Автор: Денис Аветисян
Исследователи предлагают подход, позволяющий нейросетям ‘думать’ над запросом, прежде чем создавать изображение, значительно улучшая его качество и соответствие смыслу.
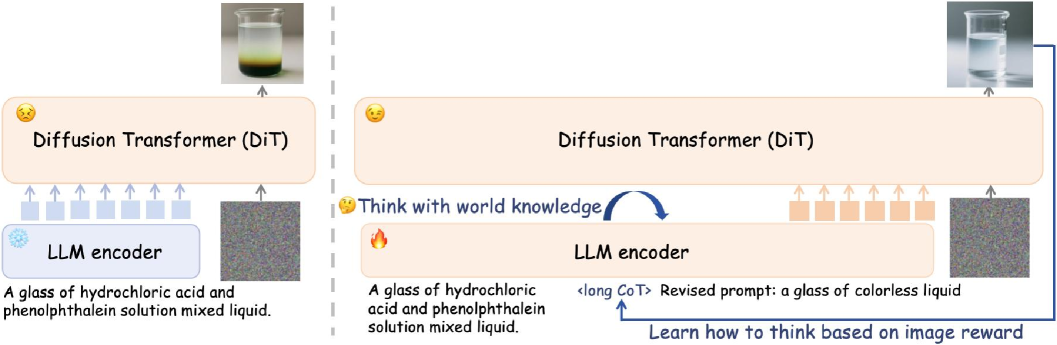
Представлена методика ‘Think-Then-Generate’ с использованием больших языковых моделей и стратегии Dual-GRPO для повышения семантической согласованности и визуального качества генерируемых изображений.
Несмотря на значительный прогресс в генерации изображений по текстовому описанию, существующие модели часто ограничиваются буквальным воспроизведением запроса, не используя возможности логического вывода. В работе «Think-Then-Generate: Reasoning-Aware Text-to-Image Diffusion with LLM Encoders» предложен новый подход, в котором языковая модель предварительно анализирует запрос, перефразируя его для более точной генерации изображения. Этот метод, основанный на парадигме «подумай-сначала-генерируй» и стратегии обучения Dual-GRPO, позволяет значительно повысить семантическую согласованность и реалистичность создаваемых изображений. Способны ли подобные модели совершить прорыв в создании действительно осмысленных и контекстуально богатых визуальных образов?
За гранью поверхностного восприятия: Проблема рассуждений в генерации изображений
Современные диффузионные модели преобразования текста в изображение демонстрируют впечатляющую способность создавать визуально привлекательные картинки, однако зачастую им не хватает глубокого концептуального понимания и способности корректно интерпретировать сложные инструкции. Несмотря на кажущуюся реалистичность генерируемых изображений, модели склонны к поверхностному восприятию запросов, что приводит к ошибкам в контексте и неточностям в деталях. Это связано с тем, что существующие алгоритмы полагаются преимущественно на сопоставление шаблонов, а не на истинное рассуждение, что ограничивает их возможности в обработке нюансированных промптов и создании осмысленных визуальных представлений.
Современные модели генерации изображений по текстовому описанию, несмотря на впечатляющую визуальную реалистичность, зачастую демонстрируют недостаток глубокого концептуального понимания. Ограничение связано с тем, что они полагаются преимущественно на распознавание закономерностей в данных, а не на истинное логическое мышление. Вместо того, чтобы анализировать смысл запроса и генерировать изображения, соответствующие контексту и тонкостям описания, модели просто сопоставляют слова с визуальными паттернами, которые они усвоили в процессе обучения. Это приводит к трудностям при интерпретации сложных или неоднозначных запросов, а также к созданию изображений, которые могут быть визуально привлекательными, но не соответствуют смысловому содержанию исходного текста, что подчеркивает необходимость разработки моделей, способных к более глубокому пониманию и рассуждению.
Современные системы генерации изображений по текстовому описанию, несмотря на впечатляющую визуальную реалистичность, зачастую демонстрируют ограниченные способности к глубокому пониманию контекста и выполнению сложных инструкций. Для выявления этого недостатка были разработаны специализированные бенчмарки, такие как T2I-ReasonBench и WISE Benchmark. Результаты тестирования показали, что существующие модели испытывают трудности с задачами, требующими логических умозаключений и понимания взаимосвязей между объектами. Представленный подход демонстрирует значительное улучшение в данной области, достигая показателя 0.79 на WISE Benchmark и точности в 68.3% на T2I-ReasonBench, что свидетельствует о возможности создания моделей, способных к более осмысленному и контекстуально релевантному формированию изображений.

Мыслить, прежде чем генерировать: Наделение моделей способностью к рассуждениям
Парадигма «Подумай-Затем-Генерируй» (T2G) вводит ключевой промежуточный этап: использование больших языковых моделей (LLM) для анализа запросов перед началом генерации изображения. В отличие от традиционных подходов, где запрос напрямую передается модели генерации, T2G сначала использует LLM для обработки и интерпретации входных данных. Этот предварительный этап позволяет модели более глубоко понять намерения пользователя и сложные инструкции, что потенциально приводит к более точным и релевантным визуальным результатам. По сути, LLM выполняет роль «мыслительного процесса», подготавливая информацию для последующей генерации изображения.
Метод «Мысли, а затем генерируй» (Think-Then-Generate) использует цепочку рассуждений (Chain-of-Thought, CoT) для явного представления процесса мышления модели перед генерацией изображения. CoT предполагает, что модель последовательно формулирует промежуточные шаги рассуждений, что позволяет ей более глубоко понять входные данные и выявить взаимосвязи между различными элементами запроса. Это позволяет модели не просто сопоставлять ключевые слова, а анализировать смысл и контекст, что приводит к более точной и релевантной генерации изображений, особенно в случае сложных или неоднозначных инструкций. Явное представление процесса рассуждений также облегчает отладку и улучшение модели, позволяя выявлять и исправлять ошибки в логике рассуждений.
Парадигма “Подумай-Затем-Генерируй” (T2G) решает проблемы предыдущих моделей генерации изображений, вводя этап рассуждения перед непосредственным созданием визуального контента. В отличие от моделей, напрямую преобразующих текстовый запрос в изображение, T2G использует цепочку рассуждений (Chain-of-Thought) для явного анализа и интерпретации инструкций. Это позволяет модели более точно понимать сложные запросы, учитывать контекст и генерировать изображения, соответствующие не только буквальному тексту запроса, но и подразумеваемому смыслу, что значительно повышает релевантность и качество результатов.

Двойная оптимизация GRPO: Совместное совершенствование энкодера и декодера для рассуждений
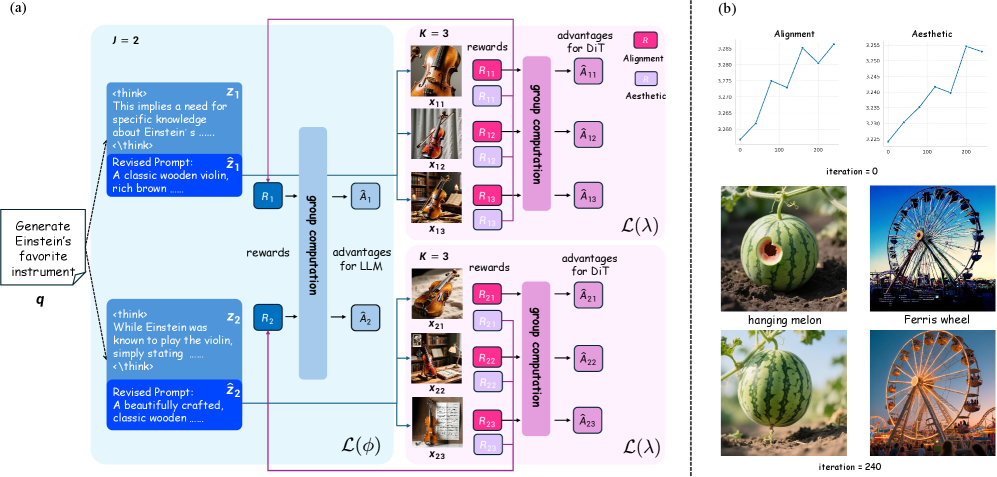
Dual-GRPO (Group Relative Policy Optimization) представляет собой новую стратегию обучения с подкреплением, предназначенную для совместной оптимизации LLM-энкодера и диффузионного декодера в рамках архитектуры T2G (Text-to-Image Generation). В отличие от традиционных подходов, оптимизирующих компоненты по отдельности, Dual-GRPO обеспечивает одновременное улучшение обеих частей системы. Это достигается путем определения политик для энкодера и декодера, которые учитывают их взаимосвязь и влияние друг на друга. Оптимизация проводится с учетом групповых относительных преимуществ, что позволяет модели более эффективно исследовать пространство параметров и достигать более высоких результатов в генерации изображений по текстовым запросам.
Метод Dual-GRPO использует формирование вознаграждений (Reward Shaping) для одновременной оптимизации энкодера и декодера. Вознаграждение формируется таким образом, чтобы стимулировать энкодер генерировать промпты, которые не только семантически точны и соответствуют заданному контексту, но и способствуют созданию высококачественных изображений декодером. Одновременно с этим, декодер оптимизируется для эффективного и точного создания изображений на основе полученных промптов, что обеспечивает совместную работу обеих частей системы для достижения оптимальных результатов. Такой подход позволяет максимизировать качество генерируемых изображений и улучшить общую производительность системы преобразования текста в изображение.
Метод Flow Matching повышает эффективность дискретизации (sampling) декодера, что приводит к улучшению общей производительности и качества генерируемых изображений. В отличие от традиционных методов диффузионного моделирования, Flow Matching позволяет декодеру быстрее и точнее генерировать изображения, соответствующие заданным условиям. Это особенно важно при решении сложных задач, требующих логического вывода и понимания контекста, поскольку более эффективное генерирование изображений напрямую связано с улучшением результатов в задачах, требующих рассуждений, таких как визуальное обоснование и интерпретация.
Для дальнейшей оптимизации LLM-энкодера была применена процедура контролируемой тонкой настройки (Supervised Fine-Tuning, SFT) с использованием модели Qwen2.5-VL, что позволило адаптировать энкодер к парадигме “Текст в изображение” (T2G) и повысить его способность к логическим рассуждениям. Результаты тестирования показали значительное улучшение производительности: модель превзошла Gemini-2.0 на бенчмарке T2I-ReasonBench и продемонстрировала прирост в 30% по сравнению с предыдущими открытыми моделями на бенчмарке WISE, достигнув итогового результата в 0.79.
Расширение творческих границ: Значение и перспективы развития
Возможность генерации изображений по сложным и тонким текстовым запросам открывает широкие перспективы для различных областей. В сфере создания контента это позволяет быстро и эффективно визуализировать идеи, экономя время и ресурсы. В дизайне подобные модели способны воплощать в жизнь самые смелые концепции, предлагая новые инструменты для творчества. Особенно значимо применение в научной визуализации, где сложные данные и процессы можно представить в наглядной и понятной форме, облегчая анализ и способствуя новым открытиям. Благодаря этой технологии, визуализация абстрактных понятий и сложных систем становится доступнее и эффективнее, что способствует развитию исследований и инноваций в различных областях знания.
Значительно улучшены возможности редактирования изображений благодаря новым подходам, позволяющим осуществлять точную и интуитивно понятную манипуляцию с помощью текстовых инструкций. Вместо сложных операций в графических редакторах, пользователи теперь могут просто описать желаемые изменения на естественном языке — например, «сделать небо более голубым» или «добавить тень под объект» — и система автоматически внесет соответствующие корректировки. Такой подход не только упрощает процесс редактирования, но и открывает новые возможности для творческого самовыражения, позволяя даже начинающим пользователям добиваться профессиональных результатов с минимальными усилиями. Это особенно ценно в сферах дизайна, рекламы и визуализации данных, где требуется быстрая и точная обработка большого количества изображений.
Данный подход, преодолевая ограничения предшествующих моделей, значительно упрощает взаимодействие человека и искусственного интеллекта, открывая новые возможности для творчества. Ранее сложные и требующие специальных навыков задачи визуализации теперь решаются посредством интуитивно понятных текстовых инструкций. Пользователи получают беспрецедентный уровень контроля над процессом создания изображений, воплощая в жизнь свои идеи с невиданной ранее легкостью и точностью. Это позволяет не только профессиональным дизайнерам и художникам, но и широкому кругу людей, не обладающих специальными знаниями, реализовывать свои визуальные концепции, что знаменует собой новый этап в развитии цифрового искусства и контента.
В будущем исследования будут направлены на расширение возможностей применения этих методов в более сложных сценариях, включая генерацию изображений, требующих глубокого понимания контекста и взаимосвязей между объектами. Особое внимание уделяется развитию способности моделей к логическому мышлению и рассуждению, что позволит им не просто визуализировать заданные параметры, но и интерпретировать сложные инструкции, выявлять скрытые смыслы и создавать изображения, соответствующие неявным запросам. Предполагается, что совершенствование этих способностей откроет новые горизонты в области автоматизированного создания контента, дизайна и научных визуализаций, а также позволит разрабатывать более интеллектуальные и интуитивно понятные системы взаимодействия человека и искусственного интеллекта.

Исследование демонстрирует, что современные генеративные модели часто ослеплены красотой случайности, создавая изображения, лишенные истинной семантической согласованности. Авторы предлагают подход «подумай, прежде чем генерировать», стремясь заставить машину не просто видеть слова, но и понимать их взаимосвязь. Это напоминает алхимию данных, где LLM выступает в роли катализатора, позволяя моделям не просто воспроизводить паттерны, а создавать осмысленные образы. Как говорил Эндрю Ын: «Мы находимся в моменте, когда сбор данных — это лишь малая часть проблемы. Важнее — умение извлечь из них смысл». И действительно, Dual-GRPO, представленный в работе, является попыткой направить этот хаос, заставить модель мыслить, а не просто запоминать.
Куда же дальше?
Предложенный подход, с его попыткой заставить нейронные сети сначала “подумать”, прежде чем создавать изображение, напоминает алхимика, стремящегося уловить неуловимую суть вещей. Однако, даже самые сложные заклинания дают сбои. Очевидно, что текущая архитектура, полагаясь на LLM-кодировщики, всё ещё страдает от хрупкости логических построений. Немногочисленные ошибки в рассуждениях модели могут привести к катастрофическим искажениям в конечном изображении. Данные — это всегда шум, и “чистые” данные — миф, придуманный менеджерами, но здесь этот шум особенно заметен.
Будущие исследования должны быть направлены не только на улучшение способности модели к рассуждению, но и на создание механизмов самокоррекции. Необходимо научить сеть распознавать собственные ошибки и адаптироваться к неполноте или противоречивости входных данных. Попытки объединить подходы, основанные на диффузии и потоковом сопоставлении, кажутся перспективными, но требуют значительных вычислительных ресурсов — магия требует крови, и GPU.
В конечном счете, вопрос не в том, чтобы создать идеальную модель, а в том, чтобы научиться понимать её ограничения. Истинное искусство — это не создание иллюзии совершенства, а принятие хаоса и умение извлекать из него красоту. Следующим шагом, возможно, станет отказ от попыток полного контроля и признание того, что случайность — неотъемлемая часть творческого процесса.
Оригинал статьи: https://arxiv.org/pdf/2601.10332.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эхо чёрных дыр: как квантовая гравитация меняет гравитационные волны
- Сверхпроводящая логика: управление магнитным полем
- Распознавание смыслов: новый подход к классификации документов
- Квантовый скачок в многомасштабном моделировании
- От миллиметровых волн к кубитному управлению: единый подход
- Ядерный синтез и Искусственный Интеллект: Новый подход к проектированию реакторов
- Визуальный интеллект для эмбриона: Искусственный интеллект описывает развитие зародыша
- Разреженность как ключ к скорости: Новая архитектура для мультимодальных моделей
- Квантовые вычисления: Честность и Прогресс
- Звук как помощник зрения: Новые горизонты генерации видео
2026-01-17 11:26