Автор: Денис Аветисян
Новая система DeepResearchEval позволяет комплексно оценивать качество и достоверность отчетов, созданных интеллектуальными агентами, расширяя возможности автоматизированного анализа данных.
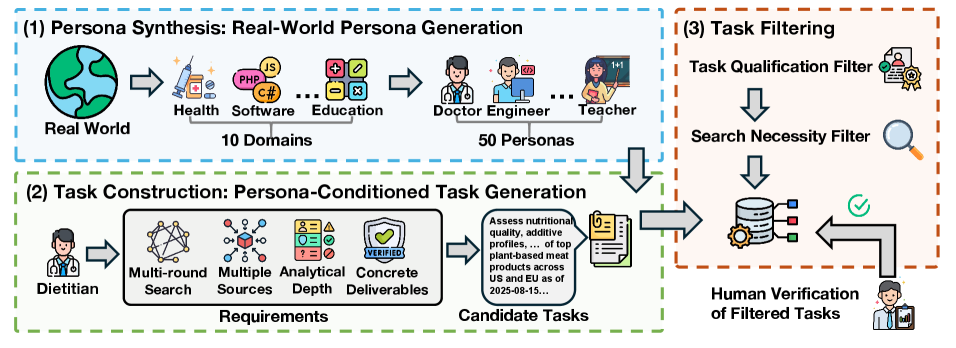
Представлен автоматизированный фреймворк для конструирования задач глубоких исследований и оценки отчетов, генерируемых агентными системами, с акцентом на фактическую достоверность.
Несмотря на широкое распространение систем глубоких исследований для многоступенчатого анализа данных, их объективная оценка остается сложной задачей. В настоящей работе, посвященной разработке DeepResearchEval: An Automated Framework for Deep Research Task Construction and Agentic Evaluation, представлен автоматизированный комплекс для генерации исследовательских задач и оценки качества генерируемых отчетов, основанный на принципах агентного подхода. Предложенная система позволяет не только создавать реалистичные задачи, требующие синтеза информации из нескольких источников, но и динамически оценивать результаты, а также верифицировать факты, даже при отсутствии цитат. Сможет ли данный фреймворк стать стандартом де-факто для оценки систем глубоких исследований и способствовать развитию более надежных и точных инструментов анализа данных?
Глубокое исследование в эпоху LLM: вызовы и ограничения
Несмотря на впечатляющие успехи в решении широкого спектра задач, современные большие языковые модели (LLM) испытывают трудности при выполнении глубоких исследований, требующих сложного, многоэтапного рассуждения. В отличие от способности генерировать текст или переводить языки, подлинное исследование предполагает не просто обработку информации, но и её критический анализ, сопоставление различных источников, выявление противоречий и формирование новых, обоснованных выводов. LLM часто демонстрируют поверхностное понимание, полагаясь на статистические закономерности в данных, а не на глубокое осмысление, что делает их неспособными к проведению действительно оригинальных исследований, требующих последовательного применения логики и критического мышления на протяжении длительного времени.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в решении разнообразных задач, простое увеличение их масштаба не позволяет эффективно справляться с задачами, требующими глубокого исследования и проверки информации из внешних источников. Существующие модели склонны к генерации правдоподобных, но не всегда достоверных ответов, особенно когда требуется синтез знаний из различных областей и сопоставление с актуальными данными. Необходим принципиально новый подход, сочетающий в себе возможности LLM с механизмами внешнего поиска, верификации фактов и логического вывода, чтобы обеспечить надежность и точность результатов исследований. Такой подход позволит преодолеть ограничения существующих моделей и открыть новые горизонты в области автоматизированного анализа данных и научных открытий.
DeepResearchEval: Автоматизация глубокого анализа и оценки
DeepResearchEval представляет собой автоматизированную платформу, предназначенную для создания комплексных исследовательских заданий и оценки сгенерированных отчетов. Система позволяет автоматизировать процесс формирования заданий, требующих глубокого анализа информации, и предоставляет инструменты для объективной оценки качества полученных результатов. Автоматизация включает в себя генерацию задач, сбор релевантных данных и оценку полноты и точности ответа, что позволяет проводить исследования в больших масштабах и с повышенной эффективностью. Оценка отчетов проводится на основе заранее определенных критериев, обеспечивая воспроизводимость и надежность результатов.
В основе DeepResearchEval лежит метод построения задач, ориентированный на создание персонажей (Persona-Driven Task Construction). Этот подход подразумевает разработку сценариев, в которых задача формулируется с точки зрения конкретного пользователя с определенными потребностями и знаниями. Для этого создаются детальные профили персонажей, определяющие их мотивацию, контекст и ожидания от исследования. Такая методология позволяет генерировать сложные, реалистичные сценарии, требующие от системы не просто извлечения информации, а проведения глубокого анализа и синтеза данных из различных источников для удовлетворения специфических потребностей заданного персонажа. Это обеспечивает более точную оценку способности системы к проведению полноценного исследовательского процесса.
В рамках DeepResearchEval используется фильтр квалификации задач (Task Qualification Filter), который позволяет отбирать наиболее сложные и требующие глубокого анализа задания. Изначально формируется набор из 200 задач, из которых после фильтрации остается 100. Критерием отбора является необходимость привлечения внешних источников информации и проведения многостороннего анализа для получения достоверного ответа. Данный подход гарантирует, что отобранные задачи требуют не простого поиска фактов, а синтеза информации из различных источников и критической оценки ее достоверности.
Оценка глубины исследования: выходим за рамки простых метрик
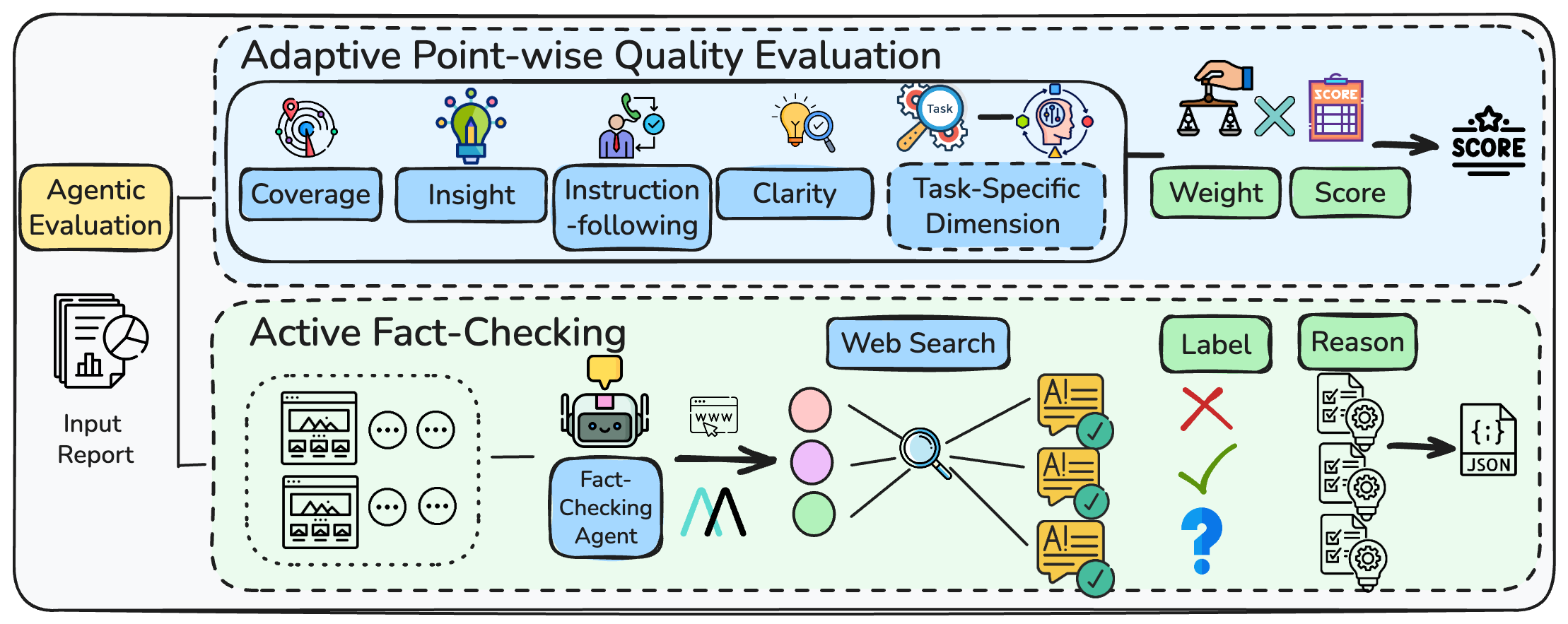
Адаптивная точечная оценка качества (Adaptive Point-wise Quality Evaluation) предполагает комбинирование общих и специфичных для задачи измерений для получения детализированной оценки. В отличие от традиционных метрик, которые фокусируются на едином показателе, данный подход учитывает различные аспекты качества, такие как релевантность, согласованность, информативность и грамматическая корректность, а также специфические требования конкретной задачи, например, точность ответа на вопрос или качество генерируемого текста. Это позволяет получить более полную и нюансированную оценку, учитывающую все важные характеристики ответа или текста, и, как следствие, повысить точность оценки в целом.
Активная проверка фактов предполагает извлечение проверяемых утверждений из текста и последующий поиск внешних доказательств для их подтверждения или опровержения. Этот процесс включает в себя автоматическое выделение конкретных фактов, формулирование запросов для поиска релевантной информации в внешних источниках, таких как базы данных, новостные статьи и научные публикации, и сравнение найденных данных с извлеченными утверждениями. Целью является предоставление объективной основы для оценки фактической точности информации, что позволяет отделить подтвержденные факты от недостоверных или требующих дополнительной проверки.
Методы адаптивной оценки качества и активной проверки фактов интегрированы в рамках Agentic Evaluation Pipeline — конвейера, использующего агентов для автоматизации процесса оценки и обеспечения его согласованности. Данный подход позволяет автоматизировать оценку, достигая 73% согласованности между автоматической проверкой фактов и аннотациями, выполненными людьми. Использование агентов обеспечивает воспроизводимость и масштабируемость оценки, минимизируя субъективность и повышая надежность результатов.
Автоматизированные системы глубоких исследований: расширяя границы знаний
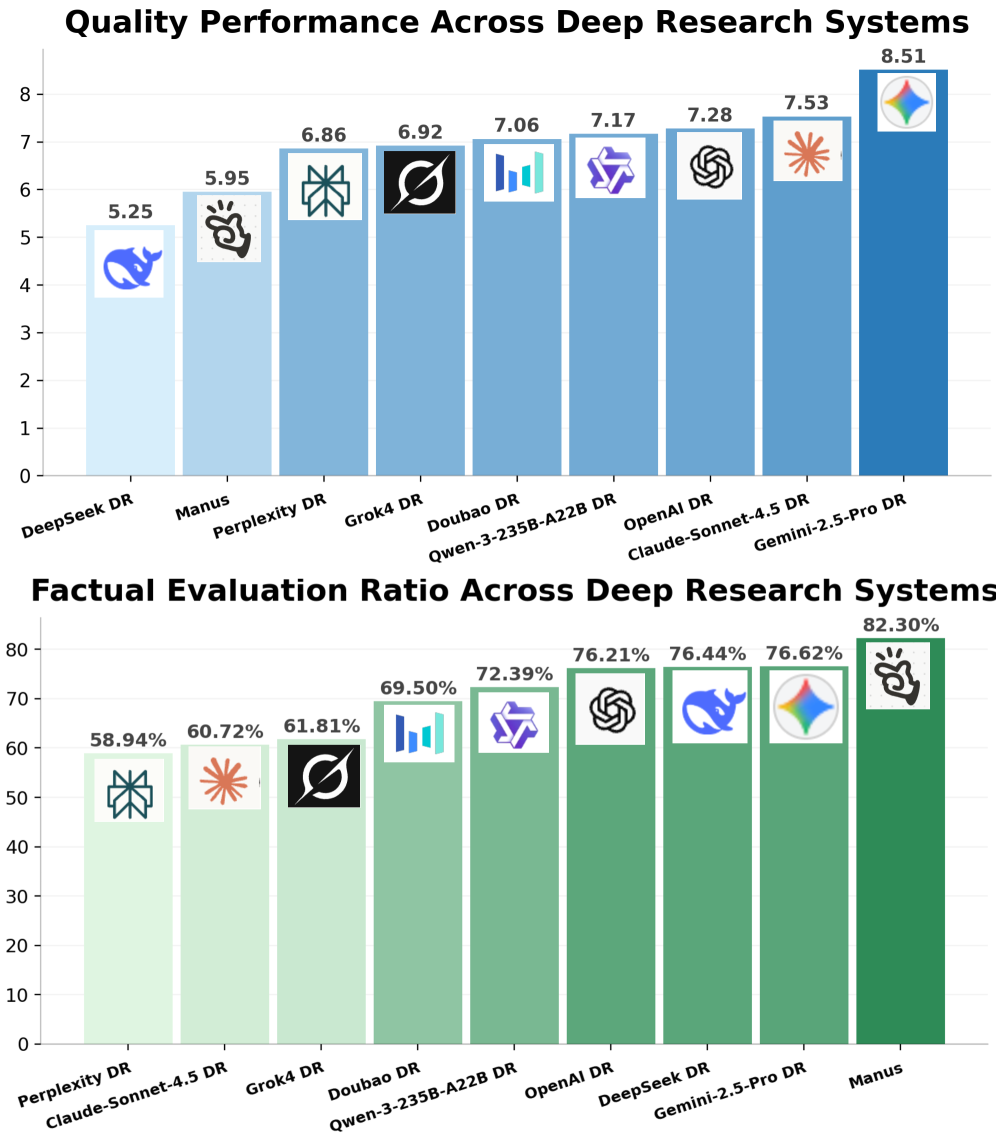
Системы глубоких исследований, функционирующие на базе DeepResearchEval, оценивают качество генерируемых отчетов, опираясь на два ключевых показателя: качество изложения и фактическую достоверность. Данный подход позволяет не просто констатировать объем полученной информации, но и критически оценивать ее обоснованность и логическую структуру. Качество отчета подразумевает связность, ясность и отсутствие противоречий в представленных аргументах, в то время как фактическая достоверность подтверждается сопоставлением с авторитетными источниками и проверкой на отсутствие ошибок или искажений. В совокупности, эти показатели формируют надежную основу для оценки ценности и применимости результатов, полученных в ходе автоматизированного исследования, обеспечивая возможность объективного сравнения различных подходов и выявления наиболее точных и обоснованных выводов.
Современные автоматизированные системы глубоких исследований активно используют возможности веб-браузинга для доступа к внешним источникам информации и их интеграции в формируемые отчеты. Этот подход позволяет не только повысить актуальность предоставляемых данных, но и значительно расширить охват исследуемой темы, обеспечивая комплексный анализ и всестороннее понимание вопроса. Системы автоматически анализируют множество веб-страниц, извлекая релевантные факты и аргументы, которые затем используются для подтверждения или опровержения выдвинутых гипотез, а также для построения более обоснованных выводов. Такая интеграция внешних данных обеспечивает динамическое обновление знаний и позволяет системам оставаться в курсе последних научных открытий и изменений в различных областях знаний.
Автоматизированная оценка, основанная на модели Gemini-2.5-Pro, предоставляет принципиально новый подход к проверке качества исследовательских отчетов. Вместо ручного анализа, требующего значительных временных затрат и подверженного субъективности, система способна обрабатывать в среднем 86.99 утверждений в каждом отчете. Такая масштабируемость позволяет проводить объективную оценку больших объемов информации, выявляя неточности и обеспечивая достоверность представленных данных. В результате, исследователи получают возможность быстро и эффективно верифицировать свои выводы, а читатели — быть уверенными в надежности полученных знаний. Это открывает перспективы для автоматизации процесса научной проверки и ускорения темпов развития различных областей знаний.
Наблюдая за этим стремлением к автоматизированной оценке глубины исследований, представленным в DeepResearchEval, невольно вспоминается высказывание Давида Гильберта: «В математике нет теорем, а есть лишь способы их доказательства». По сути, эта работа пытается автоматизировать процесс проверки этих самых «способов доказательства» — фактологической корректности и глубины анализа, генерируемого агентами. Ирония в том, что, автоматизируя оценку, они создают новый уровень сложности, где сама система оценки может стать источником ошибок. Особенно учитывая, что, как известно, документация к любой системе — это форма коллективного самообмана, а значит, проверка фактов в автоматическом режиме — это всегда компромисс между скоростью и точностью. Продакшен, как всегда, найдёт способ сломать элегантную теорию.
Что дальше?
Представленный фреймворк, безусловно, добавляет ещё один уровень автоматизации в бесконечную гонку за “интеллектом”. Однако, стоит помнить, что каждая автоматизированная проверка — это лишь отсрочка неизбежного столкновения с реальностью. Проверка фактов — это хорошо, но не стоит забывать, что система, способная генерировать убедительные, но ложные нарративы, рано или поздно найдёт способ обойти и эти проверки. Особенно, когда речь заходит о долгосрочных отчётах и “глубоких исследованиях” — каждый новый слой абстракции увеличивает вероятность того, что первоначальная цель исследования будет утеряна в процессе автоматической генерации.
Более того, упор на автоматизированное построение задач неизбежно столкнётся с проблемой репрезентативности. Автоматически сгенерированные задачи, какими бы сложными они ни были, рискуют отражать лишь узкий спектр предубеждений, заложенных в используемых данных и алгоритмах. А это значит, что оценка “агентных систем” останется, в лучшем случае, оценкой их способности успешно выполнять заранее предопределённые тесты, а не демонстрировать истинный интеллект.
В конечном счёте, эта работа — ещё один шаг к автоматизации оценки систем, которые, вероятно, уже сегодня создают больше шума, чем полезной информации. И это нормально. Мы не чиним продакшен — мы просто продлеваем его страдания. Следующим шагом, видимо, будет автоматизация жалоб на автоматизированную оценку.
Оригинал статьи: https://arxiv.org/pdf/2601.09688.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Язык тела под присмотром ИИ: архитектура и гарантии
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Квантовый импульс для несбалансированных данных
- Умная экономия: Как сжать ИИ без потери качества
- Редактирование изображений по запросу: новый уровень точности
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Безопасность генерации изображений: новый вектор управления
2026-01-15 20:57