Автор: Денис Аветисян
Новый подход позволяет агентам, основанным на больших языковых моделях, более эффективно планировать свои действия, используя возможности предсказания и моделирования окружающего мира.
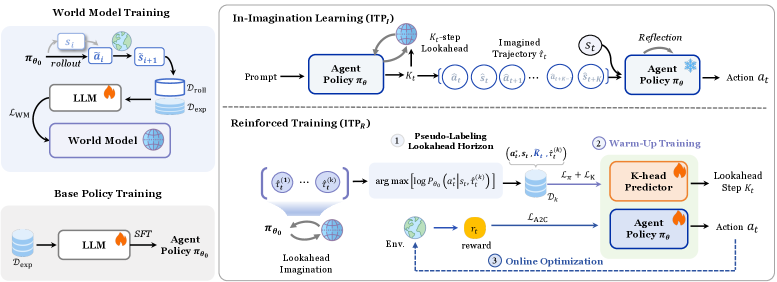
В статье представлен фреймворк Imagine-then-Plan (ITP), объединяющий адаптивный взгляд в будущее и мировые модели для улучшения обучения агентов в сложных средах.
Несмотря на успехи в области мировых моделей, их потенциал для сложного планирования действий агентов часто остается нереализованным. В статье ‘Imagine-then-Plan: Agent Learning from Adaptive Lookahead with World Models’ предлагается новый подход, позволяющий агентам использовать адаптивный горизонт прогнозирования для более эффективного решения задач. Предложенная схема “Imagine-then-Plan” (ITP) объединяет возможности мировых моделей с адаптивным механизмом прогнозирования, значительно повышая способность агентов к рассуждениям и успешному выполнению сложных задач. Какие перспективы открывает интеграция адаптивного планирования с использованием мировых моделей для создания более интеллектуальных и автономных агентов?
За гранью реакций: Необходимость предвидения для агентов
Традиционные алгоритмы обучения с подкреплением и агенты, основанные на больших языковых моделях, зачастую демонстрируют реактивный подход к принятию решений, оперируя исключительно текущим состоянием среды. Это ограничивает их способность эффективно действовать в сложных и динамичных условиях, где важна предвидение последствий. Вместо проактивного планирования и долгосрочного прогнозирования, такие агенты склонны реагировать на немедленные стимулы, что приводит к субоптимальным результатам в задачах, требующих последовательности действий и учета отложенной награды. Отсутствие способности к планированию снижает эффективность агентов в ситуациях, где успех зависит от способности предвидеть будущие события и адаптировать стратегию соответствующим образом.
Для эффективного принятия решений в сложных средах недостаточно просто реагировать на текущую ситуацию. Вместо этого, необходим переход к проактивному подходу, основанному на предвидении последствий действий. Искусственные агенты, способные моделировать будущие состояния и оценивать долгосрочные результаты, демонстрируют значительно более высокую эффективность в задачах, требующих планирования и адаптации. Такой прогноз позволяет агенту выбирать действия не только на основе немедленной выгоды, но и с учетом потенциального влияния на будущие события, что особенно важно в динамичных и непредсказуемых условиях. Разработка алгоритмов, способных к точному предвидению, является ключевой задачей для создания действительно интеллектуальных систем.
Современные методы обучения с подкреплением и языковые модели часто испытывают трудности при решении задач с горизонтом планирования, где вознаграждение достигается спустя значительное время. Это связано с тем, что точная оценка будущих состояний становится критически важной для принятия эффективных решений. Предсказание долгосрочных последствий действий требует от агента не просто реагирования на текущую ситуацию, а построения вероятностных моделей развития событий, что представляется сложной задачей, особенно в динамичных и непредсказуемых средах. Неспособность надежно оценивать отдаленные последствия приводит к принятию субоптимальных решений и снижает эффективность агента в долгосрочной перспективе. Разработка алгоритмов, способных к более точному прогнозированию будущих состояний и адекватному учету отложенного вознаграждения, является ключевой задачей для создания интеллектуальных агентов, способных успешно функционировать в сложных реальных условиях.
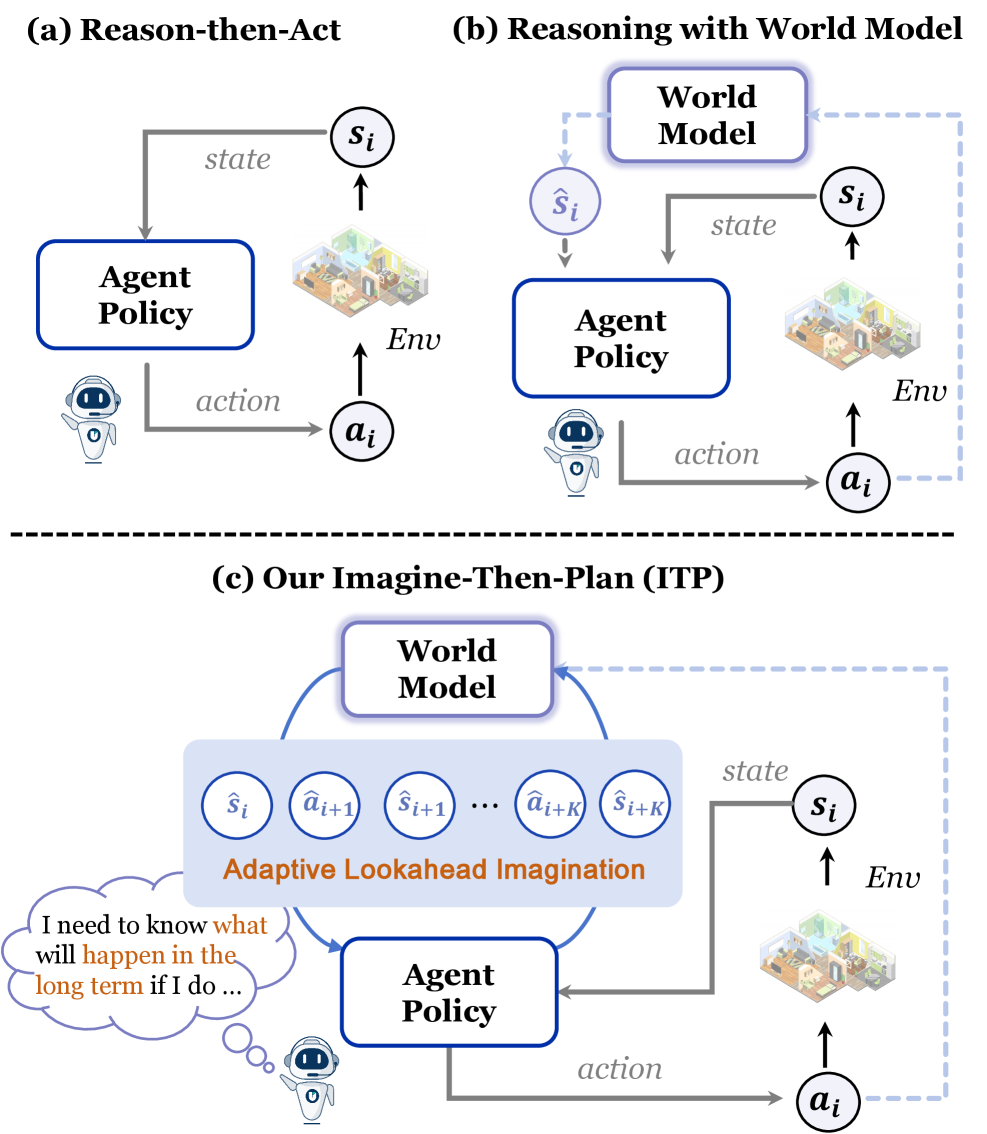
Предвидение и планирование: Архитектура проактивных агентов
В рамках концепции “Предвидение-Планирование” (Imagine-then-Plan) агенты используют “Мировую Модель” для моделирования возможных будущих траекторий развития событий перед принятием конкретных действий. Этот подход позволяет агенту оценить потенциальные последствия различных вариантов действий в смоделированной среде, что повышает эффективность и надежность принимаемых решений. Мировая модель представляет собой внутреннее представление об окружающей среде и динамике её изменения, позволяющее прогнозировать результаты действий без их непосредственного выполнения в реальном мире. Эффективность данного подхода заключается в возможности предварительной оценки рисков и оптимизации стратегии действий на основе смоделированных сценариев.
Стандартная модель процесса принятия решений Маркова с частичной наблюдаемостью (POMDP) предполагает принятие решений на основе текущего наблюдения и вероятностной оценки состояния мира. Предложенный подход расширяет эту модель, вводя понятие «Частично Наблюдаемый и Воображаемый POMDP» (Partially Observable and Imaginable MDP). В этой расширенной модели, состояние агента включает не только текущее наблюдение, но и представления о возможных будущих траекториях, полученные в результате симуляции (“воображения”) различных сценариев. Таким образом, агент планирует действия, учитывая не только текущую ситуацию, но и вероятные последствия этих действий в будущем, что позволяет повысить эффективность планирования и адаптивность к изменяющейся среде. s_t \in S теперь включает в себя как текущие наблюдения, так и смоделированные будущие состояния.
Ключевым элементом данной архитектуры является механизм «Адаптивного Прогнозирования» (Adaptive Lookahead), который динамически изменяет горизонт планирования в зависимости от сложности задачи и потенциальных конфликтов. Этот подход позволяет оптимизировать использование вычислительных ресурсов, поскольку агент не тратит время на планирование на большие временные горизонты в простых ситуациях, и наоборот, расширяет горизонт планирования при обнаружении сложных сценариев или возможности возникновения конфликтов. Длина горизонта планирования определяется на основе оценки текущего состояния среды и прогнозируемой сложности будущих действий, обеспечивая баланс между точностью планирования и вычислительной эффективностью.
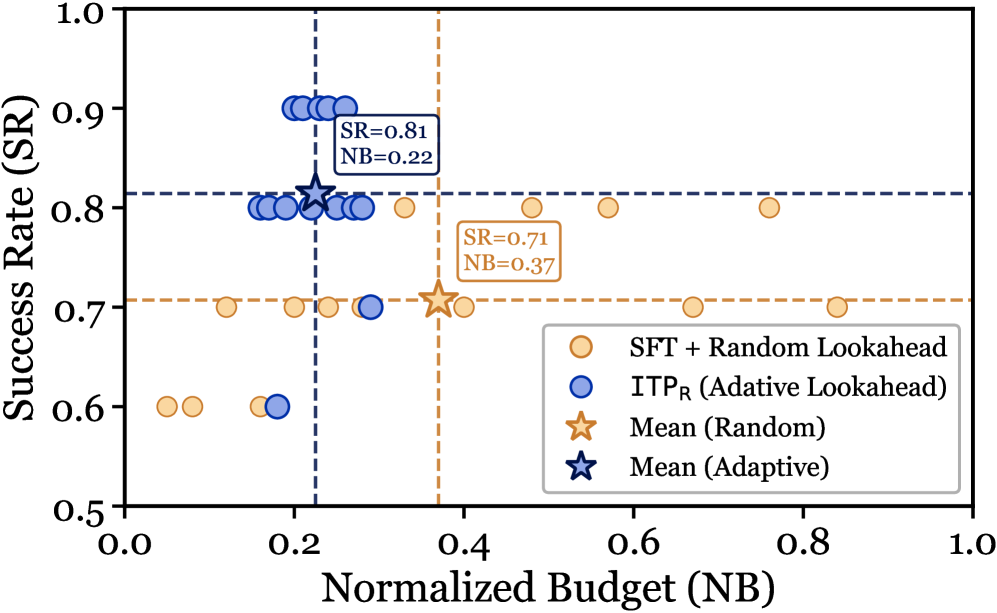
Уточнение предвидения: Стратегии обучения и инференса
Представлены две реализации фреймворка Imagine-then-Plan: ‘ITP-R’ и ‘ITP-I’. Вариант ‘ITP-R’ использует обучение с подкреплением и обучение с учителем на основе траекторий эксперта (‘Expert Trajectories’) для оптимизации стратегии агента. В свою очередь, ‘ITP-I’ является подходом, не требующим обучения во время инференса и использующим исключительно предобученную модель мира. Оба варианта предназначены для решения сложных задач, требующих долгосрочного планирования и надежной оценки состояния.
В рамках подхода ITP-R обучение агента осуществляется с использованием методов обучения с подкреплением, что позволяет оптимизировать как стратегию действий агента (policy), так и горизонт адаптивного прогнозирования (Adaptive Lookahead). В отличие от этого, ITP-I не требует обучения в процессе инференса и полностью полагается на возможности предварительно обученной модели мира. Оптимизация Adaptive Lookahead в ITP-R позволяет динамически регулировать глубину планирования, что повышает эффективность решения задач, требующих долгосрочного прогнозирования и точной оценки состояния среды.
Оба варианта предложенного подхода — ITP-R и ITP-I — демонстрируют повышение эффективности при решении сложных задач, требующих долгосрочного планирования и надежной оценки состояния среды. Наблюдаемое улучшение связано с возможностью более точного прогнозирования последствий действий на значительном горизонте планирования, что критически важно для успешного выполнения задач с высокой степенью неопределенности. Повышенная устойчивость к шумам и неточностям в оценке состояния позволяет агентам сохранять работоспособность в сложных и динамичных окружениях, где традиционные методы планирования могут оказаться неэффективными.
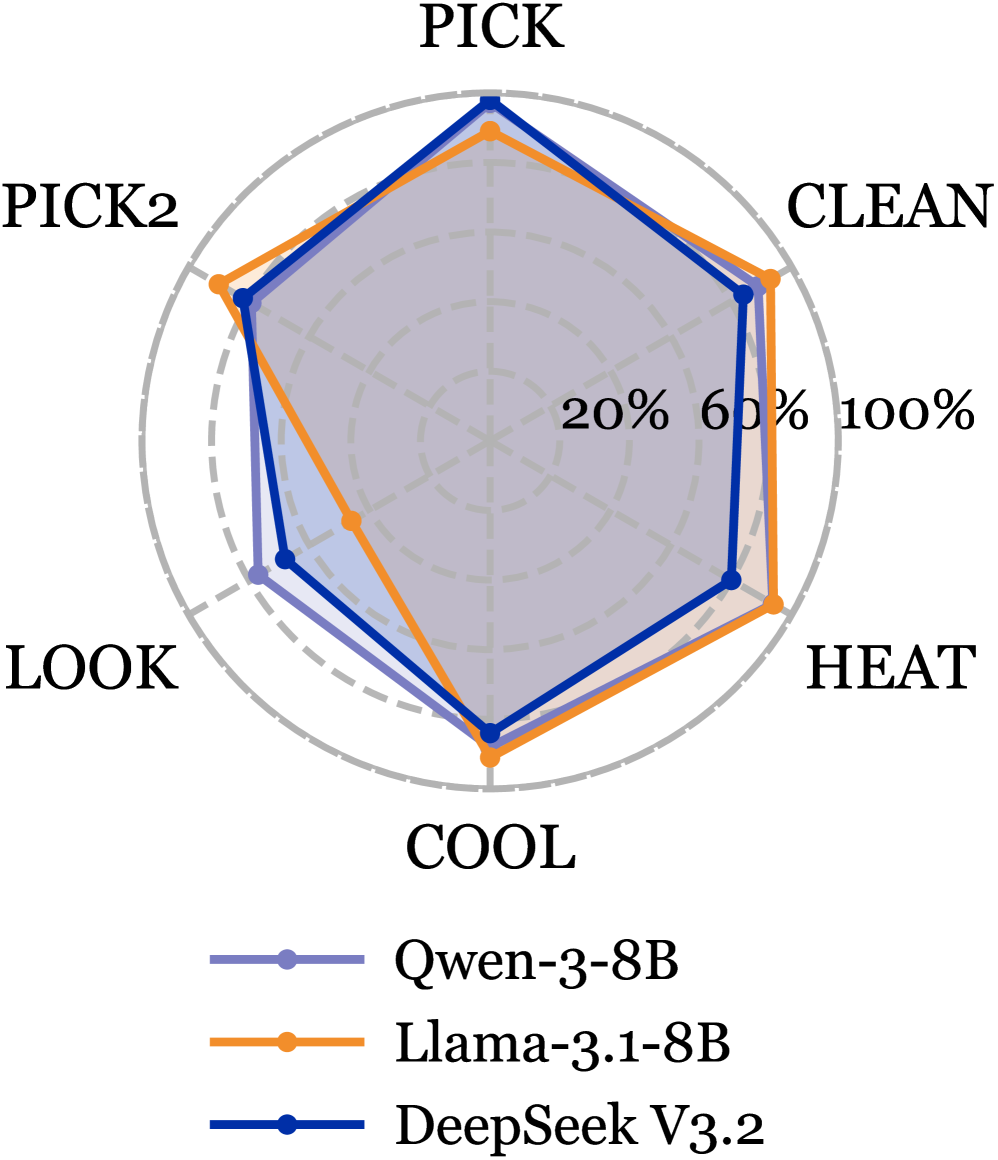
Демонстрация влияния: Воплощенные агенты в сложных средах
Для подтверждения эффективности предложенного подхода «Предвидение-Планирование» были проведены всесторонние испытания в сложных текстовых средах, таких как ‘ALFWorld’ и ‘ScienceWorld’. Эти платформы, известные своей сложностью и необходимостью глубокого понимания языка для успешного взаимодействия, позволили оценить способность агентов к планированию и прогнозированию последствий своих действий. Результаты показали, что разработанный фреймворк демонстрирует высокую надежность и способность адаптироваться к различным задачам, требующим логического мышления и стратегического подхода к решению проблем в динамичных текстовых мирах.
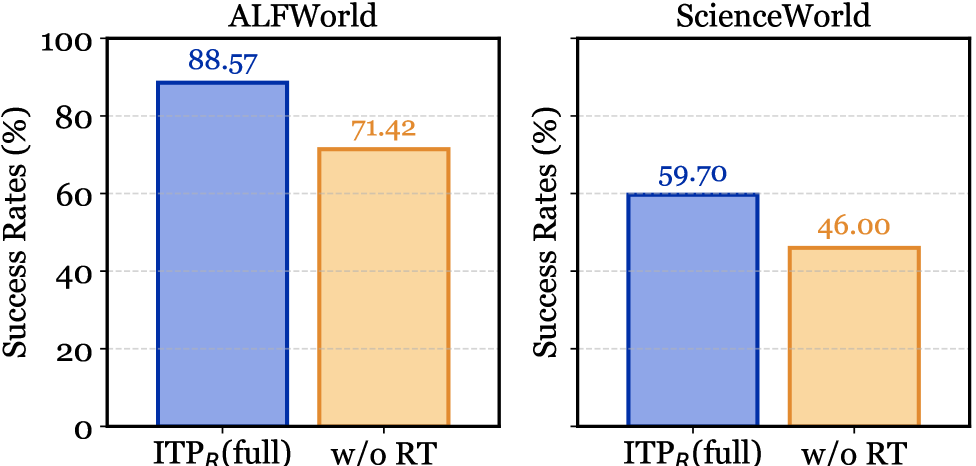
Исследования показали значительное превосходство предложенных моделей ITP-R и ITP-I над существующими базовыми методами в сложных текстовых средах. В частности, при тестировании на платформе ALFWorld с использованием языковой модели Qwen3-8B, достигнут впечатляющий показатель успешного выполнения задач — до 88.57%. Аналогичные результаты были получены на платформе ScienceWorld с использованием Llama3.1-8B, где успешность составила 63.91%. Эти данные свидетельствуют о высокой эффективности разработанного подхода в обеспечении надежной работы агентов в сложных и непредсказуемых условиях, что открывает перспективы для создания более интеллектуальных и адаптивных систем искусственного интеллекта.
Предложенная архитектура демонстрирует высокую эффективность благодаря способности к прогнозированию последствий действий. Агенты, использующие данный подход, способны не только воспринимать текущую ситуацию, но и моделировать несколько шагов вперёд, что позволяет им выбирать наиболее оптимальные решения в сложных условиях. В ходе экспериментов на платформах ALFWorld и ScienceWorld было установлено, что средний горизонт планирования составляет 3 шага для ALFWorld и 8 шагов для ScienceWorld. Такое проактивное планирование значительно повышает устойчивость агентов к непредсказуемым ситуациям и позволяет достигать поставленных целей с большей эффективностью, обеспечивая надёжную навигацию и выполнение задач в запутанных средах.
Этот документ описывает очередную попытку заставить языковую модель думать. «Представь, а потом планируй»… Звучит как очередная сложная архитектура, призванная решить проблему частичной наблюдаемости. На самом деле, всё сводится к тому, чтобы добавить ещё один уровень абстракции над существующими проблемами. Как говорил Алан Тьюринг: «Мы можем только надеяться, что машины не станут слишком умными». Ведь в конечном итоге, каждая новая «революционная» технология, будь то адаптивный горизонт планирования или мировые модели, рано или поздно превратится в техдолг, который придётся расхлёбывать. И кто-нибудь обязательно найдёт способ сломать даже самую элегантную теорию, применив её на практике.
Что Дальше?
Представленный подход, интегрирующий «воображение» и планирование, неизбежно сталкивается с той же проблемой, что и любое усложнение: экспоненциальный рост вычислительных затрат. Элегантность теоретической конструкции не гарантирует масштабируемость. Ведь рано или поздно, любое оптимизированное решение будет оптимизировано обратно — под требования реальных ресурсов. Вопрос не в том, чтобы построить идеальную модель мира, а в том, чтобы найти компромисс между детализацией и вычислительной доступностью.
Очевидным направлением является поиск более эффективных методов обучения и представления «мировых моделей». Однако, истинная проблема, вероятно, заключается не в самих моделях, а в определении «достаточной» точности. Бесконечное усложнение симуляции не приблизит агента к решению, если оно не учитывает непредсказуемость реального мира. В конце концов, архитектура — это не схема, а компромисс, переживший деплой.
Вероятно, будущие исследования будут смещены в сторону более гибридных подходов, сочетающих возможности LLM с традиционными алгоритмами обучения с подкреплением. Не стоит забывать, что «воображение» без обратной связи с реальностью — это лишь ещё один способ отложить неизбежное столкновение с хаосом. Мы не рефакторим код — мы реанимируем надежду.
Оригинал статьи: https://arxiv.org/pdf/2601.08955.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- Согласие роя: когда разум распределён, а ошибки прощены.
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Квантовый импульс для несбалансированных данных
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Безопасность генерации изображений: новый вектор управления
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Умная экономия: Как сжать ИИ без потери качества
- Видеовопросы и память: Искусственный интеллект на грани
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
2026-01-15 10:33