Автор: Денис Аветисян
В статье представлена формальная методика для выделения ключевых причинно-следственных связей путём упрощения сложных моделей, что позволяет более эффективно анализировать данные и делать обоснованные выводы.
Предложенная работа формализует процесс упрощения направленных ациклических графов (DAG) для причинного вывода с использованием интервенционных данных и гарантирует идентифицируемость полученных абстракций.
Построение полных причинно-следственных моделей на основе направленных ациклических графов (DAG) часто затруднено из-за сложности и избыточности исходных данных. В работе ‘Coarsening Causal DAG Models’ предложен формальный подход к причинно-следственному абстрагированию посредством упрощения DAG, позволяющий выделить наиболее значимые связи. Авторы доказывают теоретическую возможность однозначной идентификации таких упрощенных моделей в различных интервенционных сценариях и разрабатывают эффективный алгоритм для их обучения на данных, полученных в результате экспериментов с неизвестными точками вмешательства. Какие перспективы открывает этот подход для анализа сложных систем и построения более интерпретируемых причинно-следственных моделей?
От сложности к абстракции: Неизбежность упрощения
Анализ причинно-следственных связей в сложных системах зачастую опирается на использование направленных ациклических графов (DAG), представляющих собой мощный инструмент для моделирования зависимостей между переменными. Однако, с увеличением числа переменных, сложность этих графов экспоненциально возрастает, что приводит к вычислительной непрактичности. Даже при наличии современных вычислительных мощностей, обработка и анализ DAG с большим количеством узлов становится затруднительным, поскольку требуемые ресурсы для вычислений и хранения данных быстро превышают доступные возможности. Эта проблема особенно актуальна в таких областях, как системная биология, экономика и социальные науки, где количество рассматриваемых факторов может быть очень велико, что требует поиска эффективных методов упрощения и агрегации информации.
В контексте анализа причинно-следственных связей в сложных системах, абстракция играет ключевую роль, позволяя упростить представление реальности. Этот подход заключается в объединении отдельных переменных в более общие группы, что создает представление системы на более высоком уровне. Вместо детального рассмотрения каждого элемента, исследователь фокусируется на агрегированных показателях, что существенно снижает вычислительную сложность и позволяет выявить общие закономерности. По сути, абстракция позволяет «отфильтровать» несущественные детали, акцентируя внимание на наиболее важных факторах, определяющих поведение системы. Использование абстракции — это не упрощение ради упрощения, а осознанный выбор уровня детализации, необходимый для эффективного анализа и построения адекватных моделей.
Определение оптимального способа абстрагирования — то есть, объединения переменных в более крупные группы — представляет собой сложную задачу в анализе причинно-следственных связей. Некорректное абстрагирование может привести к сокрытию важных взаимосвязей, искажая понимание системы и приводя к ошибочным выводам. Суть проблемы заключается в том, что объединение переменных, не учитывающее их фактическое влияние друг на друга, способно замаскировать критически важные каналы причинности, приводя к упрощенной и неточной модели реальности. Таким образом, выбор переменных для объединения требует тщательного анализа и учета структуры причинно-следственной сети, чтобы избежать потери значимой информации.
Для эффективной абстракции сложных систем, представленных направленными ациклическими графами (DAG), необходимы систематические методы упрощения этих графов — так называемого “укрупнения”. Этот процесс заключается в объединении отдельных переменных в более общие группы, однако ключевой задачей является сохранение существенной причинно-следственной информации при этом. Неправильное укрупнение может скрыть важные взаимосвязи, искажая результаты анализа. Поэтому разработка алгоритмов, позволяющих целенаправленно упрощать DAG, выделяя наиболее значимые причинные пути и игнорируя несущественные детали, является критически важной для успешного применения методов причинного вывода к реальным, сложным системам. Такие методы позволяют снизить вычислительную сложность, сохраняя при этом адекватное представление о причинно-следственных связях в исследуемой системе.
Интервенционное упрощение: Принцип, который работает
Интервенционное упрощение (Interventional Coarsening) представляет собой формальный метод определения абстракции, основанный на объединении переменных в соответствии с их схожим реакциям на интервенции — преднамеренные воздействия на систему. В рамках этого подхода, переменные, демонстрирующие идентичное или близкое поведение при одинаковых внешних воздействиях, рассматриваются как эквивалентные и могут быть представлены единой, более грубой переменной. Это позволяет снизить сложность модели, сохраняя при этом ключевые причинно-следственные связи и обеспечивая возможность анализа системы на более высоком уровне абстракции. Суть метода заключается в выявлении общих закономерностей в ответах переменных на контролируемые изменения в системе.
Основная идея интервенционного укрупнения заключается в идентификации переменных, демонстрирующих схожее поведение при воздействии одинаковых интервенций — преднамеренных манипуляций с системой. Если несколько переменных реагируют на одну и ту же интервенцию аналогичным образом, они могут быть представлены как единая, более грубая переменная. Этот подход позволяет снизить сложность модели, сохраняя при этом ключевые характеристики системы, определяемые воздействием извне. Укрупнение происходит путем объединения переменных, которые имеют схожие отклики на идентичные внешние воздействия, что позволяет упростить анализ и моделирование сложных систем без потери существенной информации о причинно-следственных связях.
Процесс интервенционного упрощения опирается на определение сигнатуры потомков интервенции — множества интервенций, которые влияют на конкретный узел. Эта сигнатура формируется путем анализа всех возможных манипуляций системой и определения, какие из них приводят к изменению значения данного узла. Узлы, имеющие идентичные или схожие сигнатуры потомков интервенции, считаются эквивалентными с точки зрения влияния внешних воздействий и могут быть объединены в одну более грубую переменную. Таким образом, \Sigma(X) представляет собой множество всех интервенций, оказывающих влияние на переменную X, и используется для определения возможности объединения переменных в процессе интервенционного упрощения.
Использование сигнатуры потомков интервенций в процессе укрупнения позволяет сохранить причинно-следственные связи, возникающие при внешних воздействиях на систему. Вместо анализа всех возможных зависимостей между переменными, метод фокусируется исключительно на тех, которые подвержены влиянию одних и тех же интервенций. Это гарантирует, что укрупненная модель, полученная в результате абстракции, будет корректно отражать эффект внешнего воздействия на систему, поскольку причинные связи, определенные через сигнатуру потомков интервенций, остаются неизменными. Таким образом, абстракция не искажает результаты предсказаний при манипуляциях, что критически важно для задач моделирования и управления.
Уточнение разбиения: Статистическая шлифовка абстракции
Итеративное уточнение разбиения (Partition Refinement) представляет собой метод последовательного разделения и объединения переменных на основе статистической схожести их реакций на вмешательства. Процесс начинается с начального разбиения множества переменных-потомков вмешательства. Далее, на каждом шаге, алгоритм оценивает статистическую значимость различий между группами переменных внутри каждого разбиения. Если различия существенны, разбиение уточняется, то есть группы разделяются на более мелкие подгруппы. В противном случае, соседние группы, демонстрирующие высокую статистическую схожесть, объединяются. Этот процесс повторяется до достижения оптимального уровня обобщения, при котором сохраняется максимальное количество информации о причинно-следственных связях, а сложность модели минимизируется.
Для оценки статистической значимости различий в эффектах интервенций на различные переменные используется ряд статистических тестов, включая t-критерий Уэлча. Этот критерий применяется для сравнения средних значений двух выборок, когда дисперсии неизвестны и могут отличаться. В контексте анализа причинно-следственных связей, t-критерий Уэлча позволяет определить, существует ли статистически значимая разница между эффектами интервенции на две переменные, что является ключевым шагом в процессе группировки переменных и упрощения модели без потери важной информации.
Процесс определения оптимального уровня обобщения (coarsening) достигается путем систематического применения статистических тестов и итеративной корректировки разбиения переменных. Алгоритм последовательно оценивает статистическую схожесть эффектов вмешательств на различные переменные, объединяя те, которые не демонстрируют значимых различий, и разделяя те, для которых различия статистически значимы. Это позволяет найти баланс между упрощением модели — уменьшением количества переменных — и сохранением информации о причинно-следственных связях, что критически важно для корректного вывода причинных эффектов при анализе данных о вмешательствах.
Алгоритм демонстрирует гарантируемую идентифицируемость и масштабируемость. Его вычислительная сложность составляет O(edn + d²e + k²(p²n + p³)), где e — количество ребер в графе вмешательств, d — максимальная степень вершины, k — количество итераций уточнения разбиения, p — количество переменных, а n — размер выборки.
Оценка качества абстракции: Вероятность и причинный poset
Оценка качества абстрактной модели осуществляется посредством эвристики правдоподобия — метода, который ранжирует различные уровни упрощения на основе их способности объяснять наблюдаемые данные. Данная эвристика использует вероятностные модели, такие как Gaussian Chain Graphs, для оценки вероятности абстрактной системы при заданном наборе данных. Более высокие значения правдоподобия указывают на то, что упрощенная модель лучше соответствует наблюдаемой реальности, что позволяет выбирать оптимальный уровень абстракции для конкретной задачи. Эффективно, данная методика позволяет количественно оценить, насколько хорошо упрощенная модель сохраняет важную информацию из исходной системы, предоставляя инструмент для сравнения различных стратегий абстракции и выбора наиболее подходящей для анализа или прогнозирования.
Для оценки качества абстракции используется эвристика правдоподобия, применяющая вероятностные модели, такие как Gaussian Chain Graphs. Эти графы позволяют оценить вероятность наблюдаемой системы после проведения абстракции, то есть насколько хорошо упрощенная модель объясняет исходные данные. Используя Gaussian Chain Graphs, можно численно определить, насколько правдоподобна абстракция, учитывая статистические зависимости между переменными в исходной системе. Более высокая вероятность указывает на то, что абстракция сохраняет важную информацию из исходной системы, обеспечивая надежное представление о ее поведении, даже после упрощения.
Пространство всех возможных абстракций формирует так называемый каузальный poset абстракций — частично упорядоченное множество, в котором каждый уровень представляет различную степень упрощения исходной системы. Представьте себе лестницу, где каждая ступень — это новый уровень абстракции, от более детального представления к все более обобщенному. Порядок в этом множестве определяется тем, что одна абстракция является «грубее» другой, если она объединяет больше состояний или переменных. Такая структура позволяет систематически исследовать различные уровни абстракции и выбирать наиболее подходящий для конкретной задачи, учитывая компромисс между точностью и упрощением модели. Изучение этого poset позволяет не просто создавать абстракции, но и понимать их взаимосвязь и иерархию, что открывает новые возможности для анализа и прогнозирования сложных систем.
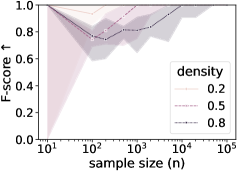
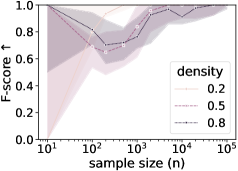
Исследования, проведенные на искусственно сгенерированных данных, демонстрируют, что показатель Adjusted Rand Index (ARI) стабильно увеличивается с ростом объема выборки, что свидетельствует о точном восстановлении разбиений на кластеры. Этот результат указывает на то, что предложенный метод позволяет эффективно определять оптимальный уровень абстракции при увеличении количества доступных данных. Параллельно с этим, показатель F-score, оценивающий качество восстановления связей между переменными, также демонстрирует улучшение с увеличением размера выборки. Данные тенденции подтверждают надежность и эффективность предложенного подхода к оценке качества абстракций, позволяя получать более точные и информативные модели даже при ограниченном объеме исходных данных.
Исследование демонстрирует неизбежную тенденцию к упрощению сложных систем. Авторы формализуют процесс «огрубления» причинно-следственных DAG-моделей, что напоминает о том, как практика всегда находит способ обойти теоретическую сложность. Стремление к идентифицируемости в условиях интервенционных данных — это попытка обуздать хаос, который, как показывает опыт, всегда ускользает. Нильс Бор говорил: «Противоположности не только могут сосуществовать, но и необходимы друг другу». В контексте данной работы это означает, что упрощение модели, неизбежно ведущее к потере детализации, является необходимой платой за возможность практического применения и извлечения полезной информации из данных. Попытки сохранить всю сложность системы обречены на провал, а «огрубление» — это прагматичный компромисс.
Куда это всё ведёт?
Представленный формальный аппарат для упрощения причинно-следственных графов, безусловно, элегантен. Однако, история учит, что любая «гарантия идентифицируемости» неизбежно сталкивается с жестокой реальностью данных. Упрощение ради упрощения — занятие полезное, пока не возникает необходимость в детализации. Неизбежно возникнет потребность в алгоритмах, способных не только грубо объединять переменные, но и гранулярно восстанавливать утерянную информацию, когда это потребуется. И, разумеется, всё это снова потребует ресурсов.
Текущая работа фокусируется на интервенционных данных, что, конечно, хорошо. Но жизнь, как известно, редко предоставляет чистые эксперименты. В реальном мире данные будут смешанными — наблюдательными и интервенционными, шумными и неполными. Следующим шагом, вероятно, станет разработка методов, устойчивых к этим несовершенствам, и способов оценки степени искажения, вносимого каждым источником данных. Иначе, все красивые диаграммы окажутся просто оптимистичным представлением о том, что могло бы быть.
В конечном счёте, данная работа — ещё один шаг на пути к автоматическому открытию причинно-следственных связей. Но не стоит забывать, что в 2012-м году тоже обещали «бесконечную масштабируемость» и «самообучающиеся системы». Пока тесты зелёные, можно считать, что всё в порядке. Пока.
Оригинал статьи: https://arxiv.org/pdf/2601.10531.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Безопасность генерации изображений: новый вектор управления
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Самостоятельные агенты: Баланс безопасности и автономии
- Квантовое «восстановление» информации: обращение вспять шума
- Редактирование изображений по запросу: новый уровень точности
- Искусственный интеллект: между мифом и реальностью
- Квантовые Кластеры: Где Рождается Будущее?
- 3D-моделирование: оживляем объекты без оптимизации
- Квантовый импульс для несбалансированных данных
- Разрушая иллюзию квантового превосходства: новый взгляд на Гауссовскую выборку бозонов
2026-01-17 19:50