Автор: Денис Аветисян
Новая архитектура OpenDecoder позволяет учитывать качество извлеченных документов при генерации текста, делая ответы искусственного интеллекта более точными и устойчивыми к шуму.
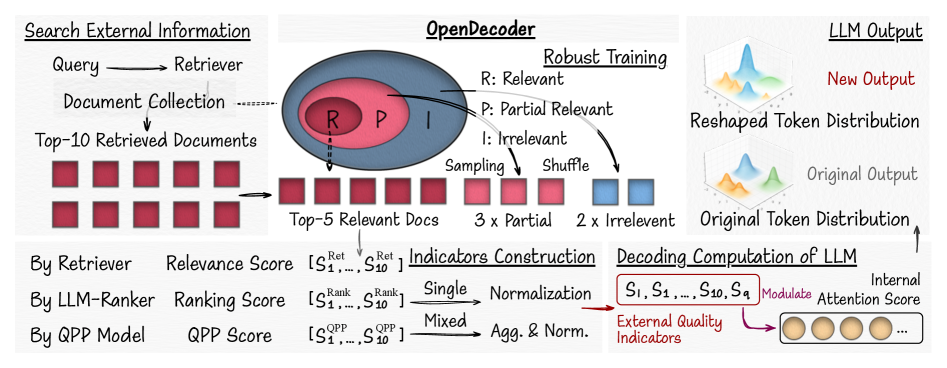
OpenDecoder — это фреймворк, использующий внешние сигналы релевантности для управления процессом декодирования больших языковых моделей в системах Retrieval-Augmented Generation.
Несмотря на значительные успехи в области генеративных моделей, качество ответов, формируемых с использованием поиска и дополнения (RAG), часто зависит от релевантности извлечённой информации. В данной работе, представленной под названием ‘OpenDecoder: Open Large Language Model Decoding to Incorporate Document Quality in RAG’, предлагается новый подход, использующий явную оценку релевантности извлечённых документов в качестве признаков для управления процессом декодирования больших языковых моделей. Эксперименты демонстрируют, что OpenDecoder повышает устойчивость RAG-систем к шумам в контексте, улучшая качество генерируемых ответов. Возможно ли дальнейшее расширение этого подхода за счет интеграции дополнительных источников информации о качестве документов и адаптации к различным задачам генерации?
Вызов Контекста в Больших Языковых Моделях
Несмотря на впечатляющую беглость речи и способность генерировать текст, современные большие языковые модели (БЯМ) часто испытывают трудности при решении задач, требующих глубокого логического мышления и точного понимания контекста. Это связано с тем, что БЯМ, по сути, оперируют статистическими закономерностями в данных, а не реальным пониманием смысла. В результате, модели могут генерировать грамматически правильные, но семантически неверные или нерелевантные ответы, особенно когда требуется учитывать сложные взаимосвязи и нюансы в предоставленной информации. Способность к точному контекстуальному анализу остается серьезным вызовом для развития действительно интеллектуальных систем обработки естественного языка.
Традиционные большие языковые модели (БЯМ) зачастую демонстрируют неэффективность при использовании внешних знаний, что приводит к генерации неправдоподобной информации, или так называемых «галлюцинаций», а также к предоставлению ответов, не соответствующих исходному запросу. Особенно остро эта проблема проявляется при обработке сложных запросов, требующих глубокого понимания контекста и интеграции информации из различных источников. Модели, неспособные эффективно отбирать и использовать релевантные знания, склонны к домыслам и неточностям, что снижает надежность и полезность генерируемого текста. В результате, даже обладая впечатляющей способностью к генерации связного текста, такие модели могут давать ошибочные или бессмысленные ответы на вопросы, требующие фактической точности и контекстуального понимания.
Эффективный поиск релевантной информации является ключевым фактором для работы больших языковых моделей, однако простое увеличение их размера не решает эту проблему. Несмотря на впечатляющие результаты, достигаемые за счет масштабирования, модели сталкиваются с ограничениями в обработке и использовании внешних знаний. Увеличение объема параметров приводит к экспоненциальному росту вычислительных затрат и энергопотребления, не гарантируя при этом значительного улучшения в понимании контекста и точности ответов. Более того, простое увеличение размера не позволяет моделям эффективно отбирать и фокусироваться на наиболее важной информации из огромного объема данных, что приводит к галлюцинациям и нерелевантным ответам. Таким образом, необходимы инновационные подходы, направленные на повышение эффективности поиска и использования релевантной информации, а не на дальнейшее увеличение размера моделей.
Современные методы работы с большими языковыми моделями зачастую не предусматривают чёткого механизма для фокусировки внимания на наиболее релевантных фрагментах извлечённой информации. Несмотря на способность моделей обрабатывать большие объёмы текста, они сталкиваются с трудностями в определении, какие именно части контекста являются ключевыми для ответа на конкретный запрос. Это приводит к тому, что модель может упустить важные детали или, напротив, уделить внимание несущественным фактам, что негативно сказывается на точности и осмысленности генерируемых ответов. Разработка систем, способных эффективно направлять внимание модели на наиболее значимые части контекста, является важной задачей для повышения её способности к глубокому пониманию и логическому выводу.
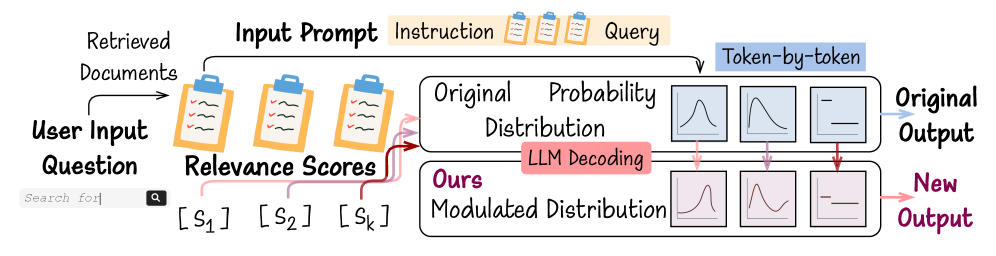
RAG и Обещание Управляемого Декодирования
Генеративные модели больших языков (LLM) часто сталкиваются с ограничениями, связанными с объемом и актуальностью знаний, заложенных в процессе их обучения. Метод Retrieval-Augmented Generation (RAG) предлагает решение этой проблемы путем интеграции внешних источников знаний непосредственно в процесс генерации текста. Вместо того, чтобы полагаться исключительно на внутренние параметры модели, RAG извлекает релевантную информацию из внешних баз данных или документов и использует её в качестве контекста для формирования ответа. Это позволяет модели генерировать более точные, информативные и актуальные ответы, особенно в тех случаях, когда требуются знания, выходящие за рамки её первоначального обучения. Фактически, RAG расширяет возможности LLM, позволяя им динамически использовать и синтезировать информацию из внешних источников в процессе генерации текста.
Простое извлечение релевантных документов недостаточно для эффективного использования внешних знаний большими языковыми моделями (LLM). Необходим механизм, позволяющий LLM интеллектуально интегрировать полученную информацию в процесс генерации. Проблема заключается в том, что LLM, как правило, не способны автоматически определять, какие части извлеченных документов наиболее важны для формирования точного и релевантного ответа. Без соответствующего механизма, LLM может игнорировать ключевую информацию или неправильно интерпретировать ее, что приводит к снижению качества генерируемого текста и фактическим ошибкам. Таким образом, требуется способ управления вниманием LLM и направления его на наиболее значимые фрагменты извлеченных документов.
OpenDecoder представляет собой новый фреймворк, который модифицирует процесс декодирования больших языковых моделей (LLM) посредством использования явных сигналов релевантности, извлеченных из найденных документов. В отличие от стандартного подхода, где LLM полагается исключительно на свои внутренние знания, OpenDecoder интегрирует информацию из внешних источников непосредственно в процесс генерации текста. Это достигается путем модуляции механизма внимания LLM на основе сигналов релевантности, что позволяет модели более эффективно фокусироваться на наиболее важных частях извлеченного контекста. В результате, OpenDecoder направляет процесс декодирования, обеспечивая генерацию более точных и контекстуально релевантных ответов.
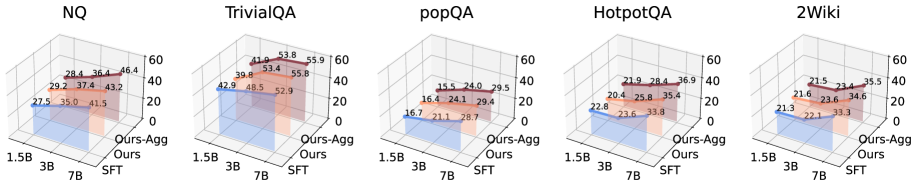
Направленное управление механизмом внимания большой языковой модели (LLM) с использованием релевантных сигналов, полученных из извлеченных документов, позволяет повысить качество генерируемых ответов и улучшить понимание контекста. Экспериментальные результаты демонстрируют стабильно более высокую метрику F1 на пяти различных наборах данных: NQ, TriviaQA, PopQA, HotpotQA и 2WikiMultiHopQA, что подтверждает эффективность данного подхода к улучшению производительности LLM в задачах, требующих использования внешних знаний.
Улучшение Поиска с Помощью Релевантности и Устойчивости
Эффективный поиск информации основывается на выявлении K наиболее релевантных документов в ответ на запрос пользователя. Этот процесс реализуется посредством методов, таких как Top-K Retrieval, которые позволяют ранжировать документы по степени соответствия запросу и выбирать только лучшие K результатов. Алгоритмы Top-K Retrieval оценивают релевантность, используя различные метрики, включая векторное сходство, частоту ключевых слов и другие факторы, определяющие степень соответствия между запросом и содержимым документа. Выбор оптимального значения K является важным параметром, влияющим на точность и полноту результатов поиска.
В OpenDecoder оценка качества извлеченных документов осуществляется не только на основе соответствия ключевым словам запроса, но и с использованием двух показателей: Relevance Score и Semantic Score. Relevance Score определяет степень соответствия документа запросу на основе традиционных методов поиска, например, TF-IDF. Semantic Score, в свою очередь, оценивает семантическую близость между запросом и документом, учитывая смысл и контекст, что позволяет выявлять релевантные документы, даже если они не содержат точных совпадений по ключевым словам. Комбинирование этих двух оценок позволяет более точно ранжировать документы и повысить эффективность поиска.
Для повышения устойчивости модели к шуму и нерелевантной информации применяется обучение на устойчивость (Robustness Training). Этот подход направлен на улучшение способности модели игнорировать вводящие в заблуждение сигналы и фокусироваться на наиболее значимых данных. Важно отметить, что экспериментально установлено, что изменение порядка документов в обучающей выборке — то есть, обратный порядок — приводит к повышению эффективности модели, что свидетельствует о её способности к обобщению и адаптации к различным представлениям данных.
Нормализация является ключевым компонентом процесса декодирования, обеспечивающим стабильность и предотвращающим перекос в оценке релевантности. Масштабирование значений релевантности и семантических оценок позволяет привести их к сопоставимому диапазону, что особенно важно при объединении различных метрик. Без нормализации, компоненты с большими абсолютными значениями могут доминировать в итоговой оценке, игнорируя вклад других, возможно, более значимых факторов. Применение техник нормализации, таких как min-max масштабирование или Z-score стандартизация, гарантирует, что каждый фактор вносит пропорциональный вклад в определение релевантности документа, повышая общую точность и надежность системы извлечения информации.
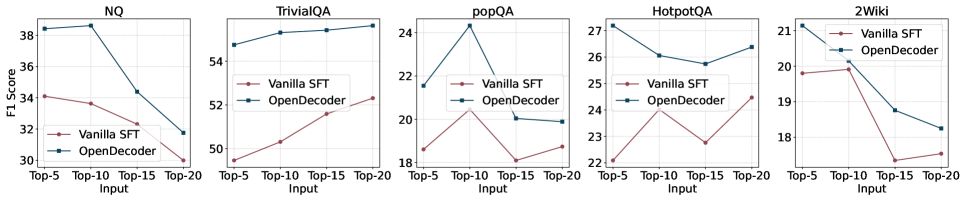
Улучшение Производительности LLM посредством Управляемого Генерации
В основе OpenDecoder лежит инновационный подход к управлению механизмом внимания больших языковых моделей (LLM). Система использует внешние индикаторы, полученные из релевантных документов, для целенаправленной модуляции внимания модели. Вместо того, чтобы полагаться исключительно на внутренние параметры, OpenDecoder динамически корректирует, на какие части входных данных следует обращать особое внимание. Этот процесс позволяет LLM более эффективно извлекать и использовать информацию из контекста, что приводит к генерации более связных, точных и релевантных ответов. По сути, внешние индикаторы выступают в роли своеобразных «подсказок», направляющих внимание модели на наиболее важные фрагменты информации, существенно повышая качество генерируемого текста.
Благодаря возможности направлять внимание на наиболее значимую информацию, модель демонстрирует существенное улучшение в генерации ответов. Этот механизм позволяет отфильтровать несущественные детали и сконцентрироваться на ключевых аспектах запроса, что приводит к более связным, точным и релевантным ответам. В результате, генерируемый текст лучше соответствует контексту, избегает противоречий и предоставляет пользователю именно ту информацию, которая необходима для решения поставленной задачи. Такой подход особенно важен при обработке сложных запросов, требующих глубокого понимания контекста и способности к логическому выводу.
Дополнительное повышение эффективности больших языковых моделей достигается посредством контролируемой тонкой настройки и настройки на основе инструкций. Эти методы позволяют модели более точно интерпретировать и использовать предоставленный контекст, что критически важно для генерации связных и релевантных ответов. Контролируемая тонкая настройка, основанная на размеченных данных, позволяет модели изучать корреляции между входными данными и ожидаемыми результатами. В свою очередь, настройка на основе инструкций фокусируется на обучении модели следовать конкретным указаниям и форматам, что значительно улучшает качество генерируемого текста и повышает его полезность для пользователя. Оба подхода в совокупности способствуют формированию более адаптивной и интеллектуальной системы, способной решать сложные задачи, требующие глубокого понимания контекста.
Исследования показали заметное повышение качества генерируемого текста, особенно при обработке сложных запросов, требующих глубокого понимания контекста. Установлено, что более крупные языковые модели демонстрируют последовательно лучшие результаты в таких задачах, эффективно используя предоставленный контекст для формирования связных и точных ответов. Этот прогресс особенно заметен при решении вопросов, требующих анализа большого объема информации и выявления взаимосвязей между различными фактами, что подтверждает важность масштабирования моделей и улучшения их способности к контекстуализации.
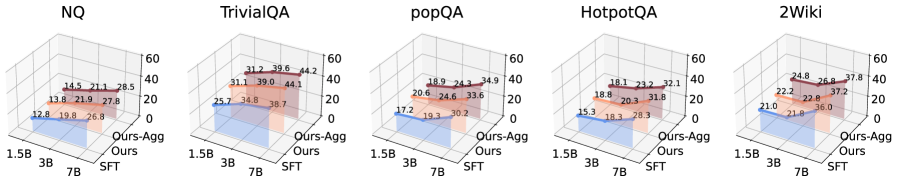
Будущие Направления: К Адаптивным и Устойчивым RAG-Системам
Будущие исследования направлены на внедрение предсказания производительности запроса, что позволит динамически корректировать стратегию поиска информации в зависимости от сложности самого запроса. Данный подход предполагает, что система сможет оценивать, насколько сложным является вопрос, и, исходя из этой оценки, выбирать оптимальный метод извлечения релевантных данных. Например, для простых запросов может использоваться быстрый, но менее точный поиск, а для сложных — более глубокий и тщательный анализ, требующий больше вычислительных ресурсов. Такая адаптивность позволит значительно повысить эффективность системы поиска и обеспечить более точные и релевантные ответы, особенно в случаях, когда запросы содержат сложные концепции или требуют анализа большого объема информации. Предполагается, что предсказание производительности запроса станет ключевым элементом в создании интеллектуальных систем поиска, способных самостоятельно адаптироваться к потребностям пользователя.
Исследования направлены на разработку адаптивных схем взвешивания внешних индикаторов, что позволит значительно повысить устойчивость и эффективность OpenDecoder. Вместо использования фиксированных весов для каждого индикатора, предлагается динамически корректировать их значимость в зависимости от конкретного запроса и контекста. Такой подход позволит системе более гибко реагировать на неоднозначные или сложные запросы, а также снизить влияние шума и нерелевантной информации. Разработка алгоритмов, способных оценивать надежность и релевантность каждого индикатора в реальном времени, станет ключевым фактором для достижения большей точности и надежности в извлечении знаний и генерации ответов. В результате, система сможет более эффективно использовать доступные ресурсы и адаптироваться к изменяющимся условиям, обеспечивая более качественные и релевантные результаты.
Перспективы применения данной архитектуры выходят далеко за рамки текущих задач, открывая новые горизонты в области знаний-интенсивной обработки естественного языка. Исследования показывают, что адаптация фреймворка к различным предметным областям, таким как медицина, юриспруденция или финансовый анализ, способна значительно повысить эффективность извлечения и использования специализированных знаний. Более того, применение в новых типах задач, включая ответы на сложные вопросы, генерацию креативных текстов и поддержку принятия решений, позволит создать интеллектуальные системы, способные не только понимать информацию, но и эффективно применять её для решения конкретных проблем. Таким образом, расширение области применения данной разработки является ключевым фактором для реализации потенциала знаний-интенсивных моделей и создания более интеллектуальных и полезных систем.
Представленная работа открывает перспективы для создания систем извлечения и генерации ответов (RAG), которые отличаются не только повышенной точностью и надежностью, но и способностью к адаптации и интеллектуальному поведению. Вместо статичных моделей, ограниченных заранее заданными параметрами, разрабатываемый подход закладывает основу для систем, способных динамически подстраиваться под сложность запроса и контекст ситуации. Это означает, что будущие RAG-системы смогут самостоятельно оценивать качество извлеченных данных, корректировать стратегию поиска информации и, как следствие, предоставлять более релевантные и обоснованные ответы. Подобная гибкость и интеллектуальность позволит преодолеть ограничения существующих систем и приблизиться к созданию искусственного интеллекта, способного эффективно решать сложные задачи, требующие глубокого понимания и анализа информации.
Без точного определения задачи любое решение — шум. Данное исследование, представляя OpenDecoder, подчеркивает необходимость строгого подхода к проблеме надежности в системах Retrieval-Augmented Generation (RAG). Авторы предлагают не просто улучшить производительность, а создать механизм, напрямую использующий внешние сигналы релевантности для модуляции процесса декодирования больших языковых моделей. Этот подход, направленный на повышение устойчивости в условиях зашумленных данных, соответствует принципу доказательства корректности алгоритма, а не просто его работоспособности на тестовых примерах. Как отмечал Анри Пуанкаре: «Чистая математика — это единственная наука, в которой мы можем быть уверены, что не ошибаемся». Это особенно актуально при разработке сложных систем, где даже небольшая ошибка может привести к значительным последствиям.
Что дальше?
Представленная работа, безусловно, демонстрирует потенциал прямого влияния внешних сигналов релевантности на процесс декодирования больших языковых моделей. Однако, пусть N стремится к бесконечности — что останется устойчивым? Улучшение производительности в шумной среде — это лишь частный случай. Более фундаментальным вопросом является природа самой «релевантности». Как обеспечить, чтобы сигнал релевантности не стал очередным источником предвзятости, лишь замаскированным под объективность? Не станет ли стремление к «устойчивости» в шумной среде просто заменой одного типа ошибки на другой, более тонкий и труднообнаружимый?
Очевидно, что необходимы дальнейшие исследования в области формальной верификации алгоритмов оценки релевантности. Недостаточно просто демонстрировать улучшения на тестовых наборах данных; необходимо доказать, что предлагаемый подход действительно уменьшает вероятность генерации неверной или вводящей в заблуждение информации. Попытки интеграции формальных методов в процесс обучения больших языковых моделей — сложная, но неизбежная задача. Без этого, все усовершенствования останутся эмпирическими, а не теоретически обоснованными.
В конечном итоге, успех подобных подходов зависит не от сложности архитектуры или размера модели, а от способности сформулировать четкие и непротиворечивые критерии истинности и релевантности. Именно в этой области кроется наибольший вызов и, возможно, самая большая надежда на создание действительно интеллектуальных систем.
Оригинал статьи: https://arxiv.org/pdf/2601.09028.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Язык тела под присмотром ИИ: архитектура и гарантии
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Квантовый импульс для несбалансированных данных
- Умная экономия: Как сжать ИИ без потери качества
- Редактирование изображений по запросу: новый уровень точности
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Безопасность генерации изображений: новый вектор управления
2026-01-16 01:51