Автор: Денис Аветисян
Новый подход позволяет эффективно сжимать и адаптировать крупные языковые модели для работы на устройствах с ограниченными ресурсами, сохраняя при этом высокую точность.
В статье представлен комплексный метод, включающий дистилляцию знаний, адаптацию LoRA, квантизацию и оптимизатор Muon для повышения производительности и снижения задержек.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их развертывание на устройствах с ограниченными ресурсами остается сложной задачей. В данной работе, ‘Advancing Model Refinement: Muon-Optimized Distillation and Quantization for LLM Deployment’, предложен интегрированный подход, сочетающий квантизацию, адаптацию LoRA и дистилляцию знаний для эффективного сжатия и специализации LLM. Предложенная методика, включающая оптимизатор Muon, позволяет достичь до двукратного уменьшения размера модели при сохранении или улучшении производительности. Сможет ли данный подход существенно расширить возможности применения LLM в задачах, требующих высокой скорости и эффективности на периферийных устройствах?
Преодолевая Границы: Ограничения Масштабных Языковых Моделей
Несмотря на впечатляющие достижения в области обработки естественного языка, масштабные языковые модели представляют собой серьезную проблему с точки зрения внедрения и эффективности. Их огромный размер, обусловленный миллиардами параметров, требует колоссальных вычислительных ресурсов и памяти для хранения и обработки данных. Это затрудняет развертывание таких моделей на устройствах с ограниченными ресурсами, например, на мобильных телефонах или встроенных системах. Более того, большие модели потребляют значительное количество энергии, что создает экологические и экономические проблемы. Таким образом, поиск способов уменьшить размер и сложность этих моделей, не жертвуя при этом их способностями, является ключевой задачей для дальнейшего развития и широкого применения технологий искусственного интеллекта.
Несмотря на впечатляющие возможности, большие языковые модели зачастую демонстрируют трудности при решении задач, требующих сложного логического мышления и способности к обобщению. Исследования показывают, что модели, обученные на огромных объемах данных, могут успешно воспроизводить паттерны, но испытывают затруднения в ситуациях, требующих понимания причинно-следственных связей или применения знаний к новым, незнакомым контекстам. Например, при решении задач, требующих абстрактного мышления или здравого смысла, модели часто допускают ошибки, которые кажутся очевидными для человека. Это связано с тем, что модели, в основном, оперируют статистическими закономерностями, а не глубоким пониманием смысла, и поэтому не способны к истинному обобщению и адаптации к меняющимся условиям.
Вычислительные затраты, связанные с использованием больших языковых моделей, и сложность их адаптации к новым задачам существенно ограничивают возможности их практического применения. Несмотря на впечатляющие результаты, процесс получения ответов от этих моделей требует значительных ресурсов, что делает их развертывание на устройствах с ограниченной мощностью проблематичным. Кроме того, переобучение или тонкая настройка модели для решения принципиально новых задач часто требует огромного количества данных и времени, что делает адаптацию к меняющимся потребностям пользователей сложной и дорогостоящей. В связи с этим, разработка эффективных методов снижения вычислительной нагрузки и упрощения процесса адаптации моделей является ключевой задачей для расширения сферы их применения и обеспечения доступности передовых технологий обработки языка.
В связи с растущими потребностями в использовании больших языковых моделей (БЯМ), всё более актуальной становится задача их компрессии и оптимизации без потери качества работы. Разработка эффективных методов уменьшения размера моделей и снижения вычислительных затрат при сохранении точности и способности к обобщению является ключевым направлением современных исследований. Это включает в себя такие подходы, как квантизация весов, прунинг нейронных связей, дистилляция знаний и архитектурные инновации, направленные на создание более компактных и эффективных моделей. Успешное решение этой задачи позволит расширить возможности применения БЯМ на устройствах с ограниченными ресурсами и снизить экономические и экологические издержки, связанные с их эксплуатацией.
Сжатие Моделей: Стратегии Повышения Эффективности
Методы сжатия моделей, такие как прунинг (удаление неважных связей) и аппроксимация низким рангом, направлены на уменьшение размера модели за счет устранения избыточности параметров. Прунинг предполагает удаление весов с малыми значениями или не оказывающих существенного влияния на выходные данные, что снижает вычислительную сложность и объем памяти. Аппроксимация низким рангом использует разложение матриц весов на матрицы меньшего ранга, что позволяет представить модель с меньшим количеством параметров, сохраняя при этом ее функциональность. Оба подхода позволяют значительно сократить размер модели без существенной потери точности, особенно в глубоких нейронных сетях, где присутствует значительная избыточность параметров.
Квантование — это метод сжатия моделей, основанный на уменьшении разрядности, используемой для представления весов и активаций. Вместо стандартных 32-битных чисел с плавающей точкой (float32), квантование может использовать 8-битные целые числа (int8) или даже меньшую разрядность. Это значительно уменьшает размер модели и требования к памяти, что приводит к ускорению вычислений и снижению энергопотребления. Однако, снижение разрядности приводит к потере информации и, как следствие, к некоторой потере точности модели. Степень потери точности зависит от выбранного уровня квантования и архитектуры модели. Существуют различные методы квантования, включая post-training quantization и quantization-aware training, направленные на минимизацию потери точности.
Метод дистилляции знаний предполагает передачу информации из большой, сложной модели (учителя) в более компактную модель (ученика). В процессе обучения ученика используется не только истинная метка, но и “мягкие” вероятности, предсказанные учителем, что позволяет ученику лучше обобщать данные и сохранять значительную часть производительности учителя при значительно меньшем размере. Этот подход позволяет создавать компактные модели, пригодные для развертывания на устройствах с ограниченными ресурсами, сохраняя при этом высокую точность за счет использования знаний, полученных от более крупной модели.
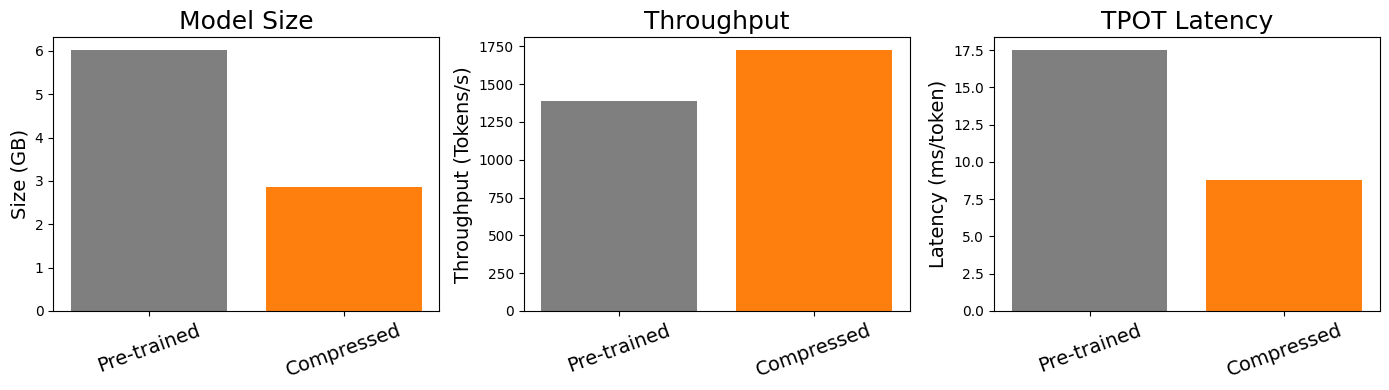
Методы компрессии моделей, такие как прунинг, квантизация и дистилляция, играют критически важную роль в развертывании больших языковых моделей (LLM) на устройствах с ограниченными ресурсами, включая мобильные телефоны и встроенные системы. Сокращение размера модели и снижение вычислительной сложности напрямую влияет на снижение стоимости инференса, что особенно важно для приложений, требующих обработки больших объемов данных или высокой пропускной способности. Уменьшение требований к памяти и энергии позволяет развертывать LLM в средах, где использование полноценных серверных ресурсов нецелесообразно или невозможно, расширяя возможности применения искусственного интеллекта в различных областях.
Адаптация с Низким Рангом и За Ее Пределами: Оптимизация Производительности
Адаптация с низким рангом (LoRA) представляет собой параметрически-эффективный метод дообучения, который заключается в добавлении к существующим весам модели обучаемых матриц низкого ранга. Вместо обновления всех параметров исходной модели, LoRA вводит небольшое количество новых, обучаемых параметров, что существенно снижает вычислительные затраты и требования к объему памяти. Матрицы низкого ранга разлагаются на произведение двух меньших матриц, что позволяет модели адаптироваться к новым задачам, сохраняя при этом большую часть знаний, закодированных в исходных весах. Данный подход особенно полезен при работе с большими языковыми моделями (LLM), где полное дообучение требует значительных ресурсов.
Метод адаптации моделей LLM с использованием малого количества параметров позволяет значительно снизить вычислительные затраты и требования к объему памяти по сравнению с полной перенастройкой (full fine-tuning). Вместо обновления всех параметров модели, этот подход обучает лишь небольшое подмножество, что существенно уменьшает количество обучаемых весов. Это достигается за счет добавления и обучения низкоранговых матриц, которые вносят изменения в существующие веса модели. В результате, для адаптации к новым задачам требуется значительно меньше вычислительных ресурсов и дискового пространства, что делает процесс более эффективным и доступным, особенно при работе с большими языковыми моделями.
Комбинация LoRA с методами пост-тренировочной квантизации, такими как GPTQ, позволяет значительно уменьшить размер модели при адаптации к новым задачам. GPTQ выполняет квантизацию весов обученной модели до 4-х или даже 3-х бит, что снижает требования к памяти и вычислительным ресурсам. В сочетании с LoRA, которая обучает лишь небольшое количество дополнительных параметров, общий размер адаптированной модели может быть уменьшен в два раза или более, без существенной потери в производительности. Это делает адаптацию больших языковых моделей более доступной и эффективной для задач, где ресурсы ограничены.
Генерация синтетических данных и использование библиотек, таких как vLLM, значительно ускоряют процессы обучения и развертывания больших языковых моделей. Синтетические данные позволяют создавать размеченные наборы данных для обучения моделей без необходимости ручной аннотации, что снижает затраты и время на подготовку данных. vLLM, являясь высокопроизводительной библиотекой для инференса, оптимизирует использование памяти и увеличивает пропускную способность, что позволяет быстрее развертывать и масштабировать обученные модели, обеспечивая эффективное обслуживание запросов пользователей. Комбинация этих подходов позволяет существенно сократить время, необходимое для адаптации и внедрения больших языковых моделей в производственную среду.
Оценка Рассуждений: Анализ Производительности Моделей
Для всесторонней оценки возможностей языковых моделей в области знаний и рассуждений используются комплексные бенчмарки, такие как MMLU, ARC-e, CommonsenseQA, OpenBookQA, HellaSwag, PIQA, SIQA и WinoGrande. Эти наборы данных представляют собой разнообразные задачи, требующие от моделей не просто запоминания фактов, но и применения логического мышления, понимания контекста и здравого смысла. MMLU проверяет знания в широком спектре дисциплин, ARC-e — способность решать научные вопросы, CommonsenseQA и SIQA — понимание повседневных ситуаций, а HellaSwag и WinoGrande — умение делать логические выводы в сложных сценариях. Использование этих бенчмарков позволяет исследователям объективно сравнивать различные модели и отслеживать прогресс в области искусственного интеллекта, определяя, насколько хорошо модели способны к решению задач, требующих реального интеллекта.
Исследования, проведенные с использованием комплексных оценочных наборов данных, таких как MMLU, ARC-e и других, наглядно демонстрируют, что современные методы сжатия моделей не только позволяют существенно уменьшить их размер, но и эффективно сохраняют способность к логическому мышлению и решению задач. Данные результаты подтверждают, что оптимизация архитектуры и параметров модели, в сочетании с техниками квантизации и дистилляции знаний, способны минимизировать потери точности, обеспечивая при этом значительное снижение вычислительных затрат. Это открывает возможности для развертывания сложных моделей на устройствах с ограниченными ресурсами, расширяя сферу их применения и делая технологии искусственного интеллекта более доступными.
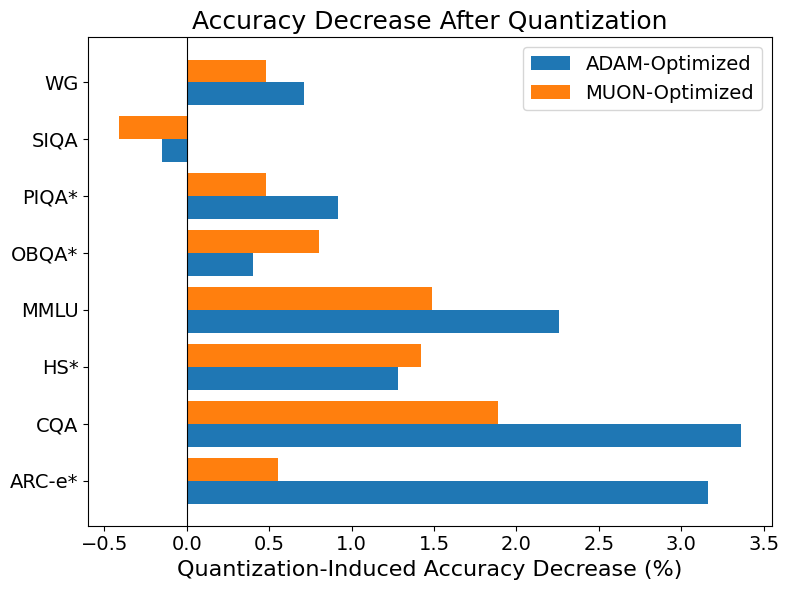
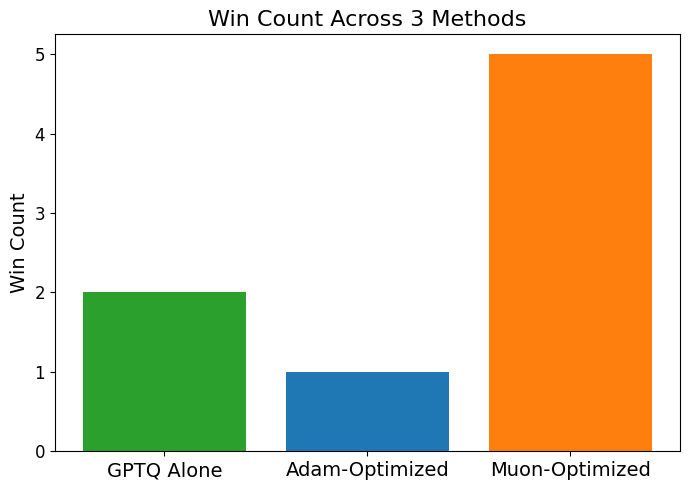
Исследование продемонстрировало, что комплексный подход к сжатию моделей, включающий в себя дистилляцию знаний, адаптацию LoRA, оптимизацию Muon и квантизацию GPTQ, превосходит использование лишь квантизации GPTQ по результатам оценки на пяти из восьми стандартных бенчмарков. Этот метод позволяет не только уменьшить размер модели, но и сохранить, а в некоторых случаях даже улучшить ее способность к рассуждениям и решению задач. Такое сочетание техник обеспечивает более эффективное сохранение ключевых знаний и логических связей в процессе сжатия, что приводит к более высокой точности и производительности модели после оптимизации.
Исследования показали, что модели, оптимизированные с использованием алгоритма Muon, демонстрируют значительно меньшую потерю точности при квантовании по сравнению с моделями, оптимизированными традиционным методом Adam. В частности, применительно к бенчмарку ARC-e, использование Muon позволило снизить потерю точности с 3% (при оптимизации Adam) до всего 0.5%. Данное улучшение свидетельствует о более эффективной адаптации параметров модели к процессу квантования, что позволяет сохранить большую часть исходной информации и, следовательно, повысить производительность сжатой модели. Этот результат указывает на потенциал Muon в качестве перспективного инструмента для создания компактных и эффективных моделей искусственного интеллекта, не уступающих по качеству своим полноразмерным аналогам.
Достижение до 50%-ного снижения задержки обработки каждого токена представляет собой значительный прорыв в оптимизации языковых моделей. Это означает, что обработка текста происходит значительно быстрее, что особенно важно для приложений, требующих оперативного ответа, таких как чат-боты, системы автоматического перевода и инструменты анализа текста в реальном времени. Уменьшение задержки не только повышает удобство использования, но и позволяет обрабатывать больший объем информации за единицу времени, что открывает новые возможности для масштабирования и расширения функциональности. Данный показатель свидетельствует об эффективности предложенного подхода к компрессии и оптимизации моделей, делая их более доступными и пригодными для широкого спектра применений, где скорость обработки является критически важным фактором.
Для достижения максимальной производительности современные модели машинного обучения нуждаются в тщательной настройке гиперпараметров. Методы байесовской оптимизации, в частности, позволяют эффективно исследовать пространство параметров, направляя поиск к оптимальным значениям с меньшим количеством вычислений, чем традиционные подходы. Алгоритмы, такие как Muon Optimizer, идут еще дальше, адаптируя процесс оптимизации к специфике модели и задачи, что позволяет добиться более высокой точности и устойчивости. В результате, точная настройка гиперпараметров, осуществляемая с помощью подобных инструментов, является ключевым фактором для раскрытия полного потенциала модели и обеспечения её эффективной работы в различных приложениях.
Успешное сжатие и оптимизация моделей открывает широкие возможности для их внедрения и доступности, оказывая значительное влияние на разнообразные сферы применения. Уменьшение размера модели и снижение вычислительных затрат позволяют развертывать искусственный интеллект на устройствах с ограниченными ресурсами, таких как мобильные телефоны и встроенные системы, делая передовые технологии доступными для более широкой аудитории. Это особенно важно для приложений, требующих обработки данных в реальном времени, например, в автономных транспортных средствах, персонализированной медицине и образовательных платформах. Помимо этого, оптимизированные модели способствуют снижению энергопотребления и уменьшению углеродного следа, делая искусственный интеллект более устойчивым и экологически безопасным решением.
Исследование, представленное в статье, демонстрирует стремление к созданию эффективных и адаптируемых систем искусственного интеллекта. Авторы фокусируются на оптимизации больших языковых моделей для развертывания на периферийных устройствах, что требует компромисса между точностью и скоростью работы. Этот процесс можно сравнить с естественным старением систем, когда необходимо поддерживать их функциональность, адаптируясь к меняющимся условиям. Как заметил Марвин Минский: «Самое важное — это идея, что интеллект — это не просто набор навыков, а способность учиться». В контексте данной работы, Muon Optimizer выступает инструментом, позволяющим модели обучаться и совершенствоваться даже после первоначального развертывания, гарантируя её актуальность и эффективность в долгосрочной перспективе. Подобный подход к развитию систем позволяет им «стареть достойно», сохраняя свою ценность и функциональность.
Что же впереди?
Представленная работа, словно тонкая настройка часового механизма, демонстрирует возможности оптимизации больших языковых моделей для работы на периферийных устройствах. Однако, подобно любому механизму, и эта система не избежит износа. Вопрос не в том, как замедлить старение модели — это лишь отсрочка неизбежного — а в том, как обеспечить её достойную эволюцию. Логирование, как хроника жизни системы, фиксирует не только успехи, но и зарождающиеся проблемы, связанные с адаптацией к постоянно меняющимся данным и требованиям.
Очевидно, что дальнейшее углубление в методы квантования и дистилляции — это лишь шлифовка существующих подходов. Более интересной представляется задача создания самоадаптирующихся моделей, способных к непрерывному обучению непосредственно на периферии, подобно живым организмам. Развертывание — это мгновение на оси времени, но именно в эти мгновения формируется будущее системы. Необходимо разработать методы, позволяющие моделям не просто сохранять актуальность, а предвидеть и адаптироваться к новым вызовам.
В конечном итоге, успех данной области исследований будет определяться не только техническими достижениями, но и способностью мыслить масштабно, признавая, что любая система, даже самая оптимизированная, — это лишь временный феномен в бесконечном потоке времени. Важно не просто сжать модель, а создать платформу для её непрерывной эволюции, подобно тому, как природа совершенствует свои творения на протяжении миллионов лет.
Оригинал статьи: https://arxiv.org/pdf/2601.09865.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Распознавание смыслов: новый подход к классификации документов
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Луна раскрывает свои секреты: Искусственный интеллект восстанавливает древнюю формулу
- Симфония Рассуждений: Управление Разнородными Моделями для Решения Сложных Задач
- Управляемое автодополнение кода: новые вызовы и решения
2026-01-17 08:05