Автор: Денис Аветисян
Новое исследование показывает, что генерация понятных объяснений для моделей машинного обучения, основанных на изменении входных данных, может быть вычислительно непосильной задачей.
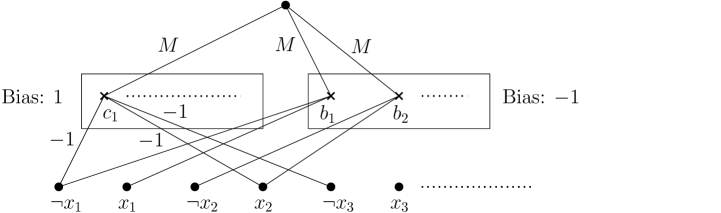
Анализ вычислительной сложности алгоритмов генерации контрфактических и полуфактических объяснений, демонстрирующий NP-трудность и трудность аппроксимации даже для простых моделей.
Несмотря на растущую потребность в интерпретируемых моделях машинного обучения, вычислительная сложность построения объяснений часто остается вне поля зрения. В работе ‘On the Hardness of Computing Counterfactual and Semifactual Explanations in XAI’ проводится анализ вычислительной сложности генерации контрфактических и семифактических объяснений, демонстрируя, что во многих случаях поиск таких объяснений является NP-трудной задачей и трудно поддается аппроксимации. Полученные результаты показывают, что даже для относительно простых моделей построение понятных объяснений может потребовать неприемлемых вычислительных ресурсов. Какие альтернативные подходы к генерации объяснений могут обеспечить компромисс между точностью, интерпретируемостью и вычислительной эффективностью?
Пределы Объяснения: Вычислительная Невозможность
Несмотря на впечатляющую точность, многие современные модели машинного обучения представляют собой, по сути, “черные ящики”, не предоставляющие ясных объяснений своих прогнозов. Это означает, что даже при верном ответе, трудно понять, какие именно факторы и закономерности привели к данному результату. Такая непрозрачность является серьезной проблемой, особенно в критически важных областях, где требуется не только правильный ответ, но и понимание логики его получения, например, при диагностике заболеваний или принятии финансовых решений. Отсутствие объяснимости снижает доверие к моделям и затрудняет выявление возможных ошибок или предвзятостей, скрытых в процессе обучения.
Генерация объяснений для сложных моделей машинного обучения часто требует значительных вычислительных ресурсов и времени. Это связано с тем, что поиск минимальных изменений во входных данных, которые приводят к изменению предсказания модели, представляет собой комбинаторную задачу, сложность которой экспоненциально растет с увеличением размерности пространства признаков и числа параметров модели. Даже для относительно небольших сетей, процесс поиска может занимать часы или дни на мощных вычислительных платформах, а для глубоких нейронных сетей с миллионами параметров — становиться практически невозможным. Такая вычислительная дороговизна ограничивает возможность использования объяснимого искусственного интеллекта в реальных приложениях, где требуется оперативное предоставление интерпретаций, например, в системах поддержки принятия решений или автоматизированном контроле.
Отсутствие прозрачности в работе алгоритмов машинного обучения создает серьезные препятствия для их внедрения в критически важные сферы, такие как здравоохранение и финансы. Врачи и финансовые аналитики, принимающие решения, влияющие на жизнь и благосостояние людей, нуждаются в четком понимании логики, лежащей в основе прогнозов моделей. Невозможность объяснить, почему алгоритм пришел к определенному выводу, подрывает доверие к системе и ограничивает ее применение, даже если точность прогнозов высока. Это особенно актуально в ситуациях, требующих юридической ответственности или этической оценки, где необходима возможность проверки и обоснования принятых решений. В конечном итоге, недостаток объяснимости становится ключевым фактором, сдерживающим широкое распространение передовых технологий в областях, где цена ошибки чрезвычайно высока.
Суть проблемы объяснимости сложных моделей машинного обучения заключается в вычислительной сложности поиска минимальных изменений входных данных, способных существенно повлиять на предсказание. Этот процесс, требующий перебора огромного пространства возможных вариаций, быстро становится непосильным даже для современных вычислительных ресурсов. По сути, задача сводится к выявлению наиболее значимых факторов, определяющих решение модели, что равносильно поиску «иглы в стоге сена» — необходимо идентифицировать небольшое подмножество признаков, изменение которых приводит к заметному изменению результата. Такая сложность поиска ограничивает возможность получения понятных и достоверных объяснений, особенно для моделей с большим количеством параметров и сложной архитектурой, препятствуя их внедрению в критически важные области, где прозрачность и обоснованность решений являются первостепенными.
За Пределами Верных Объяснений: Полуфактические и Контрфактические Подходы
Полуфактические объяснения представляют собой прагматичную альтернативу, позволяющую выявить изменения входных данных, которые не влияют на предсказание модели. Этот подход основан на выявлении ключевых признаков, поддерживающих исходный результат, путем поиска минимального набора изменений, которые сохраняют предсказание неизменным. В отличие от контрфактических объяснений, которые исследуют изменения, необходимые для изменения предсказания, полуфактические объяснения фокусируются на стабильных аспектах модели, предоставляя информацию о тех признаках, которые действительно важны для данного результата и не требуют модификации.
Объяснения, основанные на принципе минимальных достаточных причин (MSR), позволяют выделить наименьший набор признаков, определяющих предсказание модели. MSR предполагает, что для объяснения результата достаточно указать только те признаки, изменение которых приведет к изменению предсказания, исключая избыточные. Этот подход основан на поиске подмножества признаков, которое является одновременно достаточным для получения исходного результата и минимальным по объему, что обеспечивает более компактное и интерпретируемое объяснение. Фактически, MSR стремится определить наиболее релевантные признаки, игнорируя те, которые не оказывают существенного влияния на результат, тем самым упрощая понимание логики принятия решений моделью.
Контрфактические объяснения исследуют минимальные изменения входных данных, необходимые для изменения предсказания модели, представляя собой сценарии типа “что если”. В отличие от объяснений, выявляющих факторы, влияющие на текущий результат, контрфактические объяснения фокусируются на тех изменениях, которые привели бы к другому исходу. Это достигается путем поиска ближайшей альтернативной точки данных, для которой модель выдает отличное предсказание, и выявления разницы между исходными и измененными данными. Такой подход позволяет понять, какие конкретные факторы необходимо изменить, чтобы добиться желаемого результата, предоставляя пользователю возможность активно влиять на предсказания модели.
Оба подхода — полуфактические и контрфактические объяснения — направлены на предоставление практических выводов, несмотря на то, что представляют собой лишь приближения к реальному процессу принятия решений моделью. Важно понимать, что модели машинного обучения часто функционируют как «черные ящики», и точное воспроизведение их логики невозможно. Поэтому, данные методы не стремятся к абсолютному отражению внутренней работы модели, а фокусируются на выявлении минимального набора факторов, влияющих на предсказание, или изменений, необходимых для его изменения, что позволяет пользователям получить полезную информацию и принять обоснованные решения, даже при отсутствии полного понимания логики модели.
Вычислительная Цена Объяснения: NP-Трудность и Её Последствия
Задача поиска оптимальных контрфактических объяснений доказана как NP-трудная, что означает её вычислительную сложность сопоставима со сложностью задачи 3-SAT (трех-удовлетворимости). NP-трудность указывает на то, что не существует известного алгоритма, способного найти оптимальное решение за полиномиальное время, и время вычислений растёт экспоненциально с увеличением числа признаков. По сути, это означает, что для больших наборов данных поиск точного контрфактического объяснения становится практически невозможным из-за чрезмерных вычислительных затрат. Следовательно, при решении задач объяснимого ИИ (XAI) часто приходится прибегать к приближённым алгоритмам или эвристикам, жертвуя оптимальностью ради приемлемого времени вычислений.
Сложность поиска оптимальных контрфактических объяснений растет экспоненциально с увеличением количества признаков, что делает нахождение точного решения непрактичным для многих реальных задач. Это означает, что время вычислений, необходимое для определения минимального набора изменений входных данных, приводящих к желаемому результату модели, увеличивается непропорционально быстро с ростом размерности пространства признаков. В результате, для задач с большим количеством признаков, поиск точного контрфактического объяснения может потребовать неприемлемо больших вычислительных ресурсов и времени, что ограничивает применимость методов, требующих полного перебора вариантов.
Анализ вычислительной сложности предоставляет формальные инструменты для оценки масштабируемости различных методов объяснения. Эти инструменты, заимствованные из теории алгоритмов, позволяют оценить, как время вычислений растет с увеличением количества признаков и сложности модели. Применительно к моделям машинного обучения, таким как деревья решений, сети с функциями активации ReLU и алгоритм k-ближайших соседей, анализ вычислительной сложности позволяет определить границы применимости различных методов объяснения и выявить потенциальные узкие места в масштабируемости. Оценка сложности вычислений, выражаемая в нотации «O» (например, O(n^2)), позволяет сравнить эффективность различных подходов и выбрать наиболее подходящий для конкретной задачи и имеющихся ресурсов.
В работе строго доказано, что не существует алгоритма, работающего за полиномиальное время, способного найти 2p(n)-аппроксимацию для задачи WACHTER-CFE. Это подтверждает присущую вычислительную сложность поиска контрфактических объяснений. В частности, доказана NP-трудность вычисления робастных контрфактических объяснений, а также оптимальных контрфактических объяснений для ряда моделей машинного обучения, что означает экспоненциальный рост времени вычислений с увеличением числа признаков и делает точное решение практически невозможным для многих реальных задач.
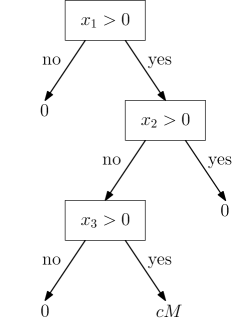
К Надёжным и Правдоподобным Объяснениям: Баланс Точности и Эффективности
Исследования показывают, что надёжность объяснений, предоставляемых системами искусственного интеллекта, существенно возрастает при акценте на устойчивых контрфактах. В шумных и непредсказуемых условиях, когда входные данные могут незначительно изменяться, традиционные объяснения часто оказываются хрупкими и недействительными. Устойчивые контрфакты, напротив, представляют собой объяснения, которые сохраняют свою валидность даже при небольших возмущениях входных данных. Это достигается за счет поиска альтернативных сценариев, которые, несмотря на незначительные изменения, приводят к аналогичному результату. Такой подход позволяет системе демонстрировать более стабильные и предсказуемые объяснения, что особенно важно в критически важных приложениях, где надёжность является первостепенной задачей. Практически это означает, что вместо поиска единственного «правильного» объяснения, система ищет набор альтернативных объяснений, которые остаются допустимыми в рамках определенной степени неопределённости.
Исследования показывают, что контрфактические объяснения, соответствующие реальным ограничениям и законам предметной области, значительно повышают их понятность и применимость на практике. Если объяснение предлагает изменение входных данных, которое физически невозможно или нереалистично в данной ситуации, оно теряет свою ценность для пользователя. Приоритезация правдоподобных контрфактов, учитывающих контекст и ограничения, позволяет создавать более осмысленные и полезные объяснения, которые могут быть непосредственно использованы для принятия решений или улучшения работы системы. Вместо абстрактных изменений, предлагаемые корректировки становятся практически реализуемыми, что способствует доверию к объяснению и облегчает его интеграцию в реальные процессы.
Несмотря на то, что достижение абсолютно совершенных объяснений представляется невозможным из-за присущей сложности систем искусственного интеллекта и неполноты данных, предложенные стратегии — акцент на устойчивых и правдоподобных контрфактических объяснениях — открывают практичный путь к созданию надёжного и полезного ИИ. Отказ от стремления к недостижимому идеалу позволяет сосредоточиться на разработке методов, которые, признавая ограничения вычислительных ресурсов и неизбежный шум в данных, всё же предоставляют ценные и понятные объяснения. Такой подход позволяет создавать системы, которым можно доверять в принятии решений, даже если эти решения не основаны на абсолютно точных, а на достаточно надёжных и обоснованных объяснениях.
Исследования в области объяснимого искусственного интеллекта (XAI) сталкиваются с фундаментальными вычислительными ограничениями. Теоретически доказано, что не существует полиномиального алгоритма, способного аппроксимировать решение задачи WACHTER-CFE с точностью до 2^{p(n)}. Это означает, что стремление к абсолютно точным и всеобъемлющим объяснениям может оказаться непрактичным из-за экспоненциального роста вычислительных затрат. Поэтому, разработка методов объяснения, учитывающих эти ограничения, становится ключевой задачей. Вместо погони за недостижимым совершенством, акцент делается на создании практичных и эффективных инструментов, способных предоставить ценные сведения без чрезмерной нагрузки на вычислительные ресурсы. Такой подход позволяет создавать системы XAI, которые не только понятны, но и применимы в реальных условиях, обеспечивая баланс между точностью, эффективностью и вычислительной сложностью.
«`html
Исследование, представленное в статье, демонстрирует, что даже поиск простых объяснений для моделей машинного обучения может оказаться вычислительно сложной задачей, приближающейся к NP-трудности. Это подтверждает идею о том, что реальность, подобно сложной программе, скрывает в себе множество неразрешимых задач. Как однажды заметил Джон фон Нейман: «В науке не бывает абсолютно точных ответов, есть лишь более или менее полезные приближения». Подобно тому, как алгоритмы приближения используются для решения NP-трудных задач, так и в XAI приходится искать компромиссы между точностью и вычислительной сложностью объяснений, признавая, что полное понимание системы может быть недостижимо.
Что дальше?
Представленные результаты демонстрируют, что поиск даже простых контрфактических объяснений, казалось бы, решенных моделей машинного обучения, может оказаться вычислительно непосильной задачей. Утверждение о прозрачности и интерпретируемости искусственного интеллекта, таким образом, нуждается в серьезной переоценке. Ведь, если «объяснение» требует экспоненциального времени, то это, скорее, замаскированная сложность, а не истинное понимание.
Очевидным направлением будущих исследований является разработка приближенных алгоритмов, способных находить «достаточно хорошие» объяснения за разумное время. Однако, возникает вопрос: насколько эти приближения будут соответствовать истинным причинам, лежащим в основе решений модели? Не превратится ли «объяснимый ИИ» в искусство компромиссов, где правдоподобность важнее точности?
Более того, необходимо исследовать взаимосвязь между вычислительной сложностью объяснений и устойчивостью самих моделей. Возможно, сложные для объяснения модели также более уязвимы к манипуляциям и атакам. И тогда, «баг» в алгоритме поиска объяснений станет признанием слабости всей системы.
Оригинал статьи: https://arxiv.org/pdf/2601.09455.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Язык тела под присмотром ИИ: архитектура и гарантии
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Квантовый импульс для несбалансированных данных
- Умная экономия: Как сжать ИИ без потери качества
- Редактирование изображений по запросу: новый уровень точности
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Безопасность генерации изображений: новый вектор управления
2026-01-16 05:13