Автор: Денис Аветисян
Исследователи предлагают инновационный метод сжатия KV-кэша, позволяющий значительно уменьшить потребление памяти при работе с крупными нейронными сетями.
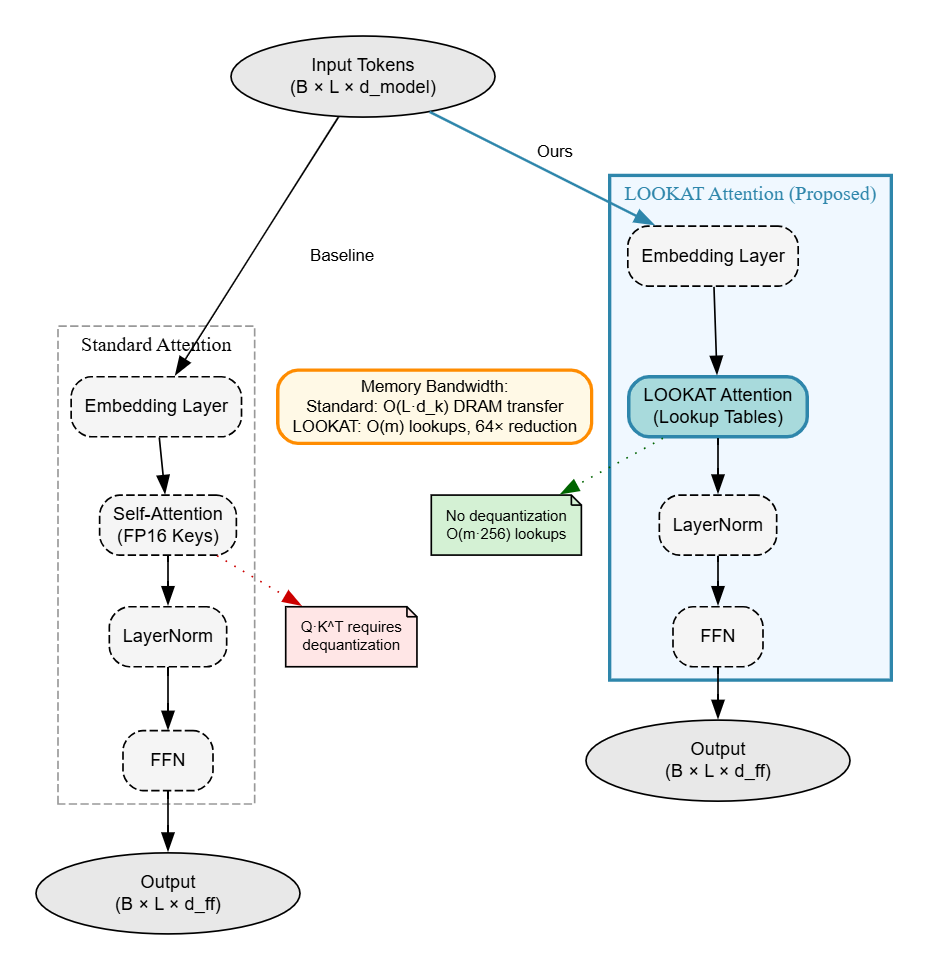
LOOKAT использует квантование произведений и асимметричное вычисление расстояний для достижения до 64-кратного сжатия и оптимизации работы на периферийных устройствах.
Современные большие языковые модели требуют всё больше вычислительных ресурсов, особенно при развертывании на периферийных устройствах. В данной работе представлена методика LOOKAT: Lookup-Optimized Key-Attention for Memory-Efficient Transformers, предлагающая новый подход к сжатию KV-кэша на основе квантования по произведению и асимметричного вычисления расстояний. LOOKAT позволяет достичь сжатия до 64 раз при сохранении высокой точности выходных данных, эффективно переводя ограничение с пропускной способности памяти на вычислительную мощность. Не откроет ли это новые возможности для развертывания сложных моделей ИИ непосредственно на мобильных устройствах и в условиях ограниченных ресурсов?
Квадратный корень из памяти: Ограничения внимания и путь к масштабируемости
Авторегрессионные модели, использующие механизм внимания, демонстрируют передовые результаты в различных задачах обработки последовательностей, однако их эффективность ограничена квадратичным ростом потребления памяти с увеличением длины входной последовательности. Это означает, что для обработки последовательности вдвое большей требуется учетверенное количество памяти, что быстро становится критичным при работе с длинными текстами или сложными данными. Несмотря на инновационные архитектуры и оптимизации, потребность в памяти для хранения промежуточных результатов, необходимых для вычисления внимания, экспоненциально увеличивается, что создает серьезные препятствия для масштабирования и применения этих моделей в ресурсоограниченных средах или при обработке очень больших объемов информации. Данное ограничение стимулирует поиск новых подходов к механизму внимания, направленных на снижение вычислительной сложности и минимизацию потребления памяти без существенной потери точности.
Ключевым компонентом эффективной работы механизмов внимания является KV-кэш — хранилище ключей и значений, необходимое для быстрого вычисления внимания на каждом шаге генерации. Однако, с увеличением длины обрабатываемой последовательности, размер KV-кэша растет квадратично, что быстро становится ограничивающим фактором. Этот эффект существенно затрудняет обработку длинных текстов или ведение продолжительных диалогов, поскольку объём доступной памяти для хранения кэша ограничен. В результате, производительность моделей внимания снижается, а возможности обработки контекста становятся ограниченными, препятствуя решению задач, требующих анализа больших объемов информации.
Ограничение, связанное с объемом памяти, оказывает существенное влияние на практическое применение механизмов внимания в задачах, требующих анализа больших объемов данных. Способность модели эффективно обрабатывать длинные последовательности текста, например, при анализе юридических документов, научных статей или ведении продолжительных диалогов, напрямую зависит от размера KV-кэша. Невозможность расширения этого кэша без значительного увеличения вычислительных затрат и времени отклика становится критическим препятствием для реализации сложных систем искусственного интеллекта, способных к глубокому пониманию и рассуждению над обширной информацией. В результате, существующие ограничения памяти формируют узкое место, сдерживающее прогресс в областях, где обработка длинных контекстов является ключевым требованием.
Квантизация: Сжатие ради эффективности
Квантизация, являясь ключевым методом сжатия моделей, заключается в снижении точности представления числовых значений, что напрямую уменьшает объем занимаемой памяти. Традиционно, веса и активации в нейронных сетях хранятся в формате с плавающей точкой (например, FP32 или FP16), требующем 32 или 16 бит на каждое число соответственно. Квантизация позволяет перевести эти значения в целочисленные форматы с меньшей разрядностью, такие как INT8 (8 бит) или INT4 (4 бита). Снижение точности приводит к уменьшению размера модели и, следовательно, снижению требований к памяти, но может сопровождаться некоторой потерей точности при выполнении расчетов. Эффективность квантизации зависит от выбранного формата представления и алгоритма, применяемого для минимизации потерь точности.
Квантизация INT8 и INT4 представляют собой различные подходы к снижению точности представления чисел в моделях машинного обучения, предлагая разные компромиссы между степенью сжатия и возможной потерей точности. INT8 квантизация использует 8-битное целое представление, обеспечивая умеренное сжатие и относительно небольшое влияние на производительность модели. В свою очередь, INT4 квантизация, использующая 4-битное целое представление, позволяет достичь более высокой степени сжатия, однако может привести к более заметному снижению точности и потребовать дополнительных мер по смягчению последствий, таких как калибровка или квантизация с учетом обучения. Выбор между этими методами зависит от конкретных требований к модели, доступным ресурсам и допустимому уровню потери точности.
Применение квантизации непосредственно к KV-кэшу представляет собой простой способ снижения потребления памяти, однако может негативно сказаться на производительности. Квантизация, уменьшая точность представления числовых значений в кэше ключей и значений, снижает объем необходимой памяти для хранения этих данных. Несмотря на простоту реализации, снижение точности может привести к увеличению частоты ошибок при извлечении данных из кэша, что потребует дополнительных вычислений или повторных запросов к модели, снижая общую скорость обработки. Степень влияния на производительность зависит от выбранного уровня квантизации и особенностей архитектуры модели.
LOOKAT: Квантование по подпространствам и асимметричные вычисления
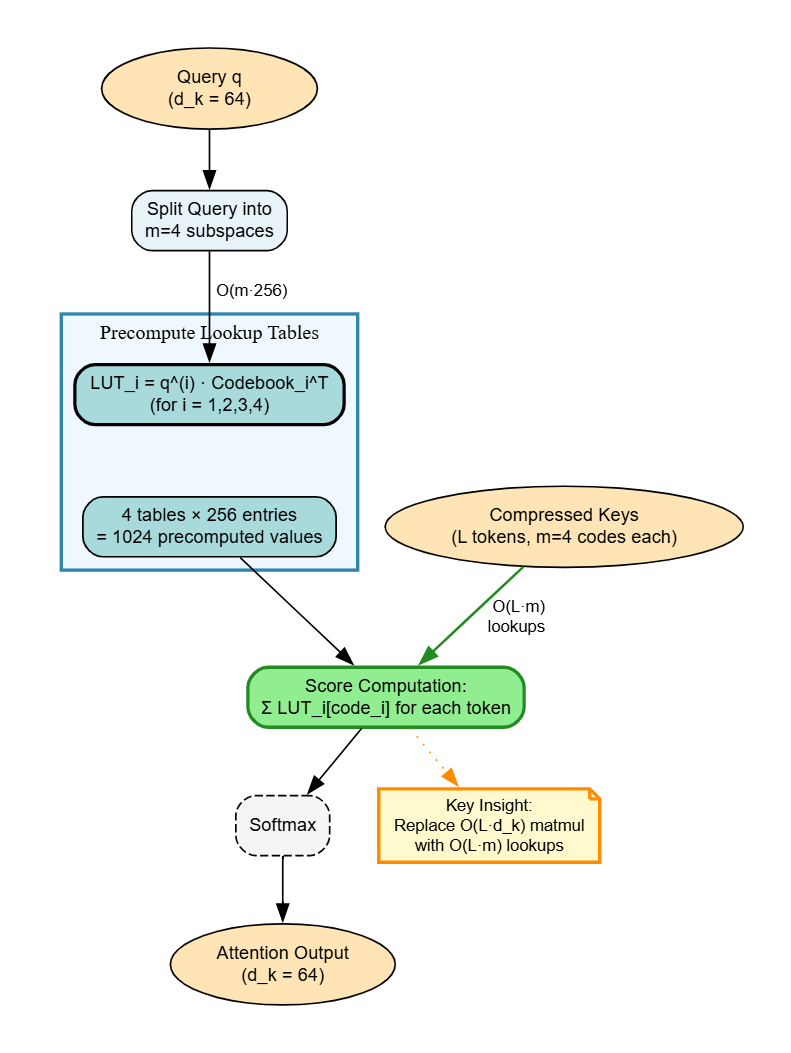
LOOKAT представляет собой новый подход к эффективной компрессии KV-кэша, объединяющий в себе метод Product Quantization (PQ) и Asymmetric Distance Computation (ADC). PQ позволяет разложить векторы на подпространства, что обеспечивает независимую квантизацию и снижение требований к объему памяти. В свою очередь, ADC поддерживает точность запросов при работе со сжатыми векторами базы данных, минимизируя потерю точности. Данная комбинация позволяет значительно уменьшить размер KV-кэша без существенной деградации производительности, что особенно важно для моделей с большим количеством параметров и ограниченными ресурсами памяти.
Квантование по подпространствам (Product Quantization) представляет собой метод сжатия векторов, основанный на их разложении на несколько подпространств. Каждое подпространство квантуется независимо, что позволяет значительно уменьшить объем памяти, необходимый для хранения данных. Вместо хранения исходного вектора, сохраняются коды, представляющие его проекции на каждое подпространство. Количество битов, используемых для кодирования каждой проекции, может быть подобрано индивидуально, оптимизируя баланс между степенью сжатия и сохранением точности. Данный подход позволяет добиться более высокой степени сжатия по сравнению с традиционными методами, такими как скалярное квантование, поскольку он учитывает структуру данных и корреляции между компонентами вектора.
Асимметричное вычисление расстояний (Asymmetric Distance Computation, ADC) позволяет сохранять точность запросов при работе со сжатыми векторами базы данных, минимизируя потерю точности. В отличие от симметричных методов, где и запросы, и векторы базы данных подвергаются одинаковому сжатию, ADC применяет более точное представление к векторам запросов, сохраняя их полноту. Сжатые векторы базы данных используются для вычисления расстояний, при этом более точное представление запросов компенсирует потерю информации, вызванную сжатием базы данных. Это позволяет достичь высокой точности при значительном снижении требований к хранению, превосходя по эффективности методы скалярной квантизации, такие как INT4, в плане сохранения точности при аналогичных или более высоких коэффициентах сжатия.
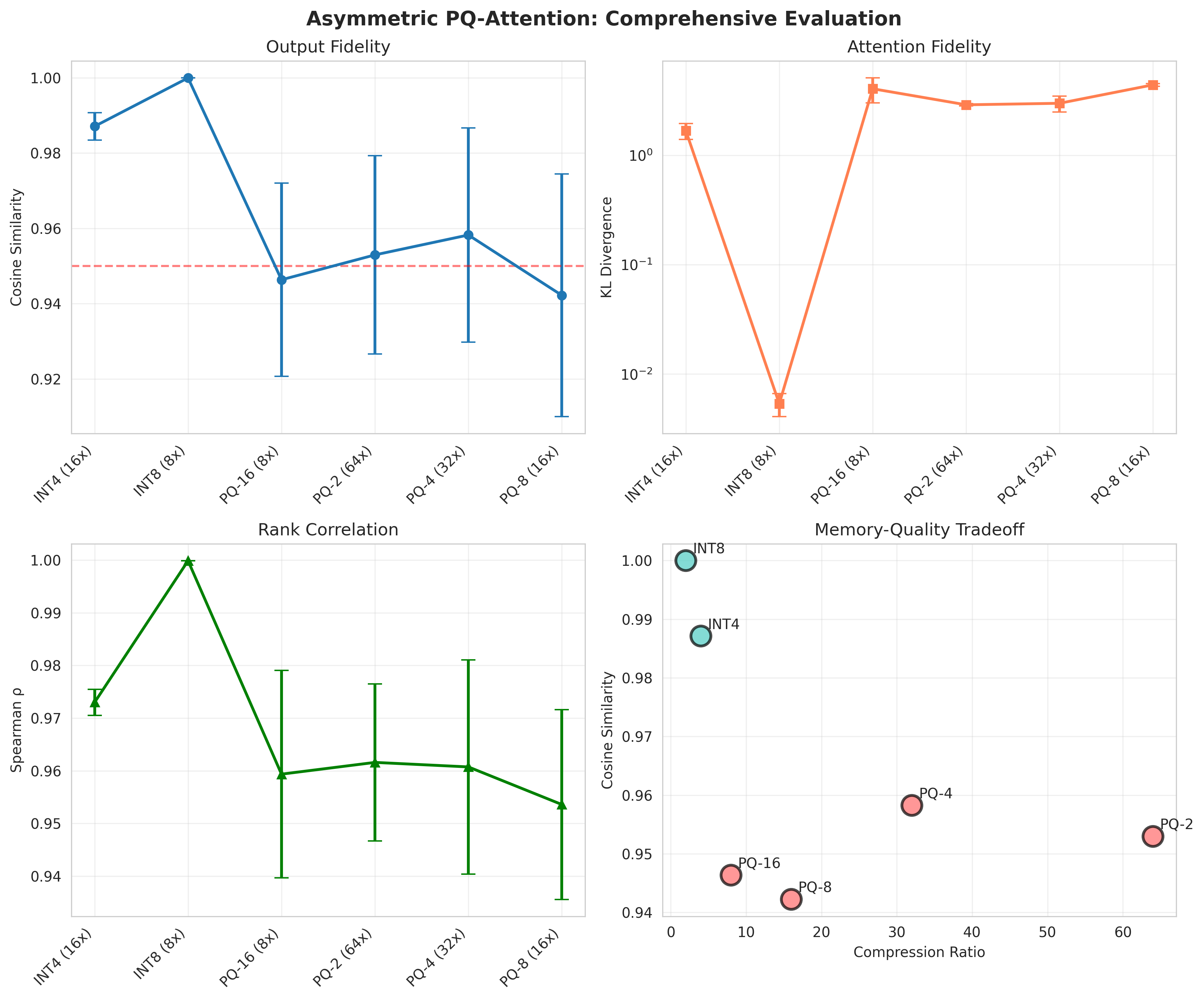
Экспериментальные результаты показали, что LOOKAT обеспечивает 64-кратное сжатие KV-кэша при сохранении более чем 95.7% точности выходных данных, измеренной с помощью косинусной близости (Cosine Similarity). Данный показатель значительно превосходит результаты, достигнутые методами скалярной квантизации, такими как INT4, демонстрируя существенное улучшение коэффициентов сжатия и сохранение качества представления данных в процессе сжатия.
Проверка качества внимания с помощью ранговой корреляции
Сохранение относительного ранжирования оценок внимания критически важно для обеспечения корректной работы механизма внимания. Внимание, как правило, фокусируется на наиболее релевантных частях входной последовательности, и порядок этих частей, определяемый рангом оценок внимания, напрямую влияет на качество выходных данных модели. Любое существенное изменение в этом ранжировании может привести к тому, что модель будет уделять внимание нерелевантным элементам, что, в свою очередь, снизит точность и надежность результатов. Поэтому, при сжатии или оптимизации механизма внимания, поддержание корреляции между исходным и сжатым ранжированием оценок является ключевым показателем сохранения функциональности и качества.
Механизм LOOKAT использует метрики ранговой корреляции, такие как коэффициент корреляции Спирмена, для подтверждения сохранения качества внимания после сжатия KV-кэша. Ранговая корреляция оценивает степень монотонной зависимости между исходными и сжатыми векторами внимания, фокусируясь на сохранении относительного порядка значений, а не на их абсолютных величинах. Высокие значения коэффициента Спирмена, как правило, превышающие 0.95 при различных коэффициентах сжатия, свидетельствуют о том, что сжатие KV-кэша посредством LOOKAT не приводит к существенным изменениям в относительной важности различных частей входной последовательности, что является критически важным для корректной работы механизма внимания.
Косинусное сходство, как метрика, дополнительно подтверждает сохранение векторных отношений после сжатия KV-кэша. Этот показатель измеряет косинус угла между векторами, представляющими входные данные до и после сжатия. Высокие значения косинусного сходства указывают на то, что векторы остаются близкими по направлению даже после применения алгоритма сжатия LOOKAT, что свидетельствует о минимальных изменениях в представлении информации и, следовательно, о сохранении качества внимания.
Результаты измерений показали, что применение LOOKAT-4 обеспечивает сохранение паттернов внимания, о чем свидетельствует значение расхождения Кульбака-Лейблера (KL Divergence) в диапазоне от 2.17 до 5.16 нат. При этом коэффициент ранговой корреляции Спирмена остается выше 0.95 для всех степеней сжатия. Это указывает на то, что сжатие KV-кэша с использованием LOOKAT не приводит к существенным изменениям в относительной важности различных частей входной последовательности, что подтверждает эффективность предложенного метода сохранения качества внимания.
Влияние на масштабируемость внимания и будущие исследования
Подход LOOKAT демонстрирует существенное снижение требований к объему памяти, открывая возможности для обработки более длинных последовательностей и сложных контекстов. Эта оптимизация достигается за счет инновационной схемы, позволяющей сжимать данные, необходимые для механизма внимания, без значительной потери производительности. Благодаря этому, модели, использующие LOOKAT, способны эффективно анализировать тексты и другие данные, содержащие больше информации, что особенно важно для таких задач, как машинный перевод, генерация текста и ответы на вопросы. Уменьшение потребления памяти не только расширяет возможности обработки данных, но и способствует снижению энергопотребления, делая использование подобных моделей более экономичным и экологичным.
Перспективные исследования направлены на синергетический эффект от объединения подхода LOOKAT с другими методами компрессии, такими как факторизация низкого ранга и отсечение внимания. Комбинирование LOOKAT с факторизацией низкого ранга позволит дополнительно уменьшить размерность весов и ускорить вычисления, а интеграция с отсечением внимания может привести к удалению менее значимых связей, что приведет к дальнейшему снижению вычислительной сложности и потребления памяти. Такой комбинированный подход, вероятно, откроет новые возможности для обработки еще более длинных последовательностей и сложных контекстов, значительно расширяя границы возможностей современных авторегрессионных моделей в различных областях обработки естественного языка.
Внимание с групповыми запросами (Grouped Query Attention) представляет собой альтернативный подход к повышению эффективности использования памяти в механизмах внимания. Традиционно, каждое head внимания обрабатывает независимый набор запросов, что требует значительных вычислительных ресурсов и памяти. Групповое внимание, напротив, объединяет несколько head для обработки общего набора запросов, тем самым снижая размерность head и, следовательно, уменьшая потребность в памяти и вычислительные затраты. Этот метод позволяет обрабатывать более длинные последовательности текста и более сложные контексты, сохраняя при этом приемлемую производительность. Сокращение размерности head не приводит к существенной потере точности, а в некоторых случаях может даже улучшить обобщающую способность модели, делая этот подход перспективным направлением для дальнейших исследований в области обработки естественного языка.
Достижения в области оптимизации механизма внимания, в частности, благодаря подходу LOOKAT, открывают путь к созданию существенно более масштабируемых и эффективных авторегрессионных моделей для широкого спектра задач обработки естественного языка. LOOKAT демонстрирует впечатляющее сжатие в 64 раза и теоретическое снижение вычислительной нагрузки на 10%, а также сокращение пропускной способности в 64 раза по сравнению со стандартным механизмом внимания. Это позволяет обрабатывать более длинные последовательности и сложные контексты, что критически важно для таких приложений, как машинный перевод, генерация текста и анализ больших объемов данных. Внедрение подобных оптимизаций значительно снижает требования к памяти и вычислительным ресурсам, делая передовые модели NLP доступнее и эффективнее для практического применения.
Исследование, представленное в данной работе, демонстрирует стремление к взлому архитектуры существующих систем, в данном случае — трансформеров. Авторы, подобно исследователям, ищущим скрытые закономерности, предлагают метод LOOKAT, который, используя квантование произведений и асимметричные вычисления расстояний, значительно сокращает объем KV-кэша. Это напоминает о словах Пола Эрдеша: «Работа не должна быть скучной». Умение находить элегантные решения, как в LOOKAT, освобождает ресурсы и открывает возможности для развертывания моделей на периферийных устройствах, что является ярким примером реверс-инжиниринга реальности и поиска оптимальных путей в заданных ограничениях. Эффективное сжатие, достигаемое LOOKAT, позволяет взглянуть на проблему памяти под новым углом, демонстрируя, что кажущиеся ограничения могут быть преодолены, если подойти к ним с нестандартной точки зрения.
Куда же дальше?
Представленный подход LOOKAT, безусловно, демонстрирует умение выжимать ресурсы из, казалось бы, исчерпанных систем. Однако, сжатие — это лишь симптом, а не лекарство. Истинная проблема заключается в экспоненциальном росте аппетитов моделей, и LOOKAT, как и любой другой метод сжатия, лишь оттягивает неизбежное. Важно понимать, что каждый эксплойт начинается с вопроса, а не с намерения. Будущие исследования, вероятно, сосредоточатся не на оптимизации существующих механизмов внимания, а на принципиально новых подходах к обработке информации, возможно, вдохновленных нейробиологией или даже квантовой физикой.
Особенно интересно рассмотреть асимметричные вычисления не только в контексте расстояний, но и в более широком смысле — создание моделей, где вычислительная сложность операций намеренно смещена в сторону тех, которые модель выполняет чаще. Это потребует глубокого понимания структуры данных и алгоритмов, а также готовности к радикальным компромиссам в точности ради скорости. Оптимизация для периферийных устройств — это лишь один из аспектов; гораздо интереснее представить модели, которые могут адаптироваться к ограниченным ресурсам “на лету”, перестраивая свою архитектуру в зависимости от доступных вычислительных мощностей.
В конечном счете, задача состоит не в том, чтобы заставить существующие модели работать на слабых устройствах, а в том, чтобы создать принципиально новые модели, которые будут изначально оптимизированы для работы в условиях ограниченных ресурсов. LOOKAT — это интересный шаг в этом направлении, но это лишь первый вопрос в длинной цепочке.
Оригинал статьи: https://arxiv.org/pdf/2601.10155.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Самостоятельные агенты: Баланс безопасности и автономии
- Безопасность генерации изображений: новый вектор управления
- Редактирование изображений по запросу: новый уровень точности
- Квантовое «восстановление» информации: обращение вспять шума
- Искусственный интеллект: между мифом и реальностью
- Квантовые Кластеры: Где Рождается Будущее?
- 3D-моделирование: оживляем объекты без оптимизации
- Разрушая иллюзию квантового превосходства: новый взгляд на Гауссовскую выборку бозонов
- Квантовый импульс для несбалансированных данных
2026-01-17 11:33