Автор: Денис Аветисян
Новый подход к поиску в интернете предлагает персонализированную помощь прямо в браузере, не отправляя ваши данные в облако.
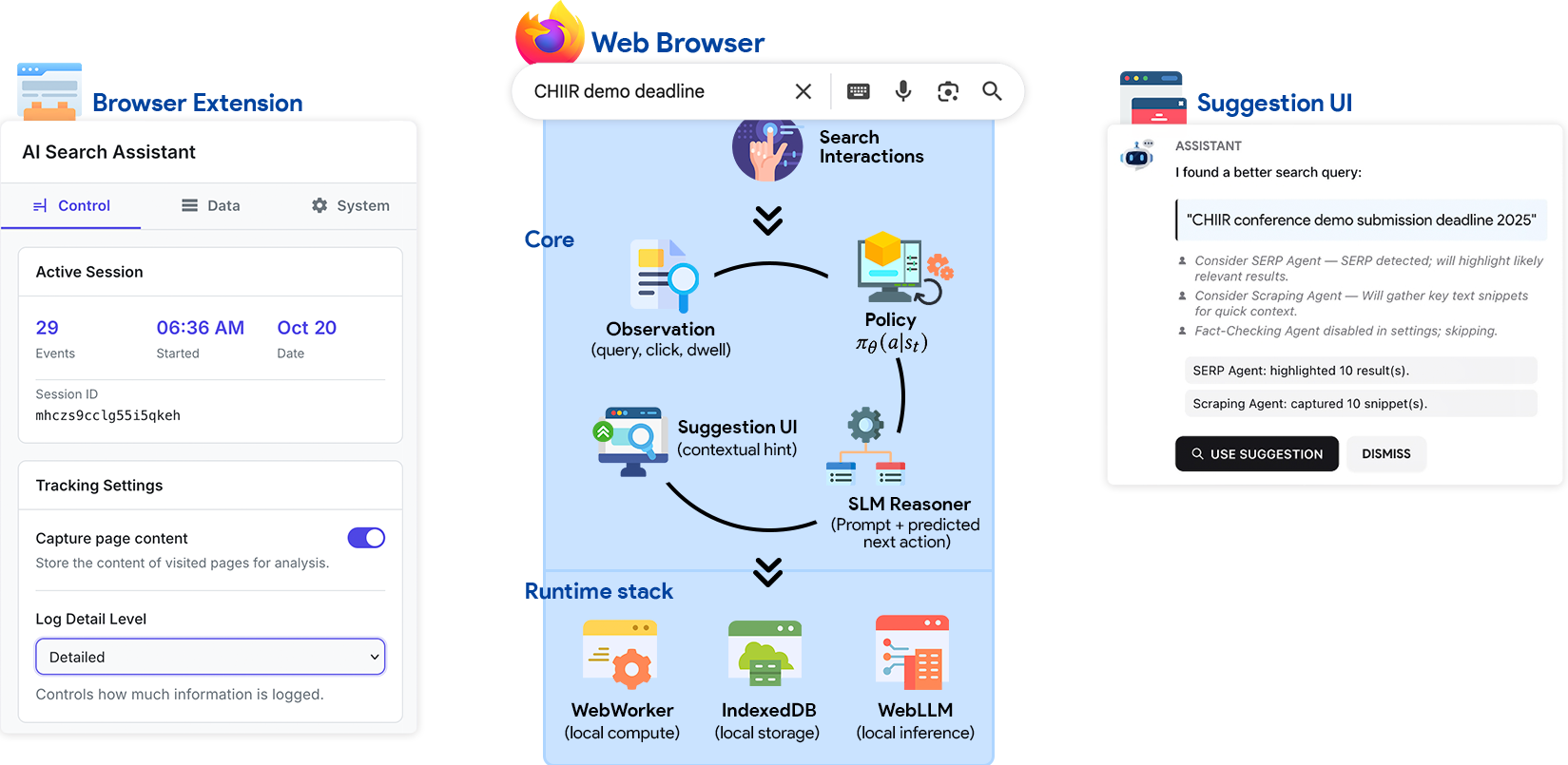
Обзор клиентских агентов, использующих малые языковые модели и адаптивное моделирование пользователя для конфиденциального и персонализированного поиска.
Современные системы помощи в веб-поиске часто требуют передачи конфиденциальных данных пользователей на внешние серверы, что вызывает опасения относительно приватности. В статье «In-Browser Agents for Search Assistance» представлено альтернативное решение — расширение для браузера, функционирующее полностью на стороне клиента. Разработанная гибридная архитектура сочетает адаптивную вероятностную модель, обучающуюся на основе обратной связи от пользователя, и малую языковую модель (SLM), генерирующую контекстно-зависимые предложения. Позволит ли такая полностью локальная обработка данных создать эффективного и конфиденциального помощника для веб-поиска, не уступающего по качеству облачным решениям?
Поиск, Адаптированный к Индивидуальности: Вызов Персонализации
Традиционные алгоритмы поиска зачастую предоставляют усредненные результаты, не учитывающие индивидуальные потребности и предпочтения пользователя. Вместо того чтобы предлагать информацию, релевантную конкретному запросу и истории поиска, эти системы опираются на общую популярность и статистику ключевых слов. Это приводит к тому, что пользователь тратит время на пролистывание множества неактуальных ссылок, чтобы найти действительно нужную информацию. В результате, несмотря на кажущуюся полноту выдачи, эффективность поиска снижается, а пользовательский опыт ухудшается, поскольку система не адаптируется к уникальным интересам и контексту каждого отдельного человека.
Эффективная персонализация поисковых систем требует глубокого анализа поведения пользователей, выходящего за рамки простого сопоставления ключевых слов. Современные алгоритмы все чаще обращаются к сложным моделям, учитывающим историю запросов, клики по ссылкам, время, проведенное на странице, а также географическое положение и социальные связи пользователя. Такой подход позволяет выявить скрытые предпочтения и намерения, которые не отражены в явном тексте запроса. Например, пользователь, часто ищущий информацию о беге, может быть заинтересован в спортивной обуви или марафонах, даже если он напрямую об этом не спрашивает. Разработка и применение таких моделей требует значительных вычислительных ресурсов, но позволяет значительно повысить релевантность и полезность поисковых результатов, предоставляя каждому пользователю уникальный и адаптированный опыт.
Масштабирование персонализированного поиска до миллионов пользователей представляет собой сложную вычислительную задачу. Традиционные алгоритмы, разработанные для обработки общих запросов, оказываются неэффективными при необходимости учета индивидуальных предпочтений каждого пользователя в реальном времени. Реализация персонализации требует обработки огромных объемов данных о поведении пользователей — истории запросов, кликов, времени, проведенном на страницах — и применения сложных моделей машинного обучения для прогнозирования релевантности результатов. Поэтому исследователи активно разрабатывают эффективные методы, такие как факторные модели, методы понижения размерности и распределенные вычисления, позволяющие снизить вычислительную нагрузку и обеспечить быстрое и точное предоставление персонализированных результатов даже при огромном количестве пользователей. Ключевым аспектом является не только скорость обработки данных, но и поддержание актуальности моделей персонализации, требующее непрерывного обучения и адаптации к меняющемуся поведению пользователей.
Динамическая Модель Пользователя: Основа Индивидуального Поиска
В отличие от статических профилей пользователей, мы используем вероятностную модель пользователя для представления предпочтений и прогнозирования будущих действий. Данная модель позволяет учитывать неопределенность и изменчивость поведения пользователей, назначая вероятности различным сценариям. Это достигается путем анализа исторических данных о взаимодействии пользователя с системой, а также учета контекста текущего взаимодействия. Вероятностный подход обеспечивает более гибкое и точное представление о потребностях пользователя, что позволяет системе адаптироваться к изменениям в его поведении и предлагать релевантный контент или функциональность. Модель непрерывно обновляется по мере поступления новых данных, повышая точность прогнозов и обеспечивая более персонализированный пользовательский опыт.
Модель динамического профиля пользователя строится на основе марковских процессов принятия решений (Markov Decision Processes, MDP). В рамках MDP, состояние системы представляет собой текущий контекст пользователя, действия — возможные варианты взаимодействия, а награды — оценку предпочтений пользователя. Изначальная модель калибруется с использованием исторических данных о поведении пользователей, включая историю просмотров, покупок и взаимодействий с контентом. В процессе эксплуатации модель постоянно уточняется на основе данных о взаимодействии пользователя в реальном времени, что позволяет адаптироваться к изменяющимся предпочтениям и повышать точность прогнозирования будущих действий. Итеративное обучение с использованием данных о реальных взаимодействиях позволяет оптимизировать параметры модели и повысить её эффективность.
Для повышения точности представления намерений пользователя и, следовательно, улучшения прогнозирования, применяются модели кликов и марковские модели. Модели кликов анализируют последовательность выборов пользователя, учитывая вероятность перехода между различными элементами интерфейса. Марковские модели, в свою очередь, описывают вероятность следующего действия пользователя, основываясь на его предыдущих действиях и текущем состоянии системы. Комбинированное использование этих моделей позволяет более эффективно учитывать контекст взаимодействия и предсказывать будущие действия, значительно превосходя статические профили пользователей по точности прогнозов. P(s_{t+1}|s_t, a_t) обозначает вероятность перехода в состояние s_{t+1} после выполнения действия a_t в состоянии s_t.
Интеллект в Браузере: Адаптивные Политики для Персонализированных Результатов
В основе системы персонализированного поиска лежит расширение для браузера, которое обеспечивает непосредственное выполнение пользовательской модели и алгоритмов поиска непосредственно на стороне клиента. Это позволяет минимизировать задержки, связанные с сетевыми запросами и обработкой данных на сервере. Расширение реализует логику анализа поисковых запросов пользователя, отслеживает взаимодействие с результатами поиска и применяет персонализированные алгоритмы ранжирования, что позволяет предоставлять более релевантные результаты, адаптированные к индивидуальным предпочтениям пользователя. Выполнение алгоритмов непосредственно в браузере также снижает нагрузку на серверную инфраструктуру и повышает общую производительность системы.
Для минимизации нагрузки на сервер и обеспечения высокой скорости отклика используется выполнение пользовательской модели и алгоритмов персонализированного поиска непосредственно в браузере. Реализация основана на применении Web Workers — фоновых потоков JavaScript, позволяющих выполнять ресурсоемкие вычисления, не блокируя основной поток пользовательского интерфейса. Такой подход снижает задержки, связанные с сетевыми запросами и обработкой данных на сервере, и обеспечивает более плавный и отзывчивый пользовательский опыт. Выполнение логики в браузере также способствует повышению конфиденциальности данных, поскольку часть обработки выполняется локально, на устройстве пользователя.
Адаптивная политика, обученная с использованием алгоритма REINFORCE, динамически корректирует результаты поиска на основе наблюдаемых взаимодействий пользователя. Алгоритм REINFORCE, относящийся к классу алгоритмов обучения с подкреплением, позволяет системе оценивать качество различных вариантов ранжирования результатов поиска, основываясь на сигналах обратной связи от пользователя, таких как клики, время просмотра и другие метрики. В процессе обучения, политика постепенно адаптируется, увеличивая вероятность выдачи результатов, которые с большей вероятностью будут восприняты пользователем как релевантные и полезные, и уменьшая вероятность выдачи нерелевантных результатов. Такой подход обеспечивает персонализацию поиска и повышение его эффективности в долгосрочной перспективе.
Для повышения точности модели персонализации и адаптации поисковых результатов используется локальное хранилище IndexedDB. Эта технология позволяет сохранять данные о поведении пользователя — историю поисковых запросов, клики по результатам, время взаимодействия с контентом — непосредственно в браузере. В отличие от хранения данных на сервере, локальное хранение обеспечивает более быстрый доступ к информации и снижает нагрузку на серверные ресурсы. Накопление данных о поведении пользователя во времени, благодаря IndexedDB, позволяет модели адаптироваться к индивидуальным предпочтениям и улучшать релевантность поисковой выдачи без необходимости повторной отправки данных на сервер для переобучения.
Эффективные Языковые Модели для Персонализированных Результатов: Достижение Баланса
Малые языковые модели, в особенности семейство Phi, представляют собой привлекательное сочетание производительности и эффективности для решения задач, связанных с персонализированными результатами. В отличие от своих более крупных аналогов, требующих значительных вычислительных ресурсов, эти модели способны эффективно обрабатывать запросы пользователей непосредственно в браузере, не прибегая к помощи удаленных серверов. Такой подход не только снижает задержки и затраты на обработку, но и обеспечивает повышенную конфиденциальность данных, поскольку вся обработка осуществляется локально. Семейство Phi, благодаря оптимизированной архитектуре и тщательному обучению, демонстрирует впечатляющие результаты, приближающиеся к производительности более крупных моделей, при значительно меньшем размере и более высокой скорости работы. Это делает их идеальным выбором для приложений, где важна скорость отклика и ограниченные ресурсы, например, для мобильных устройств или веб-приложений.
Для ускорения обработки естественного языка и повышения отзывчивости приложений, модели малого размера, такие как семейство Phi, используют возможности WebGPU. Эта технология позволяет перенести вычисления непосредственно в браузер пользователя, минуя необходимость отправки запросов на удаленные серверы. В результате достигается значительное снижение задержек и повышение скорости обработки запросов, что особенно важно для интерактивных приложений и персонализированного поиска информации. Использование WebGPU открывает возможности для выполнения сложных вычислений непосредственно на устройстве пользователя, обеспечивая конфиденциальность и независимость от сетевого соединения.
Поиск информации на основе больших языковых моделей (LLM) представляет собой подход, позволяющий глубже понять намерения пользователя и, как следствие, повысить релевантность извлекаемой информации. Вместо простого сопоставления ключевых слов, LLM анализируют смысл запроса, учитывая контекст и нюансы языка. Это позволяет системе не только находить прямые совпадения, но и выявлять информацию, которая косвенно связана с потребностями пользователя. Такой подход особенно эффективен в ситуациях, когда запрос сформулирован нечетко или содержит скрытые предположения, поскольку LLM способны к более сложному семантическому анализу и интерпретации, значительно превосходя традиционные методы поиска.
Исследование продемонстрировало значительное повышение эффективности предсказания следующих действий пользователя при использовании локальной языковой модели, развернутой непосредственно в браузере. В частности, точность предсказания увеличилась на 24,0% по сравнению с общедоступными базовыми моделями. Кроме того, показатель Mean Reciprocal Rank (MRR), отражающий качество ранжирования релевантных результатов, достиг значения 0,47, что соответствует улучшению на 20,5%. Эти результаты свидетельствуют о том, что оптимизированные языковые модели, работающие на стороне клиента, способны обеспечить более точное и эффективное понимание намерений пользователя и предоставление персонализированных ответов.
Оценка Удобства Использования и Производительности Системы: Завершение и Перспективы
Оценка удобства использования разработанного браузерного расширения проводилась с использованием общепризнанной шкалы SUS (System Usability Scale). Результаты показали высокий показатель в 82.5 балла, что свидетельствует об исключительном уровне удобства для пользователей. Такой результат указывает на то, что расширение интуитивно понятно, эффективно и обеспечивает положительный пользовательский опыт, что является важным фактором для успешного внедрения и широкого распространения.
В рамках исследования продемонстрирована возможность создания поисковой системы, способной к глубокой персонализации. Это достигается за счёт объединения трёх ключевых компонентов: построения детальных моделей пользователей, выполнения вычислительных операций непосредственно в браузере и использования эффективных языковых моделей. Такой подход позволяет адаптировать результаты поиска к индивидуальным потребностям и предпочтениям каждого пользователя, обеспечивая более релевантные и полезные ответы. В отличие от традиционных поисковых систем, работающих с усредненными запросами, данная система анализирует поведение пользователя, его историю поиска и другие факторы, чтобы предоставить поисковые результаты, максимально соответствующие его текущим информационным потребностям.
Исследование продемонстрировало значительное сокращение средней длительности поисковой сессии благодаря внедренной системе. В ходе экспериментов было установлено, что пользователям требуется в среднем 5,2 запроса для достижения желаемого результата, что статистически достоверно меньше по сравнению с 6,8 запросами, необходимыми при использовании традиционных методов поиска. Данное снижение свидетельствует о повышении эффективности системы и улучшении пользовательского опыта, позволяя экономить время и усилия при поиске информации в сети.
Дальнейшие исследования будут направлены на углубление моделей пользователей, с целью более точного понимания индивидуальных потребностей и предпочтений. Особое внимание планируется уделить расширению набора учитываемых факторов, выходящих за рамки текущей истории поиска, включая контекстуальные данные и поведенческие паттерны. Параллельно, будет осуществляться разработка и тестирование более сложных адаптивных политик, способных динамически подстраиваться под изменяющиеся запросы и обеспечивать максимально релевантные результаты. Это позволит не только повысить эффективность поиска, но и создать поисковую систему, которая действительно предвосхищает потребности пользователя и предоставляет информацию в наиболее удобном и персонализированном виде.
Исследование демонстрирует стремление к созданию поисковых агентов, функционирующих непосредственно в браузере пользователя, что обеспечивает конфиденциальность и персонализацию. Подход, предложенный авторами, акцентирует внимание на адаптивном моделировании пользователя и использовании малых языковых моделей. Этот фокус на локальной обработке данных и адаптивности перекликается с мыслями Дональда Кнута: «Оптимизм — это вера в то, что всё будет хорошо, даже когда это не так». В данном случае, оптимизм проявляется в уверенности, что эффективный и персонализированный поиск возможен даже без передачи данных в облако, а именно через тонкое взаимодействие локальных моделей с предпочтениями пользователя. Создаваемая система стремится к элегантности, определяемой простотой и ясностью архитектуры, где структура определяет поведение агента.
Куда Ведет Этот Путь?
Представленная работа, демонстрируя возможность создания локальных агентов для помощи в поиске, открывает скорее вопросы, чем дает ответы. Элегантность решения — в его самодостаточности, однако эта же самодостаточность накладывает ограничения. Построение адаптивной модели пользователя исключительно на стороне клиента — задача нетривиальная, и неизбежно возникает вопрос о компромиссе между степенью персонализации и объемом необходимых ресурсов. Каждая новая зависимость от локальных моделей — это скрытая цена свободы от облачных вычислений, требующая осознанного выбора.
В дальнейшем, представляется важным исследовать не только повышение эффективности малых языковых моделей, но и методы их адаптации к конкретным задачам пользователя без ущерба для приватности. Интересным направлением является разработка механизмов, позволяющих агенту обучаться на неявных сигналах — стиле поиска, времени, затраченном на изучение результатов — не прибегая к явному сбору данных. Структура системы, определяющая ее поведение, должна учитывать не только текущие потребности, но и возможность эволюции и самообучения.
В конечном итоге, успех подобного подхода зависит от способности найти баланс между локальной вычислительной мощностью, сложностью модели и степенью персонализации. Это не просто техническая задача, но и философский вызов — стремление создать интеллектуального помощника, уважающего границы личного пространства.
Оригинал статьи: https://arxiv.org/pdf/2601.09928.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Согласие роя: когда разум распределён, а ошибки прощены.
- Редактирование изображений по запросу: новый уровень точности
- Очарование в огненном вихре: Динамика очарованных кварков в столкновениях тяжелых ионов
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Умная экономия: Как сжать ИИ без потери качества
- Искусственный интеллект в университете: кто за кого работу делает?
- Безопасность генерации изображений: новый вектор управления
- Квантовый импульс для несбалансированных данных
- Язык тела под присмотром ИИ: архитектура и гарантии
2026-01-16 21:59