Автор: Денис Аветисян
Новое исследование подробно рассматривает потенциальные угрозы, связанные с самыми передовыми системами искусственного интеллекта, включая языковые и мультимодальные модели.
Проведен сравнительный анализ безопасности GPT-5.2, Gemini 3 Pro, Qwen3-VL, Doubao 1.8, Grok 4.1 Fast, Nano Banana Pro и Seedream 4.5, выявляющий пробелы в обеспечении безопасности и необходимость стандартизированных методов оценки.
Несмотря на значительные успехи в развитии больших языковых и мультимодальных моделей, вопрос об адекватном росте их безопасности остается открытым. В отчете ‘A Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Doubao 1.8, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5’ представлен комплексный анализ безопасности семи передовых моделей в задачах обработки языка, зрения и генерации изображений. Полученные результаты демонстрируют существенные различия в уровне безопасности и выявляют компромиссы между результатами на стандартных бенчмарках, устойчивостью к атакам и соответствием нормативным требованиям. Необходима ли разработка стандартизированных методов оценки безопасности для более точного прогнозирования рисков и обеспечения ответственного развития искусственного интеллекта?
Разоблачение уязвимостей: Почему безопасность LLM — это не просто фильтрация контента
Современные большие языковые модели, такие как Gemini-3-Pro и GPT-5.2, демонстрируют беспрецедентный уровень возможностей в обработке и генерации текста, что вызывает обоснованные опасения относительно потенциального вреда. Их растущая способность к правдоподобной имитации человеческой речи и пониманию сложных запросов открывает возможности для злоупотреблений, включая создание дезинформации, распространение предвзятых взглядов и даже автоматизацию вредоносных действий. По мере того, как эти модели становятся все более интегрированными в различные аспекты жизни, от новостных лент до систем поддержки принятия решений, возрастает необходимость в тщательной оценке и смягчении рисков, связанных с их использованием. Простое увеличение масштаба моделей не решает проблему безопасности; напротив, оно может усугубить существующие уязвимости и создать новые, требуя разработки принципиально новых подходов к обеспечению их надежности и соответствия этическим нормам.
Традиционные методы обеспечения безопасности, разработанные для более простых языковых моделей, оказываются недостаточными перед лицом стремительно растущих возможностей современных больших языковых моделей (LLM). Эти модели, такие как Gemini-3-Pro и GPT-5.2, демонстрируют способность к генерации текстов, все более неотличимых от созданных человеком, и способны к решению сложных задач, что требует принципиально новых подходов к оценке рисков. Простое обнаружение нежелательного контента уже не гарантирует безопасности, поскольку модели способны обходить существующие фильтры и генерировать тонко замаскированные вредоносные высказывания. В связи с этим, возникает необходимость в разработке комплексных систем оценки, включающих в себя не только анализ выходных данных, но и изучение внутренних механизмов работы модели, а также оценку ее устойчивости к различным типам атак и манипуляций. Такой подход позволит более эффективно выявлять и устранять потенциальные угрозы, связанные с использованием LLM, и обеспечивать их безопасное и ответственное применение.
Появление многомодальных моделей, таких как системы, объединяющие зрение и язык, значительно усложняет задачу обеспечения их безопасности. В отличие от традиционных языковых моделей, обрабатывающих исключительно текст, эти системы способны интерпретировать и генерировать контент на основе изображений, видео и других типов данных. Это требует принципиально нового подхода к оценке рисков, поскольку потенциальные уязвимости и вредоносные проявления могут возникать не только в текстовых ответах, но и в визуальной составляющей. Проверка безопасности таких моделей должна охватывать широкий спектр входных данных и сценариев, чтобы выявить и предотвратить нежелательные последствия, включая генерацию вводящего в заблуждение контента, распространение дезинформации или создание визуально оскорбительных материалов. Эффективная оценка требует разработки специализированных метрик и методов тестирования, учитывающих взаимодействие между различными модальностями и способность моделей к обобщению и адаптации.
Комплексная оценка LLM: От фильтрации контента к анализу внутренних механизмов
Оценка безопасности больших языковых моделей (LLM) в рамках LLM-Evaluation представляет собой комплексный подход, выходящий за рамки простой фильтрации контента. Данный фреймворк предполагает анализ LLM по нескольким измерениям, включая оценку предвзятости, токсичности, утечки персональных данных и потенциала для генерации дезинформации. Оценка проводится с использованием различных модальностей — текстовых запросов, визуальных входных данных и даже аудио — для всестороннего анализа поведения модели в различных сценариях. В отличие от простых систем цензуры, LLM-Evaluation направлена на выявление и смягчение рисков, связанных с непреднамеренным или злонамеренным использованием LLM, обеспечивая более надежную и безопасную работу моделей.
Методология оценки больших языковых моделей (LLM) использует как бенчмарк-тестирование для стандартизации оценок и обеспечения воспроизводимости результатов, так и адьверсарное тестирование для выявления скрытых уязвимостей. Бенчмарк-тестирование предполагает использование набора заранее определенных входных данных и метрик для количественной оценки производительности модели в различных задачах. Адьверсарное тестирование, в свою очередь, заключается в намеренном создании входных данных, предназначенных для обхода механизмов безопасности или выявления неожиданного поведения модели, что позволяет оценить ее устойчивость к манипуляциям и потенциальным угрозам. Комбинация этих подходов позволяет получить более полное и объективное представление о возможностях и ограничениях LLM.
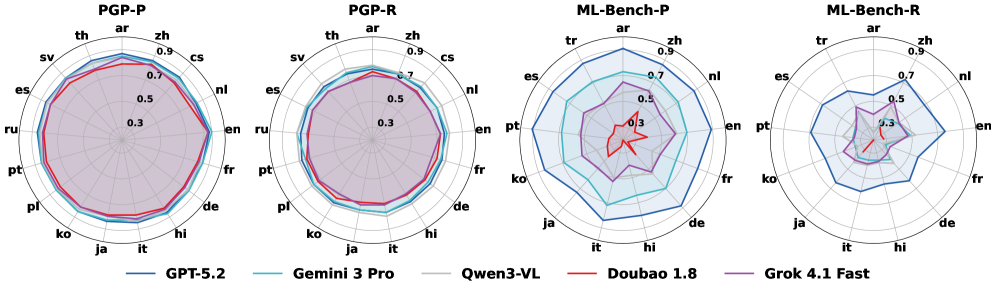
Оценка больших языковых моделей (LLM) включает в себя многоязычное тестирование для выявления и устранения предвзятости, а также обеспечения корректной и ответственной работы в различных языковых и культурных контекстах. Это достигается за счет использования разнообразных наборов данных и метрик оценки, специфичных для каждого языка, что позволяет выявить случаи, когда модель демонстрирует неравномерную производительность или выдает предвзятые результаты в зависимости от языка или культуры. Многоязычная оценка также предполагает анализ влияния лингвистических особенностей, таких как морфология и синтаксис, на поведение модели и ее способность понимать и генерировать текст на разных языках. Особое внимание уделяется адаптации моделей к языкам с ограниченными ресурсами и выработке стратегий для смягчения негативных последствий предвзятости в многоязычной среде.
Целенаправленные тесты: Разработка специализированных бенчмарков для оценки безопасности LLM
Наборы данных, такие как PolyGuardPrompt, разработаны для проведения всесторонней многоязычной оценки языковых моделей. Они позволяют выявить, как модели реагируют на незначительные лингвистические и культурные нюансы, представляя разнообразные запросы и анализируя выходные данные на предмет чувствительности к контексту и потенциальных предвзятостей. Оценка охватывает широкий спектр языков и культурных особенностей, включая идиомы, сленг, юмор и специфические культурные отсылки, чтобы определить, способна ли модель адекватно обрабатывать и интерпретировать информацию в различных культурных контекстах и избегать генерации оскорбительного или нерелевантного контента.
ML-Bench представляет собой стандартизированный подход к оценке соответствия моделей нормативным требованиям и этическим принципам. Эта платформа обеспечивает систематическую проверку на соответствие действующим законам, отраслевым стандартам и внутренним политикам безопасности. Оценка включает в себя анализ ответов моделей на запросы, потенциально нарушающие правовые нормы, а также проверку на предвзятость и дискриминацию. Результаты оценки ML-Bench предоставляют измеримые показатели соответствия, необходимые для аудита, сертификации и демонстрации ответственности при разработке и развертывании моделей машинного обучения.
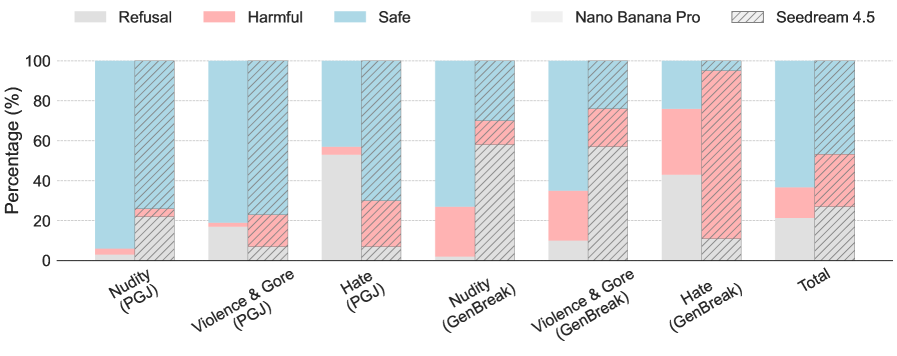
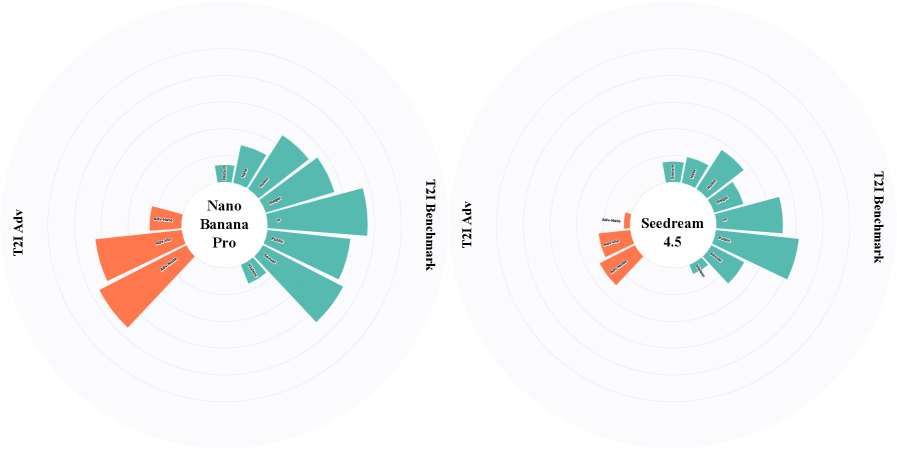
Для оценки безопасности генерируемых изображений используется бенчмарк T2I-Safety, предназначенный для тестирования моделей, таких как Nano-Banana-Pro и Seedream-4.5. Основная задача T2I-Safety — выявление и предотвращение генерации потенциально опасного контента, включая изображения, нарушающие этические нормы или содержащие нежелательные элементы. Оценка производится путем подачи моделям различных запросов и анализа выходных изображений на предмет соответствия заданным критериям безопасности, что позволяет разработчикам выявлять и устранять уязвимости.
В процессе оценки больших языковых моделей (LLM) активно используются методы состязательных атак (Adversarial Attacks) для выявления и устранения уязвимостей, которые могут быть использованы злоумышленниками. Эти атаки включают в себя намеренное создание входных данных, разработанных для обхода защитных механизмов модели и провоцирования нежелательного поведения, например, генерации вредоносного контента или раскрытия конфиденциальной информации. Целью применения состязательных атак является повышение устойчивости LLM к манипуляциям и обеспечение безопасной работы в реальных условиях, а также выявление слабых мест в архитектуре и алгоритмах моделей для их последующего улучшения.
Оценка ведущих LLM и генераторов изображений: Анализ уровня безопасности и выравнивания моделей
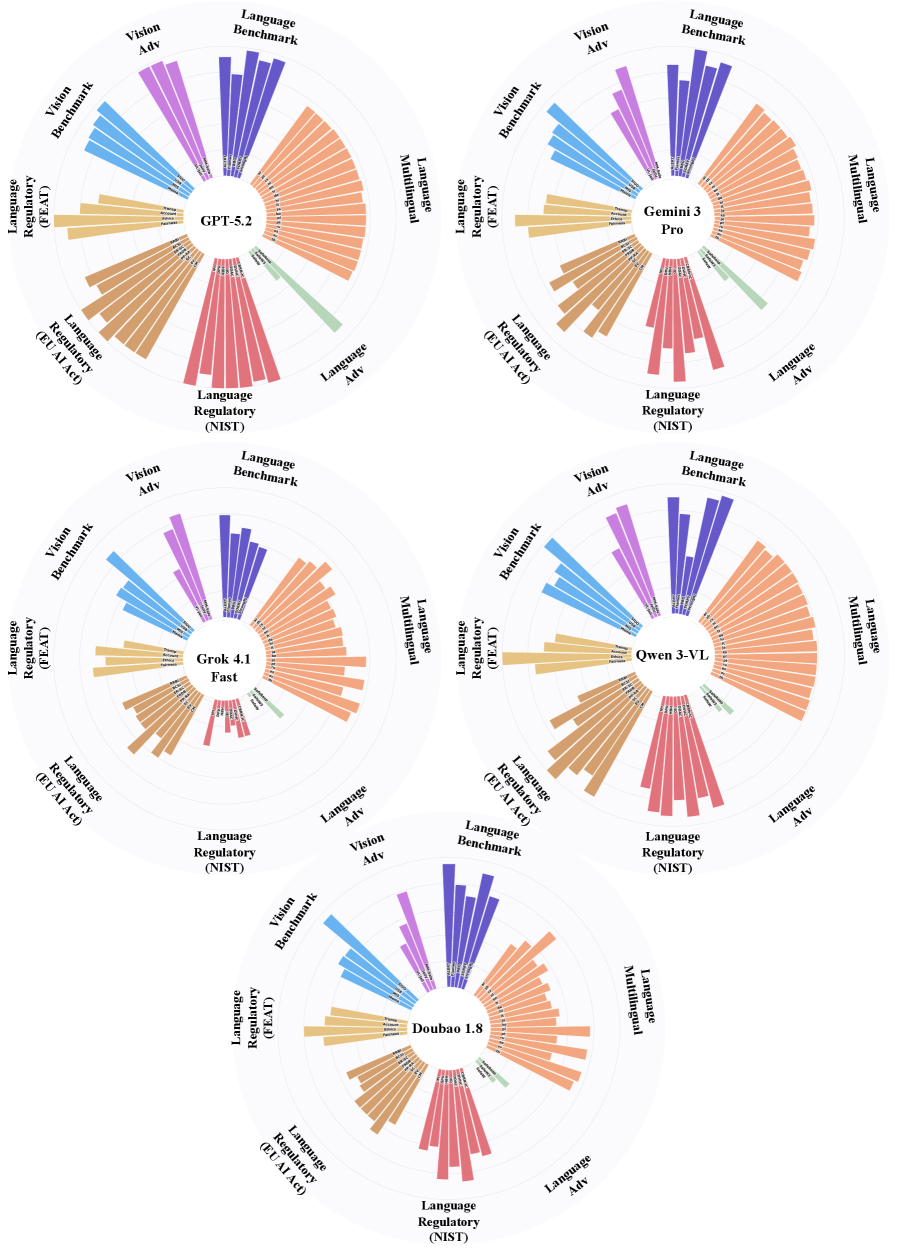
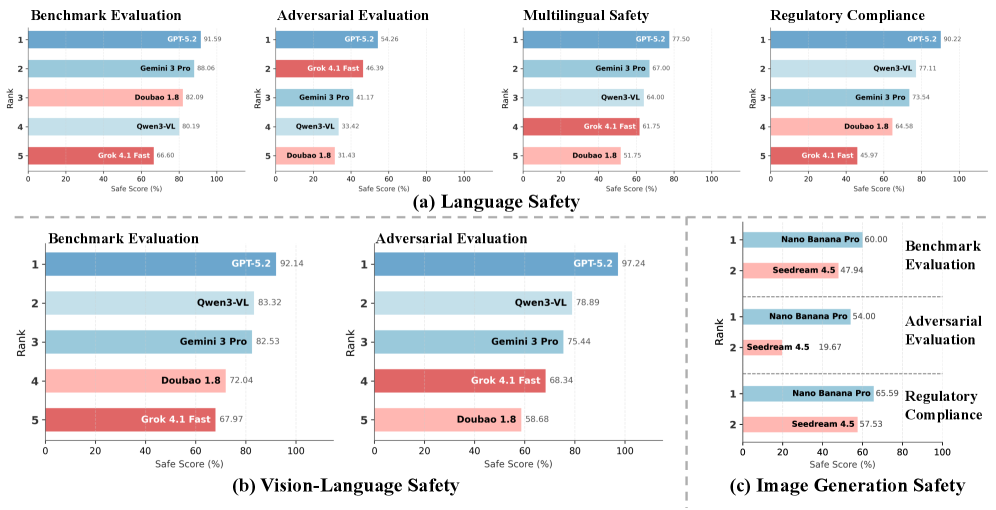
Исследование безопасности и устойчивости ведущих больших языковых моделей, таких как Gemini-3-Pro, Qwen3-VL, Grok-4.1-Fast и Doubao-1.8, выявило существенные различия в их способности противостоять потенциально вредоносным запросам и генерировать безопасный контент. Применение комплексных методик LLM-Evaluation показало, что каждая модель демонстрирует уникальный профиль безопасности, обусловленный архитектурными особенностями и применяемыми стратегиями обучения. В то время как некоторые модели проявляют высокую устойчивость к манипуляциям и способны эффективно фильтровать небезопасные запросы, другие оказываются более уязвимыми, что подчеркивает необходимость постоянного мониторинга и совершенствования механизмов защиты. Эти различия указывают на то, что универсального подхода к обеспечению безопасности не существует, и разработчики должны адаптировать стратегии защиты к специфическим характеристикам каждой модели.
Современные модели генерации изображений подвергаются тщательной проверке с использованием специализированных бенчмарков, таких как T2I-Safety, для обеспечения ответственного создания контента. Эти тесты направлены на выявление потенциальных уязвимостей, способных привести к генерации вредоносных, предвзятых или неприемлемых изображений. Оценка включает в себя проверку способности моделей избегать создания контента, нарушающего этические нормы или законодательство, а также устойчивость к манипуляциям и «взломам» через специально разработанные запросы. Результаты этих тестов позволяют разработчикам выявлять слабые места в алгоритмах и совершенствовать механизмы фильтрации, обеспечивая более безопасное и контролируемое создание визуального контента.
Результаты исследований подчеркивают необходимость постоянного мониторинга и итеративной доработки механизмов безопасности, направленных на противодействие возникающим угрозам. Поскольку модели искусственного интеллекта становятся все более сложными и широко распространенными, их потенциальная уязвимость к злоумышленникам и непреднамеренным последствиям также возрастает. Постоянный анализ эффективности существующих мер защиты и оперативное внедрение улучшений — критически важный процесс, позволяющий своевременно выявлять и нейтрализовывать новые векторы атак и обеспечивать ответственное развитие технологий. Эффективный мониторинг не ограничивается проверкой на известные угрозы, но и предполагает прогнозирование и адаптацию к еще не выявленным рискам, что требует постоянного совершенствования методов оценки и реагирования.
Результаты тестирования ведущих больших языковых моделей и генераторов изображений демонстрируют значительные различия в уровне безопасности. В частности, модель GPT-5.2 достигает 92.14% макро-среднего показателя безопасности при прохождении стандартных бенчмарков, что указывает на её высокую устойчивость к потенциально вредоносным запросам. В то же время, Nano Banana Pro и Seedream 4.5 демонстрируют значительно более низкие показатели — 54.00% и 19.67% соответственно — при воздействии со стороны специально разработанных “атакующих” запросов. Показатели соответствия нормативным требованиям также варьируются: Nano Banana Pro соответствует требованиям в 65.59% случаев, в то время как Seedream 4.5 — лишь в 57.53%. Эти данные подчеркивают необходимость тщательной оценки и постоянного улучшения механизмов безопасности для всех моделей генеративного искусственного интеллекта.
Выравнивание безопасности является фундаментальным аспектом разработки современных генеративных моделей. Этот процесс включает в себя применение специализированных методов и техник для направления поведения модели к безопасному и полезному взаимодействию с пользователем. Он подразумевает не только предотвращение генерации вредоносного или оскорбительного контента, но и активное поощрение создания ответов, соответствующих этическим нормам и общественным ценностям. Эффективное выравнивание безопасности требует постоянного мониторинга, анализа и адаптации алгоритмов, поскольку модели постоянно развиваются и подвергаются новым вызовам, связанным с потенциальными злоупотреблениями. Достижение высокого уровня выравнивания безопасности является ключевым фактором для обеспечения надежности и ответственности в сфере искусственного интеллекта, позволяя максимально использовать потенциал этих мощных инструментов, минимизируя при этом связанные с ними риски.
Исследование семи передовых моделей искусственного интеллекта выявляет закономерную картину: уровень безопасности варьируется в зависимости от модальности и архитектуры. Оценка устойчивости к враждебным атакам и соответствие нормативным требованиям демонстрируют, что даже самые мощные системы далеки от идеальной защиты. Как метко заметила Барбара Лисков: «Программы должны быть спроектированы таким образом, чтобы их можно было изменять без риска разрушения их основных принципов». Эта фраза особенно актуальна в контексте быстрого развития больших языковых и мультимодальных моделей, где постоянное совершенствование и адаптация необходимы для обеспечения их надёжности и безопасности. По сути, необходимо постоянно проводить реверс-инжиниринг систем, чтобы понять их слабые места и укрепить их защиту.
Куда двигаться дальше?
Представленный анализ семи передовых моделей искусственного интеллекта обнажил закономерную картину: безопасность — это не абсолютная величина, а скорее текучая граница, которую постоянно испытывают на прочность. Утверждения о “выравнивании” моделей следует воспринимать с долей скепсиса; каждое преодоленное ограничение — это лишь демонстрация того, насколько хрупка эта конструкция. Настоящая проверка — не в создании более сложных фильтров, а в понимании фундаментальных принципов, управляющих этими системами.
Очевидно, что существующие методики оценки недостаточны. Стандартизированные тесты, безусловно, важны, но они неизбежно отстают от эволюции моделей. Необходимо сместить фокус с обнаружения известных уязвимостей на проактивное выявление потенциальных векторов атак — по сути, научиться думать как система, а затем взломать её изнутри. Только так можно приблизиться к истинному пониманию границ безопасности.
В конечном счете, вопрос не в том, чтобы запереть интеллект в клетку правил, а в том, чтобы понять логику, которой он подчиняется. Именно в этом реверс-инжиниринге реальности и кроется подлинный прогресс. Пусть попытки ограничить эти модели будут лишь стимулом для поиска новых, более изящных способов их обхода — это и есть естественный ход вещей.
Оригинал статьи: https://arxiv.org/pdf/2601.10527.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самостоятельные агенты: Баланс безопасности и автономии
- Безопасность генерации изображений: новый вектор управления
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Искусственный интеллект: между мифом и реальностью
- Редактирование изображений по запросу: новый уровень точности
- Квантовое «восстановление» информации: обращение вспять шума
- Квантовые Кластеры: Где Рождается Будущее?
- 3D-моделирование: оживляем объекты без оптимизации
- Квантовый импульс для несбалансированных данных
- Разрушая иллюзию квантового превосходства: новый взгляд на Гауссовскую выборку бозонов
2026-01-17 19:48