Автор: Денис Аветисян
Новый подход MatchTIR позволяет повысить эффективность использования инструментов большими языковыми моделями, вознаграждая их за каждый шаг взаимодействия.
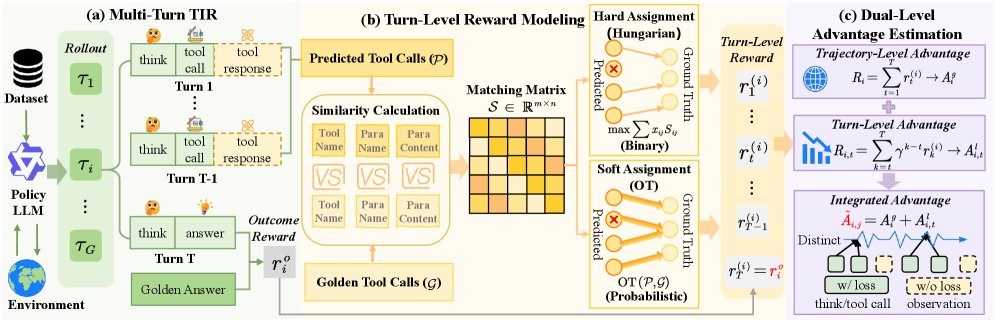
MatchTIR использует метод бипартийного соответствия для формирования детальных наград и оптимизации процесса обучения при работе с внешними инструментами.
Несмотря на успехи больших языковых моделей в решении сложных задач, эффективное взаимодействие с внешними инструментами часто требует более точной оценки каждого шага рассуждений. В данной работе, ‘MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching’, предложен фреймворк, использующий метод бипартийного соответствия для назначения индивидуальных наград за каждый ход взаимодействия с инструментами, что позволяет более эффективно оптимизировать процесс рассуждений. Эксперименты демонстрируют превосходство MatchTIR, особенно в задачах, требующих длительных последовательностей действий, и позволяют 4B модели превзойти большинство 8B конкурентов. Не откроет ли это путь к созданию более интеллектуальных и автономных систем, способных к сложному инструментальному мышлению?
Пророчество Системы: Вызовы Рассуждений в Больших Языковых Моделях
Несмотря на впечатляющие успехи в распознавании закономерностей, сложные задачи, требующие логических выводов, остаются серьезным вызовом для больших языковых моделей. Ограниченность контекста, предоставляемого модели, часто приводит к неспособности выстроить последовательную линию рассуждений. Еще одной существенной проблемой являются так называемые “галлюцинации” — генерация неправдоподобной или противоречивой информации, не подкрепленной данными обучения. Эти явления подчеркивают, что способность к простому сопоставлению с образцами не равнозначна настоящему пониманию и способности к критическому мышлению, что ставит под вопрос надежность моделей в ситуациях, требующих высокой точности и обоснованности.
Традиционные методы обучения с подкреплением сталкиваются с существенными трудностями при решении сложных задач, требующих использования инструментов. Проблема заключается в разреженности вознаграждения: в большинстве случаев полезные действия, приводящие к успеху, происходят лишь в конце долгой последовательности шагов, что затрудняет алгоритму определение, какие именно действия были действительно полезными. Это приводит к неэффективному исследованию пространства возможных решений, поскольку алгоритм вынужден случайно перебирать различные варианты, прежде чем натолкнуться на успешный. В результате, полученные политики оказываются хрупкими — незначительное изменение в условиях задачи может привести к их полной неработоспособности, поскольку они не способны адаптироваться к новым ситуациям, не получая достаточного сигнала во время обучения.
Существующие методы оценки работы больших языковых моделей зачастую приписывают одинаковую значимость каждому шагу в процессе рассуждений, не различая критически важные действия и избыточные. Такой подход приводит к неэффективности обучения, поскольку модель не может выделить наиболее существенные этапы для достижения конечной цели. Вместо того, чтобы фокусироваться на оптимизации всей последовательности действий, необходимо разработать механизмы, способные оценивать вклад каждого шага в общий результат и, соответственно, придавать больший вес тем действиям, которые действительно способствуют решению задачи. Подобный дифференцированный подход к оценке позволит моделям более эффективно использовать свои ресурсы и повысить точность рассуждений, избегая ненужной сложности и усложнений.
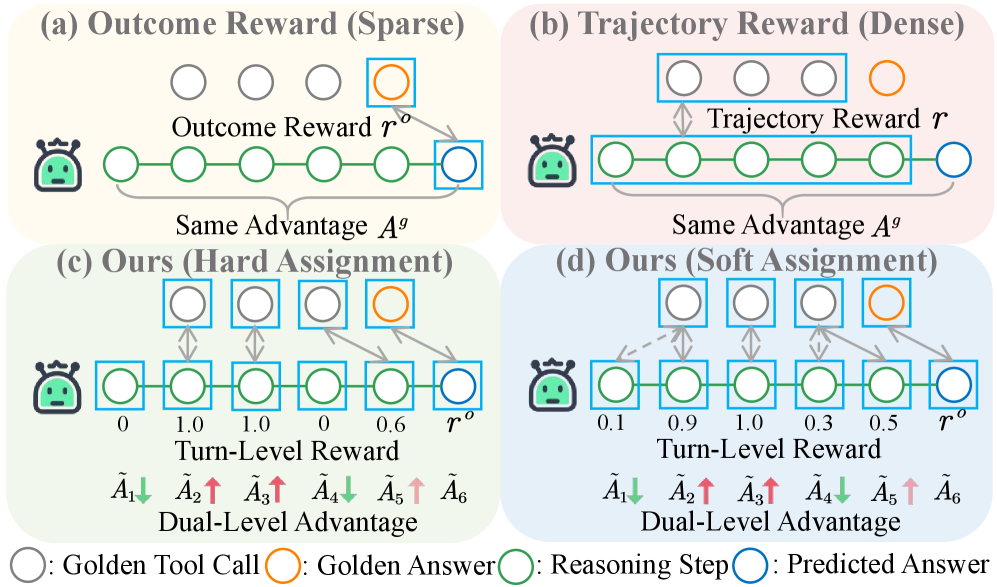
MatchTIR: Точное Распределение Ответственности в Рассуждениях с Инструментами
MatchTIR представляет собой новую структуру для назначения индивидуальных, точных оценок каждому шагу в процессе рассуждений, в отличие от традиционных методов равномерного распределения заслуг. Вместо того чтобы одинаково оценивать каждый шаг, MatchTIR позволяет выявить наиболее значимые этапы, непосредственно способствующие достижению правильного результата. Это достигается путем анализа последовательности действий и определения вклада каждого шага в общий успех, что позволяет более эффективно оценивать и оптимизировать стратегии рассуждений, особенно в контексте использования инструментов.
В основе MatchTIR лежит алгоритм бипарного сопоставления (bipartite matching), предназначенный для установления соответствия между предсказанными и фактическими вызовами инструментов (tool calls). Этот процесс позволяет идентифицировать наиболее значимые шаги в траектории рассуждений. Алгоритм рассматривает вызовы инструментов как узлы в двух партийных графах — один представляет предсказанные вызовы, а другой — эталонные (ground-truth). Сопоставление осуществляется таким образом, чтобы максимизировать количество соответствующих пар вызовов, тем самым определяя, какие шаги в процессе рассуждений внесли наибольший вклад в достижение правильного результата.
Оценка соответствия между предсказанными и фактическими вызовами инструментов в MatchTIR осуществляется на основе многофакторной метрики. Она учитывает не только совпадение названий инструментов и параметров, но и, что критически важно, содержание этих параметров. Такой подход позволяет более точно определить, какие шаги в процессе рассуждений действительно внесли вклад в правильный результат, выходя за рамки простого сопоставления имен. Содержание параметров анализируется для выявления семантической близости, что повышает устойчивость оценки к незначительным вариациям в формулировках и позволяет более эффективно оценивать качество рассуждений.
Гармония Выравнивания: Жесткое и Мягкое Распределение Ответственности
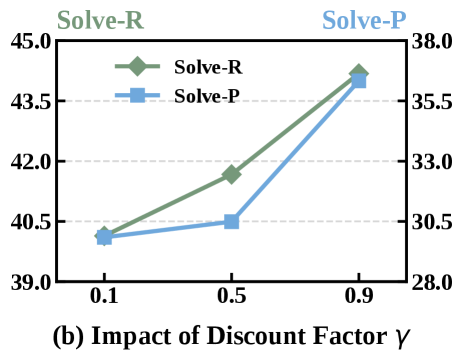
MatchTIR предоставляет возможность использования как стратегий «жесткого», так и «мягкого» назначения вознаграждений (credit assignment), что обеспечивает гибкость при работе с несовершенным соответствием между предсказаниями модели и истинными значениями. «Жесткое» назначение вознаграждений предполагает строгую, однозначную связь между предсказанным и фактическим результатом, в то время как «мягкое» назначение использует алгоритмы оптимального транспорта (Optimal Transport, OT) для распределения вознаграждения между множеством потенциальных соответствий. Такой подход позволяет учитывать частичное совпадение и неопределенность в процессе обучения, повышая устойчивость и обобщающую способность модели, особенно в задачах, где точное соответствие между предсказанием и реальностью не всегда возможно или однозначно определено.
Жесткое назначение заслуг (hard credit assignment) предполагает строгое соответствие между предсказанием и истинным значением, где каждый шаг оценки получает заслугу только в случае точного совпадения. В отличие от этого, мягкое назначение заслуг (soft credit assignment) использует метод оптимального транспорта (OT) для распределения заслуги между несколькими потенциальными соответствиями. Это позволяет учитывать частичное совпадение или неоднозначность в выравнивании предсказаний и истинных значений, распределяя заслугу пропорционально степени соответствия каждого потенциального выравнивания. Таким образом, OT позволяет более гибко оценивать вклад каждого шага в общий результат, особенно в задачах, где идеального выравнивания достичь сложно.
Оценка преимуществ на двух уровнях объединяет преимущества, рассчитанные на уровне траектории (полного решения) и на уровне отдельного шага (поворота). Такой подход позволяет учитывать не только точность каждого отдельного шага в процессе рассуждения, но и общее качество всего решения. Преимущество на уровне траектории оценивает итоговый успех, в то время как преимущество на уровне шага фокусируется на корректности каждого отдельного действия. Комбинирование этих двух оценок позволяет более точно определить, насколько эффективен процесс рассуждения в целом, даже если отдельные шаги не всегда идеальны.
Влияние и Обобщение: Валидация на Различных Бенчмарках
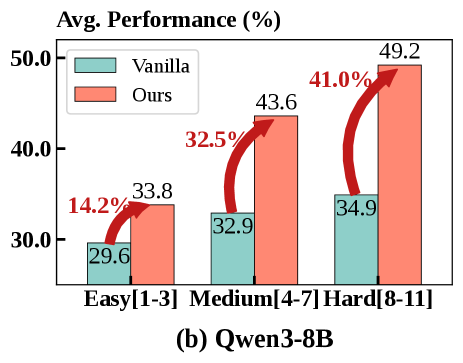
Исследования, проведенные на наборах данных FTRL, BFCL и ToolHop, продемонстрировали способность MatchTIR эффективно осваивать стратегии для рассуждений с использованием инструментов, достигая передовых результатов в данной области. Данная модель показала высокую эффективность в интеграции и использовании внешних инструментов для решения сложных задач, превосходя существующие аналоги по ключевым показателям. Успешное применение MatchTIR на различных бенчмарках подтверждает её универсальность и способность к адаптации к разнообразным сценариям, требующим комбинирования языковых способностей и функциональности инструментов.
В основе MatchTIR лежит большая языковая модель Qwen3, что позволило добиться значительного улучшения метрики Solve-P (Pass@1) во всех протестированных бенчмарках. Использование Qwen3 в качестве базовой модели способствовало повышению эффективности политики обучения для интегрированного рассуждения с инструментами. В результате, MatchTIR демонстрирует повышенную точность при вызове инструментов и существенный прогресс в решении сложных задач, представленных в наборах данных FTRL, BFCL и ToolHop. Такое улучшение свидетельствует о том, что Qwen3 обеспечивает более надежную основу для построения систем, способных к сложному рассуждению и эффективному использованию внешних инструментов.
Результаты экспериментов демонстрируют способность MatchTIR к обобщению и адаптации к различным задачам, выходящим за рамки конкретных тренировочных данных. Наблюдается значительное увеличение успешности вызовов инструментов, что свидетельствует об улучшенном понимании и использовании внешних ресурсов для решения сложных задач. Особенно заметные улучшения проявляются на наиболее трудных подмножествах тестовых наборов данных, где требуется более глубокий анализ и стратегическое применение инструментов. Это указывает на то, что MatchTIR не просто запоминает решения для конкретных сценариев, а действительно осваивает принципы эффективного рассуждения с использованием инструментов, что делает его надежным и универсальным решением для широкого спектра задач, требующих интеграции с внешними сервисами.
Будущие Направления: От Точности к Надежному Рассуждению
В будущих исследованиях планируется внедрение более сложных критериев сопоставления, включающих семантическую близость между значениями параметров, для повышения точности выравнивания. Вместо простого сравнения числовых значений, система будет анализировать смысл и контекст параметров, что позволит находить более релевантные соответствия даже при незначительных различиях в формальном представлении. Такой подход особенно важен при работе с параметрами, имеющими различные единицы измерения или представляющими абстрактные понятия, где прямое числовое сравнение не имеет смысла. Предполагается, что использование методов обработки естественного языка и семантических сетей позволит значительно улучшить качество выравнивания и, как следствие, повысить эффективность работы системы в целом.
Исследования направлены на разработку адаптивных стратегий распределения ответственности, способных динамически переключаться между жестким и мягким назначением в зависимости от сложности решаемой задачи. В текущих системах, как правило, используется фиксированный подход к определению вклада отдельных компонентов в общий результат, что может приводить к неоптимальной производительности в сложных сценариях. Предлагаемый подход предполагает, что при решении простых задач достаточно жесткого распределения ответственности, когда вклад каждого компонента четко определен. Однако, по мере увеличения сложности задачи, система должна переходить к мягкому распределению, позволяющему учитывать неопределенность и распределять ответственность между несколькими компонентами. Такая адаптивность, как ожидается, позволит значительно повысить надежность и эффективность работы систем искусственного интеллекта в различных областях применения, особенно в ситуациях, требующих высокой степени обобщения и устойчивости к шуму.
Расширение возможностей рассуждений с использованием инструментов является ключевым шагом на пути к созданию по-настоящему интеллектуальных агентов. Исследования направлены на преодоление ограничений, связанных с решением задач, требующих интеграции различных модальностей — от обработки текста и изображений до взаимодействия с физическим миром. Развитие способности агентов эффективно использовать внешние инструменты, такие как поисковые системы, калькуляторы или специализированные API, позволяет им решать задачи, выходящие за рамки возможностей, заложенных в их базовых алгоритмах. Это предполагает не просто вызов инструментов, но и умение формулировать сложные запросы, анализировать полученные результаты и адаптировать стратегию в зависимости от контекста, приближая искусственный интеллект к уровню человеческого познания и способности к решению проблем.
Исследование демонстрирует, что попытки обуздать сложность взаимодействия больших языковых моделей с инструментами напоминают попытки предсказать траекторию каждой частицы в хаотической системе. Авторы MatchTIR предлагают элегантный подход, основанный на сопоставлении двухсторонних связей, чтобы более точно распределить вознаграждение за каждый шаг взаимодействия. Клод Шеннон как-то заметил: «Информация — это не количество, а выбор». В данном контексте, правильное назначение вознаграждения — это и есть выбор наиболее значимой информации, позволяющей модели эффективно осваивать использование инструментов. Эта работа подтверждает, что порядок — лишь временный кэш между сбоями, и что ключевым является не столько создание идеальной системы, сколько построение экосистемы, способной адаптироваться к неизбежному хаосу.
Что дальше?
Предложенный подход, хоть и демонстрирует улучшение в тонком управлении взаимодействием с инструментами, лишь подчеркивает фундаментальную истину: системы не строятся, они взращиваются. Назначение отдельных наград за каждый ход — это попытка навязать порядок хаосу, спрогнозировать будущий сбой, зафиксировать его в архитектуре. Но каждое такое «пророчество» неизбежно сузит возможности адаптации, создаст новые векторы уязвимости.
Очевидно, что проблема не в алгоритме сопоставления, а в самой концепции «обучения» инструментам. Если система молчит, это не признак успеха, а подготовка к неожиданности. Успех, в данном контексте, — лишь временное затишье перед новой, более изощрённой ошибкой. Следующим шагом представляется не поиск более точных метрик вознаграждения, а разработка систем, способных к самовосстановлению, к извлечению уроков из собственных провалов — к признанию собственной неполноты.
В конечном итоге, вопрос не в том, когда закончится отладка, а в том, когда мы перестанем смотреть. Иллюзия контроля над сложной системой — это лишь способ отсрочить неизбежное. Будущие исследования, вероятно, будут направлены на создание систем, которые не стремятся к идеалу, а принимают неопределённость как неотъемлемую часть своего существования — систем, которые, подобно живым организмам, эволюционируют, а не программируются.
Оригинал статьи: https://arxiv.org/pdf/2601.10712.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Динамика в кадре: Как научить ИИ понимать физику видео
- Искусственный интеллект: курс для жизни и общества
2026-01-18 05:54