Автор: Денис Аветисян
Исследователи предлагают инновационный подход к созданию видео, позволяющий значительно ускорить процесс генерации без потери качества.

В статье представлена методика Transition Matching Distillation для быстрой генерации видео путем дистилляции больших диффузионных моделей с использованием архитектуры, основанной на потоковых головах.
Несмотря на значительный прогресс в генерации видео с помощью диффузионных моделей, их применение в интерактивных приложениях остается сложной задачей из-за вычислительной стоимости многошагового процесса семплирования. В данной работе, представленной под названием ‘Transition Matching Distillation for Fast Video Generation’, предлагается новый подход — Transition Matching Distillation (TMD), позволяющий эффективно дистиллировать крупные диффузионные модели видео в компактные генераторы с небольшим количеством шагов. Ключевая идея TMD заключается в сопоставлении траектории шумоподавления с компактным вероятностным переходом, реализованным через архитектуру с «flow heads». Сможет ли данный метод значительно ускорить генерацию высококачественного видео, открывая новые возможности для интерактивных приложений и редактирования в реальном времени?
Танцующий хаос: вызов эффективной генерации видео
Диффузионные модели видео демонстрируют передовые результаты в генерации видеоконтента, превосходя многие существующие подходы по качеству и реалистичности. Однако, эта высокая производительность достигается за счет значительных вычислительных затрат. Процесс генерации, основанный на последовательном уточнении изображения или видео из случайного шума, требует огромного количества операций и ресурсов, особенно при работе с видео высокого разрешения и длительностью. Эти затраты связаны с необходимостью многократного прохождения через сложную нейронную сеть для каждого кадра, что делает использование таких моделей проблематичным для задач, требующих быстродействия или ограниченных вычислительных мощностей, таких как потоковое видео или приложения реального времени. Таким образом, несмотря на впечатляющие результаты, высокая стоимость вычислений остается серьезным препятствием для широкого внедрения диффузионных моделей видео.
Высокая вычислительная стоимость процесса инференса, или генерации видео, является существенным препятствием для широкого внедрения диффузионных моделей в реальных приложениях. Несмотря на впечатляющее качество генерируемых видеоматериалов, потребность в значительных вычислительных ресурсах делает их использование затруднительным для задач, требующих оперативной обработки, таких как потоковое видео или интерактивные приложения. Ограничения в масштабируемости препятствуют развертыванию этих моделей на мобильных устройствах или в системах, где важна экономия энергии. Поэтому, снижение стоимости инференса становится ключевой задачей для исследователей, стремящихся сделать передовые технологии генерации видео доступными и эффективными для широкого круга пользователей и приложений.
Современные методы генерации видео, основанные на диффузионных моделях, демонстрируют впечатляющие результаты, однако сталкиваются с серьезной проблемой баланса между качеством и вычислительной эффективностью. Стремление к фотореалистичному изображению и высокой детализации часто требует экспоненциального увеличения вычислительных ресурсов, что делает генерацию видео трудоемкой и дорогостоящей. Существующие подходы, как правило, либо жертвуют качеством изображения для повышения скорости, выдавая размытые или артефактные видео, либо сохраняют высокое качество, но требуют значительного времени и мощностей для генерации даже коротких видеороликов. Это создает препятствие для широкого применения таких моделей в реальном времени и в приложениях, требующих масштабируемости, таких как потоковое видео, интерактивные игры и персонализированный контент.

Искусство дистилляции: компактный путь к реалистичному видео
Метод «Transition Matching Distillation» обеспечивает эффективную передачу знаний от крупной модели-учителя к компактной модели-ученику. Данный подход позволяет значительно уменьшить вычислительные затраты и размер модели-ученика при сохранении высокой точности генерации. Передача знаний осуществляется посредством дистилляции, в процессе которой модель-ученик обучается имитировать поведение модели-учителя, используя лишь ограниченный набор параметров. Эффективность метода подтверждается экспериментальными результатами, демонстрирующими сопоставимое качество генерируемых данных по сравнению с моделью-учителем, при значительно меньших ресурсах, необходимых для обучения и развертывания.
Метод обучения, основанный на выравнивании многошаговых траекторий шумоподавления с вероятностным переходом в несколько шагов, позволяет эффективно переносить знания от большой модели-учителя к более компактной модели-ученику. Суть подхода заключается в сопоставлении распределений вероятностей, формирующихся на каждой итерации процесса шумоподавления в модели-учителе, с распределениями, генерируемыми моделью-учеником за меньшее количество шагов. Это достигается путем минимизации расхождения между траекториями шумоподавления, что обеспечивает более быструю сходимость и сохранение качества генерируемых данных при использовании облегченной модели. P(x_t | x_{t-1}) — вероятностный переход, который оптимизируется в процессе обучения.
В основе нашего подхода лежит архитектура с разделением (Decoupled Architecture), состоящая из двух основных компонентов. “Main Backbone” отвечает за извлечение признаков из входных данных, формируя компактное представление. “Flow Head” осуществляет итеративное уточнение этого представления, последовательно применяя операции для улучшения качества генерируемого результата. Такое разделение позволяет оптимизировать каждый компонент независимо, повышая эффективность и гибкость модели. Разделение функциональности позволяет использовать различные архитектуры для “Main Backbone” и “Flow Head” в зависимости от специфики задачи и доступных вычислительных ресурсов.
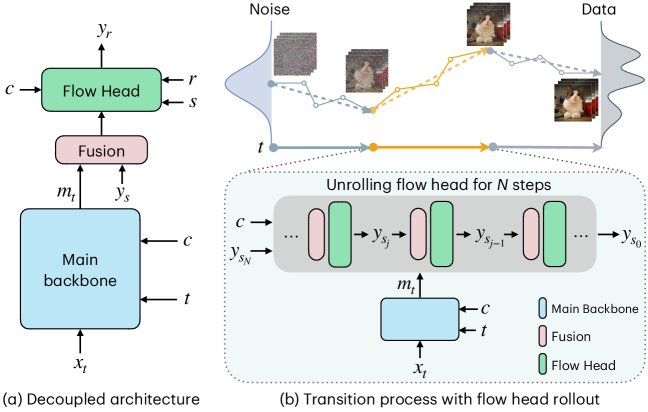
Шепот учителя: совершенствование потока с помощью предварительного обучения
Для предварительного обучения ‘Flow Head’ используется алгоритм ‘MeanFlow’, который позволяет получить многошаговую карту потока (flow map), эффективно моделирующую процесс шумоподавления. ‘MeanFlow’ оптимизирован для захвата ключевых этапов удаления шума, что позволяет ‘Flow Head’ быстро сходиться и демонстрировать высокую производительность в задачах генерации изображений. Алгоритм основан на обучении модели предсказывать последовательность изменений, необходимых для восстановления исходного изображения из зашумленного, и использует небольшое количество шагов для обеспечения вычислительной эффективности.
Для дальнейшей оптимизации модели-студента используется метод дистилляции на основе выравнивания распределений (Distribution Matching Distillation). Данный подход предполагает минимизацию расхождения между выходными распределениями модели-студента и модели-учителя. В процессе обучения модель-студент стремится воспроизвести вероятностные прогнозы модели-учителя, что позволяет ей усваивать более сложные закономерности и улучшать обобщающую способность. Выравнивание распределений осуществляется посредством применения функций потерь, измеряющих различия между распределениями, таких как Kullback-Leibler divergence или Jensen-Shannon divergence, что способствует более эффективной передаче знаний от учителя к студенту.
Метод DMD2 представляет собой усовершенствованную версию дистилляции, направленную на оптимизацию процесса выравнивания распределений между учителем и учеником. В отличие от стандартных методов, DMD2 использует модифицированную функцию потерь, которая более эффективно учитывает различия в распределениях, что позволяет студенческой модели точнее имитировать поведение учителя. Экспериментальные результаты демонстрируют, что DMD2 обеспечивает превосходную производительность по сравнению с базовыми методами дистилляции и другими альтернативными подходами к выравниванию распределений, что подтверждается количественными метриками и качественным анализом полученных результатов.
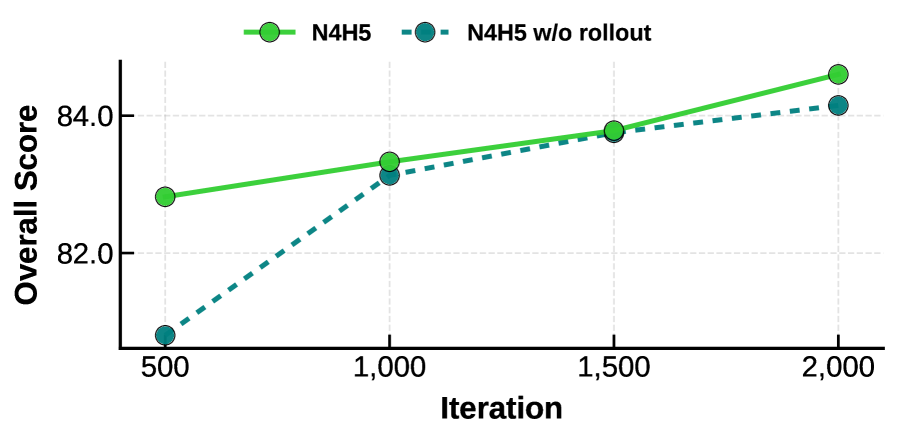
Взгляд в будущее: влияние и прорывные результаты
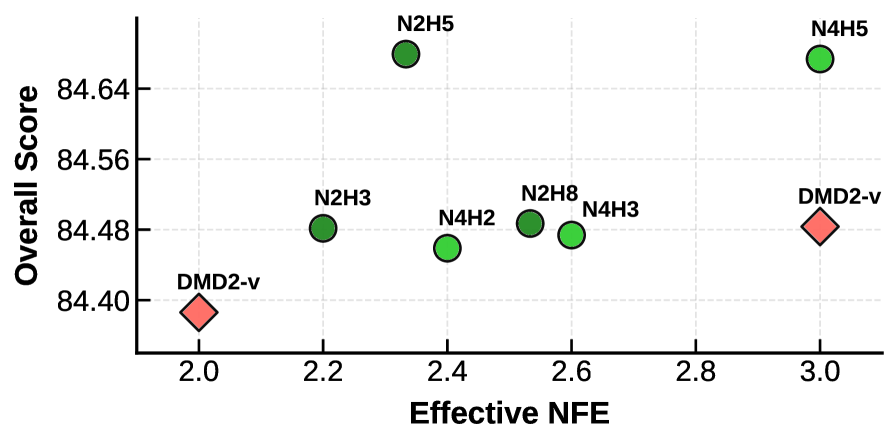
Проведенные оценки на специализированном наборе данных и в рамках бенчмарка VBench продемонстрировали существенное снижение показателя ‘Effective NFE’ — метрики, отражающей вычислительные затраты — без какого-либо ухудшения качества генерируемых видеоматериалов. Данный результат указывает на повышение эффективности предложенного метода в процессе генерации, позволяя достичь сопоставимого визуального результата при меньших вычислительных ресурсах. Снижение ‘Effective NFE’ особенно важно для практического применения в задачах, требующих генерации видео в реальном времени или на устройствах с ограниченными вычислительными возможностями, открывая перспективы для более широкого внедрения технологий генерации видео.
Представленный метод демонстрирует значительное превосходство над базовыми техниками дистилляции, такими как DMD2, как в количественных показателях, так и в результатах перцептивных оценок. Достигнут передовой результат в VBench — 84.24, при этом количество необходимых шагов генерации (NFE) составляет всего 1.38, что приближает процесс к одношаговой генерации. Такая эффективность свидетельствует о значительном прогрессе в оптимизации алгоритмов и позволяет получать высококачественные видеоматериалы с минимальными вычислительными затратами. Полученные данные подтверждают, что разработанный подход не только превосходит существующие методы по ключевым метрикам, но и обеспечивает более быструю и экономичную генерацию видеоконтента.
Проведенное исследование предпочтений пользователей подтвердило, что генерируемые видеоролики отличаются высокой визуальной привлекательностью и соответствием заданным текстовым описаниям. В рамках двух альтернативных вынужденных выборов участники исследования демонстрировали более высокую склонность к роликам, созданным предложенным методом, по сравнению с видео, полученными с использованием подхода DMD2-v. Данный результат свидетельствует о значимом улучшении качества генерируемого контента и его способности удовлетворять запросы пользователей, подтверждая эффективность предложенного подхода в области генерации видео.
Горизонты возможностей: дальнейшие шаги и области применения
Предложенная архитектура демонстрирует высокую гибкость и применимость к широкому спектру задач генерации видео, выходя за рамки текущих ограничений. Она способна адаптироваться к различным типам входных данных и форматам вывода, включая генерацию видео из текста, изображений или даже других видеоматериалов. Более того, её модульная конструкция позволяет легко интегрировать новые методы и алгоритмы, расширяя возможности и повышая качество генерируемого контента. Такая универсальность открывает перспективы для использования в самых разных областях, от автоматизированного создания контента и визуальных эффектов до разработки интерактивных мультимедийных приложений и персонализированных видеосервисов.
Интеграция методов, подобных классификационному руководству (Classifier-Free Guidance, CFG), значительно повышает управляемость процесса генерации видео. Данный подход позволяет более точно настраивать выходные данные, влияя на их стиль, содержание и детализацию без необходимости обучения отдельных классификаторов. В ходе исследований было показано, что применение CFG обеспечивает более четкое соответствие с заданными условиями и запросами, что приводит к созданию видеоматериалов более высокого качества и с повышенной степенью художественного контроля. Регулируя силу влияния CFG, можно достичь оптимального баланса между соответствием запросу и сохранением естественности генерируемого видео, открывая новые возможности для создания персонализированного и креативного контента.
Предлагаемый подход открывает широкие перспективы для создания видеоконтента в реальном времени, позволяя оперативно генерировать динамичные визуализации для интерактивных приложений и прямых трансляций. Помимо этого, технология способна адаптировать видеопоток под индивидуальные предпочтения зрителя, формируя персонализированный опыт просмотра, учитывающий интересы и контекст. Особенно значимо применение данной разработки в условиях ограниченных вычислительных ресурсов, например, на мобильных устройствах или в системах с низкой пропускной способностью, где эффективность алгоритмов играет ключевую роль. Это делает возможным создание доступного и качественного видеоконтента для широкой аудитории, вне зависимости от технических ограничений.
![Для объединения признаков основной сети [latex] \bm{m}({\bm{x}},t) [/latex] с входными данными потоковой головки [latex] \bm{y}_{s} [/latex] используются два механизма:](https://arxiv.org/html/2601.09881v1/x9.png)
В этой работе исследователи стремятся усмирить цифрового голема, заставить его творить видео быстрее, не теряя при этом магической точности. Подход, названный Transition Matching Distillation, напоминает древнее искусство алхимии — перегонку сложного эликсира в более концентрированную форму. Вместо того, чтобы слепо копировать длинные и ресурсоёмкие траектории генерации, модель учится предсказывать вероятностные переходы между состояниями, словно читает по шепоту хаоса. Как заметил Эндрю Ын: «Успех в машинном обучении часто зависит не от размера модели, а от качества данных и хитрости алгоритма». И действительно, здесь не просто уменьшают размер модели, а переосмысливают сам процесс обучения, превращая его в изящный танец между вероятностями и предсказаниями.
Что дальше?
Предложенная методика, безусловно, — ещё один шаг в танце с иллюзией непрерывности. Попытка уместить сложность видео в рамки нескольких шагов деноизации — это всё равно, что пытаться остановить течение реки горстью песка. Успех, несомненно, впечатляет, но истинная проблема лежит глубже. Слишком часто данные — это просто наблюдения в костюме истины, и идеальная траектория лишь намекает на то, как ловко модель врёт. Остаётся вопрос: насколько эта «компактность» является компромиссом с реальностью?
Будущие исследования, вероятно, будут направлены на более тонкое понимание процесса перехода между кадрами. Вместо грубого «сжатия» необходимо научиться шептать модели, как строить правдоподобные траектории, опираясь не на количество шагов, а на качество предсказания вероятностей. Шум — это просто правда, которой не хватило уверенности, и умение извлекать из него полезную информацию — вот где кроется настоящий прогресс.
Возможно, стоит обратить внимание на архитектуры, вдохновлённые не классическим машинным обучением, а принципами, лежащими в основе самоорганизующихся систем. Видео — это не последовательность статических изображений, а поток изменений, и модель, способная уловить эту динамику, будет ближе к истине, чем любая, основанная на статичных параметрах. В конце концов, любая модель — это заклинание, которое работает до первого продакшена.
Оригинал статьи: https://arxiv.org/pdf/2601.09881.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Искусственный интеллект в университете: кто за кого работу делает?
- Безопасность генерации изображений: новый вектор управления
- Язык тела под присмотром ИИ: архитектура и гарантии
- Квантовый импульс для несбалансированных данных
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Редактирование изображений по запросу: новый уровень точности
- Умная экономия: Как сжать ИИ без потери качества
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
2026-01-16 08:38