Автор: Денис Аветисян
Исследователи представили комплексную методику оценки способности больших языковых моделей к научному мышлению, основанному на извлечении и применении знаний из памяти.
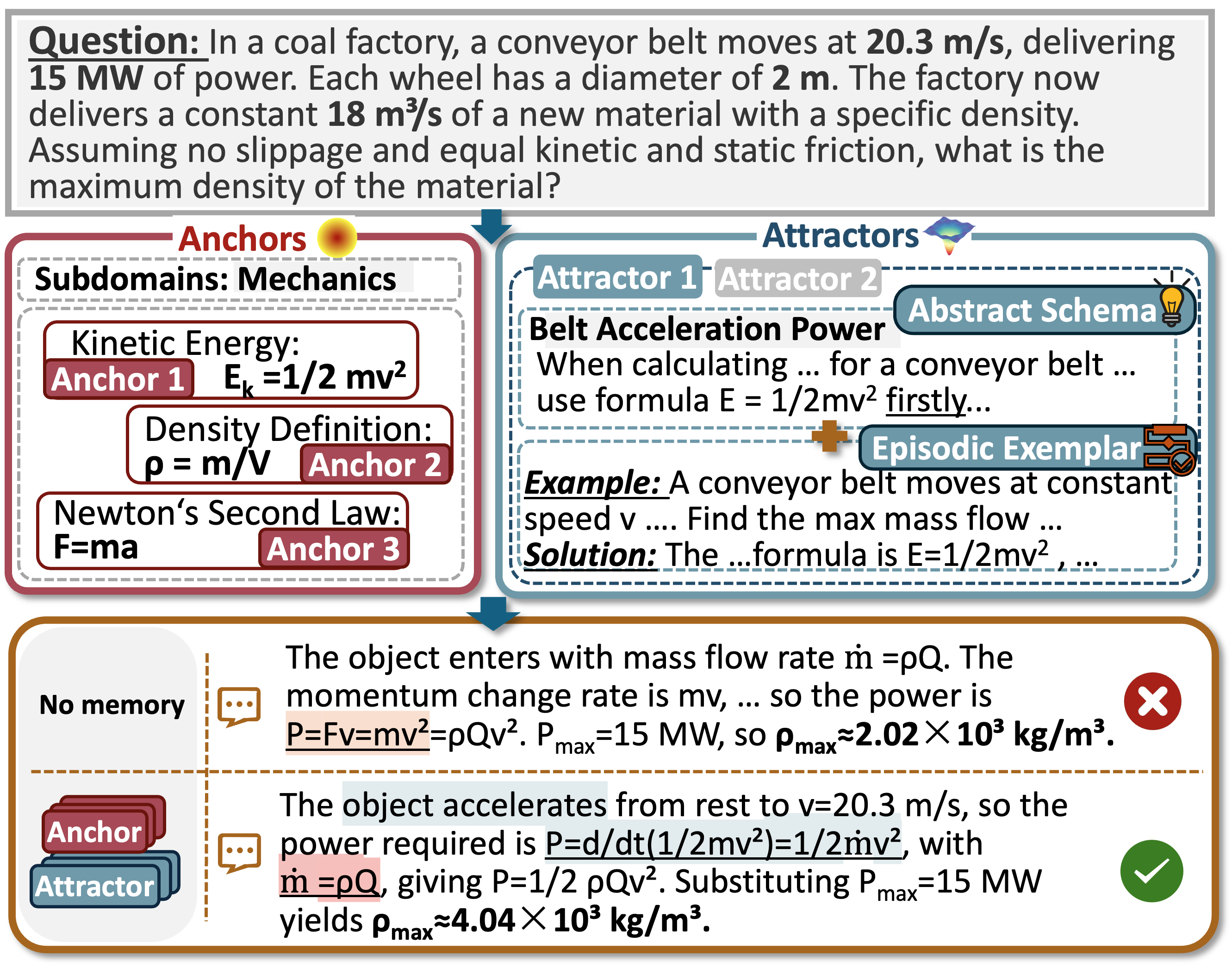
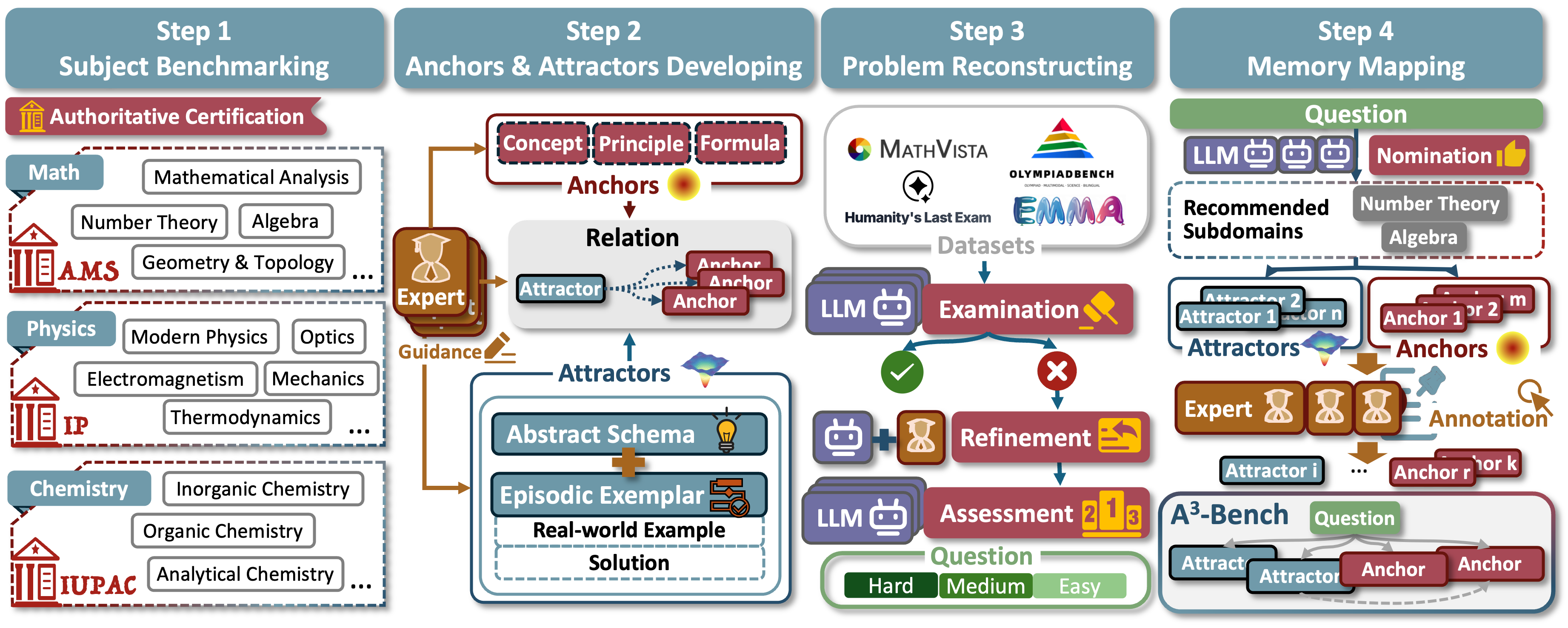
Представлен набор данных A³-Bench для оценки памяти и логического мышления языковых моделей в контексте научных задач.
Несмотря на успехи современных моделей искусственного интеллекта в решении научных задач, часто упускается из виду роль памяти и предшествующих знаний в процессе рассуждений. В данной работе представлена новая методика оценки, ‘$A^3$-Bench: Benchmarking Memory-Driven Scientific Reasoning via Anchor and Attractor Activation’, направленная на анализ способности моделей к использованию фундаментальных знаний (Якоря) и шаблонов решения задач (Аттракторы) в процессе научного рассуждения. Предложенный набор данных и метрика AAUI позволяют оценить активацию памяти и ее влияние на эффективность рассуждений, выявляя, как именно предшествующий опыт способствует решению сложных научных проблем. Не откроет ли это путь к созданию более надежных и эффективных систем искусственного интеллекта, способных к истинному научному мышлению?
Предел Масштабирования: Необходимость Мышления, Основанного на Памяти
Современные подходы к научному рассуждению всё чаще опираются на простое масштабирование больших языковых моделей, что приводит к значительному росту вычислительных затрат и снижению эффективности. Этот метод, хотя и позволяет достигать впечатляющих результатов в некоторых задачах, быстро становится непрактичным по мере увеличения сложности решаемых проблем. Необходимость обработки огромных объемов данных и проведения миллионов вычислений для каждого нового вопроса делает такие модели ресурсоемкими и медленными. Вместо того, чтобы имитировать человеческое мышление, основанное на эффективном использовании памяти и накопленных знаний, существующие системы часто полагаются на грубую силу вычислений, что ограничивает их масштабируемость и способность к обобщению. Подобный подход, несмотря на свою кажущуюся простоту, препятствует созданию действительно интеллектуальных систем, способных к глубокому пониманию и решению сложных научных задач.
Человеческий мозг демонстрирует удивительную способность к рассуждениям, основанную не на грубой вычислительной мощности, а на эффективном извлечении информации из памяти и применении накоренного опыта. В отличие от современных систем искусственного интеллекта, требующих огромных ресурсов для решения даже простых задач, мозг оперирует с принципиально иной эффективностью. Исследования нейрофизиологии показывают, что рассуждение часто сводится к активации определенных паттернов в памяти и их комбинированию для формирования новых выводов. Этот биологически вдохновленный подход предполагает, что для создания действительно интеллектуальных систем необходимо отойти от чисто статистических моделей и сосредоточиться на разработке механизмов, имитирующих способность мозга к активному использованию и компоновке фундаментальных знаний, что откроет путь к более эффективным и масштабируемым решениям в области научного мышления.
Для достижения подлинного научного мышления, необходимо отойти от моделей, основанных исключительно на статистическом анализе больших объемов данных. Вместо этого, акцент должен быть сделан на создание систем, способных активно использовать и комбинировать фундаментальные знания. Такой подход предполагает не просто запоминание информации, но и умение извлекать релевантные факты из базы знаний, устанавливать связи между ними и применять их для решения новых задач. Подобная организация позволяет системе рассуждать более эффективно, избегая вычислительных затрат, связанных с «грубой силой» статистических методов, и приближаясь к принципам работы человеческого мозга, где память и накопленный опыт играют ключевую роль в процессе познания.
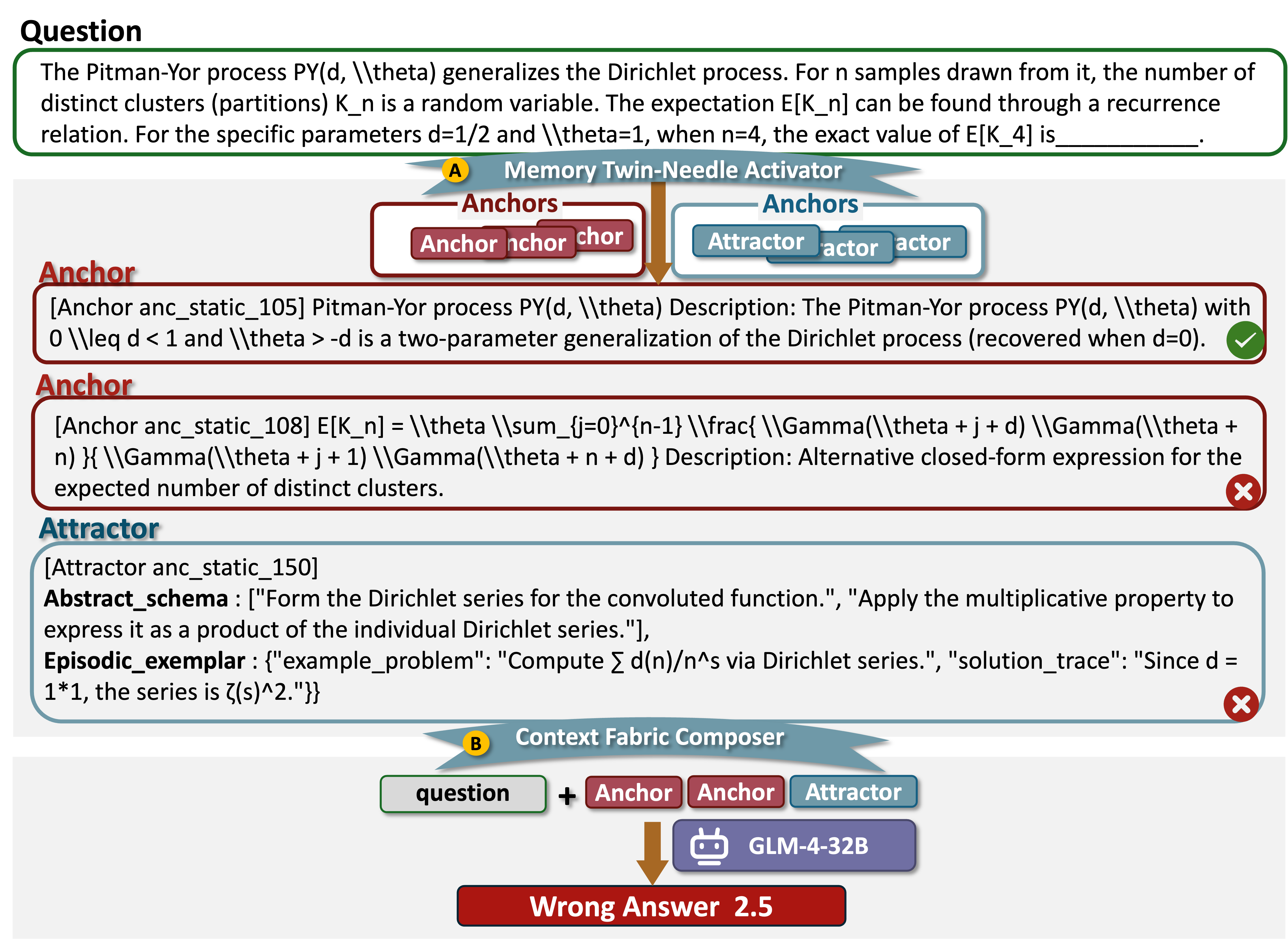
Активация Памяти: Якоря, Аттракторы и Чертеж Мозга
Активация памяти представляет собой процесс извлечения и использования релевантных знаний — представленных в виде Якорей и Аттракторов — для повышения эффективности рассуждений. Якоря служат базовыми единицами знаний, включающими основные понятия, принципы или формулы, в то время как Аттракторы представляют собой повторно используемые шаблоны решений или схемы. Этот процесс позволяет мозгу применять накопленный опыт и знания к текущим задачам, оптимизируя когнитивные операции и улучшая способность к логическому мышлению и решению проблем. Эффективная активация памяти критически важна для адаптивного поведения и обучения.
Якоря представляют собой фундаментальные единицы знаний — основные понятия, принципы или формулы, служащие базовыми строительными блоками для решения задач. В отличие от них, аттракторы воплощают собой повторно используемые образцы решений или схемы, представляющие собой уже сформированные стратегии для работы с определенными типами задач. Таким образом, якоря обеспечивают основу для понимания, а аттракторы — готовую структуру для применения этого понимания, позволяя эффективно обрабатывать информацию и находить решения без необходимости каждый раз начинать с нуля. Например, знание E=mc^2 является якорем, а схема решения задачи на закон сохранения энергии — аттрактором.
Процесс активации памяти и, как следствие, улучшение когнитивных способностей, теоретически обоснован принципами минимизации свободной энергии. Данная концепция предполагает, что мозг функционирует как система, стремящаяся к уменьшению расхождения между предсказаниями и поступающими сенсорными данными. F = \in t Q(x,z)log \frac{Q(x,z)}{P(x,z)} dx, где F — свободная энергия, Q — апроксимированное распределение, а P — истинное распределение вероятностей. Минимизация этого расхождения достигается путем корректировки внутренних моделей и предсказаний, что позволяет более эффективно обрабатывать информацию и адаптироваться к окружающей среде. В контексте активации памяти, это означает, что мозг использует имеющиеся знания (якоря и аттракторы) для формирования предсказаний о текущей ситуации и, в случае расхождения с реальностью, корректирует эти предсказания, активируя соответствующие воспоминания и знания.
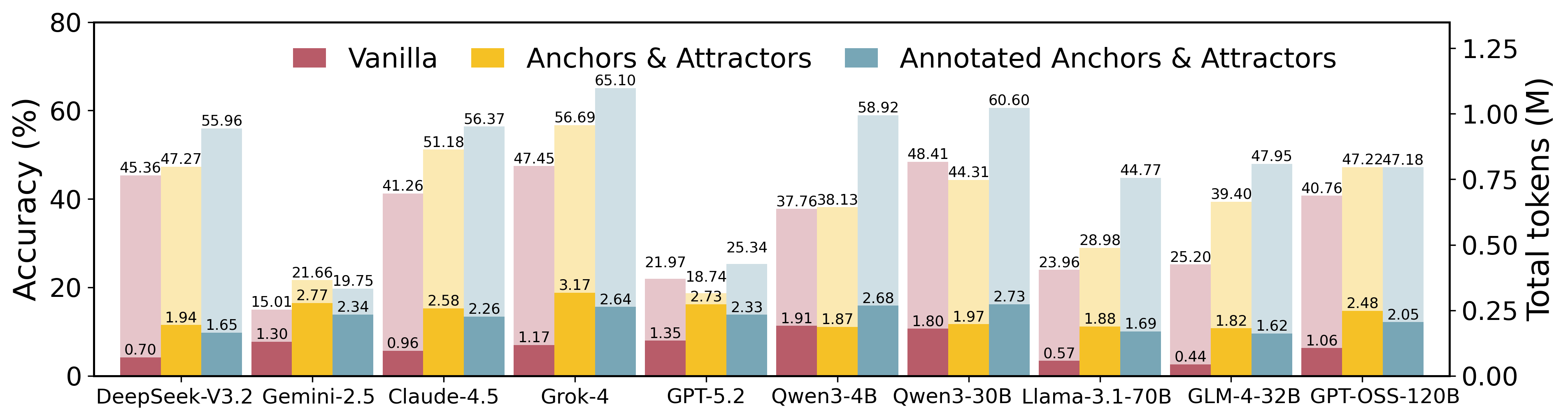
HybridRAG: Рамки для Композиции Знаний
Гибридная система HybridRAG представляет собой фреймворк, предназначенный для реализации рассуждений, основанных на памяти, посредством комбинирования релевантных Якорей (Anchors) и Аттракторов (Attractors). Якоря служат точками отсчета, предоставляя конкретные факты и информацию, извлеченную из источников знаний. Аттракторы, в свою очередь, определяют направление рассуждений, связывая Якоря и обеспечивая контекст для применения извлеченной информации. Композиция Якорей и Аттракторов позволяет системе не просто извлекать данные, но и структурировать их для решения поставленной задачи, имитируя процесс человеческого мышления и обеспечивая более логичные и обоснованные выводы.
Гибридный подход к поиску знаний в системе HybridRAG реализуется посредством двух основных механизмов: Vector Needle и Graph Needle. Vector Needle использует векторное представление данных и поиск по семантической близости для извлечения информации, релевантной запросу. Graph Needle, в свою очередь, оперирует с графовыми структурами знаний, позволяя обходить связи между сущностями и извлекать информацию, опосредованно связанную с запросом. Комбинирование этих двух подходов обеспечивает более полный доступ к знаниям, включая как прямые соответствия запросу, так и связанные концепции и факты, что расширяет возможности системы в решении сложных задач.
Композиция, обеспечиваемая HybridRAG, позволяет системе не только извлекать фактическую информацию, но и применять ее в логически структурированном порядке, приближаясь к модели человеческого рассуждения. Это достигается за счет интеграции извлеченных данных из различных источников — как семантически похожих фрагментов, определенных Vector Needle, так и связанных сущностей, обнаруженных Graph Needle. В результате система способна выводить новые знания, основанные на комбинации и анализе релевантной информации, а не просто предоставлять ответы на основе прямого поиска совпадений, что повышает ее способность к решению сложных задач и адаптации к новым ситуациям.
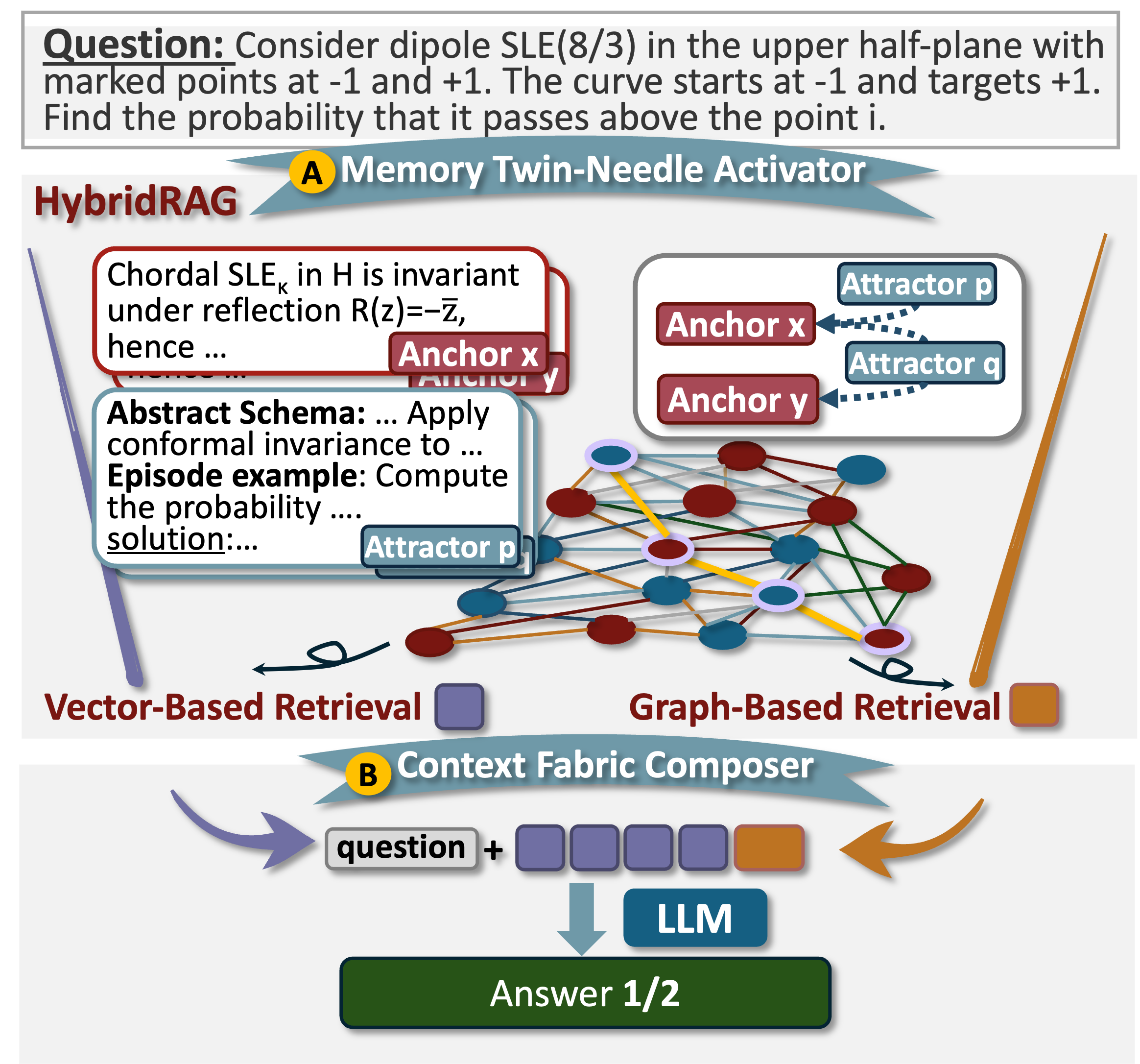
A3A^3-Bench: Оценка Научного Мышления, Основанного на Памяти
Бенчмарк A3A^3 был разработан специально для оценки научного рассуждения, основанного на использовании памяти, применяя принципы активации “Якорей” и “Аттракторов”. Данный подход имитирует процесс, происходящий в человеческом мозге, где ключевая информация (“Якоря”) активирует связанные знания (“Аттракторы”), позволяя эффективно решать сложные задачи. В основе A3A^3 лежит идея о том, что способность модели извлекать и использовать релевантную информацию из памяти является критически важной для успешного научного анализа. Бенчмарк позволяет оценить, насколько эффективно языковые модели способны использовать внешнюю память для улучшения своих рассуждений и достижения более точных результатов в научных задачах, требующих глубокого понимания контекста и способности к логическому выводу.
Для создания эталонного набора данных A3A^3-Bench был применен процесс аннотации SAPM (Scientific Annotation and Pattern Mining), что обеспечило строгий и стандартизированный подход к формированию датасета. SAPM предполагает детальный анализ научных текстов с выделением ключевых фактов, связей и паттернов, необходимых для оценки способностей моделей к рассуждению, основанному на памяти. Использование SAPM гарантирует согласованность и надежность аннотаций, а также позволяет объективно оценивать эффективность различных методов аугментации памяти в контексте научных задач. Такой подход к созданию датасета критически важен для получения достоверных результатов и продвижения исследований в области искусственного интеллекта, способного к глубокому научному анализу.
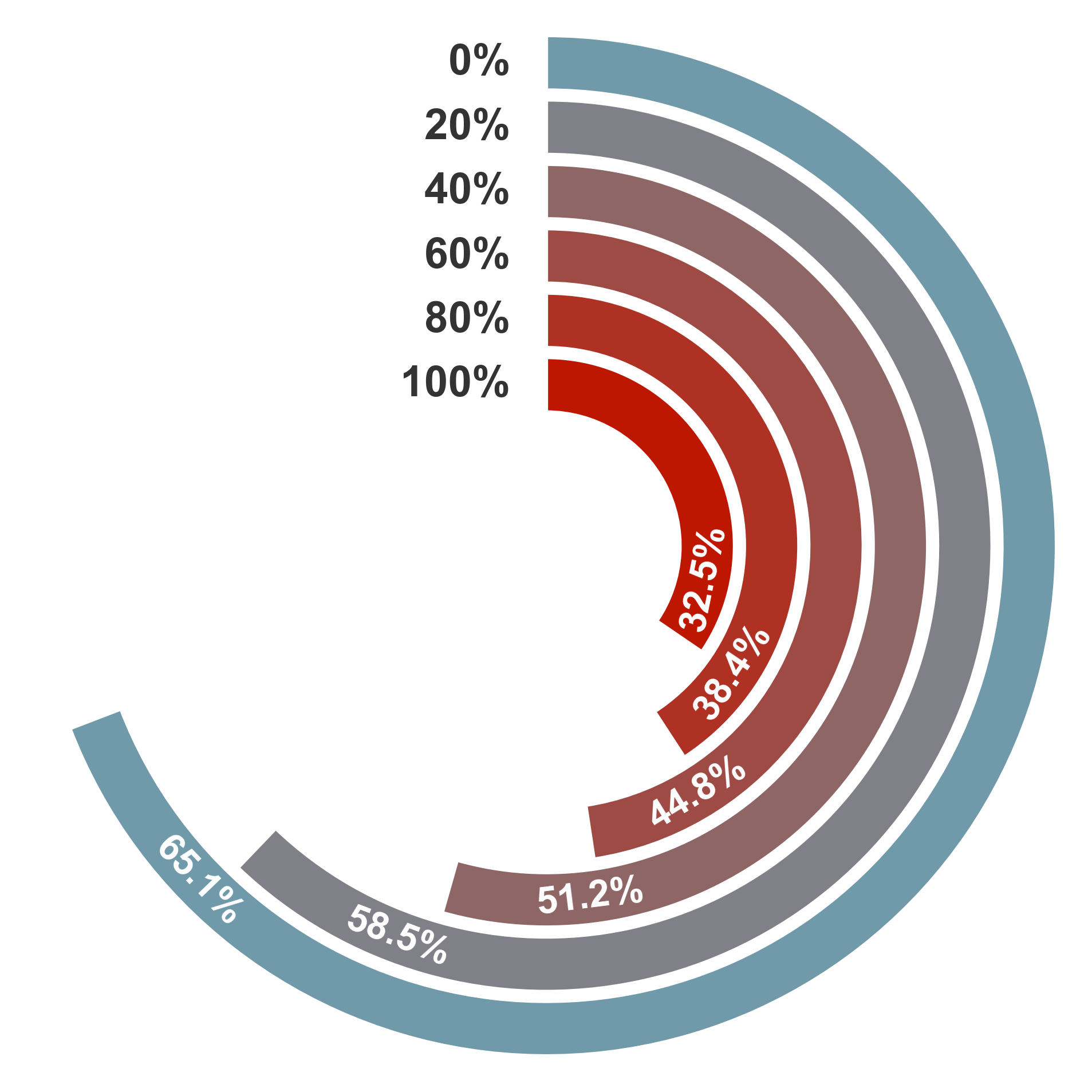
Результаты тестирования на бенчмарке A3A^3-Bench демонстрируют значительное повышение точности — в среднем на 13.48% — у десяти различных больших языковых моделей (LLM) при использовании дополнения внешней памятью. Это подчеркивает ключевую роль памяти в усилении способностей к логическому мышлению и решению научных задач. В частности, разработанный показатель — Индекс Использования Якорей и Аттракторов (AAUI) — показывает прямую корреляцию с точностью ответов. Например, модель Grok-4-Fast демонстрирует значение AAUI равное 0.66, что свидетельствует об эффективной активации и использовании механизмов памяти для повышения качества рассуждений и получения более точных результатов.
Смягчение Шума: К Надежным Системам, Основанным на Памяти
Помехи в данных представляют собой серьезную проблему для систем, использующих память для рассуждений, поскольку нерелевантная информация способна затруднить точный поиск и применение знаний. Данное явление особенно критично в сложных задачах, где система должна отделить важные детали от шума, чтобы прийти к верному выводу. Неспособность эффективно фильтровать помехи приводит к снижению точности, увеличению вероятности ошибок и, в конечном итоге, к ухудшению общей производительности системы. Исследования показывают, что даже незначительное количество нерелевантных данных может существенно повлиять на качество принимаемых решений, что подчеркивает необходимость разработки эффективных механизмов для борьбы с этим явлением и повышения надежности систем, основанных на использовании памяти.
Перспективные исследования направлены на разработку методов фильтрации шума и повышения устойчивости процессов активации памяти в системах, основанных на использовании памяти. Особое внимание уделяется алгоритмам, способным эффективно отделять релевантную информацию от нерелевантной, тем самым предотвращая искажение знаний и улучшая точность рассуждений. Разработка таких методов предполагает исследование различных подходов к взвешиванию и ранжированию информации в памяти, а также создание механизмов, способных адаптироваться к различным типам шума и контекстам. Успешная реализация этих исследований позволит создавать более надежные и эффективные системы, способные оперировать знаниями в сложных и зашумленных условиях, открывая новые возможности для применения в различных областях, включая обработку естественного языка и машинное обучение.
Исследования показали значительное повышение эффективности моделей, использующих аннотированные воспоминания. В частности, модель GLM-4-32B продемонстрировала улучшение до 22.75% в задачах, требующих памяти и рассуждений. Данный результат был подтвержден статистической значимостью, установленной тестом МакНемара с p-значениями менее 0.001, что указывает на высокую вероятность того, что наблюдаемое улучшение не является случайным. Подобные результаты свидетельствуют о перспективности подхода к использованию структурированных и размеченных данных в памяти систем искусственного интеллекта для повышения их надежности и точности.
Преодоление помех в системах, основанных на памяти, открывает путь к реализации их полного потенциала. Устранение влияния нерелевантной информации позволяет создавать системы, способные к более точной и эффективной работе с знаниями. Это, в свою очередь, ведет к разработке надежных и устойчивых решений, применимых в самых разных областях — от обработки естественного языка до принятия решений в сложных условиях. Повышение надежности и эффективности работы с памятью позволяет создавать интеллектуальные системы, способные не только хранить, но и эффективно использовать накопленные знания, что является ключевым фактором для достижения высокого уровня искусственного интеллекта.
Представленный труд демонстрирует стремление к проверке границ возможностей больших языковых моделей в области научного рассуждения. Создание A3A³-Bench, как эталона для оценки активации фундаментальных знаний и шаблонов решения задач, является попыткой не просто оценить существующие системы, но и спровоцировать их дальнейшее развитие. Подобный подход к тестированию, акцентирующий внимание на механизмах активации ‘якорей’ и ‘аттракторов’, напоминает о словах Блеза Паскаля: «Все великие вещи начинаются с малого». И действительно, понимание базовых принципов работы системы, её внутренних ‘якорей’, открывает путь к взлому её ограничений и реализации потенциала, заложенного в модели.
Куда двигаться дальше?
Представленный инструментарий, A3A³-Bench, обнажает не столько возможности, сколько границы текущего поколение больших языковых моделей в области научного рассуждения. Выявление активации «якорей» и «аттракторов» — это, по сути, попытка заглянуть внутрь «чёрного ящика», чтобы понять, не просто что модель выдает, а как она приходит к этим ответам. Однако, само определение «якорей» и «аттракторов» остаётся субъективным, подверженным человеческой интерпретации. Неизбежен вопрос: а не создаём ли мы лишь иллюзию понимания, приписывая рациональные схемы там, где царит чистый статистический хаос?
Будущие исследования, вероятно, должны сосредоточиться на автоматизации процесса идентификации этих ключевых элементов знания. Более того, необходимо исследовать, как различные архитектуры моделей влияют на формирование и использование «якорей» и «аттракторов». Вместо того, чтобы просто оценивать результат, следует изучить траекторию рассуждений, выявляя узкие места и потенциальные источники ошибок.
И, наконец, самое интересное: а что, если истинное научное мышление — это не столько активация заранее заданных шаблонов, сколько способность к их разрушению и созданию принципиально новых? Текущий бенчмарк измеряет лишь умение оперировать существующими знаниями. Следующим шагом должно стать создание задач, требующих от моделей не просто вспоминать, но и изобретать.
Оригинал статьи: https://arxiv.org/pdf/2601.09274.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Искусственный интеллект в университете: кто за кого работу делает?
- Безопасность генерации изображений: новый вектор управления
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый импульс для несбалансированных данных
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Редактирование изображений по запросу: новый уровень точности
- Умная экономия: Как сжать ИИ без потери качества
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2026-01-15 20:52