Автор: Денис Аветисян
Новая серия открытых моделей HeartMuLa позволяет генерировать длинные музыкальные произведения, используя инновационный подход к токенизации и языковому моделированию аудио.
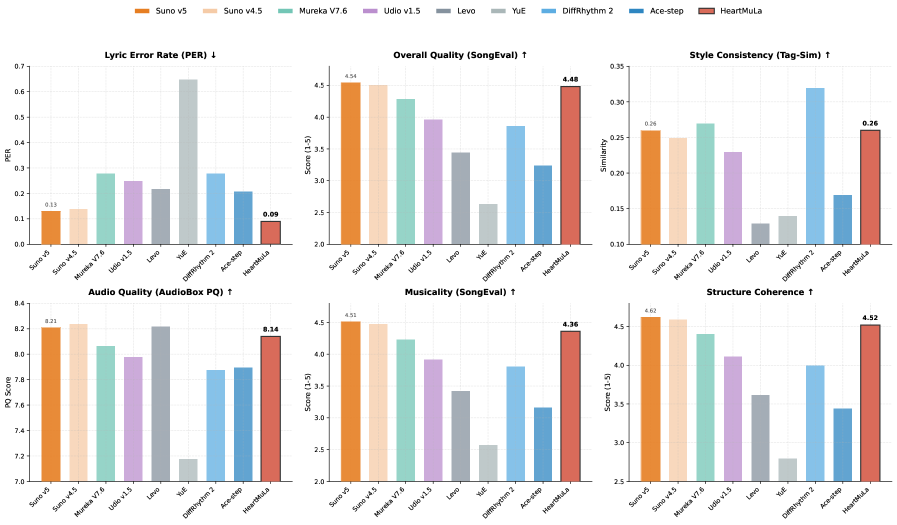
Представлена семейство моделей HeartMuLa, использующих иерархическую структуру и сверхнизкочастотные музыкальные токены для эффективной и контролируемой генерации музыки.
Несмотря на значительный прогресс в области генерации музыки, создание открытых, масштабируемых моделей, способных к детальному и контролируемому синтезу, остается сложной задачей. В данной работе представлена семейство моделей HeartMuLa: A Family of Open Sourced Music Foundation Models, основанное на иерархическом подходе к языковому моделированию аудио, использующем ультра-низкочастотные музыкальные токены. Это позволяет эффективно генерировать длинные музыкальные композиции с возможностью точной настройки стиля и содержания. Смогут ли эти модели стать основой для новых мультимодальных инструментов создания контента и дальнейших исследований в области искусственного интеллекта и музыки?
Разгадывая Семантический Голос Музыки
Традиционные методы извлечения информации из музыки зачастую сталкиваются с трудностями в понимании нюансов семантики, рассматривая аудиосигнал исключительно как необработанную волну. Такой подход, фокусирующийся на физических характеристиках звука, упускает из виду субъективные аспекты восприятия, такие как эмоциональная окраска, настроение или жанровые особенности. В результате, системы анализа музыки, основанные на обработке сырых волновых форм, испытывают сложности в распознавании и интерпретации более сложных музыкальных концепций, что ограничивает их возможности в задачах, требующих глубокого понимания музыкального содержания. Данный подход препятствует созданию интеллектуальных систем, способных не просто идентифицировать звуки, но и понимать смысл, который в них заложен, и устанавливать связи между музыкой и человеческим опытом.
Эффективное сопоставление музыки и текста имеет решающее значение для таких задач, как генерация музыки и поиск по текстам песен, однако представляет собой значительную проблему. Существующие методы часто сталкиваются с трудностями при установлении точной связи между музыкальными характеристиками — темпом, тональностью, инструментами — и лингвистическими особенностями текстового описания. Успешное выравнивание требует не просто идентификации соответствий между отдельными звуками и словами, но и понимания более широкого контекста — эмоционального окраса, повествования, культурных ассоциаций. Разработка алгоритмов, способных улавливать эти сложные взаимосвязи, является ключевым шагом к созданию интеллектуальных систем, которые могут не только воспроизводить музыку, но и понимать её смысл, а также генерировать новые композиции на основе текстовых запросов.
Современные методы анализа музыкального контента зачастую оказываются неспособными уловить сложные взаимосвязи между звуковыми характеристиками и текстовыми описаниями. Это связано с тем, что большинство алгоритмов фокусируются на низкоуровневых признаках, таких как частота и амплитуда, упуская из виду более абстрактные понятия, выраженные в языке — эмоции, настроение, сюжет или жанр. В результате, системы испытывают трудности при интерпретации музыкальных произведений в контексте человеческого восприятия, что ограничивает их возможности в задачах, требующих глубокого семантического понимания, например, при поиске музыки по эмоциональному окрасу или генерации композиций на основе текстовых запросов. Неспособность установить четкую связь между музыкой и текстом снижает эффективность систем автоматического анализа и обработки музыкальной информации.
HeartMuLa: Фундамент Объединенного Музыкального ИИ
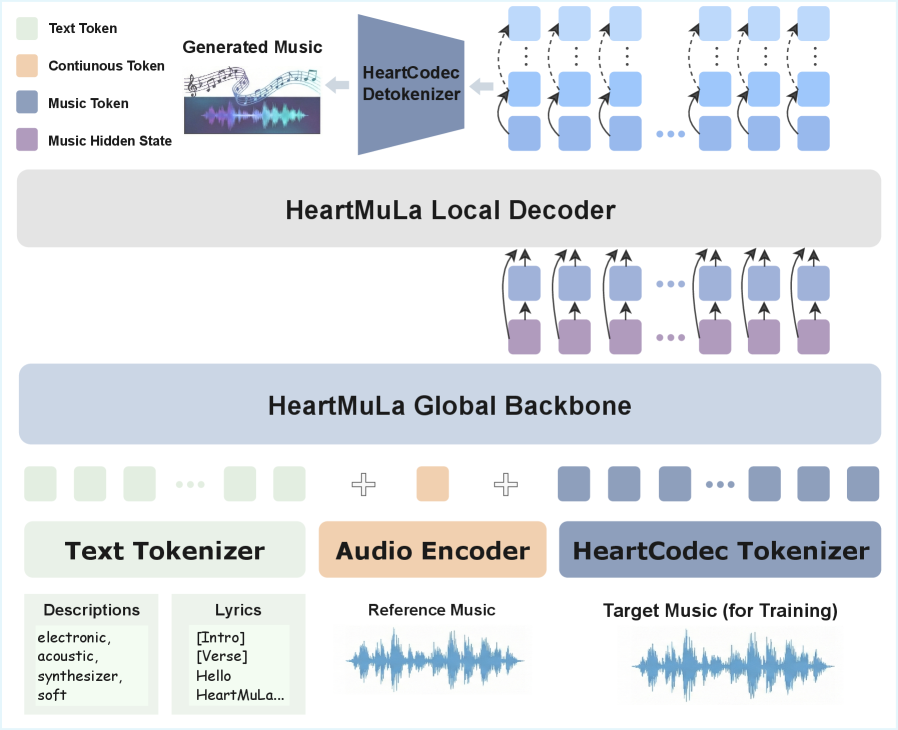
HeartMuLa представляет собой унифицированную структуру, использующую дискретное представление аудио для эффективного моделирования музыкального контента. Вместо работы с непрерывными аудиосигналами, HeartMuLa кодирует аудио в последовательность дискретных токенов, что позволяет применять методы, разработанные для обработки естественного языка, к музыкальным данным. Этот подход значительно снижает вычислительную сложность и требования к памяти по сравнению с традиционными методами, основанными на анализе волновых форм или спектрограмм. Дискретное представление также облегчает обучение моделей генерации музыки и позволяет более эффективно захватывать долгосрочные зависимости в музыкальной структуре.
Архитектура HeartMuLa включает в себя несколько ключевых компонентов, обеспечивающих комплексную обработку музыкального контента. HeartTranscriptor выполняет надежное распознавание текста песен, преобразуя аудиосигнал в последовательность текстовых токенов. В свою очередь, HeartCLAP отвечает за семантическое выравнивание между музыкальным аудио и текстом песен, что позволяет системе понимать взаимосвязь между музыкальным содержанием и лирическим смыслом. Это выравнивание критически важно для задач, требующих понимания контекста, таких как генерация музыки по тексту или автоматическое создание субтитров для песен.
Представление аудио в виде дискретных токенов является ключевым аспектом архитектуры HeartMuLa, позволяющим значительно повысить эффективность обучения и генерации музыкального контента. В отличие от традиционных методов, оперирующих с непрерывными сигналами, дискретизация аудио упрощает процесс моделирования, снижает вычислительные затраты и позволяет использовать алгоритмы, разработанные для обработки последовательностей, такие как трансформеры. Такой подход позволяет HeartMuLa более эффективно захватывать сложные музыкальные структуры, облегчает манипулирование музыкальными элементами и открывает возможности для создания новых музыкальных произведений с повышенной степенью контроля и креативности.
Эффективное Аудиопредставление с Дискретными Токенами
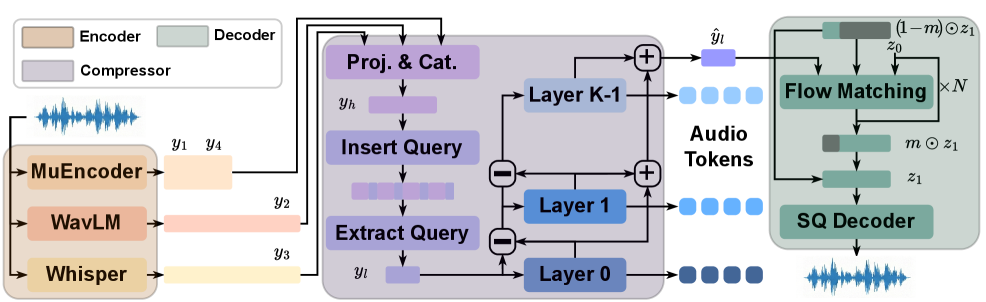
HeartMuLa использует остаточную векторизацию (RVQ) и модели, такие как MuCodec, для создания компактного и семантически значимого дискретного представления аудио. RVQ позволяет сжимать аудиосигнал, представляя его в виде последовательности дискретных токенов, каждый из которых соответствует вектору из кодового словаря. Модель MuCodec, в частности, обучена создавать и декодировать такие дискретные представления, эффективно кодируя аудиоинформацию в сжатом виде. Использование дискретных токенов упрощает моделирование и манипулирование музыкальным контентом, позволяя снизить вычислительные затраты по сравнению с обработкой непрерывных аудиосигналов. Кодовый словарь, созданный в процессе обучения RVQ, содержит векторы, представляющие наиболее часто встречающиеся паттерны в аудиоданных, обеспечивая тем самым эффективное и информативное сжатие.
Использование дискретного представления аудио, основанного на методах Residual Vector Quantization (RVQ) и моделях, таких как MuCodec, позволяет существенно снизить вычислительные затраты при моделировании и обработке музыкального контента. Переход от непрерывных аудиосигналов к конечному набору дискретных токенов уменьшает объем данных, необходимых для хранения и обработки, что приводит к снижению требований к памяти и вычислительной мощности. Такой подход особенно важен для задач, требующих обработки больших объемов музыкальных данных или работы на устройствах с ограниченными ресурсами, например, при создании музыкальных приложений для мобильных устройств или при потоковой передаче музыки.
Для повышения точности и качества реконструированного звука в HeartMuLa применяются методы Flow Matching и автокодировщики. Flow Matching позволяет построить непрерывное отображение между дискретными представлениями аудио и исходным сигналом, что способствует снижению потерь информации при кодировании и декодировании. Автокодировщики, в свою очередь, обучаются сжимать аудиоданные в компактное представление, а затем восстанавливать их, минимизируя ошибку реконструкции. Комбинация этих методов позволяет достичь высокой степени fidelity, сохраняя ключевые характеристики звука и минимизируя артефакты при восстановлении.
Раскрывая Семантическое Понимание через Самообучение
Самообучающееся обучение, использующее модели вроде WavLM и HuBERT, играет ключевую роль в извлечении семантических представлений из неразмеченных аудиоданных. Эти модели обучаются, предсказывая скрытые части аудиосигнала, такие как пропущенные фреймы или порядок фрагментов, что позволяет им формировать внутреннее представление о структуре и содержании звука без необходимости в ручной аннотации. WavLM и HuBERT используют различные методы маскирования и предсказания, например, предсказание дискретных единиц спектрального анализа или квантованных представлений аудиосигнала, что позволяет им улавливать сложные зависимости в данных и формировать надежные семантические векторы.
Модели, такие как WavLM и HuBERT, способны формировать устойчивое понимание музыкального контента, анализируя внутреннюю структуру аудиозаписей без необходимости в явных аннотациях. Они извлекают закономерности из временных последовательностей звуковых событий, выявляя корреляции между различными фрагментами музыки и их контекстом. Этот процесс позволяет моделям изучать представления о музыкальной форме, гармонии и ритме, не требуя предварительной разметки данных экспертами. В результате, модели самостоятельно формируют семантические представления, отражающие музыкальное содержание.
Предварительное обучение с самоконтролем значительно повышает эффективность выполнения последующих задач, таких как выравнивание музыки и текста, а также генерация музыкального контента. Модели, предварительно обученные на больших объемах неразмеченных аудиоданных, демонстрируют улучшенные показатели в задачах, требующих понимания семантической структуры музыки. Это связано с тем, что самоконтроль позволяет моделям изучать полезные представления, которые затем могут быть перенесены на различные целевые задачи, снижая потребность в больших объемах размеченных данных и повышая обобщающую способность системы. В частности, в задачах выравнивания музыки и текста, предварительное обучение способствует более точному сопоставлению музыкальных фрагментов с соответствующими текстовыми описаниями, а в задачах генерации — позволяет создавать более когерентные и осмысленные музыкальные произведения.
К Контролируемому и Длинному Музыкальному Творению
В основе системы HeartMuLa лежит инновационный подход к согласованию музыки и текста, достигаемый благодаря применению методов контрастного обучения, реализованных в HeartCLAP. Данный механизм позволяет модели устанавливать четкую связь между текстовым описанием и соответствующими музыкальными характеристиками. В отличие от предыдущих методов, HeartCLAP не просто сопоставляет музыку и текст, но и активно обучается различать релевантные и нерелевантные соответствия, что значительно повышает точность и детализацию генерируемой музыки. Это позволяет пользователям эффективно управлять процессом создания музыки, задавая желаемые параметры и характеристики через естественный язык, и получать результат, максимально соответствующий их ожиданиям. По сути, HeartMuLa обеспечивает беспрецедентный уровень контроля над музыкальным контентом, открывая новые возможности для креативных экспериментов и автоматизированного музыкального производства.
Благодаря достигнутой взаимосвязи между музыкой и текстом, система позволяет пользователям осуществлять детальное управление процессом генерации музыкальных композиций посредством простых текстовых запросов. Это означает, что желаемые характеристики музыки — от жанра и настроения до конкретных инструментов и темпа — могут быть заданы в виде естественного языка. По сути, текстовое описание становится своего рода «дирижерской палочкой», направляющей процесс создания музыки и позволяющей получать композиции, точно соответствующие задуманному. Такой подход открывает новые возможности для музыкантов, композиторов и всех, кто хочет создавать музыку без необходимости владения сложными музыкальными инструментами или навыками нотной грамоты.
Разработанная модель демонстрирует передовые результаты в области генерации музыки, превосходя существующие аналоги, такие как Laion-CLAP и MuQ-MuLan, по ключевым показателям — Recall@K (R@K) и Mean Average Precision@10 (mAP@10). Данное превосходство свидетельствует о значительно улучшенной способности модели точно сопоставлять музыкальный контент с текстовыми описаниями и генерировать музыку, соответствующую заданным параметрам. Более того, достигнуто пятикратное ускорение процесса генерации 5.4x, что открывает возможности для интерактивного и оперативного создания музыкальных композиций и делает систему особенно привлекательной для приложений, требующих высокой производительности и быстрого отклика.
Исследование семейства моделей HeartMuLa демонстрирует стремление к созданию гибких и контролируемых систем генерации музыки. Авторы предлагают иерархический подход к аудио языковому моделированию, что позволяет эффективно работать с длинными музыкальными последовательностями. Как однажды заметила Барбара Лисков: «Программы должны быть спроектированы так, чтобы изменения в одной части не приводили к неожиданным последствиям в других». Этот принцип находит отражение в архитектуре HeartMuLa, где модульность и иерархичность обеспечивают предсказуемость и управляемость процесса генерации, позволяя тонко настраивать параметры и контролировать результат, избегая нежелательных артефактов. Особенный акцент на низкочастотных музыкальных токенах указывает на стремление к оптимизации и повышению эффективности модели, что согласуется с идеей создания надежных и масштабируемых систем.
Что дальше?
Представленная работа, демонстрируя возможности иерархического моделирования музыкального языка с использованием сверхнизкочастотных токенов, лишь аккуратно приподнимает край завесы над потенциалом действительно контролируемого и долгосрочного музыкального синтеза. Однако, стоит признать, что сама необходимость кодирования звука в дискретные токены — это компромисс, своего рода патч на несовершенство нашей способности непосредственно оперировать непрерывными сигналами. Улучшение алгоритмов токенизации, возможно, в сторону адаптивных или гибридных подходов, представляется ключевой задачей.
Более того, текущая архитектура, как и большинство современных генеративных моделей, остаётся зависимой от объёма обучающих данных. Следующим шагом видится разработка методов, позволяющих модели не просто воспроизводить стили, но и экстраполировать, комбинировать, и даже критиковать существующие музыкальные каноны — создавать нечто принципиально новое, а не просто вариации на тему. И, конечно, неизбежен вопрос о субъективности оценки: что есть «хорошая» музыка для алгоритма, лишённого эмоционального контекста?
В конечном счёте, лучший «хак» — это осознание того, как всё работает. Каждый патч — это философское признание несовершенства. И в этой гонке за идеальным музыкальным алгоритмом, возможно, самое интересное — это не конечный продукт, а сам процесс реверс-инжиниринга креативности.
Оригинал статьи: https://arxiv.org/pdf/2601.10547.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эволюция под контролем: эксперименты с обучением с подкреплением в генетическом программировании
- Безопасность генерации изображений: новый вектор управления
- Самостоятельные агенты: Баланс безопасности и автономии
- Квантовое «восстановление» информации: обращение вспять шума
- Редактирование изображений по запросу: новый уровень точности
- Искусственный интеллект: между мифом и реальностью
- Квантовые Кластеры: Где Рождается Будущее?
- 3D-моделирование: оживляем объекты без оптимизации
- Разрушая иллюзию квантового превосходства: новый взгляд на Гауссовскую выборку бозонов
- Квантовый импульс для несбалансированных данных
2026-01-17 21:29