Автор: Денис Аветисян
Исследователи разработали систему, способную находить ответы на сложные вопросы в области геномики, используя возможности нескольких искусственных интеллектов, работающих сообща.
Многоагентный фреймворк GenomAgent превосходит существующие решения, такие как GeneGPT, на 12% по производительности и на 79% снижает вычислительные затраты.
Извлечение знаний из геномных данных, критически важных для биомедицинских исследований, осложняется сложностью и распределённостью соответствующих баз данных. В работе ‘From Single to Multi-Agent Reasoning: Advancing GeneGPT for Genomics QA’ представлена система GeneGPT, использующая API-вызовы для работы с геномной информацией, однако она ограничена жёсткой зависимостью от этих API. Мы разработали GenomAgent — многоагентный фреймворк, превосходящий GeneGPT на 12% в задачах геномного вопросно-ответного поиска и снижающий вычислительные затраты на 79%. Открывает ли предложенный подход новые возможности для извлечения экспертных знаний в других областях науки, требующих анализа больших объёмов специализированных данных?
Вызов геномной аналитики: Сложность и неоднородность данных
Ответы на сложные вопросы в геномике требуют объединения данных из разнообразных и разнородных источников, что представляет собой серьезную проблему для традиционных методов обработки естественного языка. Геномные данные, поступающие из различных баз данных, научных статей и экспериментальных исследований, часто имеют разные форматы, терминологию и уровни детализации. Традиционные алгоритмы, разработанные для работы с однородными текстовыми данными, испытывают трудности при интеграции и интерпретации этой сложной гетерогенной информации. Например, информация о гене может быть представлена в виде последовательности нуклеотидов, аннотаций функций гена, результатов экспериментов по экспрессии генов и данных о взаимодействии белков, каждое из которых требует особого подхода к анализу и интеграции. Преодоление этих трудностей является ключевым шагом к созданию интеллектуальных систем, способных эффективно извлекать знания из огромного объема геномных данных и поддерживать передовые биологические исследования.
Существующие системы, предназначенные для поиска ответов на вопросы в геномике, часто сталкиваются с трудностями при анализе разнородных баз данных и извлечении точной информации. Проблема заключается не только в объеме данных, но и в их структуре — различные базы используют разные форматы, терминологию и уровни детализации. Это приводит к тому, что даже при наличии необходимой информации, системам сложно установить логические связи между различными источниками и сформулировать корректный ответ. В результате, исследователи вынуждены тратить значительное время на ручную проверку результатов, что существенно замедляет процесс биологических открытий и ограничивает практическую ценность автоматизированных систем поиска.
Потребность в надежных и масштабируемых решениях для обработки геномных данных послужила стимулом для разработки как GeneGPT, так и, впоследствии, GenomAgent. Существующие методы анализа генома часто сталкиваются с трудностями при интеграции разрозненных источников информации и предоставлении точных ответов на сложные вопросы, что ограничивает их применимость в биологических исследованиях. Разработка GeneGPT и GenomAgent направлена на преодоление этих ограничений, предлагая системы, способные эффективно обрабатывать большие объемы геномных данных и предоставлять исследователям актуальную информацию для принятия обоснованных решений. Эти инструменты представляют собой важный шаг к автоматизации и ускорению геномных исследований, открывая новые возможности для понимания биологических процессов и разработки инновационных методов лечения.
GeneGPT: Первый шаг к интеллектуальному геномному поиску
GeneGPT использует подход обучения с подкреплением на основе контекста (in-context learning) и интеграцию с API для непосредственного ответа на геномные запросы, используя единственную большую языковую модель. Это позволяет системе извлекать и обрабатывать информацию из различных геномных баз данных и инструментов без необходимости предварительной тонкой настройки модели для каждой конкретной задачи. В процессе обработки запроса, GeneGPT формирует ответы, комбинируя знания, заложенные в предварительно обученной языковой модели, с результатами, полученными через вызовы внешних API, что обеспечивает доступ к актуальным геномным данным и специализированным аналитическим функциям.
GeneGPT использует фреймворк ReAct (Reason + Act) для улучшения процесса рассуждений и выбора действий при обработке геномных запросов. ReAct позволяет модели генерировать как рассуждения (мыслительный процесс), так и действия, такие как вызовы API для получения данных, в чередующейся последовательности. Это итеративное взаимодействие позволяет GeneGPT динамически корректировать стратегию поиска и анализа, улучшая точность и релевантность ответов. В процессе работы модель формулирует промежуточные мысли, определяющие следующие действия, и использует результаты этих действий для уточнения рассуждений, что позволяет эффективно решать сложные запросы, требующие многошагового анализа.
Монолитная архитектура GeneGPT, несмотря на свою функциональность, создавала трудности с масштабированием и адаптацией к новым источникам данных и сложным запросам. Ограниченная модульность затрудняла внесение изменений и добавление новых функций без влияния на всю систему. В частности, увеличение объема геномных данных и разнообразие типов запросов требовали более гибкой структуры, способной к параллельной обработке и независимой модификации отдельных компонентов. Необходимость в расширяемости и отказоустойчивости привела к переходу к более модульному и распределенному дизайну, позволяющему эффективно решать задачи, выходящие за рамки возможностей исходной архитектуры.
В архитектуре GeneGPT использование “Стоп-токена” является критически важным для корректной обработки вызовов API. Этот токен служит сигналом для завершения генерации текста моделью после выполнения необходимой операции с API. Без стоп-токена, модель могла бы продолжать генерировать текст, потенциально формируя неверные или избыточные запросы к API, что привело бы к ошибкам или снижению производительности. Стоп-токен позволяет точно контролировать взаимодействие с внешними ресурсами, обеспечивая надежную и предсказуемую работу системы, особенно при выполнении сложных запросов, требующих нескольких последовательных вызовов API.
GenomAgent: Многоагентный фреймворк для надежного геномного поиска
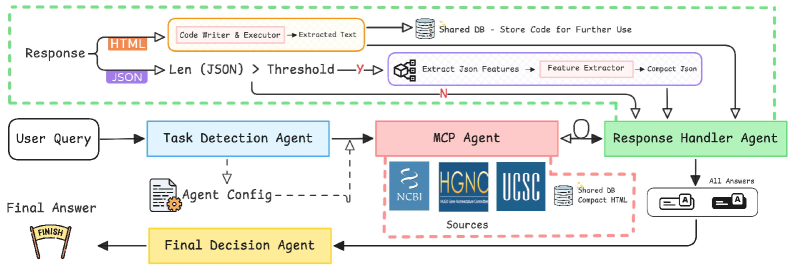
Архитектура GenomAgent основана на принципе многоагентности, где процесс ответа на вопросы разделяется на отдельные, специализированные агенты. Каждый агент отвечает за конкретную подзадачу, например, определение типа запроса, написание кода для доступа к данным, извлечение признаков или форматирование ответа. Такой подход позволяет декомпозировать сложный процесс поиска информации и повысить эффективность обработки запросов, поскольку каждый агент оптимизирован для выполнения своей узкой функции. Взаимодействие между агентами осуществляется посредством протоколов координации, обеспечивающих последовательное и согласованное выполнение задачи.
Архитектура GenomAgent предполагает совместную работу агентов, таких как ‘Task Detection Agent’ (агент определения задачи) и ‘Code Writer Agent’ (агент генерации кода), для доступа и обработки данных из различных баз данных, включая NCBI, HGNC и UCSC. Взаимодействие этих агентов координируется посредством протокола ‘Multi-source Coordination Protocol’, который обеспечивает последовательное выполнение задач по извлечению, трансформации и загрузке данных (ETL) из гетерогенных источников. Агент определения задачи анализирует запрос пользователя и определяет необходимые шаги для его выполнения, в то время как агент генерации кода создает SQL-запросы или другие необходимые скрипты для взаимодействия с базами данных. Протокол координации гарантирует, что данные из разных источников будут объединены и обработаны корректно, что необходимо для получения точного и полного ответа на запрос.
Агент извлечения признаков (Feature Extractor Agent) и агент обработки ответов (Response Handler Agent) совместно обеспечивают контроль качества и единообразие формата данных, поступающих из различных источников. Агент извлечения признаков выполняет предварительную обработку и валидацию данных, отфильтровывая нерелевантную или некорректную информацию. Агент обработки ответов стандартизирует формат данных, приводя его к единому виду, необходимому для дальнейшей обработки. Итоговый агент принятия решений (Final Decision Agent) синтезирует обработанные и стандартизированные данные, полученные от других агентов, формируя итоговый связный и логичный ответ на исходный запрос.
Архитектура GenomAgent построена на базе Google Agent Development Kit, что обеспечивает высокую модульность системы. Эта модульность позволяет легко расширять функциональность фреймворка путем добавления новых агентов или модификации существующих без изменения основной структуры. Адаптация к новым источникам данных, таким как базы данных геномики или протеомики, осуществляется путем интеграции соответствующих API и настройки агентов для взаимодействия с ними. Аналогично, поддержка новых типов запросов реализуется путем создания или адаптации агентов, отвечающих за обработку специфических параметров и логики запроса. Такая гибкость позволяет GenomAgent оперативно реагировать на изменяющиеся требования и расширять область применения.
Подтверждение производительности и обеспечение воспроизводимости результатов
Бенчмарк GeneTuring представляет собой стандартизированную платформу для оценки производительности моделей GeneGPT и GenomAgent. Данный фреймворк обеспечивает объективное сравнение различных архитектур и конфигураций, позволяя исследователям количественно оценивать эффективность систем в задачах, связанных с геномикой. Стандартизация процесса оценки включает в себя чётко определенный набор данных и метрик, что гарантирует воспроизводимость результатов и возможность сопоставления различных подходов. Использование единого бенчмарка способствует ускорению научных открытий за счёт упрощения валидации и сравнения новых моделей и алгоритмов.
Для обеспечения воспроизводимости результатов и оценки влияния архитектурных изменений в ходе исследований использовались модели, такие как GPT-4o-mini, и фреймворки, включая LangGraph. Применение этих инструментов позволило стандартизировать процесс тестирования и валидации, обеспечивая возможность повторного выполнения экспериментов с сохранением исходных условий. Это критически важно для подтверждения достоверности полученных данных и выявления потенциальных улучшений в архитектуре системы, а также для объективного сравнения различных подходов к решению задач в области геномики.
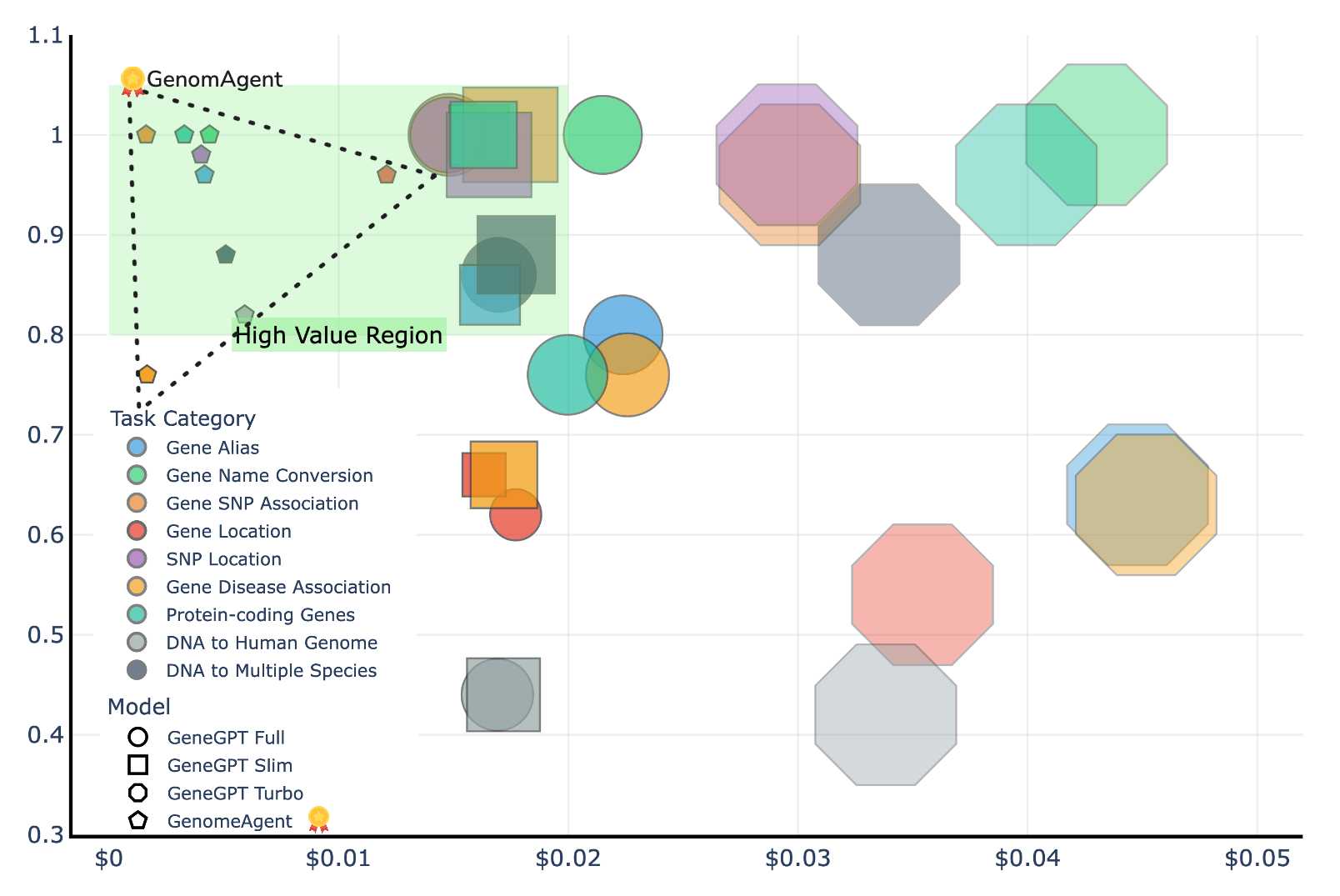
В ходе оценки на бенчмарке GeneTuring, GenomAgent продемонстрировал на 12% более высокую среднюю производительность (0.93) по сравнению с GeneGPT (0.83). При этом, вычислительные затраты на GenomAgent оказались на 79% ниже, составив \$10.06, в то время как для GeneGPT они составили \$48.28. Данные результаты подтверждают эффективность оптимизаций, реализованных в GenomAgent, как с точки зрения качества результатов, так и с точки зрения потребляемых ресурсов.
В ходе тестирования на GeneTuring Benchmark, GenomAgent продемонстрировал улучшение на 28.8% в задачах, связанных с выравниванием (alignment), по сравнению с GeneGPT. Данный показатель отражает повышенную точность и эффективность GenomAgent в определении соответствий и связей между генетическими последовательностями или структурами, что является критически важным для задач, требующих высокой степени соответствия и корректности, таких как анализ мутаций или идентификация функциональных элементов генома.
Систематическая оценка и усовершенствование системы имеют решающее значение для повышения доверия к результатам и ускорения научного прогресса. Непрерывная валидация производительности, как демонстрируется на GeneTuring Benchmark, позволяет количественно оценить улучшения, такие как повышение средней производительности GenomAgent на 12% (до 0.93) по сравнению с GeneGPT (0.83) и снижение вычислительных затрат на 79% (до \$10.06). Подобный подход к оценке, включающий воспроизводимость результатов и анализ влияния архитектурных изменений с использованием моделей вроде GPT-4o-mini и фреймворков LangGraph, обеспечивает надежность и позволяет целенаправленно оптимизировать систему для достижения более высоких показателей, например, улучшения в задачах выравнивания на 28.8%.
Перспективы развития: К интеллектуальному геномному исследованию
Многоагентная архитектура GenomAgent представляет собой гибкую платформу, позволяющую интегрировать разнообразные источники данных, вычислительные модели и возможности логического вывода. В отличие от традиционных подходов, где анализ генома опирается на жестко заданные алгоритмы, GenomAgent позволяет динамически добавлять новые инструменты и базы данных, адаптируясь к постоянно растущему объему геномной информации. Каждый агент в системе специализируется на определенной задаче — от поиска генов до анализа регуляторных элементов — и способен взаимодействовать с другими агентами для решения более сложных вопросов. Эта модульность и расширяемость открывают перспективы для создания самообучающихся систем, способных автоматически адаптироваться к новым данным и находить скрытые закономерности в геномных исследованиях, значительно ускоряя темпы биологических открытий.
Будущие исследования направлены на повышение способности агентов, входящих в состав GenomAgent, к обработке сложных взаимосвязей в геномных данных, а также к работе с неопределенной и динамически изменяющейся информацией. Ученые стремятся усовершенствовать алгоритмы, позволяющие агентам эффективно анализировать данные, содержащие неполные или противоречивые сведения, и адаптироваться к постоянно меняющимся запросам исследователей. Особое внимание уделяется разработке механизмов, способных учитывать контекст и вероятность различных гипотез, что позволит более точно интерпретировать геномные данные и выявлять скрытые закономерности, которые могли бы остаться незамеченными при традиционных подходах к анализу.
Ожидается, что разработанная система позволит исследователям проводить анализ геномных данных с невиданной ранее скоростью и эффективностью. Благодаря оптимизации процессов поиска и сопоставления, а также способности выявлять сложные взаимосвязи, станет возможным обнаружение скрытых закономерностей и новых биологических механизмов. Это, в свою очередь, значительно ускорит темпы научных открытий в области биологии, генетики и медицины, открывая перспективы для разработки новых методов диагностики и лечения заболеваний.
В перспективе, создание интеллектуальной системы исследования генома предполагает принципиально новый подход к анализу биологических данных. Эта система призвана предоставить ученым возможность формулировать и решать задачи, выходящие за рамки возможностей современных инструментов. Предполагается, что она сможет не только обрабатывать огромные массивы геномной информации, но и устанавливать сложные взаимосвязи, учитывать неопределенность данных и адаптироваться к изменяющимся запросам. Такая система позволит исследователям выходить за пределы поиска известных закономерностей и открывать скрытые инсайты, что, в свою очередь, значительно ускорит темпы биологических открытий и позволит глубже понять механизмы жизни.
Представленная работа демонстрирует стремление к математической чистоте в области геномных вычислений. Разработка GenomAgent, как многоагентной системы, направлена на оптимизацию процесса ответа на вопросы, что соответствует принципу достижения максимальной эффективности при минимальных затратах. Как заметила Барбара Лисков: «Хороший дизайн — это когда система достаточно проста, чтобы ее можно было понять, но достаточно мощная, чтобы решать сложные задачи». В данном исследовании эта простота проявляется в снижении вычислительных издержек на 79%, а мощность — в увеличении производительности на 12% по сравнению с GeneGPT. Акцент на масштабируемости и асимптотической устойчивости, как ключевых метриках, подчеркивает стремление к созданию не просто работающего, но и доказуемо корректного решения.
Куда Далее?
Представленная работа, демонстрируя улучшение в 12% и снижение вычислительных затрат на 79% по сравнению с GeneGPT, не является, однако, окончательным ответом. Напротив, она обнажает новые грани проблемы. Успех GenomAgent, основанный на декомпозиции задачи и взаимодействии агентов, поднимает вопрос о природе самой «понимаемости» в контексте геномики. Достаточно ли простого увеличения точности? Или необходимо разработать критерии, позволяющие оценивать качество рассуждений, а не только их результат?
Очевидно, что оптимизация без анализа — это самообман и ловушка для неосторожного разработчика. Увеличение контекстного окна и интеграция API, безусловно, полезны, но они не решают фундаментальную проблему ограниченности моделей в экстраполяции знаний за пределы тренировочного набора. Дальнейшие исследования должны быть сосредоточены на разработке методов, позволяющих моделям обучаться принципам геномики, а не просто запоминать корреляции.
Перспективы кажутся связаны с изучением формальных методов верификации рассуждений, возможно, используя инструменты из области автоматического доказательства теорем. Потребуется переосмысление метрик оценки, чтобы отличать истинное понимание от статистической случайности. И, возможно, самое главное, необходимо признать, что геномика — это область, требующая не только вычислительной мощности, но и глубоких биологических знаний, которые пока что не поддаются полной формализации.
Оригинал статьи: https://arxiv.org/pdf/2601.10581.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- LongCat-Video: ещё один «прорыв», который придётся поддерживать.
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Растительность под прицетом ИИ: Оценка биофизических параметров по снимкам Sentinel-2
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Надежность ускорителей: от замысла до реализации
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
2026-01-17 21:31