Автор: Денис Аветисян
Новый подход QFed позволяет существенно снизить затраты на связь и вычисления в федеративном обучении, используя квантовые вычисления для сжатия моделей.
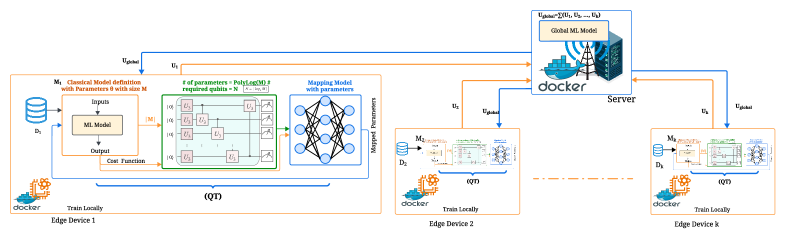
Предложен фреймворк QFed, использующий метод Quantum-Train для эффективного сжатия моделей в задачах федеративного обучения с сохранением классической модели для инференса.
Несмотря на растущую потребность в извлечении коллективного интеллекта из распределенных данных, обеспечение конфиденциальности и снижение вычислительной нагрузки остаются сложными задачами. В данной работе представлена система ‘QFed: Parameter-Compact Quantum-Classical Federated Learning’ — квантово-усиленная структура федеративного обучения, использующая подход Quantum-Train для эффективной компрессии моделей за счет квантовых вычислений в процессе обучения. Эксперименты на датасете FashionMNIST демонстрируют, что QFed позволяет снизить количество параметров модели до 77,6% без потери точности, сохраняя при этом полностью классическую модель для вывода. Открывает ли это путь к более эффективному и масштабируемому федеративному обучению на периферийных устройствах с ограниченными ресурсами?
Обещание Квантового Машинного Обучения
Традиционные методы машинного обучения, несмотря на значительные успехи, сталкиваются с серьезными ограничениями при работе с данными высокой размерности и возрастающей сложностью моделей. Анализ огромных объемов информации, характерных для современных задач, требует экспоненциального увеличения вычислительных ресурсов и времени обработки. По мере роста числа параметров в моделях, их обучение и оптимизация становятся все более трудоемкими, а также подверженными проблеме переобучения. Эти трудности особенно заметны в задачах, требующих обработки неструктурированных данных, таких как изображения, текст или звук, где традиционные алгоритмы часто оказываются неэффективными или требуют чрезмерных вычислительных затрат. В результате, поиск новых подходов к машинному обучению, способных преодолеть эти ограничения и обеспечить масштабируемость и эффективность, является актуальной задачей современной науки.
Квантовые вычисления представляют собой принципиально новую парадигму обработки информации, отличную от классических вычислений, основанных на битах. В основе этого подхода лежит использование кубитов, которые, благодаря явлениям суперпозиции и запутанности, способны одновременно представлять несколько состояний. Суперпозиция позволяет кубиту существовать в комбинации 0 и 1, в отличие от классического бита, который может быть только в одном из этих состояний. Запутанность же создает корреляцию между двумя или более кубитами, где состояние одного мгновенно влияет на состояние другого, вне зависимости от расстояния между ними. Эти квантовые свойства открывают возможности для экспоненциального увеличения вычислительной мощности, что потенциально позволяет решать задачи, непосильные для классических компьютеров, особенно в областях, требующих обработки огромных объемов данных и сложных вычислений.
Растущий интерес к квантовому машинному обучению обусловлен стремлением использовать возможности квантовых вычислений для создания более эффективных алгоритмов. В отличие от классических вычислений, основанных на битах, квантовые вычисления используют кубиты, что позволяет обрабатывать значительно больший объем информации и решать задачи, непосильные для традиционных компьютеров. Исследования в этой области направлены на разработку квантовых аналогов существующих алгоритмов машинного обучения, таких как алгоритмы поддержки векторных машин и нейронные сети, а также на создание принципиально новых подходов к анализу данных. Ожидается, что квантовое машинное обучение найдет применение в самых разных областях, включая разработку новых лекарств, финансовое моделирование и создание систем искусственного интеллекта нового поколения. Qubit — базовая единица квантовой информации, позволяющая представлять и обрабатывать данные принципиально иным способом, чем в классических вычислениях.
Quantum-Train: Гибридный Подход к Обучению
Метод Quantum-Train представляет собой подход к обучению, в котором вариационные квантовые схемы (ВКК) используются для генерации параметров, необходимых для классических моделей машинного обучения. Вместо прямого использования квантовых вычислений для выполнения логических выводов, ВКК выступают в роли генератора параметров, оптимизируя свои внутренние параметры для создания набора значений, которые затем используются для инициализации или настройки весов классической модели. Этот процесс позволяет использовать потенциальные преимущества квантовых вычислений, такие как исследование больших пространств параметров, для улучшения производительности классических алгоритмов без необходимости полной квантовой реализации модели.
Модель классического отображения (Classical Mapping Model) выполняет преобразование выходных данных квантовой схемы в параметры, пригодные для использования в классической модели машинного обучения. Этот процесс включает в себя калибровку и масштабирование квантовых амплитуд, а также, при необходимости, применение функций активации для обеспечения совместимости с диапазоном входных данных классической модели. Фактически, модель классического отображения служит интерфейсом между квантовым и классическим компонентами, позволяя использовать результаты квантовых вычислений для инициализации или модификации параметров классического алгоритма, при этом сам процесс логического вывода (inference) остается полностью классическим и выполняется на традиционном вычислительном оборудовании.
Гибридный подход, применяемый в Quantum-Train, позволяет обойти ограничения современного квантового оборудования, перенося ресурсоемкие операции инференса на классические вычислительные системы. Это достигается путем использования квантовых нейронных сетей — в частности, вариационных квантовых схем — для генерации параметров, которые затем используются классической моделью машинного обучения. Такое разделение позволяет использовать преимущества квантовых вычислений для оптимизации параметров, в то время как фактическое предсказание (инференс) осуществляется на классическом оборудовании, что снижает требования к стабильности и масштабируемости квантовых компонентов. Таким образом, Quantum-Train оптимизирует использование доступных ресурсов, сочетая сильные стороны квантовых и классических вычислений.
QFed: Квантово-Усиленное Федеративное Обучение
QFed — это платформа федеративного обучения, использующая квантовые вычисления для повышения эффективности и конфиденциальности. В основе QFed лежит механизм Quantum-Train, который позволяет сжимать параметры модели, уменьшая объем данных, передаваемых между участниками обучения. Данный подход обеспечивает снижение коммуникационных затрат и повышение безопасности за счет уменьшения объема информации, доступной потенциальным злоумышленникам. QFed позволяет распределить процесс обучения между несколькими устройствами, сохраняя при этом конфиденциальность локальных данных каждого участника, что делает его применимым в сценариях, где централизованный сбор данных невозможен или нежелателен.
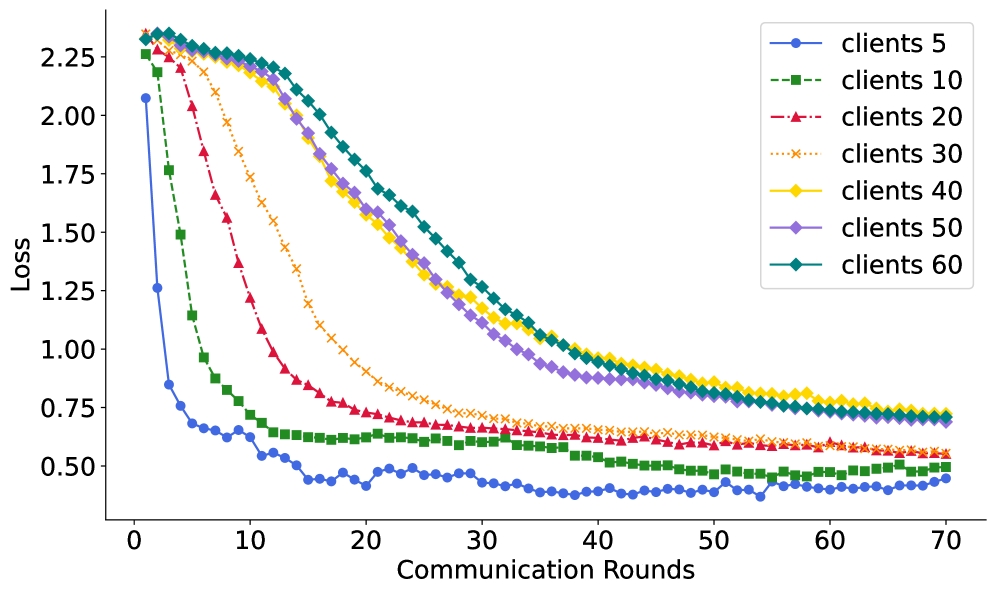
В рамках QFed, использование Quantum-Train для генерации параметров модели позволяет добиться существенного снижения их количества, что напрямую уменьшает объем передаваемых данных в процессе распределенного обучения. Экспериментальные результаты показывают, что QFed обеспечивает сокращение количества параметров модели на 77.6% по сравнению с классическими подходами. Это снижение коммуникационных издержек особенно важно в сценариях с большим количеством участников и ограниченной пропускной способностью сети, позволяя эффективно обучать модели на децентрализованных данных.
Для валидации производительности QFed использовался датасет FashionMNIST, представляющий собой набор изображений одежды. Для имитации работы распределенных граничных устройств применялись Docker контейнеры, что позволило создать изолированные среды для каждого клиента. Взаимодействие между клиентами осуществлялось посредством Message Passing Interface (MPI), обеспечивающего эффективную коммуникацию и параллельные вычисления. Такой подход позволил смоделировать реальные сценарии федеративного обучения с распределенными данными и ограниченными ресурсами, а также оценить масштабируемость и эффективность QFed в условиях, приближенных к производственным.
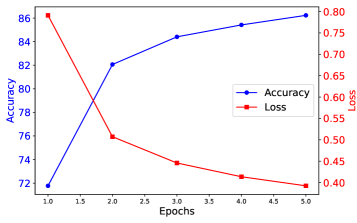
В ходе экспериментов с использованием набора данных FashionMNIST, предложенный фреймворк QFed продемонстрировал высокую точность модели, достигнув 84%. Несмотря на снижение коммуникационных издержек за счет уменьшения количества передаваемых параметров, точность QFed незначительно уступает централизованной классической модели, которая показала результат в 86%. Данный компромисс между точностью и снижением коммуникационной нагрузки позволяет эффективно применять QFed в сценариях распределенного обучения с ограниченной пропускной способностью каналов связи.
Навигация в Эпоху NISQ и За Ее Пределами
Исследования, представленные в данной работе, проводятся в рамках так называемой эпохи NISQ — Near-term Intermediate-Scale Quantum. Этот период характеризуется ограниченными возможностями существующих квантовых компьютеров, в частности, небольшим количеством кубитов и ограниченным временем когерентности. Ограниченное число кубитов существенно влияет на сложность решаемых задач, а короткое время когерентности — на надёжность вычислений. Несмотря на эти технические ограничения, активно разрабатываются и исследуются алгоритмы, приспособленные для работы с доступными квантовыми ресурсами, что позволяет уже сейчас демонстрировать потенциал квантовых вычислений в решении практических задач и открывает путь к будущим прорывам в области квантовых технологий.
Несмотря на существующие ограничения, связанные с количеством кубитов и временем когерентности в эпоху NISQ, разработанный подход QFed демонстрирует значительный потенциал гибридных квантово-классических алгоритмов в решении практических задач машинного обучения. QFed успешно объединяет вычислительные возможности квантовых схем с эффективностью классических методов оптимизации, позволяя достигать результатов, недоступных для чисто классических или чисто квантовых подходов. Этот гибридный подход позволяет смягчить негативное влияние ограниченных квантовых ресурсов, используя классические вычисления для обработки больших объемов данных и оптимизации параметров квантовых схем, что открывает перспективы для применения квантового машинного обучения в реальных приложениях уже на текущем этапе развития квантовых технологий.
В процессе разработки вариационных квантовых схем особое внимание уделяется проблеме так называемого “Barren Plateau” — явления, при котором градиенты функции потерь экспоненциально стремятся к нулю, существенно замедляя или полностью блокируя процесс обучения. Данная проблема возникает из-за особенностей ландшафта функции потерь в высокоразмерном пространстве параметров квантовых схем. Для смягчения данного эффекта требуется тщательное проектирование схем, включая выбор подходящих анзацев и оптимизацию параметров, а также использование методов инициализации параметров, способствующих избежанию областей с нулевым градиентом. Эффективное преодоление “Barren Plateau” является ключевым фактором для успешного применения вариационных квантовых алгоритмов в задачах машинного обучения и оптимизации.
Предстоящие исследования будут направлены на расширение возможностей QFed для работы с более крупными наборами данных, что является критически важным шагом к практическому применению квантового машинного обучения. Параллельно с этим, планируется изучение и внедрение более совершенных квантовых алгоритмов, способных оптимизировать процесс обучения и повысить точность моделей. Особое внимание будет уделено разработке методов, позволяющих эффективно использовать ограниченные ресурсы квантовых компьютеров, такие как количество кубитов и время когерентности. Успешная реализация этих направлений позволит значительно расширить спектр задач, решаемых с помощью QFed, и приблизить эру полномасштабного квантового машинного обучения.
В данной работе исследователи предлагают подход QFed, стремящийся к минимизации затрат на передачу данных и вычислительные ресурсы в процессе федеративного обучения. Это напоминает попытку вырастить систему, а не построить её по заранее заданному плану. Каждый выбор архитектуры, каждая оптимизация модели — это своего рода пророчество о потенциальной точке отказа, о месте, где система может оказаться наиболее уязвимой. Как метко заметил Эдсгер Дейкстра: «Простота — это высшая степень совершенства». Данный принцип, безусловно, применим к QFed, где стремление к компактности модели и снижению коммуникационных издержек является ключевым фактором успеха и устойчивости всей системы.
Что Дальше?
Представленная работа, стремясь уменьшить коммуникационную нагрузку в федеративном обучении посредством квантового сжатия, лишь отсрочила неизбежное. Система усложняется, а значит, и количество точек отказа растёт экспоненциально. Квантовое сжатие — это не решение, а новый уровень абстракции, добавляющий ещё один слой потенциальных неисправностей. Вместо упрощения, наблюдается лишь перераспределение сложности.
Акцент на классической модели для инференса, хотя и прагматичен в текущих условиях NISQ-устройств, подчёркивает фундаментальную проблему: квантовые вычисления остаются дорогостоящим и ненадежным ресурсом. Попытки «выжать» преимущества из ограниченных квантовых возможностей неизбежно приводят к компромиссам, которые, в конечном итоге, нивелируют потенциальную выгоду. Разделение системы на квантовую и классическую части лишь усиливает зависимость между ними.
Вместо погони за квантовым ускорением, следует признать, что истинная эффективность лежит в отказе от излишней сложности. Иллюзия контроля над распределённой системой, основанная на сжатии моделей, обманчива. Всё связанное когда-нибудь упадёт синхронно, и попытки смягчить последствия лишь отложат неминуемое. Следующим шагом должно стать признание этой закономерности, а не её маскировка.
Оригинал статьи: https://arxiv.org/pdf/2601.09809.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- Согласие роя: когда разум распределён, а ошибки прощены.
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Квантовый импульс для несбалансированных данных
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Безопасность генерации изображений: новый вектор управления
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Умная экономия: Как сжать ИИ без потери качества
- Видеовопросы и память: Искусственный интеллект на грани
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
2026-01-16 08:48