Автор: Денис Аветисян
Новый метод позволяет значительно улучшить качество и скорость генерации текста на основе извлеченных данных, используя параллельную обработку контекста.
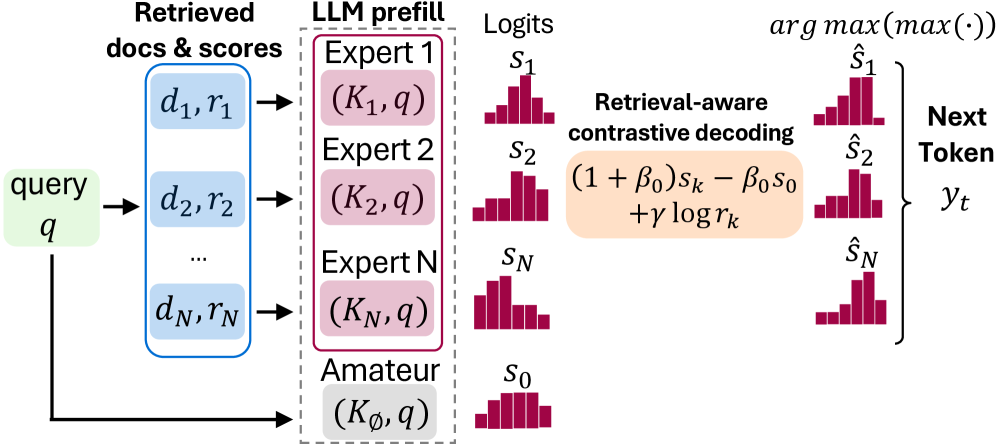
Предложена framework Parallel Context-of-Experts Decoding (PCED) для повышения эффективности retrieval-augmented generation за счет динамического взвешивания вкладов документов.
Повышение эффективности генеративных моделей с поиском релевантной информации сталкивается с дилеммой между скоростью обработки и способностью к сопоставлению данных из разных источников. В данной работе, посвященной ‘Parallel Context-of-Experts Decoding for Retrieval Augmented Generation’, предложен фреймворк PCED, позволяющий обрабатывать извлеченные документы параллельно и динамически взвешивать их вклад на этапе декодирования, избегая узких мест, связанных с объединением длинных запросов. Такой подход восстанавливает возможности кросс-документного рассуждения без построения общего механизма внимания между документами, обеспечивая прирост скорости и точности. Способно ли данное решение стать ключевым шагом к созданию более интеллектуальных и эффективных систем генерации текстов, использующих внешние знания?
Длинный контекст: неизбежные издержки прогресса
Традиционные архитектуры Transformer, несмотря на свою вычислительную мощь, сталкиваются с серьезными ограничениями при обработке длинных последовательностей данных. Суть проблемы заключается в так называемой «квадратичной сложности внимания» — с увеличением длины входного текста, объем вычислений, необходимых для установления взаимосвязей между элементами последовательности, растет пропорционально квадрату этой длины O(n^2). Это означает, что даже умеренное увеличение длины текста может привести к экспоненциальному росту потребляемых ресурсов и времени обработки, что делает невозможным эффективное использование Transformer для задач, требующих анализа обширных документов или длинных контекстов. Таким образом, необходимость разработки более эффективных механизмов внимания, способных справиться с этой проблемой, является ключевой задачей в области обработки естественного языка.
Ограничение в обработке больших объемов текста существенно сказывается на способности трансформеров эффективно извлекать смысл из обширных документов. Вместо целостного понимания, модели часто сталкиваются с трудностями при установлении долгосрочных зависимостей между различными частями текста, что приводит к фрагментарному анализу и снижению точности синтеза информации. В результате, даже при наличии достаточного количества данных, модели могут упускать важные нюансы и взаимосвязи, необходимые для полноценного понимания содержания, особенно в сложных текстах, требующих глубокого контекстуального анализа и обобщения.
Увеличение масштаба трансформаторных моделей неизбежно усугубляет существующие проблемы, связанные с обработкой длинных контекстов. По мере роста числа параметров и объемов данных, потребность в вычислительных ресурсах и памяти возрастает экспоненциально, делая традиционные архитектуры непрактичными. Это требует разработки инновационных решений, направленных на снижение вычислительной сложности, например, использование разреженного внимания или альтернативных механизмов агрегации информации. Исследования в этой области сосредоточены на создании более эффективных и масштабируемых моделей, способных обрабатывать огромные объемы текста без значительной потери производительности и точности, что является ключевым для решения сложных задач в области обработки естественного языка.
Способность эффективно обрабатывать длинные контексты становится ключевым требованием для широкого спектра приложений, где необходимы сложные умозаключения и интеграция знаний. Речь идет не просто о чтении большого объема текста, а о понимании взаимосвязей между отдаленными фрагментами информации, что позволяет, например, извлекать тонкие смыслы из юридических документов, проводить глубокий анализ научных статей или создавать правдоподобные и связные сюжеты в генеративных моделях. Без эффективной обработки длинных контекстов модели испытывают трудности с поддержанием когерентности, что приводит к неточным выводам и снижению общей производительности. Таким образом, разработка архитектур, способных масштабироваться для работы с обширными объемами данных, представляет собой важную задачу, определяющую будущее искусственного интеллекта и его способность решать действительно сложные проблемы.
Параллельный анализ: новый взгляд на декодирование
Параллельное декодирование с использованием контекста экспертов (Parallel Context-of-Experts Decoding) представляет собой фреймворк, не требующий обучения, для параллельной обработки извлеченных документов в процессе декодирования. В отличие от традиционных подходов, где агрегация документов осуществляется посредством механизма внимания, данная архитектура позволяет обрабатывать документы параллельно, что значительно снижает вычислительную нагрузку. Это достигается за счет разделения этапов извлечения и обработки документов, позволяя использовать предварительно извлеченные документы без дополнительных вычислений в процессе генерации текста. Отсутствие необходимости в обучении делает систему гибкой и легко адаптируемой к различным задачам и наборам данных.
Традиционные Transformer-модели испытывают вычислительные затруднения при агрегации информации из извлеченных документов, поскольку этот процесс осуществляется на этапе внимания. Параллельный подход Context-of-Experts переносит агрегацию документов непосредственно на этап декодирования, что позволяет избежать узких мест, связанных с вычислительной сложностью механизма внимания. Это достигается за счет обработки документов параллельно и независимого вычисления весов для каждого документа в процессе генерации токенов, что существенно снижает общую вычислительную нагрузку и позволяет ускорить процесс декодирования.
В основе подхода лежит использование KV Cache Encoding — предварительное вычисление и хранение векторных представлений документов в формате ключ-значение (Key-Value) кэша. Это позволяет избежать повторных вычислений векторных представлений документов на этапе декодирования, значительно ускоряя процесс. Вместо динамического вычисления векторов при каждом шаге декодирования, система обращается к предварительно вычисленному и сохраненному кэшу KV, обеспечивая быстрый доступ к информации о документах. Такая предварительная обработка позволяет параллельно обрабатывать множество документов, существенно снижая вычислительные затраты и задержки, особенно при работе с большим объемом данных.
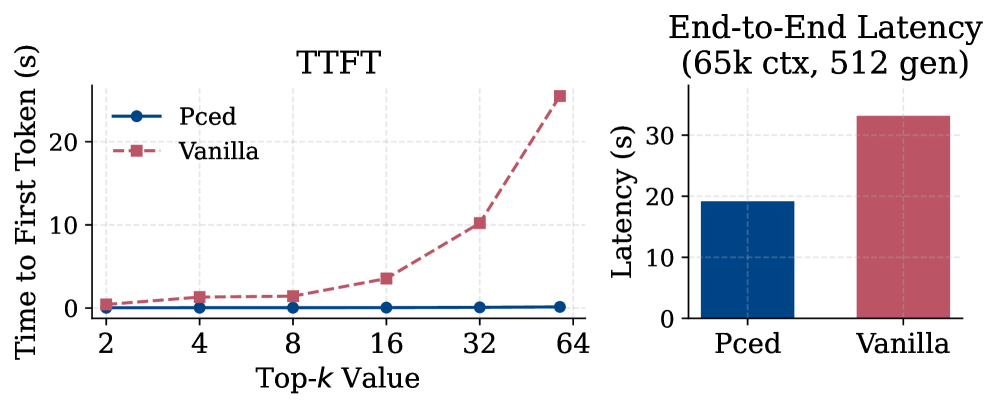
Ключевым нововведением подхода Parallel Context-of-Experts является разделение этапов кодирования документов и декодирования, что позволяет осуществлять их независимую обработку и значительно повысить скорость работы. Традиционно, кодирование документов и генерация ответа происходят последовательно, создавая вычислительные узкие места. Данный подход позволяет предварительно вычислить и сохранить представления документов (KV Cache Encoding), что обеспечивает быстрый доступ к информации во время декодирования. В результате, достигается более чем 180-кратное ускорение Time-to-First-Token (времени получения первого токена) по сравнению с существующими методами, что существенно повышает эффективность обработки больших объемов документов.

Оценка экспертных знаний: взвешивание релевантности
Эффективная агрегация вклада экспертов напрямую зависит от точной оценки релевантности документов, осуществляемой на основе двух ключевых показателей: Retrieval Score и Reranker Score. Retrieval Score отражает начальную степень соответствия документа запросу, полученную при извлечении информации. Reranker Score, в свою очередь, уточняет эту оценку, переоценивая документы на основе более сложных моделей и контекстуальной информации. Комбинирование этих двух показателей позволяет получить более полную и надежную картину релевантности, что критически важно для выбора наиболее подходящих экспертов для обработки каждого токена. Игнорирование любого из этих показателей может привести к снижению точности и эффективности всей системы.
Приоритет экспертов, используемый для выбора наиболее релевантных документов для каждого токена, формируется на основе среднего гармонического (Harmonic Mean) оценок Retrieval Score и Reranker Score. F_1 = 2 <i> (RetrievalScore </i> RerankerScore) / (RetrievalScore + RerankerScore) Такой подход позволяет более точно учитывать как изначальную релевантность документа, полученную при извлечении (Retrieval Score), так и последующую переоценку, выполненную переранжировщиком (Reranker Score). Использование среднего гармонического обеспечивает баланс между этими двумя показателями, акцентируя внимание на документах, которые демонстрируют высокие значения по обоим параметрам, и снижая приоритет документов с низкими значениями хотя бы по одному из них. Полученное значение служит весом для каждого эксперта при агрегации их вкладов.
Для дальнейшей оптимизации вклада каждого эксперта применяются различные методы агрегации. Метод «Mixture of Experts» (MoE) комбинирует прогнозы экспертов, используя взвешенную сумму, где веса определяются качеством вклада каждого эксперта. «Product of Experts» (PoE) перемножает вероятности, предсказанные каждым экспертом, что позволяет снизить влияние менее уверенных экспертов. Наконец, «Max Aggregation» выбирает наиболее вероятный прогноз из всех экспертов, обеспечивая акцент на наиболее сильных сигналах. Каждый из этих методов предоставляет различные способы комбинирования информации от разных источников, что позволяет повысить общую точность и надежность системы.
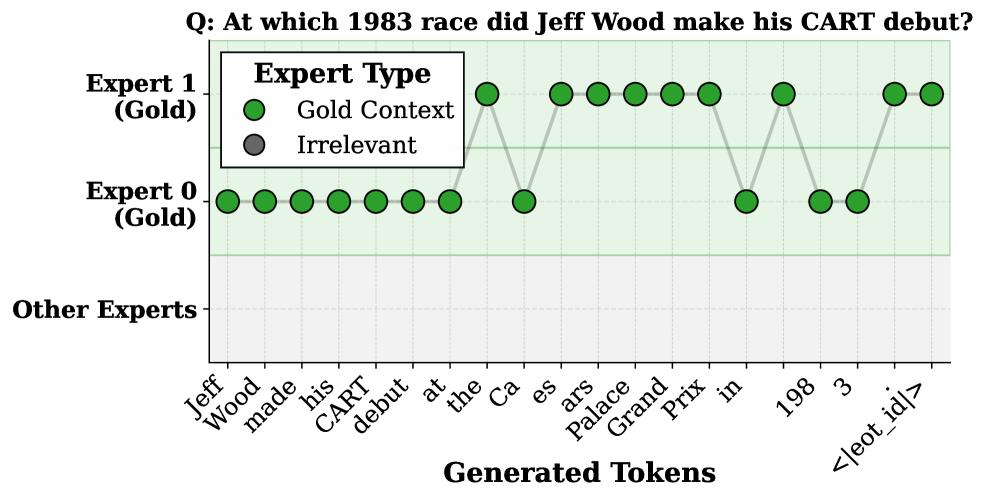
Переключение экспертов на уровне токенов представляет собой механизм динамической адаптации процесса декодирования. Вместо использования фиксированного набора документов-экспертов на протяжении всей генерации, система оценивает релевантность каждого документа для текущего генерируемого токена. Это позволяет динамически переключаться между различными источниками знаний, приоритизируя наиболее подходящие документы для каждого шага. В результате, модель может более эффективно использовать доступную информацию, повышая точность и связность генерируемого текста, поскольку фокус смещается в соответствии с контекстом каждого токена.
Эмпирические результаты: подтверждение эффективности
Исследования, проведенные на эталонных наборах данных LongBench и LoFT, наглядно демонстрируют эффективность параллельного декодирования с использованием Context-of-Experts. Данный подход позволяет значительно улучшить обработку длинных контекстов, обеспечивая прирост производительности до 70 баллов по сравнению с предыдущими параллельными методами. Полученные результаты подтверждают, что предложенная архитектура не только справляется с задачами, требующими анализа обширных документов, но и существенно превосходит существующие решения в этой области, открывая новые возможности для работы с текстами и данными, требующими глубокого понимания контекста.
Ключевым показателем эффективности разработанного подхода является время получения первого токена — метрика, демонстрирующая существенное ускорение обработки благодаря параллельным вычислениям. В ходе экспериментов зафиксировано значительное сокращение этого времени, что позволяет модели быстрее генерировать начальную часть ответа и, следовательно, повышает общую скорость работы. Это особенно важно при работе с длинными контекстами, где традиционные методы могут испытывать задержки. Уменьшение времени получения первого токена не только улучшает пользовательский опыт, но и открывает возможности для использования модели в приложениях, требующих оперативной генерации ответов, таких как чат-боты и системы автоматического перевода.
Представленный фреймворк демонстрирует не просто сопоставимые, но и превосходящие результаты в сравнении с традиционными методами обработки длинных контекстов. Экспериментальные данные свидетельствуют о значительном улучшении показателей эффективности, что делает его привлекательной альтернативой существующим решениям. Эта превосходная производительность открывает новые возможности для задач, требующих анализа больших объемов информации, и позволяет создавать более быстрые и точные системы искусственного интеллекта. Полученные результаты подтверждают перспективность данного подхода и его потенциал для широкого применения в различных областях, где обработка длинных последовательностей является ключевой задачей.
В ходе тестирования новой методики Parallel Context-of-Experts Decoding (Pced) на общепризнанных эталонах, таких как HotpotQA и Natural Questions, были продемонстрированы впечатляющие результаты. При использовании модели Llama-3.1-8B, Pced достиг показателя в 66 баллов на HotpotQA, что свидетельствует о способности эффективно извлекать информацию из сложных вопросов, требующих многоступенчатого рассуждения. Еще более значительным оказался результат на Natural Questions, где Pced набрал 85 баллов, подтверждая высокую точность в ответе на вопросы, основанные на предоставленном контексте. Эти показатели демонстрируют существенный прогресс в обработке длинных контекстов и способности системы к пониманию и анализу информации.
Перспективы развития: расширяя горизонты
Предлагаемый параллельный подход к декодированию открывает принципиально новые возможности для интеграции внешних источников знаний и осуществления сложных процессов рассуждения. Вместо традиционного последовательного анализа, система способна одновременно обрабатывать информацию из различных источников — баз данных, специализированных корпусов, или даже результатов других моделей — и эффективно сопоставлять ее с текущим контекстом. Это позволяет не просто генерировать текст, но и обосновывать его, ссылаясь на релевантные факты и логические цепочки. В перспективе, подобная архитектура позволит создавать системы, способные к самостоятельному решению сложных задач, требующих анализа большого объема информации и проведения логических выводов, что значительно расширяет границы возможностей языковых моделей и открывает новые перспективы в области искусственного интеллекта.
Восстановление взаимодействия между независимо закодированными документами представляет собой перспективное направление для повышения связности генерируемых текстов. Исследования показывают, что традиционные методы кодирования часто фрагментируют информацию, теряя контекстуальные связи между различными источниками. Предлагаемый подход направлен на восстановление этих связей, позволяя модели учитывать взаимозависимости между документами и создавать более последовательные и логически обоснованные тексты. Это достигается за счет анализа семантических отношений и установления соответствий между фрагментами информации из разных источников, что особенно важно при работе с большими объемами данных и сложными темами. Успешная реализация данного механизма позволит создавать системы, способные не просто генерировать текст, но и эффективно синтезировать знания из различных источников, обеспечивая более глубокое понимание и более качественную коммуникацию.
Архитектура данной системы разработана с учетом принципов модульности, что обеспечивает возможность беспрепятственной интеграции передовых стратегий декодирования, таких как контекстно-зависимое декодирование. Такой подход позволяет адаптировать модель к специфическим требованиям различных задач и эффективно использовать внешние знания. В частности, контекстно-зависимое декодирование позволяет учитывать более широкий спектр факторов при генерации текста, что значительно повышает его связность, релевантность и естественность. Гибкость архитектуры открывает перспективы для дальнейшего развития и внедрения инновационных методов обработки естественного языка, способствуя созданию более интеллектуальных и эффективных языковых моделей.
Непрерывные исследования и оптимизация данной архитектуры представляют собой перспективный путь к значительному расширению возможностей моделирования длинного контекста. Углубленная работа над алгоритмами, направленная на повышение эффективности и точности обработки информации, позволит преодолеть существующие ограничения и достичь качественно нового уровня понимания и генерации текста. Ожидается, что дальнейшее развитие позволит модели не только обрабатывать значительно большие объемы информации, но и более эффективно извлекать из них полезные знания, выявлять сложные взаимосвязи и генерировать более связные и осмысленные тексты, открывая новые горизонты в области обработки естественного языка и искусственного интеллекта.
Работа демонстрирует, что параллельная обработка документов в процессе генерации, как предлагается в PCED, действительно способна ускорить процесс и повысить точность. Однако, за этим стоит неизбежный компромисс: увеличение сложности системы и, как следствие, потенциальные точки отказа. В этом контексте вспоминается высказывание Винтона Серфа: «Всё, что оптимизировано, рано или поздно оптимизируют обратно». Стремление к максимальной производительности, пусть даже и достигаемое за счет параллелизации и динамического взвешивания вкладов документов, рано или поздно столкнется с необходимостью оптимизации самой этой оптимизации. Архитектура, как и любой сложный механизм, обречена на постоянный рефакторинг в погоне за эффективностью, ведь даже самый элегантный теоретический подход неизбежно столкнется с суровой реальностью продакшена.
Что дальше?
Предложенный фреймворк, Parallel Context-of-Experts Decoding, безусловно, добавляет ещё один слой абстракции между запросом и ответом. Ускорение декодирования и повышение точности — это, конечно, приятно, но неизбежно порождает новые проблемы. Скорость — это иллюзия, а масштабирование всегда найдёт способ превратить элегантную оптимизацию в узкое место. Кэш KV, как и любая другая оптимизация, рано или поздно потребует ритуальных жертвоприношений в виде памяти и вычислительных ресурсов.
Очевидно, что поле cross-document reasoning — это благодатная почва для исследований, но стоит помнить: каждая новая архитектура — это просто ещё один способ отложить нерешённые проблемы на потом. В конечном счёте, документация — это миф, созданный менеджерами, а реальная сложность всегда скрывается в краевых случаях, которые никто не предвидел. Более того, динамическое взвешивание вклада документов — это элегантно, но как гарантировать, что система не начнёт отдавать предпочтение самым громким, а не самым релевантным источникам?
Можно предположить, что будущее за ещё более сложными механизмами взвешивания, возможно, с использованием методов обучения с подкреплением, чтобы система могла «научиться» оценивать качество информации. Но не стоит забывать: наша CI — это храм, в котором мы молимся, чтобы ничего не сломалось. И каждая «революционная» технология завтра станет техдолгом. В конечном итоге, все эти улучшения лишь позволяют нам откладывать неизбежное: необходимость переосмыслить саму концепцию поиска и генерации знаний.
Оригинал статьи: https://arxiv.org/pdf/2601.08670.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- Согласие роя: когда разум распределён, а ошибки прощены.
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Квантовый импульс для несбалансированных данных
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Безопасность генерации изображений: новый вектор управления
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Умная экономия: Как сжать ИИ без потери качества
- Видеовопросы и память: Искусственный интеллект на грани
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
2026-01-15 03:57