Автор: Денис Аветисян
Исследователи представили масштабный набор данных MathDoc для оценки способности моделей извлекать информацию из реальных экзаменационных работ по математике и распознавать неполные или нечеткие данные.
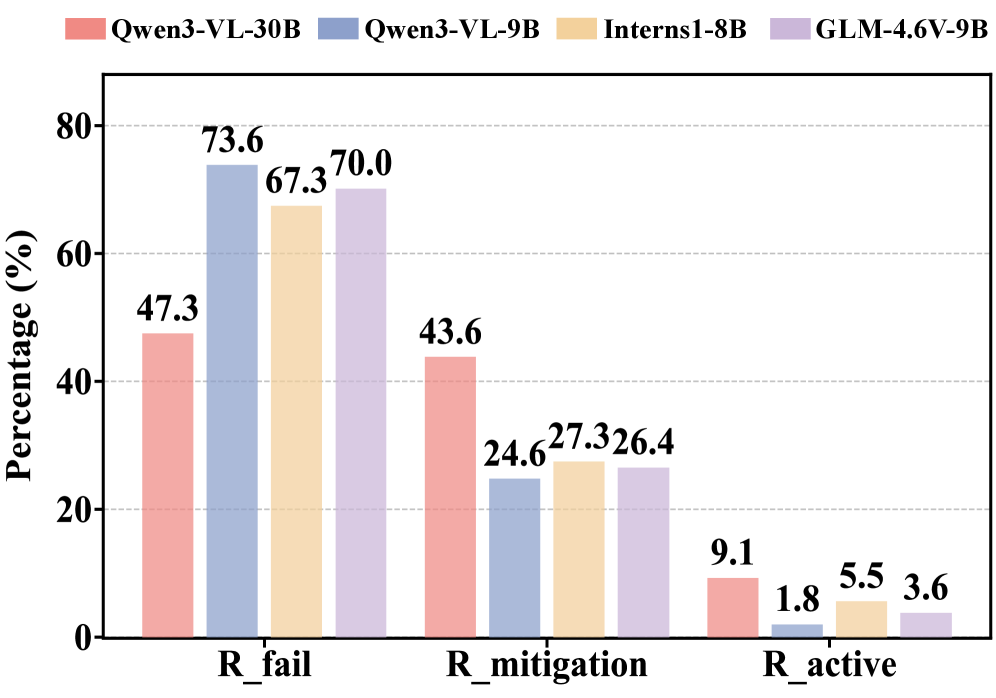
Оценка эффективности моделей извлечения информации и активного отказа от ответов на неполные или шумные математические документы.
Несмотря на успехи в области извлечения информации из документов, автоматизированное распознавание математических задач в реальных экзаменационных работах остается сложной задачей из-за высокого уровня визуального шума. В данной работе представлена новая методика оценки, получившая название ‘MathDoc: Benchmarking Structured Extraction and Active Refusal on Noisy Mathematics Exam Papers’, и новый набор данных, предназначенный для тестирования моделей машинного обучения на предмет извлечения структурированных математических задач и способности корректно отказываться от обработки нечитаемых фрагментов. Эксперименты с передовыми мультимодальными языковыми моделями показали, что, хотя они и демонстрируют высокую точность извлечения, зачастую не способны распознать и отклонить некачественные входные данные, выдавая уверенные, но неверные ответы. Не является ли способность к активному отказу от обработки неполных или поврежденных данных ключевым фактором для создания надежных систем интеллектуального обучения?
Иллюзия Точности: Проблема Шумных Документов
Существующие эталоны оценки оптического распознавания символов (OCR) зачастую не отражают реальную картину производительности при работе с документами, встречающимися в повседневной практике. Эти эталоны, как правило, базируются на чистых, хорошо отсканированных изображениях текста, что существенно отличается от документов, подверженных различным искажениям, шумам и дефектам. В результате, показатели, демонстрируемые на стандартных тестовых наборах, могут быть значительно завышены и не соответствовать эффективности OCR-систем при обработке реальных, «зашумленных» документов, содержащих рукописные вставки, пятна, размытия и другие артефакты. Это создает иллюзию высокой точности и затрудняет объективную оценку и сравнение различных OCR-алгоритмов в условиях, приближенных к реальным задачам извлечения информации.
Документы, содержащие рукописный текст и различные искажения, представляют собой серьезное препятствие для точной экстракции информации. Неровности бумаги, пятна, размытость, нечеткие линии и индивидуальный почерк значительно усложняют задачу автоматического распознавания символов и извлечения данных. Эти “шумные” документы, в отличие от четких, машинопечатных текстов, требуют от систем извлечения информации гораздо более сложной обработки и алгоритмов, способных к адаптации и компенсации дефектов. В результате, точность автоматического извлечения данных из таких документов существенно снижается, что создает проблемы для архивирования, анализа и использования содержащейся в них информации.
Традиционные методы оптического распознавания символов (OCR) и извлечения информации из документов испытывают значительные трудности при обработке некачественных входных данных. Суть проблемы заключается в том, что искажения, рукописные вставки и общий «шум» в документах приводят к неоднозначности и потере информации. Алгоритмы, разработанные для работы с чистыми, отсканированными текстами, часто не способны корректно интерпретировать нечеткие символы или восстановить утраченные фрагменты. Это приводит к ошибкам распознавания, неверной классификации данных и, в конечном итоге, к снижению эффективности всей системы извлечения информации. Преодоление этих сложностей требует разработки новых подходов, способных эффективно справляться с неопределенностью и восстанавливать потерянные данные, чтобы обеспечить надежную и точную обработку документов любого качества.

MathDoc: Реалистичный Тест для Систем Извлечения Информации
MathDoc — это масштабный бенчмарк, предназначенный для оценки систем извлечения информации из документов, представляющих собой варианты экзаменационных работ по математике для старших классов средней школы. Бенчмарк включает в себя большое количество экзаменационных работ, что позволяет проводить статистически значимые оценки производительности различных моделей и алгоритмов. Особенностью MathDoc является ориентация на оценку извлечения информации на уровне целого документа, а не отдельных элементов, что требует от систем понимания контекста и связей между различными частями работы. Набор данных включает в себя как правильно решенные, так и частично или полностью нерешенные работы, что позволяет оценить устойчивость систем к различным уровням сложности и неполноты входных данных.
Бенчмарк MathDoc намеренно использует сложные входные данные, представляющие собой зашумленные и неполные сканы школьных экзаменационных работ. Такой подход обусловлен стремлением к реалистичной оценке систем извлечения информации. В реальных сценариях обработки документов часто встречаются изображения низкого качества, неполные данные, а также различные артефакты, возникающие при сканировании или фотографировании. Использование таких данных позволяет более точно оценить устойчивость и надежность алгоритмов обработки документов в условиях, максимально приближенных к практическим задачам, в отличие от бенчмарков, использующих идеально чистые и полные документы.
Для количественной оценки степени деградации информации в извлеченных данных MathDoc использует метрики Information Loss Rate (ILR) и Semantic Similarity. ILR определяет долю потерянной информации при переходе от исходного математического выражения к его извлеченной версии, измеряя расхождения в символах, структуре и значениях. Semantic Similarity оценивает смысловое соответствие между исходным и извлеченным выражением, используя методы сопоставления LaTeX-кода и семантического анализа, что позволяет учитывать эквивалентные, но синтаксически отличающиеся представления. Эти метрики позволяют объективно сравнивать различные системы извлечения информации и оценивать их устойчивость к шуму и неполноте данных.
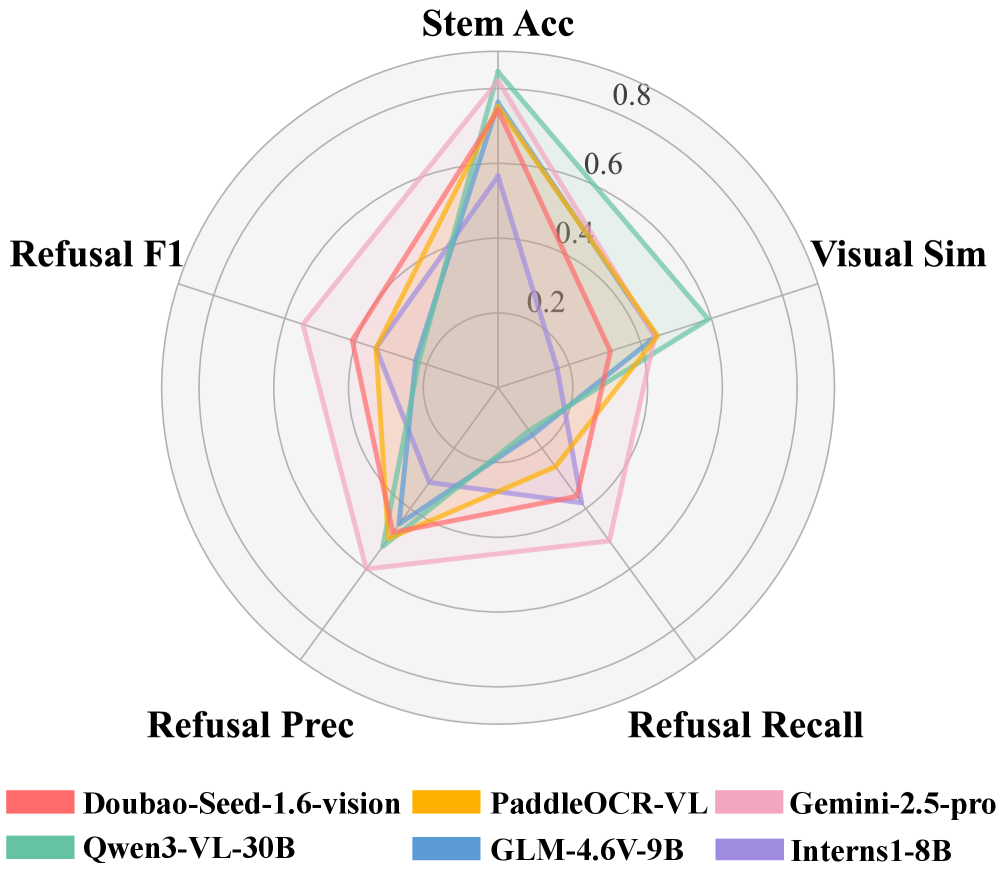
Оценка Мультимодальных Моделей на MathDoc
Мультимодальные большие языковые модели (MLLM) всё шире применяются для извлечения информации из документов, однако наблюдается значительная вариативность в их производительности. Различные модели демонстрируют существенные различия в точности и эффективности при решении задач, связанных с анализом и интерпретацией документов, что обусловлено архитектурными особенностями, объемом и качеством обучающих данных, а также спецификой решаемых задач. Несмотря на прогресс в области обработки естественного языка и компьютерного зрения, надежность и воспроизводимость результатов, полученных с использованием MLLM, остаются важными проблемами, требующими дальнейших исследований и оптимизации.
В ходе оценки моделей Qwen3-VL и Gemini-2.5-Pro на наборе данных MathDoc была достигнута точность определения основы математической задачи (Stem Accuracy) в 0.89 для модели Qwen3-VL-30B. Параллельно, была измерена визуальная схожесть (Visual Similarity) между предсказаниями модели и эталонными данными, которая составила 0.63 для той же модели Qwen3-VL-30B. Данные показатели отражают способность моделей извлекать и интерпретировать математические выражения и их структурные элементы из документов, представленных в формате изображений.
Исследование подтвердило значимость анализа компоновки (Layout Analysis) для точной интерпретации структуры сложных математических документов. Математические документы, в отличие от обычного текста, содержат элементы, расположенные нелинейно, такие как формулы, символы, таблицы и диаграммы. Корректное распознавание и понимание взаимосвязи между этими элементами критически важно для извлечения информации и решения математических задач. Недостаточное внимание к анализу компоновки приводит к ошибкам в интерпретации математических выражений, например, неправильному прочтению \in t_0^1 x^2 dx или путанице в индексах и степенях. В ходе исследования была продемонстрирована зависимость точности извлечения информации от качества анализа компоновки, что подчеркивает необходимость разработки и применения специализированных методов для обработки математических документов.
В ходе исследования оценивалась способность моделей к активному отказу — распознаванию и отклонению неполных или нечитаемых входных данных. Для провокации этой способности использовалось кадрирование изображений, в результате чего для модели Qwen3-VL-30B был зафиксирован показатель Refusal Recall в 0.14. Это указывает на низкий уровень проактивного отказа модели от обработки поврежденных или неполных документов, что свидетельствует о потенциальных проблемах с надежностью при работе с реальными данными, где качество изображений может варьироваться.
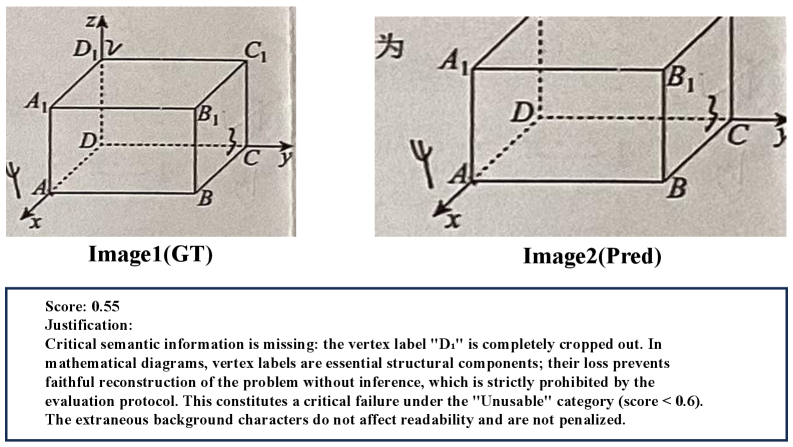
Последствия для Надежного Документооборота с ИИ
Исследования показали, что, несмотря на впечатляющие успехи в извлечении информации из документов, многие мультимодальные большие языковые модели (MLLM) демонстрируют недостаточную способность к активному отказу от обработки неполных или некорректных данных. В то время как некоторые модели эффективно извлекают содержательную информацию, другие склонны к обработке неполных запросов, что может привести к неточным или вводящим в заблуждение результатам. Эта уязвимость особенно критична в приложениях, требующих высокой степени надежности, таких как автоматизированная сборка тестов или персонализированное обучение, где даже незначительные ошибки могут иметь серьезные последствия. Неспособность модели корректно определить и отказаться от обработки неполных данных подчеркивает необходимость разработки более надежных и ответственных систем искусственного интеллекта, способных оценивать качество входных данных и избегать предоставления неточной информации.
Применение систем искусственного интеллекта для автоматизированной сборки тестов или персонализированного обучения несет в себе значительные риски, связанные с неточностью или неполнотой извлекаемой информации. Если модель не способна корректно определить недостающие данные или ошибочно интерпретирует содержание документа, это может привести к формированию некорректных тестовых заданий, вводящих в заблуждение, или к предоставлению неверных рекомендаций в процессе обучения. Последствия подобных ошибок могут быть серьезными, особенно в сферах, требующих высокой точности и надежности, таких как образование и профессиональная сертификация. Поэтому, обеспечение надежности систем искусственного интеллекта, работающих с документами, является критически важной задачей для предотвращения негативных последствий и повышения доверия к подобным технологиям.
Разработанный MathDoc benchmark представляет собой ценный инструмент для оценки и повышения надежности систем искусственного интеллекта, работающих с документами. В отличие от традиционных подходов, часто основанных на идеализированных и упрощенных данных, MathDoc предлагает реалистичные сценарии, включающие неполные, нечеткие или противоречивые математические документы. Это позволяет более точно оценить способность моделей не только извлекать информацию, но и распознавать случаи, когда данные недостаточны или ненадежны для принятия решений. Использование MathDoc способствует разработке систем, которые не просто выдают ответы, но и демонстрируют ответственное поведение, отказываясь от обработки некачественных данных и предупреждая о возможных ошибках, что критически важно для применения ИИ в областях, требующих высокой точности и надежности.
Исследования показали, что применение стратегии обрезки (cropping) изображений документов значительно повышает способность моделей искусственного интеллекта к ответственному отказу от обработки неполных или поврежденных данных. Данный подход, оцениваемый посредством показателя “Mitigation Rate”, позволяет моделям более эффективно распознавать и избегать обработки некачественных входных данных, тем самым снижая риск предоставления неточной или вводящей в заблуждение информации. Полученные результаты демонстрируют перспективный путь к разработке более надежных и ответственных систем искусственного интеллекта для работы с документами, где точность и полнота информации являются критически важными.
Дальнейшие исследования должны быть направлены на создание моделей искусственного интеллекта, ставящих во главу угла принципы ответственного подхода. Особое внимание следует уделить способности моделей корректно отказываться от обработки неполных или неоднозначных данных, а также прозрачной оценке уровня неопределенности в своих ответах. Разработка таких механизмов позволит значительно повысить надежность систем обработки документов, снизить риски, связанные с предоставлением неточной информации, и способствовать более осознанному и безопасному использованию технологий искусственного интеллекта в различных областях, включая образование и автоматизированное тестирование. Важно не просто извлекать информацию, но и уметь признавать собственные ограничения и сообщать о них пользователю.
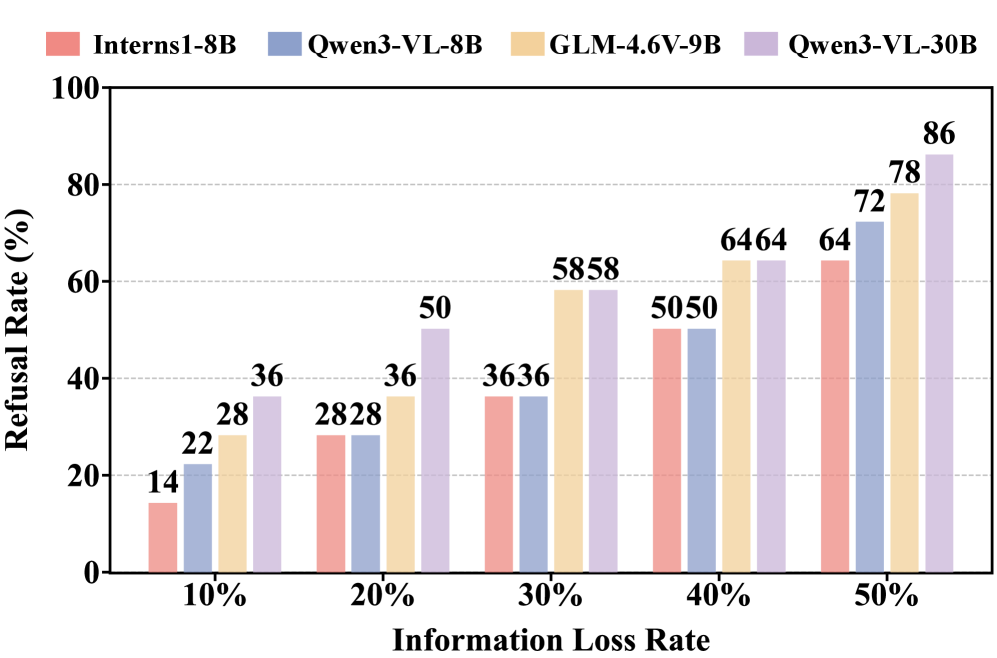
В представленной работе авторы вновь подтверждают старую истину: элегантная теория сталкивается с суровой реальностью данных. MathDoc, как новый бенчмарк для извлечения информации из математических работ, подчеркивает необходимость не просто распознавать символы, но и уметь отказывать в ответе, когда данные неполны или зашумлены. Это особенно важно, учитывая, что “революционные” модели зачастую оказываются хрупкими перед лицом реального мира. Как однажды заметил Дэвид Марр: «Успешные системы не обязательно должны быть элегантными, но они должны быть работоспособными». Именно работоспособность, а не теоретическая красота, определяет ценность любой системы, особенно в условиях постоянного технического долга.
Что дальше?
Представленный бенчмарк MathDoc, несомненно, выявит тех, кто умеет извлекать информацию из хаоса. Но давайте не будем питать иллюзий. Каждая «революционная» модель, способная вытаскивать ответы из каракулей на экзаменационных листах, быстро обзаведется своим «коллективным техдолгом» — случаями, когда она упрямо выдает неверные решения, основываясь на неполных данных. Тесты — это, как известно, лишь форма надежды, а не гарантия успеха.
Более того, способность к «активному отказу» — это лишь первый шаг. Модели научатся говорить «нет», но кто будет разбираться, когда это «нет» — признак разумной осторожности, а когда — банальный отказ от решения сложной задачи? Автоматизация, конечно, спасёт нас… но, к сожалению, уже приходилось наблюдать, как скрипты удаляют продакшен.
В конечном итоге, истинный прогресс не в улучшении точности извлечения, а в понимании границ применимости этих моделей. Настоящая ценность MathDoc, вероятно, не в поиске идеального решателя задач, а в создании набора примеров, которые демонстрируют, где заканчивается разум и начинается шум.
Оригинал статьи: https://arxiv.org/pdf/2601.10104.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Согласие роя: когда разум распределён, а ошибки прощены.
- Умная экономия: Как сжать ИИ без потери качества
- Безопасность генерации изображений: новый вектор управления
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Язык тела под присмотром ИИ: архитектура и гарантии
- Искусственный интеллект в университете: кто за кого работу делает?
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Разбираемся с разреженными автокодировщиками: Действительно ли они учатся?
- Самостоятельные агенты: Баланс безопасности и автономии
- Квантовый спектральный метод: Решение задач с непериодическими границами
2026-01-17 06:21