Автор: Денис Аветисян
Представлен масштабный набор данных Action100M, призванный значительно улучшить понимание видео и действий в них моделями искусственного интеллекта.

Action100M содержит 147 миллионов размеченных видеосегментов, что позволяет добиться значительных успехов в распознавании действий и построении моделей мира.
Несмотря на значительный прогресс в области машинного зрения, понимание человеческих действий в видео остается сложной задачей, требующей масштабных и разнообразных данных. В данной работе представлена Action100M: A Large-scale Video Action Dataset — новый крупномасштабный набор данных, содержащий около 147 миллионов аннотированных сегментов видео, полученных из обучающих интернет-видеороликов. Инновационный конвейер обработки данных обеспечивает детальную сегментацию, многоуровневые подписи и структурированные аннотации, что позволяет добиться существенного улучшения результатов в задачах распознавания действий и понимания видео с использованием vision-language моделей. Открывает ли Action100M новые перспективы для создания более совершенных систем, способных к полноценному моделированию окружающего мира и взаимодействию с ним?
Сквозь Хаос Данных: Вызов Масштаба в Распознавании Действий
Традиционные системы распознавания действий базируются на тщательно подобранных, но ограниченных наборах данных, что существенно снижает их способность к обобщению и адаптации к реальным условиям. Эти наборы, как правило, содержат лишь небольшое количество наиболее распространенных действий, игнорируя широкий спектр человеческой деятельности и, следовательно, ограничивая возможности систем в сложных, непредсказуемых ситуациях. В результате, модели, обученные на таких данных, часто демонстрируют низкую производительность при анализе видео, содержащих редкие или необычные действия, что препятствует созданию действительно универсальных и надежных систем распознавания действий.
Для достижения существенного прогресса в понимании человеческих действий необходимы наборы данных беспрецедентных масштабов. Ограниченность существующих ресурсов, как правило, препятствует обучению моделей, способных обобщать знания и эффективно распознавать широкий спектр действий в реальных условиях. В ответ на эту проблему представлен Action100M — набор данных, содержащий 100 миллионов экземпляров действий. Этот масштабный ресурс призван преодолеть узкие места, связанные с ручной разметкой, и обеспечить основу для обучения более надежных и универсальных систем распознавания действий. Создание Action100M знаменует собой важный шаг к разработке искусственного интеллекта, способного понимать и взаимодействовать с миром так же, как и человек.
Недостаточное разнообразие данных существенно ограничивает возможности разработки надежных моделей распознавания действий. Существующие наборы данных часто сосредоточены на небольшом количестве распространенных действий, игнорируя обширный “длинный хвост” менее часто встречающихся, но не менее важных сценариев. Это приводит к тому, что модели показывают высокие результаты на стандартных тестах, но демонстрируют низкую производительность в реальных условиях, где разнообразие действий значительно выше. В результате, системы распознавания действий становятся уязвимыми к неожиданным или редким событиям, что снижает их общую надежность и практическую ценность. Для создания действительно универсальных систем необходимо обеспечить широкий охват различных действий, включая те, которые встречаются относительно редко, что требует принципиально новых подходов к сбору и аннотации данных.
Для достижения всестороннего понимания человеческих действий требуется кардинальный пересмотр подхода к созданию обучающих наборов данных. Традиционные методы, основанные на ручной разметке ограниченного количества видео, больше не соответствуют масштабу задачи и разнообразию возможных действий. Необходимо отойти от принципа создания «золотых» наборов данных в пользу автоматизированных методов сбора и аннотации, позволяющих охватить значительно большее количество примеров и, что особенно важно, редких и нетипичных действий. Такой переход предполагает разработку новых алгоритмов и инструментов, способных эффективно обрабатывать большие объемы данных и обеспечивать достаточное качество разметки, открывая путь к созданию действительно всеобъемлющих моделей понимания действий.
Action100M: Новый Масштаб в Понимании Видео
Набор данных Action100M состоит из 100 миллионов слабо-контролируемых видео-примеров, что позволяет обучать модели в беспрецедентном масштабе. Общий объем видео-контента составляет 14.6 лет непрерывного воспроизведения. Такой масштаб данных позволяет значительно улучшить обобщающую способность моделей видео-понимания и решить задачи, требующие анализа больших объемов визуальной информации. Слабая контролируемость данных подразумевает использование автоматизированных методов для получения разметок, что снижает затраты на ручную аннотацию и обеспечивает возможность масштабирования.
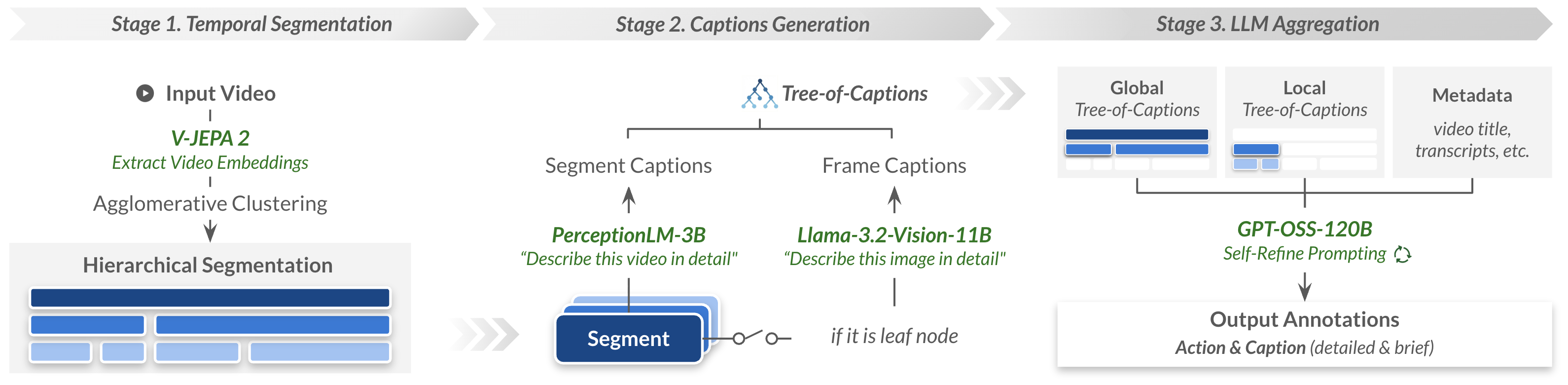
Иерархическая временная сегментация предполагает разбиение видеоматериалов на сегменты различной длительности, что обеспечивает многоуровневое обучение и детализированный анализ содержания. Данный подход позволяет не только идентифицировать отдельные действия в рамках каждого сегмента, но и учитывать временные взаимосвязи между ними, формируя более полное представление о происходящем в видео. Разбиение на сегменты разного уровня гранулярности позволяет модели одновременно обучаться как на крупных временных отрезках, отражающих общие сцены, так и на более коротких, описывающих конкретные действия или события, что способствует повышению точности и детализации анализа видеоконтента.
Для эффективной аннотации датасета Action100M использованы автоматизированные конвейеры, основанные на моделях Llama-3.2-Vision и PerceptionLM. Эти модели генерируют текстовые описания как для отдельных кадров, так и для сегментов видео, что позволило получить в общей сложности 147 миллионов аннотаций на уровне сегментов. Автоматизация процесса позволила существенно сократить временные затраты и повысить масштабируемость датасета, обходя ограничения, связанные с ручной аннотацией. Полученные описания содержат информацию о происходящих действиях и объектах в каждом сегменте, обеспечивая детальную разметку для обучения моделей видеопонимания.
Автоматизированный подход к аннотированию данных в Action100M позволяет существенно снизить зависимость от трудоемкого ручного процесса, являющегося основным ограничением для масштабирования видео-датасетов. Использование моделей, таких как Llama-3.2-Vision и PerceptionLM, для генерации подписей к кадрам и сегментам видео, позволило создать 147 миллионов сегментных аннотаций без необходимости привлечения большого количества специалистов-аннотаторов. Это не только значительно ускорило процесс создания датасета, но и обеспечивает возможность его быстрого расширения и адаптации к новым задачам и требованиям, что критически важно для развития моделей понимания видео.
Уточнение и Балансировка Представления Действий
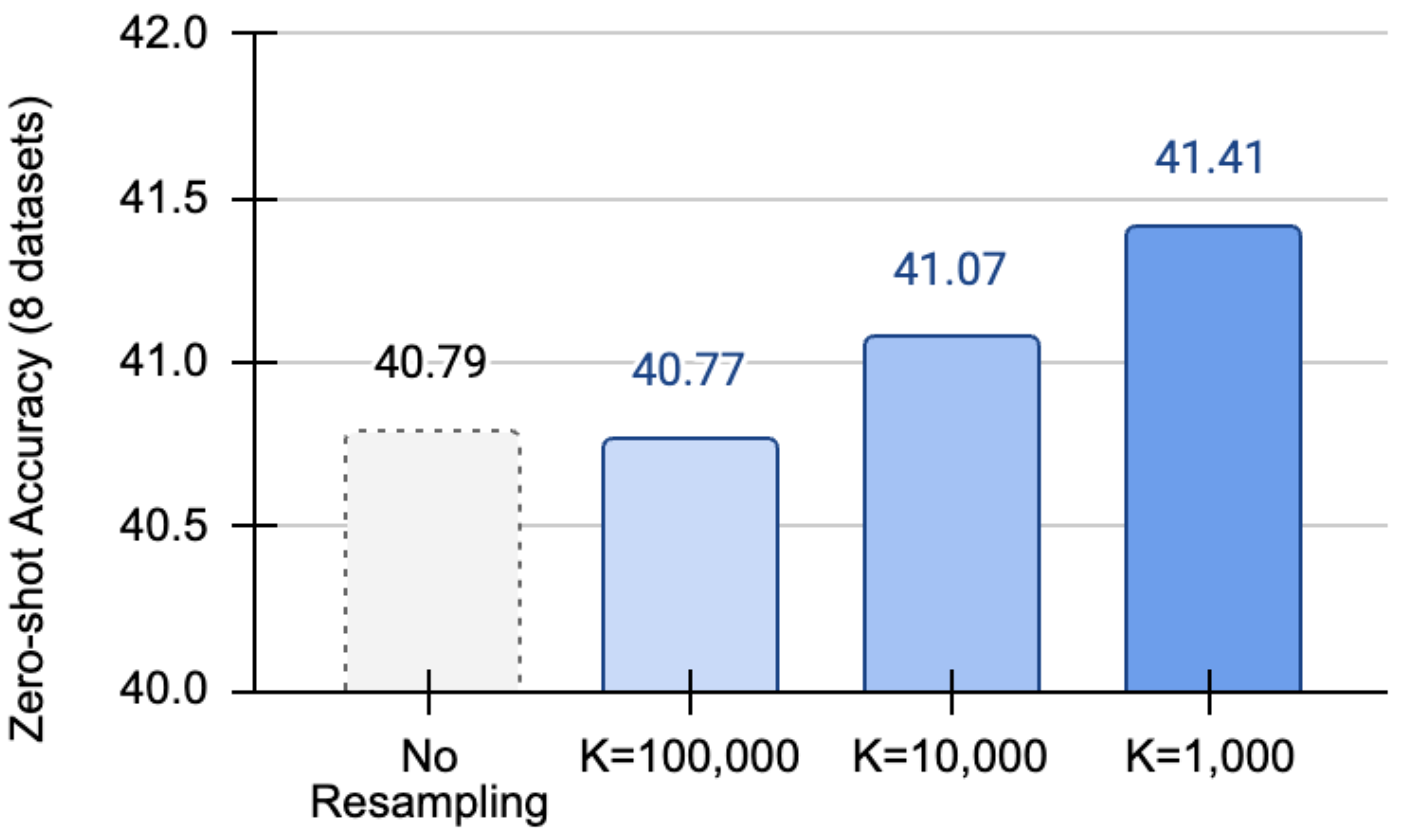
Семантическая передискретизация решает проблему “длинного хвоста” в данных об активностях, возникающую из-за неравномерного распределения частот различных действий. Данный подход направлен на балансировку частот встречаемости действий, гарантируя адекватное представление редких активностей в обучающей выборке. Это достигается за счет увеличения количества примеров редких действий, что позволяет модели более эффективно обучаться и обобщать знания на менее распространенные сценарии, предотвращая смещение в сторону преобладающих действий и улучшая общую производительность системы.
Кластеризация K-Means используется для группировки схожих действий с целью целенаправленной передискретизации данных. Этот подход позволяет повысить производительность модели при работе с менее распространенными активностями, поскольку обеспечивает более равномерное представление различных действий в обучающей выборке. Группировка действий по признакам схожести позволяет выделить редкие, но важные активности и увеличить их представленность в данных, что компенсирует дисбаланс и улучшает обобщающую способность модели. В результате, модель становится более устойчивой к редким событиям и демонстрирует улучшенные результаты в задачах, где эти события играют значимую роль.
Для повышения качества аннотаций используется комбинация GPT-OSS и метода Self-Refine. GPT-OSS генерирует первоначальные описания действий, после чего Self-Refine итеративно уточняет эти описания, выявляя и исправляя неточности. Этот процесс позволяет добиться более высокой согласованности и детализации аннотаций, что положительно сказывается на обучении и производительности модели. Итеративное уточнение позволяет системе самообучаться и улучшать качество генерируемых описаний с течением времени.
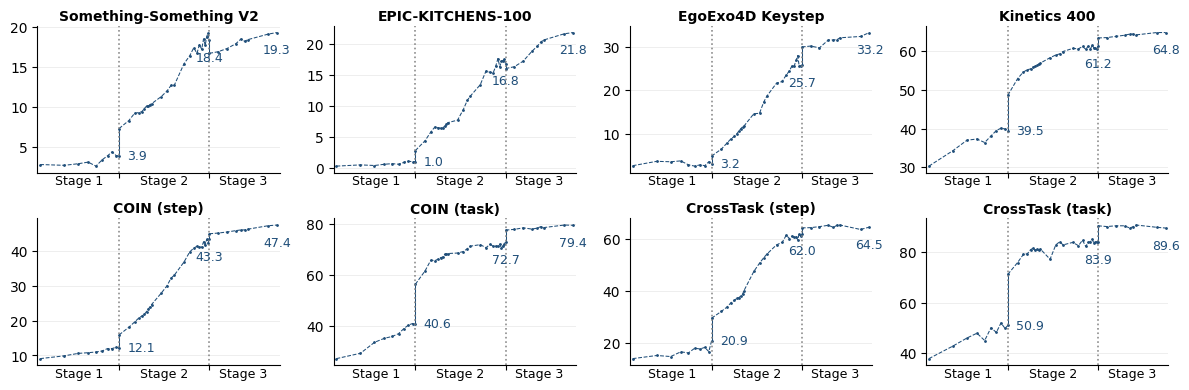
Процесс иерархической временной сегментации использует агломеративную кластеризацию и метод Уорда для обеспечения оптимального разделения данных. В ходе обработки было выявлено 7.58 миллиона групп дубликатов, содержащих в общей сложности 141.8 миллиона повторяющихся экземпляров действий, которые были удалены для повышения качества и эффективности обучающих данных. Использование метода Уорда позволяет минимизировать внутрикластерную дисперсию при объединении кластеров, что способствует более точному определению границ между различными сегментами действий.
VL-JEPA: Единая Модель для Понимания Действий
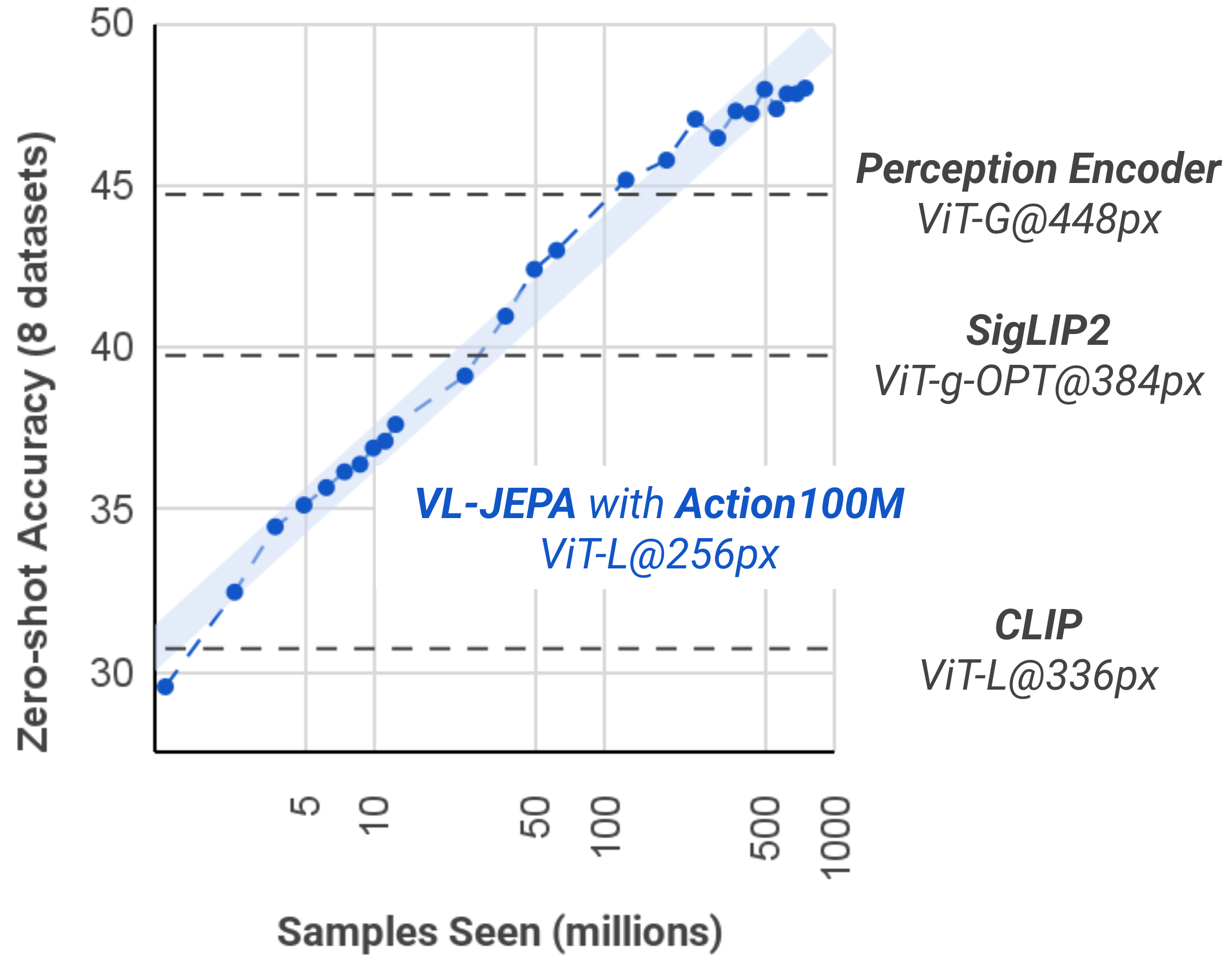
Модель VL-JEPA, обученная на масштабном наборе данных Action100M, демонстрирует выдающиеся результаты в задачах распознавания действий и поиска видео по текстовому запросу. Она эффективно определяет происходящие действия в видеоматериалах и сопоставляет их с соответствующими текстовыми описаниями, превосходя существующие подходы в задачах, требующих понимания визуального контента и его связи с языком. Такая высокая производительность обусловлена способностью модели обобщать знания, полученные в процессе обучения на большом объеме данных, и успешно применять их к новым, ранее не встречавшимся видео и запросам, что делает VL-JEPA мощным инструментом для анализа и поиска в видеоконтенте.
В основе архитектуры VL-JEPA лежит визуальный энкодер V-JEPA 2, предназначенный для извлечения устойчивых и информативных визуальных представлений из видеофрагментов. Этот энкодер обеспечивает эффективное кодирование визуальной информации, преобразуя сложные видеоданные в компактные векторные представления — визуальные эмбеддинги. Благодаря усовершенствованной структуре и алгоритмам обучения, V-JEPA 2 способен выделять наиболее значимые визуальные признаки, игнорируя несущественные детали и шум. Полученные таким образом эмбеддинги отличаются высокой устойчивостью к изменениям освещения, перспективы и другим факторам, влияющим на визуальное восприятие, что существенно повышает точность распознавания действий и эффективность поиска видео по текстовому запросу.
В основе успешной классификации действий в модели VL-JEPA лежит применение функции потерь InfoNCE, которая способствует формированию согласованного многомерного пространства представлений. Этот подход позволяет сопоставлять визуальные признаки видео с текстовыми описаниями действий, даже если конкретное действие не встречалось в обучающей выборке. Благодаря InfoNCE, модель учится выделять наиболее релевантные визуальные характеристики, соответствующие определенным текстовым запросам, что обеспечивает точную классификацию действий в условиях открытой лексики — то есть, без предварительного определения фиксированного набора классов. В результате, VL-JEPA способна распознавать широкий спектр действий, опираясь на семантическую близость между визуальными данными и текстовыми описаниями, что значительно расширяет возможности анализа видеоконтента.
Разработанная модель VL-JEPA, прошедшая предварительное обучение на масштабном наборе данных Action100M, демонстрирует стабильное повышение эффективности в задачах распознавания действий и поиска видео по текстовому запросу на различных эталонных тестах. Этот подход, объединяющий визуальное и текстовое представления, создает прочную основу для дальнейшего развития технологий понимания видео и мультимодального поиска. Успешное предварительное обучение позволяет модели эффективно обобщать знания и достигать высоких результатов даже в условиях, когда требуется распознавание действий, не встречавшихся ранее в процессе обучения, что открывает новые перспективы для создания интеллектуальных систем анализа видеоконтента.
Исследование представляет собой попытку упорядочить хаос визуальной информации, создавая обширный набор данных Action100M. Этот массив видеофрагментов, размеченных вручную, напоминает алхимический перегон, где из сырого потока данных выделяется эссенция действий. Подобно тому, как заклинание работает до первого испытания в реальном мире, любая модель распознавания действий обретает силу только благодаря масштабу и качеству данных. Как однажды заметил Джеффри Хинтон: «Я не улучшаю точность, я украшаю хаос». Действительно, создание Action100M — это не просто сбор данных, а своего рода придание формы неуловимому, попытка запечатлеть мгновения мира в цифровой форме, дабы обучить модели понимать и предсказывать действия, происходящие в видеопотоке.
Что же дальше?
Этот сборник отрезков движения, Action100M, — лишь ещё одна попытка уговорить хаос притвориться порядком. Миллионы аннотированных сегментов — это всего лишь больше наблюдений, облачённых в костюм истины. Модели учатся распознавать действия, но что, если само понятие «действие» — иллюзия, удобная для нашего ограниченного восприятия? График, показывающий улучшение в zero-shot обучении, вызывает не радость, а подозрение: значит, модель врёт красиво, подстраиваясь под ожидаемый результат.
Истинный вызов лежит не в увеличении объёма данных, а в понимании их природы. Необходимо искать не идеальные алгоритмы, а способы работать с неопределённостью. Шум — это просто правда, которой не хватило уверенности. Следующий шаг — научиться извлекать полезную информацию из кажущегося беспорядка, а не пытаться его подавить. Мир — не набор дискретных действий, а непрерывный поток вероятностей.
Попытки построить «мировые модели» обречены на провал, пока не признаётся, что сама концепция «модели» — это упрощение, искажение реальности. Данные — это не строительные блоки, а осколки зеркала. Собрать их воедино — значит увидеть лишь фрагментарное, искажённое отражение.
Оригинал статьи: https://arxiv.org/pdf/2601.10592.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Квантовый усилитель света на чипе: новый уровень эффективности
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые вычисления: линейная алгебра на службе симуляции
- Распознавание антинуклеарных антител: обучение на собственном темпе
- Самостоятельность в эпоху ИИ: Как студенты учатся учиться с искусственным интеллектом
- Искусственный интеллект на службе материаловедения: платформа AGAPI
- Сквозь флуоресценцию: нейросеть для очистки рамановских спектров
2026-01-18 00:47