Автор: Денис Аветисян
Исследователи предлагают инновационную систему VQ-Seg, использующую векторизацию и структурированные возмущения для повышения точности сегментации медицинских изображений при недостатке размеченных данных.
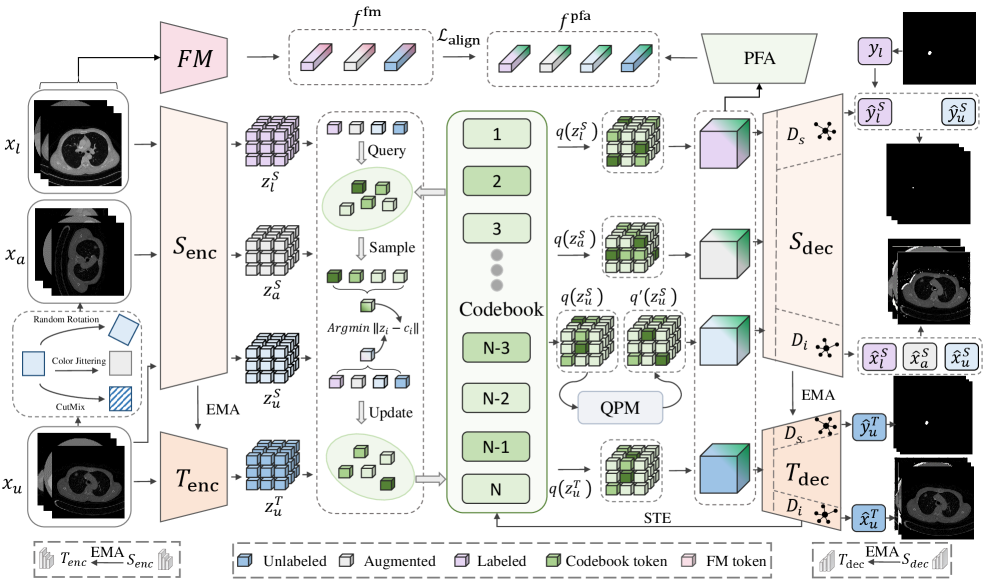
VQ-Seg — это полу-контролируемый фреймворк, использующий квантованные возмущения токенов для достижения передовых результатов в сегментации медицинских изображений.
Несмотря на успехи в области сегментации медицинских изображений, обучение с частичной разметкой данных остается сложной задачей, требующей эффективных методов регуляризации. В данной работе, ‘VQ-Seg: Vector-Quantized Token Perturbation for Semi-Supervised Medical Image Segmentation’, предложен новый подход, использующий векторизованную квантизацию для дискретизации признакового пространства и управляемое возмущение, заменяющее традиционный dropout. Предложенная архитектура VQ-Seg демонстрирует превосходные результаты за счет комбинирования двухуровневой структуры и адаптера признаков, использующего знания предварительно обученных моделей. Способна ли эта методика стать основой для создания более надежных и точных систем медицинской диагностики при ограниченном объеме размеченных данных?
Точность Диагностики: Проблема Ограниченных Разметок в Медицинской Визуализации
Точная сегментация медицинских изображений играет ключевую роль в постановке диагноза и планировании лечения, однако её достижение требует обширной ручной разметки данных — процесса, отличающегося высокой стоимостью и значительными затратами времени. Специалисты вынуждены вручную отмечать интересующие области на каждом изображении, что особенно критично для объемных данных, таких как результаты компьютерной томографии или магнитно-резонансной томографии. Эта трудоемкая работа не только замедляет процесс разработки и внедрения новых алгоритмов анализа изображений, но и ограничивает масштабируемость решений, поскольку требует значительных ресурсов для создания и поддержания размеченных баз данных. В результате, прогресс в автоматизированном анализе медицинских изображений часто сдерживается доступностью качественно размеченных данных.
Традиционные методы глубокого обучения, требующие больших объемов размеченных данных, часто сталкиваются с трудностями при анализе медицинских изображений. Ограниченное количество размеченных примеров приводит к переобучению моделей, что существенно снижает их способность к обобщению и корректной работе с новыми, ранее не встречавшимися изображениями. В результате, точность диагностики и планирования лечения, основанная на таких моделях, может быть существенно снижена, а клиническое применение автоматизированных систем анализа медицинских изображений становится затруднительным. Недостаток размеченных данных особенно актуален для редких заболеваний или специфических типов изображений, что требует разработки альтернативных подходов к обучению, способных эффективно использовать ограниченные ресурсы.
Ограниченность больших, полностью аннотированных наборов данных представляет собой существенное препятствие для развития автоматизированного анализа медицинских изображений. Отсутствие достаточного количества размеченных примеров затрудняет обучение надежных и точных алгоритмов глубокого обучения, необходимых для выявления патологий и помощи в постановке диагноза. Поскольку создание таких наборов данных требует значительных временных и финансовых затрат, а также высокой квалификации специалистов, прогресс в области автоматической сегментации и анализа медицинских изображений существенно замедляется. Это особенно актуально для редких заболеваний или специфических анатомических структур, где получение достаточного количества размеченных изображений становится практически невозможным, ограничивая возможности применения искусственного интеллекта в клинической практике и требуя разработки новых подходов к обучению моделей при ограниченном количестве данных.

VQ-Seg: Полу-Обучаемый Подход к Эффективной Сегментации
Метод VQ-Seg представляет собой новый подход к полу-обучаемому сегментированию медицинских изображений, эффективно использующий как размеченные, так и неразмеченные данные. Традиционные методы сегментации часто ограничены необходимостью большого количества вручную размеченных данных, что является трудоемким и дорогостоящим процессом. VQ-Seg обходит это ограничение, используя неразмеченные изображения для обучения надежным представлениям признаков. Это достигается путем обучения модели прогнозировать скрытые векторы признаков из неразмеченных изображений, а затем использования этих векторов для улучшения производительности сегментации на размеченных данных. Такой подход позволяет значительно сократить объем требуемых размеченных данных, сохраняя при этом высокую точность сегментации, что особенно важно в клинических условиях, где получение большого количества размеченных данных может быть затруднительным.
В основе VQ-Seg лежит использование векторной квантизации (VQ) для получения дискретного представления признаков изображения. Этот подход предполагает преобразование непрерывного вектора признаков в ближайший вектор из конечного набора кодовых векторов, что значительно снижает вычислительную сложность по сравнению с обработкой непрерывных признаков. Дискретизация позволяет эффективно передавать знания, поскольку дискретные представления более устойчивы к шуму и изменениям в данных. Использование VQ также сокращает объем требуемой памяти и вычислительные затраты, особенно при работе с большими объемами данных медицинских изображений, делая возможным обучение и применение моделей на менее мощном оборудовании.
Архитектура VQ-Seg использует двойную ветвь, объединяющую задачи реконструкции и сегментации, для повышения устойчивости и согласованности извлекаемых представлений. В процессе обучения, одна ветвь сети реконструирует входное изображение из закодированных векторных квантов, а другая выполняет задачу сегментации. Совместное обучение этих двух задач обеспечивает, что закодированные признаки содержат достаточно информации как для восстановления исходного изображения, так и для точного определения границ сегментов. Эта совместная оптимизация приводит к более надежным и обобщающим представлениям, особенно при ограниченном количестве размеченных данных, поскольку реконструкция служит формой регуляризации, способствующей изучению более информативных признаков.
В основе VQ-Seg лежит интеграция адаптера признаков после векторизации (Post-VQ Feature Adapter) с предварительно обученной основой (Foundation Model). Этот подход позволяет эффективно переносить знания, полученные моделью на больших объемах данных, на задачу сегментации медицинских изображений. Адаптер выполняет преобразование дискретных признаков, полученных в результате векторизации, в формат, совместимый с основой, обеспечивая плавную передачу информации и сокращая необходимость в обучении с нуля. Использование предварительно обученной основы значительно снижает потребность в размеченных данных для сегментации, повышая эффективность обучения и обобщающую способность модели.
Повышение Надежности: Возмущения и Обучение Согласованности
В архитектуре VQ-Seg реализован модуль квантованных возмущений (Quantized Perturbation Module), который вносит контролируемые изменения непосредственно в квантованное векторное пространство признаков. Данный модуль оперирует с дискретными представлениями признаков, полученными в результате векторной квантизации, и вносит небольшие, но преднамеренные возмущения в эти векторы. Это позволяет модели обучаться на слегка измененных данных, что способствует повышению устойчивости и обобщающей способности, поскольку модель вынуждена извлекать признаки, инвариантные к этим квантованным возмущениям. Важно отметить, что возмущения происходят в дискретном пространстве кодов, а не в исходном пространстве пикселей, что снижает вычислительную сложность и сохраняет семантическую целостность признаков.
В VQ-Seg возмущение в квантованном векторном пространстве осуществляется под управлением расхождения Кульбака-Лейблера (KL Divergence). Этот механизм направлен на повышение устойчивости и обобщающей способности модели путём стимулирования обучения инвариантным признакам. Расхождение KL используется как метрика для измерения различия между распределениями признаков исходного и возмущенного входных данных. Минимизация этого расхождения заставляет модель игнорировать незначительные возмущения и фокусироваться на существенных характеристиках объекта, что приводит к более надежной и обобщающей модели, способной эффективно работать в условиях неполных или зашумленных данных.
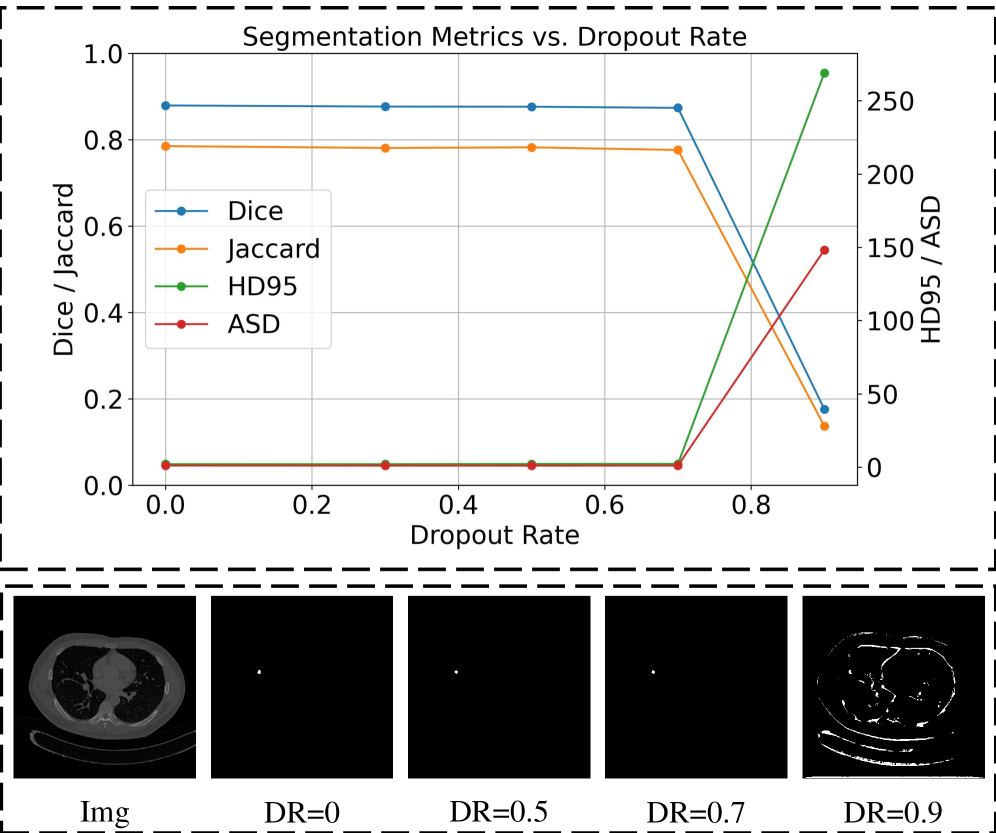
Метод Consistency Learning, дополненный применением Dropout, направлен на обеспечение инвариантности предсказаний модели к введенным возмущениям. Dropout случайным образом отключает нейроны во время обучения, что вынуждает модель полагаться на более разнообразные признаки и уменьшает переобучение. Сочетание Dropout с Consistency Learning усиливает стабильность процесса обучения, поскольку модель учится выдавать согласованные предсказания как для исходных, так и для возмущенных входных данных, что повышает ее обобщающую способность и устойчивость к шуму.
Метод максимизации согласованности между предсказаниями, полученными на исходных и возмущенных входных данных, позволяет модели VQ-Seg извлекать значимые признаки даже при ограниченном количестве размеченных данных. Этот подход основывается на предположении, что надежные признаки должны обеспечивать стабильные предсказания независимо от незначительных изменений во входных данных. Согласованность достигается за счет минимизации расхождения между предсказаниями для исходного изображения и его возмущенной версии, что эффективно выступает в качестве формы регуляризации и улучшает обобщающую способность модели, особенно в условиях нехватки обучающих данных. По сути, модель обучается игнорировать шум и фокусироваться на существенных характеристиках изображения, что приводит к более надежным и точным результатам сегментации.
Валидация и Более Широкие Последствия для Медицинской Визуализации
Исследование продемонстрировало высокую эффективность предложенного метода VQ-Seg при сегментации медицинских изображений. Оценка проводилась на двух широко используемых датасетах: ACDC (кардиологические МРТ) и датасете для обнаружения рака легких. Результаты показали, что VQ-Seg демонстрирует производительность, сопоставимую или превосходящую существующие современные методы сегментации. Это подтверждается достижением конкурентоспособных показателей точности и надежности на обоих датасетах, что указывает на потенциал VQ-Seg для широкого применения в клинической практике и научных исследованиях в области медицинской визуализации. Полученные данные свидетельствуют о перспективности использования данного подхода для автоматизации и повышения точности анализа медицинских изображений.
Для оценки точности и надежности сегментации, полученной с использованием предложенного подхода, был проведен количественный анализ с применением ряда метрик. Результаты показали, что на базе данных ACDC (кардиологические МРТ) достигнут коэффициент Дайса в 0.9103 и индекс Жаккара в 0.8327, что свидетельствует о высокой степени соответствия между автоматической сегментацией и эталонными данными. Аналогичные результаты, хотя и несколько ниже, но все еще демонстрирующие значительную эффективность, были получены на базе данных рака легких (коэффициент Дайса — 0.7852, индекс Жаккара — 0.6731) при использовании всего 10% размеченных данных. Дополнительно были учтены метрики расстояния Хаусдорфа и среднее симметричное расстояние, подтверждающие стабильность и прецизионность результатов сегментации, что особенно важно для клинического применения и последующего анализа изображений.
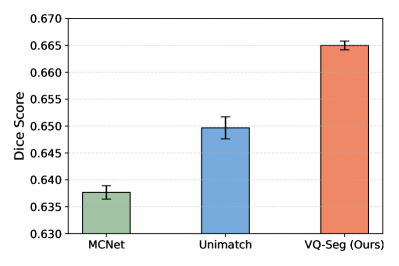
В ходе оценки на наборе данных по раку легких, при использовании всего 10% размеченных данных, предложенный алгоритм VQ-Seg продемонстрировал значительное превосходство над существующей моделью MCNet. Показатель Dice, характеризующий точность сегментации, увеличился на 2.97%, достигнув более высокого значения, что указывает на улучшенное выявление пораженных областей. Кроме того, индекс Жаккара, измеряющий степень перекрытия между предсказанной и истинной сегментацией, вырос на 3.17%. Эти результаты свидетельствуют о способности VQ-Seg обеспечивать более точную и надежную сегментацию изображений при ограниченном количестве аннотаций, что открывает перспективы для более эффективной диагностики и планирования лечения.
Разработанная система позволяет значительно снизить потребность в трудоемкой и дорогостоящей ручной разметке медицинских изображений. Традиционно, обучение алгоритмов сегментации требует обширных наборов данных, помеченных экспертами, что ограничивает скорость разработки и внедрения новых диагностических инструментов. Предложенный подход, благодаря своей эффективности при работе с ограниченным количеством размеченных данных, открывает возможности для более быстрого и экономичного создания приложений для медицинской визуализации. Это особенно актуально для задач, где получение большого количества размеченных данных затруднено или требует значительных временных и финансовых затрат, что в конечном итоге способствует более широкому внедрению передовых технологий в клиническую практику.
Разработанный фреймворк VQ-Seg открывает новые перспективы в области медицинской диагностики, обеспечивая точную сегментацию изображений при минимальном объеме ручной разметки. Это значительно снижает затраты и ускоряет внедрение передовых технологий в клиническую практику. Возможность эффективной работы с ограниченным количеством размеченных данных делает диагностические инструменты более доступными, особенно в условиях ограниченных ресурсов или при работе с редкими заболеваниями. Точность сегментации, продемонстрированная на наборах данных ACDC и Lung Cancer, позволяет врачам получать более четкие и детализированные изображения, что способствует более ранней и точной диагностике, а также улучшению планов лечения.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в области медицинской сегментации изображений. Авторы предлагают подход VQ-Seg, основанный на векторизации и структурированных возмущениях, что позволяет достичь высокой точности при ограниченном количестве размеченных данных. Как однажды заметил Джеффри Хинтон: «Иногда, чтобы сделать что-то действительно новое, нужно отказаться от всего, что вы знаете». В данном случае, авторы отошли от традиционных методов, используя квантование векторов для создания более устойчивой и эффективной модели, что подтверждает важность поиска элегантных и доказуемых решений в сложных задачах машинного обучения. Особенно выделяется использование структурированных возмущений, что позволяет модели лучше обобщать и адаптироваться к новым данным, сохраняя при этом математическую строгость подхода.
Куда Далее?
Представленная работа, хотя и демонстрирует впечатляющие результаты в области полу-контролируемого сегментирования медицинских изображений, оставляет открытым вопрос о фундаментальной природе используемых эвристик. Векторная квантизация, как и любое сжатие информации, неизбежно вносит искажения. Успех VQ-Seg поднимает вопрос: насколько эти искажения являются благом, а насколько — лишь терпимым компромиссом в погоне за производительностью? В конечном счете, алгоритм должен быть доказан, а не просто «работать» на ограниченном наборе данных.
Перспективы дальнейших исследований лежат в области формальной верификации устойчивости к возмущениям. Необходимо разработать метрики, которые бы позволяли оценивать не только точность сегментации, но и степень искажения исходного изображения в процессе квантизации. Важно выйти за рамки эмпирической оценки и стремиться к математической строгости. Иначе, мы рискуем создать системы, которые выглядят надежными, но в критических ситуациях могут дать непредсказуемые результаты.
В долгосрочной перспективе, необходимо исследовать возможность объединения VQ-Seg с моделями, основанными на принципах причинно-следственного вывода. Это позволит не просто сегментировать изображение, но и понимать, какие факторы влияют на процесс сегментации, и учитывать их при принятии решений. И лишь тогда, можно будет говорить о создании действительно интеллектуальных систем анализа медицинских изображений.
Оригинал статьи: https://arxiv.org/pdf/2601.10124.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Согласие роя: когда разум распределён, а ошибки прощены.
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Квантовый импульс для несбалансированных данных
- Редактирование изображений по запросу: новый уровень точности
- Безопасность генерации изображений: новый вектор управления
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Умная экономия: Как сжать ИИ без потери качества
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Язык тела под присмотром ИИ: архитектура и гарантии
2026-01-16 18:43