NDCG@10. Это свидетельствует о перспективности использования подобных моделей для создания систем, способных понимать и обрабатывать визуальный контент на различных языках, открывая новые возможности для мультимодального анализа и кросс-языкового взаимодействия.

Перспективы Развития: Рассуждения и Обобщения в RAG
Перспективные исследования в области систем извлечения и генерации ответов (RAG) сосредоточены на повышении их способности к логическому мышлению. Современные RAG-системы часто испытывают трудности при обработке многоступенчатых запросов, требующих синтеза информации из различных источников, и задач, предполагающих сложные умозаключения. Разработка алгоритмов, позволяющих системам не просто находить релевантные фрагменты текста, но и анализировать их, выводить новые знания и обосновывать свои ответы, является ключевой задачей. Такой подход позволит RAG-системам решать более сложные проблемы, требующие критического мышления и способности к обобщению, приближая их к уровню человеческого интеллекта и открывая возможности для применения в областях, где требуется глубокое понимание и анализ информации.
Для оценки корректности и связности ответов, генерируемых системами извлечения и генерации ответов (RAG), предложен эффективный и масштабируемый подход, использующий большие языковые модели (LLM), такие как GPT-5, в качестве независимых экспертов. Исследования показали, что данный метод позволяет достичь точности в 65.74%, с небольшим стандартным отклонением — 0.94%, что свидетельствует о стабильности оценки. Высокое значение коэффициента Криппендорфа (α = 0.80) подтверждает надежность и согласованность оценок, предоставляемых LLM, что делает этот подход перспективным инструментом для автоматической оценки качества RAG-систем и ускорения их дальнейшего развития.
Развитие систем извлечения и генерации ответов (RAG) напрямую зависит от расширения возможностей тестовых наборов данных, таких как ViDoRe V3. Внедрение более сложных типов запросов, требующих многоступенчатого анализа и синтеза информации, а также использование разнообразных корпусов документов, представляющих различные предметные области и стили изложения, является ключевым фактором для стимулирования инноваций. Такой подход позволяет более адекватно оценить производительность RAG-систем в реальных условиях и выявить слабые места, требующие доработки. Увеличение сложности и разнообразия тестовых данных не только способствует улучшению существующих моделей, но и открывает возможности для разработки принципиально новых архитектур и алгоритмов, способных к более глубокому пониманию и обобщению информации, что в конечном итоге ускорит появление RAG-систем нового поколения.
Исследование, представленное в статье, акцентирует внимание на необходимости строгой оценки систем Retrieval-Augmented Generation (RAG) в сложных реальных сценариях, особенно при работе с визуальными документами. Подход, реализованный в ViDoRe V3, направлен на выявление истинной эффективности этих систем, а не просто на демонстрацию успешной работы на ограниченном наборе тестов. Как однажды заметил Джон Маккарти: «Всякий интеллект должен уметь делать то, что не может быть запрограммировано». Эта фраза подчеркивает, что способность системы адаптироваться к новым, непредсказуемым ситуациям, как это требуется при анализе визуальных документов и разнообразных запросов, является ключевым показателем ее реального интеллекта и надежности. ViDoRe V3, предлагая комплексную оценку, способствует развитию систем, способных к такому адаптивному поведению.
Что Дальше?
Представленный бенчмарк ViDoRe V3, несомненно, поднимает важный вопрос: достаточно ли мы продвинулись в понимании того, что значит “понимать” визуальный документ? Создание сложного набора данных — лишь первый шаг. Критически важным остается вопрос о воспроизводимости результатов. Если система демонстрирует успешное извлечение информации на ViDoRe V3, но терпит неудачу на незначительно модифицированном наборе данных, то ценность этого успеха весьма сомнительна. Алгоритм должен быть устойчив к малейшим вариациям, иначе это иллюзия, а не истинное понимание.
Дальнейшие исследования должны быть направлены не только на повышение точности, но и на разработку метрик, которые действительно отражают способность системы к обобщению. Простые показатели, такие как F1-score, часто оказываются недостаточными для оценки сложности RAG-систем, работающих с визуальной информацией. Необходимо сосредоточиться на разработке метрик, учитывающих контекстуальную значимость извлеченных данных и способность системы к логическому выводу.
В конечном счете, стремление к созданию «умных» систем должно основываться на математической строгости. Любая модель, которая не может быть доказана, остаётся лишь гипотезой. И только доказанные алгоритмы заслуживают доверия в решении сложных задач, связанных с извлечением информации из визуальных документов.
Оригинал статьи: https://arxiv.org/pdf/2601.08620.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Распознавание смыслов: новый подход к классификации документов
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовые сети связи: оптимизация расписания для спутниковой передачи
- Батарея под контролем: Искусственный интеллект на страже долговечности
- Интеллектуальные агенты: как воплотить опыт экспертов в искусственный интеллект
2026-01-14 21:16