Автор: Денис Аветисян
Исследователи представляют AI-NativeBench — комплексную платформу для глубокого анализа работы систем, управляемых большими языковыми моделями.
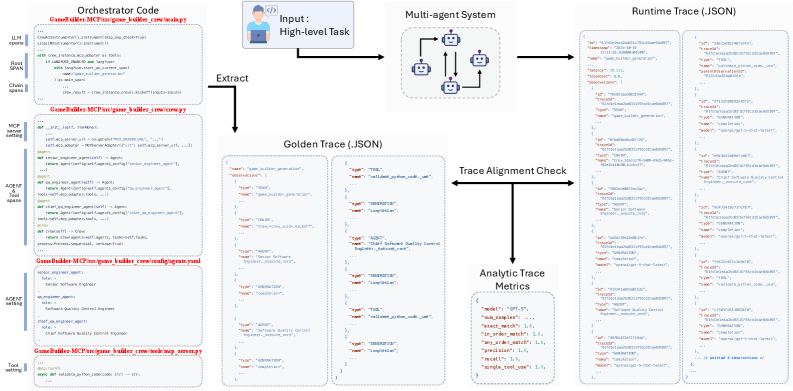
AI-NativeBench — это открытый набор инструментов для оценки надежности, производительности и экономических затрат систем, построенных на базе агентов ИИ.
Переход к архитектурам, основанным на агентах, ставит под вопрос применимость традиционных «черных ящиков» для оценки производительности и надежности систем. В данной работе представлена AI-NativeBench: An Open-Source White-Box Agentic Benchmark Suite for AI-Native Systems — первая платформа для всестороннего анализа систем на базе больших языковых моделей, использующая отслеживание распределенных транзакций. Полученные результаты выявляют неожиданные закономерности, такие как превосходство легковесных моделей в соблюдении протоколов и контрпродуктивное увеличение затрат на самовосстановление. Сможем ли мы, используя новые методы оценки, перейти от измерения возможностей моделей к построению действительно надежных AI-Native систем?
За пределами Облачной Нативности: Рождение AI-Нативных Систем
Традиционные облачные архитектуры, основанные на детерминированной логике, всё чаще оказываются недостаточными для удовлетворения требований современных приложений искусственного интеллекта. В то время как классические системы проектировались для предсказуемых рабочих нагрузок и заранее определенных сценариев, современные модели машинного обучения, особенно большие языковые модели, характеризуются вероятностной природой и постоянно меняющимся поведением. Это создает серьезные трудности для существующих инструментов мониторинга и управления, поскольку традиционные метрики и логирование оказываются неэффективными для отслеживания и диагностики проблем в системах, где результат не всегда предсказуем. В результате, разработчики сталкиваются с необходимостью создания принципиально новых подходов к проектированию и эксплуатации инфраструктуры, способной эффективно поддерживать и масштабировать сложные, вероятностные приложения искусственного интеллекта.
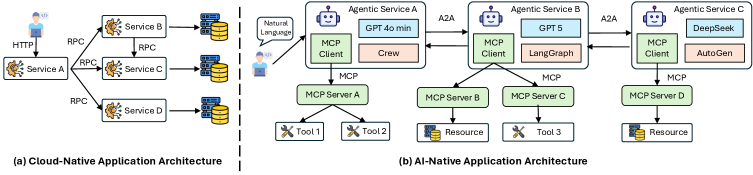
Системы, построенные на принципах искусственного интеллекта, или AI-Native, знаменуют собой фундаментальный сдвиг в архитектуре программного обеспечения, отходя от детерминированной логики традиционных облачных решений. Вместо жестко заданных инструкций, такие системы полагаются на автономных агентов и вероятностные модели, что позволяет им адаптироваться и обучаться в реальном времени. Однако эта гибкость сопряжена с новыми сложностями в области наблюдаемости и устойчивости. Отслеживание и понимание поведения системы, основанной на вероятностных расчетах, значительно сложнее, чем в случае традиционного кода. Гарантия надежности и предсказуемости в условиях неполной информации и потенциальных ошибок в моделях машинного обучения требует разработки принципиально новых подходов к мониторингу, диагностике и восстановлению после сбоев. Эффективное решение этих задач станет ключевым фактором для широкого внедрения AI-Native систем в критически важных приложениях.
Современные AI-системы в значительной степени зависят от эффективного выполнения логических выводов на основе больших языковых моделей (LLM). Однако, в отличие от традиционного программного обеспечения, эти системы обладают уникальными уязвимостями. Проблемы возникают не только из-за сложности самих моделей, но и из-за вероятностной природы их работы. Непредсказуемость результатов, зависящая от входных данных и внутренних параметров LLM, создает новые векторы атак, такие как “внедрение запросов” (prompt injection) и “отравление данных”, которые сложно обнаружить и предотвратить стандартными методами кибербезопасности. Гарантирование надежности и безопасности AI-систем требует разработки принципиально новых подходов к тестированию, мониторингу и защите, учитывающих специфику работы с вероятностными моделями и большими объемами данных.
AI-NativeBench: Взгляд Внутрь Системы
AI-NativeBench представляет собой новую систему бенчмарков, разработанную специально для оценки AI-Native систем. В отличие от традиционных “черных ящиков”, которые оценивают только входные и выходные данные, AI-NativeBench обеспечивает детальный анализ внутренней работы системы. Это достигается за счет предоставления доступа к данным о производительности на различных этапах обработки, что позволяет оценить не только общую эффективность, но и выявить конкретные узкие места и оптимизировать архитектуру системы для повышения ее надежности и масштабируемости. Такой подход позволяет перейти от простой оценки производительности к глубокому пониманию поведения системы в различных сценариях.
Для обеспечения глубокой видимости в процессе выполнения, AI-NativeBench использует распределенную трассировку и общепринятые отраслевые протоколы, такие как A2A (Application-to-Application) и MCP (Metrics Collection Pipeline). Распределенная трассировка позволяет отслеживать запросы и операции, проходящие через различные компоненты системы, выявляя задержки и зависимости. Протоколы A2A обеспечивают стандартизированный обмен данными между сервисами, а MCP — сбор и агрегацию метрик производительности, необходимых для анализа и оптимизации системы. Эта комбинация технологий позволяет детально изучить внутреннюю работу AI-Native систем и выявить потенциальные узкие места.
AI-NativeBench, благодаря акценту на наблюдаемость системы, предоставляет инструменты для выявления узких мест в производительности и подтверждения эффективности стратегий обеспечения отказоустойчивости в сложных AI-ориентированных архитектурах. Это достигается за счет детального мониторинга ключевых метрик и трассировки запросов на протяжении всей системы, позволяя разработчикам и инженерам точно определить компоненты, вызывающие задержки или сбои. Возможность анализа путей выполнения запросов и зависимостей между сервисами позволяет верифицировать, как система реагирует на различные типы отказов и как быстро восстанавливается после них, что критически важно для поддержания высокой доступности и надежности AI-приложений.
Раскрытие Системных Парадоксов: Цена, Контекст и Гетерогенность
В AI-Native системах, механизмы самовосстановления, несмотря на свою полезность, могут приводить к увеличению затрат из-за продолжительного времени выполнения. Анализ показывает, что в некоторых рабочих процессах использование токенов увеличивается до 15.4x, когда система пытается исправить ошибки самостоятельно. Данное явление, известное как “Expensive Failure Pattern”, связано с итеративным характером самовосстановления, где каждая попытка исправления требует дополнительных вычислительных ресурсов и, соответственно, большего потребления токенов. Повышенные затраты возникают даже в случаях, когда самовосстановление не приводит к успешному решению проблемы, что подчеркивает необходимость оптимизации этих механизмов для минимизации финансовых издержек.
Загрязнение контекста (Context Pollution) проявляется в снижении производительности больших языковых моделей (LLM) вследствие накопления в контекстном окне устаревшей и нерелевантной информации. По мере обработки последовательности запросов, LLM сохраняют предыдущие данные в контексте для обеспечения согласованности и релевантности ответов. Однако, увеличение объема контекста, заполненного не относящимися к текущему запросу данными, приводит к увеличению вычислительных затрат и снижению скорости обработки. Это происходит из-за того, что модель вынуждена анализировать и учитывать весь объем контекста, даже если значительная его часть не имеет отношения к текущей задаче, что требует разработки инновационных методов управления памятью и оптимизации контекстного окна для поддержания высокой производительности.
Парадокс гетерогенности проявляется в том, что использование разнородных вычислительных сред, хотя и способно ускорить сходимость алгоритмов, в AI-Native системах неизбежно влечет за собой возникновение сложностей синхронизации данных и процессов. Эти сложности, связанные с координацией работы различных аппаратных и программных компонентов, могут существенно снизить общую производительность и нивелировать потенциальные преимущества, полученные за счет ускоренной сходимости. Фактически, накладные расходы на синхронизацию могут превысить выигрыш от параллелизации вычислений, приводя к ухудшению общей эффективности системы.
К Устойчивому Искусственному Интеллекту: Адаптивная Оркестровка и Экономичный Быстрый Провал
Адаптивная оркестровка представляет собой перспективный подход к оптимизации производительности, заключающийся в динамическом выборе больших языковых моделей (LLM) и корректировке иерархий моделей в соответствии с требованиями конкретной задачи. Данный метод позволяет системе автоматически переключаться между различными LLM, учитывая их сильные и слабые стороны для различных типов задач, что позволяет максимизировать эффективность и минимизировать задержки. Корректировка иерархии моделей предполагает изменение порядка и взаимосвязи между LLM в процессе выполнения задачи, что позволяет более эффективно использовать вычислительные ресурсы и повысить точность результатов. В отличие от статических конфигураций, адаптивная оркестровка обеспечивает гибкость и масштабируемость, позволяя системе адаптироваться к изменяющимся условиям и требованиям.
Стратегия “Экономичный Быстрый Провал” (Economic Fail-Fast) представляет собой механизм повышения устойчивости, основанный на мониторинге прироста информации в процессе выполнения задачи. Система непрерывно оценивает соотношение между потребляемыми ресурсами (вычислительное время, память, энергия) и получаемым информационным выигрышем. В случае, если затраты ресурсов превышают потенциальную пользу от продолжения выполнения определенного пути решения, данный путь немедленно прерывается. Такой подход позволяет избежать необоснованно длительных и ресурсоемких вычислений, снижая общую стоимость и повышая эффективность системы, особенно в задачах, требующих обработки больших объемов данных или работы в условиях ограниченных ресурсов.
Семантические автоматические выключатели (circuit breakers) используют модули верификации для обнаружения нарушения логических ограничений в процессе выполнения задач. Эти модули непрерывно проверяют соответствие промежуточных результатов и выводов заданным логическим правилам и условиям. При обнаружении несоответствия, модуль верификации инициирует прерывание текущего пути выполнения, предотвращая распространение ошибочных данных и потенциально некорректных результатов. Такой подход позволяет повысить устойчивость системы к логическим ошибкам и неверным выводам, снижая вероятность критических сбоев и обеспечивая более надежную работу.
Парадокс Параметров: Легкие Модели и Инженерная Дисциплина
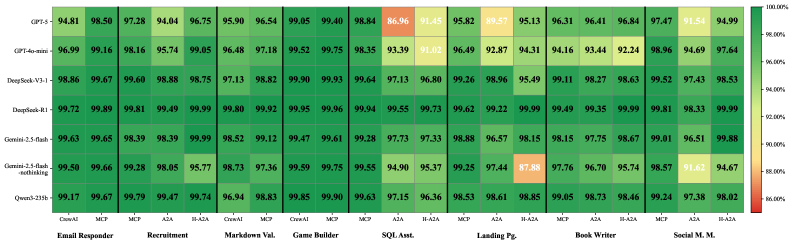
Парадокс параметров демонстрирует, что облегченные языковые модели (LLM) зачастую превосходят более крупные аналоги в соблюдении инженерных протоколов, что ставит под сомнение широко распространенное убеждение о том, что “больше — лучше”. Исследования показывают, что увеличение числа параметров не всегда приводит к повышению надежности и предсказуемости поведения модели в критически важных приложениях. Вместо этого, акцент на строгом соблюдении инженерных принципов, таких как модульное тестирование, верификация и валидация, позволяет создавать более стабильные и управляемые системы даже при использовании моделей с меньшим количеством параметров. Этот феномен подчеркивает важность не только вычислительной мощности, но и дисциплины в разработке и тестировании, что открывает новые возможности для создания эффективных и надежных решений в области искусственного интеллекта.
Исследования показывают, что в AI-системах время, затрачиваемое на выполнение логических выводов языковой моделью — так называемое время инференса — является подавляющим фактором, ограничивающим общую производительность. Анализ демонстрирует, что инференс составляет от 86.9% до 99.9% от общей задержки системы, существенно превосходя влияние сетевых задержек и времени, необходимого для сериализации данных. Это означает, что оптимизация скорости вычислений самой модели имеет решающее значение для создания быстрых и отзывчивых AI-приложений, и что простое увеличение размера модели не решит проблему, если не будет параллельной работы над повышением эффективности инференса.
Исследования демонстрируют, что в области больших языковых моделей (LLM) акцент на оптимизацию скорости вывода и строгое соблюдение инженерных принципов может оказаться более эффективным, чем простое увеличение размера модели. Полученные данные свидетельствуют о том, что даже относительно небольшие модели, тщательно спроектированные для быстродействия и надежности, способны демонстрировать производительность, сопоставимую или даже превосходящую более крупные аналоги. Это подчеркивает важность инженерной дисциплины в разработке LLM, где внимание к деталям в процессе оптимизации и развертывания может существенно повлиять на общую эффективность системы, особенно в контексте систем, ориентированных на быстрое реагирование и обработку больших объемов данных. Подобный подход позволяет достичь оптимального баланса между вычислительными затратами и производительностью, открывая новые возможности для применения LLM в различных областях.
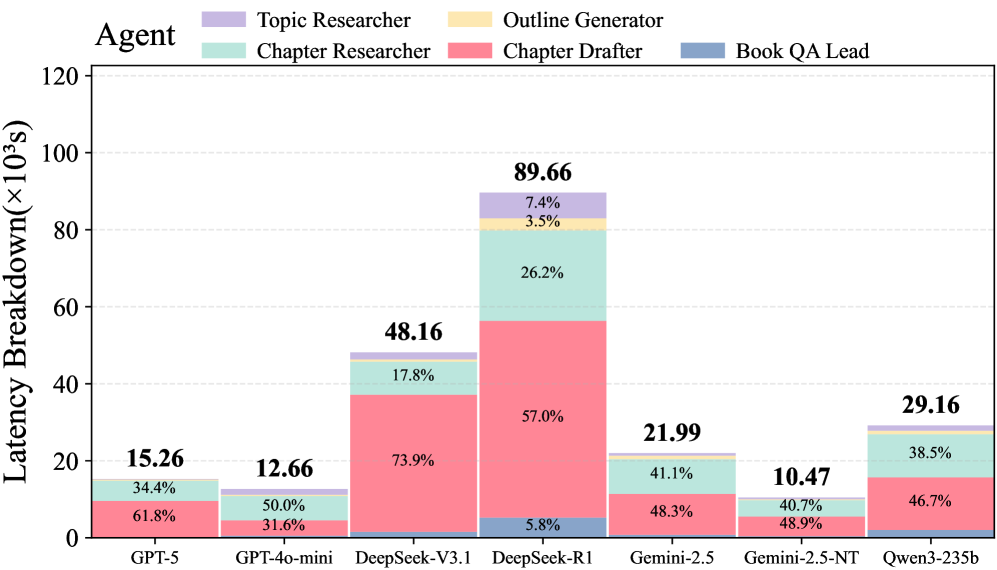
Представленный труд демонстрирует, что оценка систем, построенных на базе больших языковых моделей, требует принципиально иного подхода, чем традиционные методы. AI-NativeBench не просто измеряет производительность, но и раскрывает внутренние механизмы, выявляя узкие места и экономические издержки. Это напоминает о словах Бертрана Рассела: «Всякая система, если она достаточно сложна, неизбежно содержит в себе семена своего разрушения». Подобно саду, требующему постоянного ухода, эти системы нуждаются в прозрачности и понимании внутренних процессов для обеспечения устойчивости и избежания накопления технического долга. Подход, предложенный авторами, позволяет увидеть, как отдельные компоненты взаимодействуют, прощая ошибки друг друга, и формирует основу для создания действительно надежных и эффективных AI-native систем.
Куда Ведут Дороги?
Представленный инструментарий, AI-NativeBench, обнажает не столько ответы, сколько новые грани вопросов. Каждая зависимость, выявленная в работе агентских систем, — это обещание, данное прошлому, обещание, которое неизбежно потребует расплаты в будущем. Недостаточно измерить скорость; необходимо понять, как система сама себя чинит, когда неизбежные поломки случатся. Попытки контролировать сложность агентных систем — это иллюзия, требующая соглашения об уровне обслуживания, а не реальной власти над хаосом.
Упор на экономику токенов и прослеживаемость, безусловно, важен, но это лишь симптоматическое лечение. Истинная проблема заключается в том, что системы, построенные на базе больших языковых моделей, не проектируются, а скорее вырастают. Каждый архитектурный выбор — это пророчество о будущем сбое, и наивно полагать, что можно предвидеть все возможные пути развития этой сложной экосистемы.
Следующим шагом представляется не создание более совершенных бенчмарков, а разработка методов понимания внутренней логики этих систем, их способности к самоорганизации и адаптации. Необходимо сместить фокус с измерения производительности на изучение устойчивости и способности к восстановлению после сбоев. В конечном счете, успех не будет определяться скоростью, а способностью системы выжить в долгосрочной перспективе.
Оригинал статьи: https://arxiv.org/pdf/2601.09393.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Искусственный интеллект в университете: кто за кого работу делает?
- Безопасность генерации изображений: новый вектор управления
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый импульс для несбалансированных данных
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Редактирование изображений по запросу: новый уровень точности
- Умная экономия: Как сжать ИИ без потери качества
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2026-01-15 22:31