Автор: Денис Аветисян
Новый подход позволяет моделям искусственного интеллекта выявлять причинно-следственные связи, делая процесс более прозрачным и надежным.
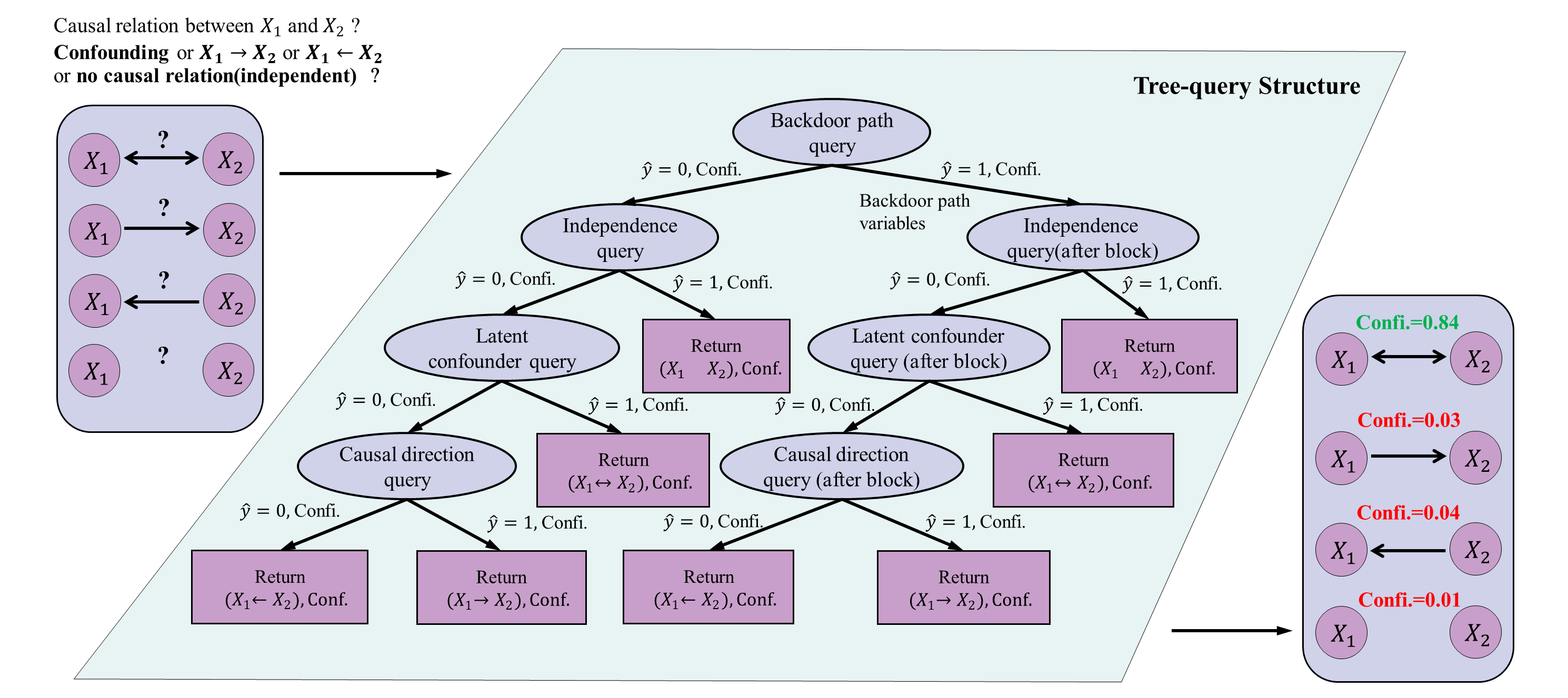
Представлен фреймворк Tree-Query, использующий многоагентные запросы и оценку достоверности для прозрачного обнаружения причинно-следственных связей и повышения точности выявления структурных причинных моделей.
Несмотря на прогресс в области обнаружения причинно-следственных связей, существующие методы часто страдают от ошибок и непрозрачности. В статье ‘Step-by-Step Causality: Transparent Causal Discovery with Multi-Agent Tree-Query and Adversarial Confidence Estimation’ представлен новый подход Tree-Query, использующий многоагентную систему на базе больших языковых моделей для выявления причинно-следственных связей с возможностью оценки достоверности. Предложенная архитектура позволяет получать интерпретируемые результаты и повышает точность по сравнению с существующими методами, особенно в условиях отсутствия данных. Способствует ли Tree-Query созданию более надежных и обоснованных моделей причинно-следственных связей, способных дополнить традиционные подходы к анализу данных?
Вызов без данных: Искусство причинности в условиях неопределенности
Традиционные методы выявления причинно-следственных связей в значительной степени зависят от наличия наблюдательных или интервенционных данных, сбор и анализ которых зачастую сопряжены с существенными трудностями и затратами. Получение достаточного объема качественных данных может быть проблематичным в различных областях, включая медицину, экономику и социальные науки, где сбор информации может быть дорогостоящим, длительным или даже невозможным по этическим соображениям. Эта зависимость от данных создает серьезное препятствие для широкого применения методов причинного вывода, особенно в сценариях, где информация ограничена или недоступна, что ограничивает потенциал развития искусственного интеллекта, способного к причинному мышлению и принятию обоснованных решений в условиях неопределенности.
Ограниченность данных представляет собой существенный тормоз для внедрения причинно-следственного анализа в различные области. В ситуациях, когда получение эмпирической информации затруднено или требует значительных затрат — например, при изучении сложных социальных явлений, редких заболеваний или систем с высокой степенью неопределенности — традиционные методы выявления причинно-следственных связей становятся неприменимыми. Это существенно ограничивает возможности развития и практического применения искусственного интеллекта, основанного на причинном анализе, поскольку алгоритмы нуждаются в достаточной статистической базе для надежной оценки взаимосвязей между переменными. В результате, потенциал причинного ИИ для принятия обоснованных решений и прогнозирования остается нереализованным во многих важных сферах.
Задача выявления причинно-следственных связей без использования данных — известная как Data-Free Causal Discovery — представляет собой уникальный и крайне важный вызов для современной науки. В отличие от традиционных методов, опирающихся на обширные наборы наблюдений или экспериментальных вмешательств, Data-Free Causal Discovery стремится к установлению причинности, используя лишь априорные знания о структуре системы и принципах ее функционирования. Это особенно актуально в тех областях, где сбор данных затруднен, дорогостоящ или попросту невозможен, например, в фундаментальных исследованиях, медицине, или при анализе сложных социальных явлений. Разработка эффективных методов Data-Free Causal Discovery открывает перспективы для применения причинного анализа в ситуациях, где ранее это казалось недостижимым, и способствует созданию более надежных и обоснованных моделей мира.
Tree-Query: Декомпозиция причинности с помощью языковых моделей
Tree-Query представляет собой многоэкспертную систему, предназначенную для декомпозиции сложного выявления причинно-следственных связей между парами переменных на серию лаконичных и прозрачных запросов. Вместо попытки прямого определения причинности, система разбивает задачу на последовательность более простых вопросов, каждый из которых направлен на проверку конкретного аспекта потенциальной причинно-следственной связи. Такая декомпозиция позволяет использовать сильные стороны больших языковых моделей (LLM) в области понимания и обработки естественного языка, что повышает надежность и интерпретируемость процесса выявления причинности. Каждый запрос сформулирован таким образом, чтобы его можно было однозначно обработать LLM, а результаты каждого запроса используются для уточнения последующих запросов, формируя итеративный процесс выявления причинно-следственных связей.
В основе подхода Tree-Query лежит систематическая оценка потенциальных причинно-следственных связей посредством последовательного применения специализированных типов запросов. Запросы независимости (Independence Query) используются для определения статистической независимости между переменными, что позволяет исключить прямые причинно-следственные связи. Запросы о задних путях (Backdoor Path Query) выявляют потенциальные смещения, вызванные конфаундерами, и позволяют оценить влияние лечения на исход при контроле соответствующих переменных. Запросы о латентных конфаундерах (Latent Confounder Query) направлены на выявление не наблюдаемых переменных, которые могут искажать оценку причинно-следственных эффектов. Последовательное применение этих типов запросов обеспечивает структурированный подход к выявлению и оценке причинно-следственных отношений.
В основе Tree-Query лежит подход, преобразующий задачу выявления причинно-следственных связей в серию чётко сформулированных вопросов. Это позволяет использовать сильные стороны больших языковых моделей (LLM) в области понимания и обработки естественного языка, а также их способность к логическим умозаключениям. Вместо попыток напрямую определить причинность из неструктурированных данных, LLM последовательно отвечают на конкретные вопросы, касающиеся независимости переменных, наличия обходных путей и потенциальных скрытых факторов, что повышает точность и интерпретируемость результатов.
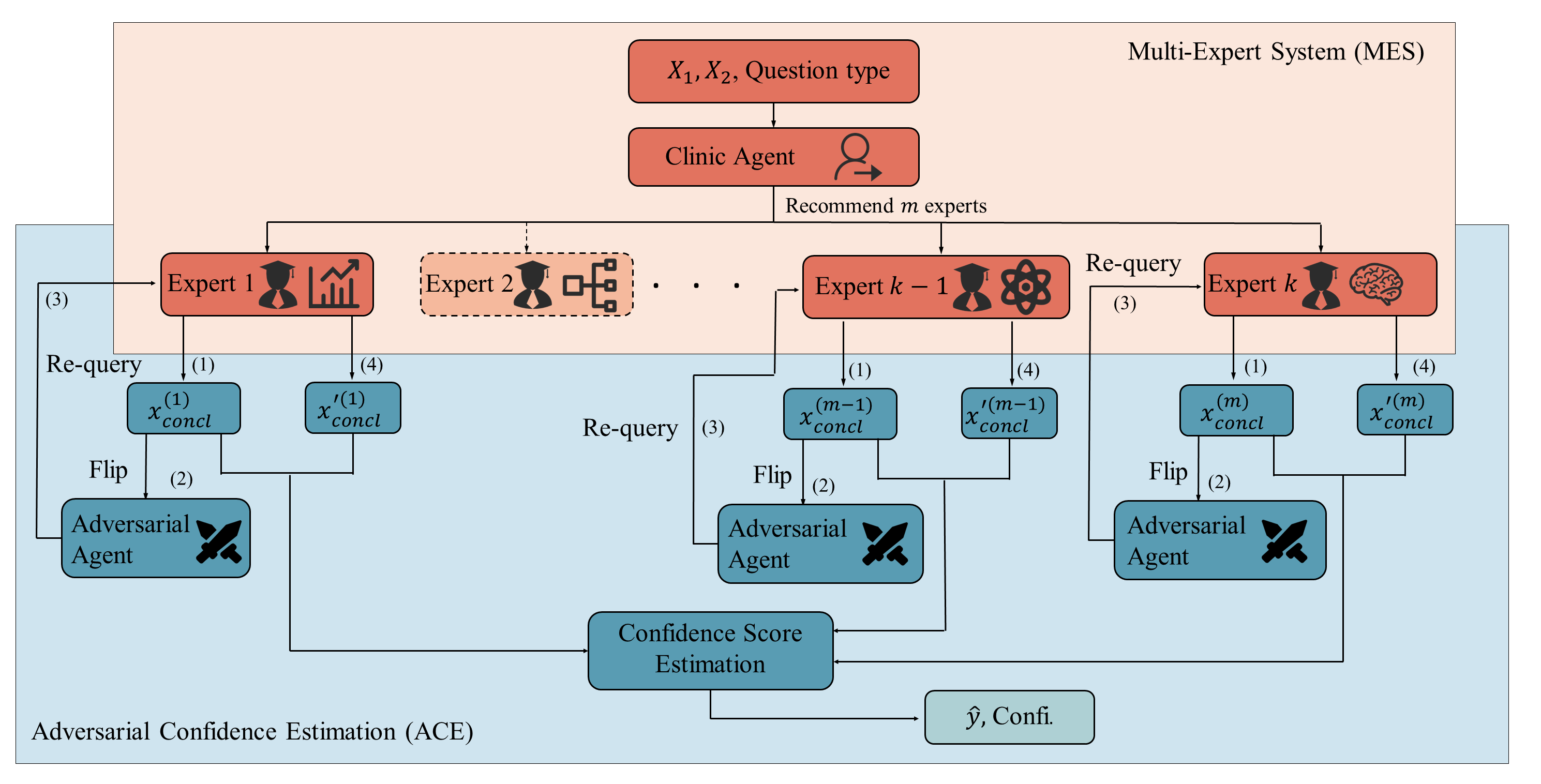
Проверка суждений LLM: Состязательная оценка уверенности
В рамках системы Tree-Query для строгой оценки устойчивости суждений, полученных от больших языковых моделей (LLM) о причинно-следственных связях, используется Adversarial Confidence Estimator (Оценщик Уверенности на основе Соперничества). Данный метод генерирует контраргументы, предназначенные для проверки исходных ответов LLM, выявляя потенциальные уязвимости или несоответствия в логике рассуждений. Процесс заключается в создании вопросов, направленных на оспаривание первоначальных заключений модели, что позволяет оценить, насколько уверенно LLM придерживается своих выводов при столкновении с альтернативными точками зрения и подтвердить надежность полученных результатов.
Метод генерации состязательных контраргументов заключается в создании альтернативных вопросов или сценариев, предназначенных для проверки устойчивости ответов языковой модели (LLM). Эти контраргументы формируются таким образом, чтобы бросить вызов первоначальным ответам LLM, выявляя потенциальные уязвимости, несогласованности или зависимость от поверхностных признаков входных данных. Анализ реакции модели на состязательные примеры позволяет оценить, насколько надежны и обоснованы ее первоначальные выводы, а также выявить случаи, когда LLM может давать неверные ответы при небольших изменениях во входных данных или контексте.
Для количественной оценки смещения распределений между исходными и адверсарными ответами используется расстояние Вассерштейна-1 (также известное как расстояние Землеройки). Этот показатель позволяет оценить, насколько сильно изменился ответ языковой модели при незначительных, но намеренных изменениях входных данных. Большое значение расстояния Вассерштейна-1 указывает на низкую устойчивость модели и потенциальную неуверенность в своих суждениях, в то время как малые значения свидетельствуют о высокой стабильности и уверенности. W_1(P, Q) = \in f_{γ ∈ Π(P, Q)} E_{(x, y) \sim γ}[||x - y||], где Π(P, Q) — множество всех совместных распределений, а ||x - y|| — метрика между точками x и y.
При использовании методологии Tree-Query наблюдается снижение количества структурных ошибок примерно на 20 ребер по сравнению с прямым запросом к языковой модели (LLM) на стандартных и скрытых бенчмарках. Данное снижение оценивается с помощью метрики Structural Hamming Distance (SHD), которая количественно определяет разницу в структуре полученных графов. Меньшее значение SHD указывает на более высокую точность и согласованность структуры, реконструированной методом Tree-Query, по сравнению с результатами, полученными напрямую от LLM.
В ходе оценки разработанного фреймворка были получены значения Normalized Discounted Cumulative Gain (NDCG) в диапазоне от 0.73 до 0.81 на стандартных (Standard) и скрытых (Latent) бенчмарках. Данный показатель, используемый для оценки ранжирования результатов, демонстрирует высокую релевантность и точность генерируемых ответов в задачах определения причинно-следственных связей. Полученные значения NDCG подтверждают эффективность предложенного подхода в сравнении с другими методами, используемыми для оценки качества ответов больших языковых моделей (LLM).
Коэффициент достоверности, получаемый в процессе состязательного тестирования, представляет собой количественную оценку устойчивости и надежности причинно-следственных утверждений, генерируемых языковой моделью. Этот коэффициент вычисляется на основе степени изменения ответа модели при предъявлении ей состязательных контраргументов. Более низкий коэффициент указывает на повышенную чувствительность к небольшим изменениям во входных данных, что свидетельствует о меньшей надежности сделанного вывода. Использование состязательной оценки позволяет оценить не только точность ответа, но и его устойчивость к потенциальным манипуляциям или неточностям во входных данных, предоставляя более полную картину надежности причинно-следственных суждений.
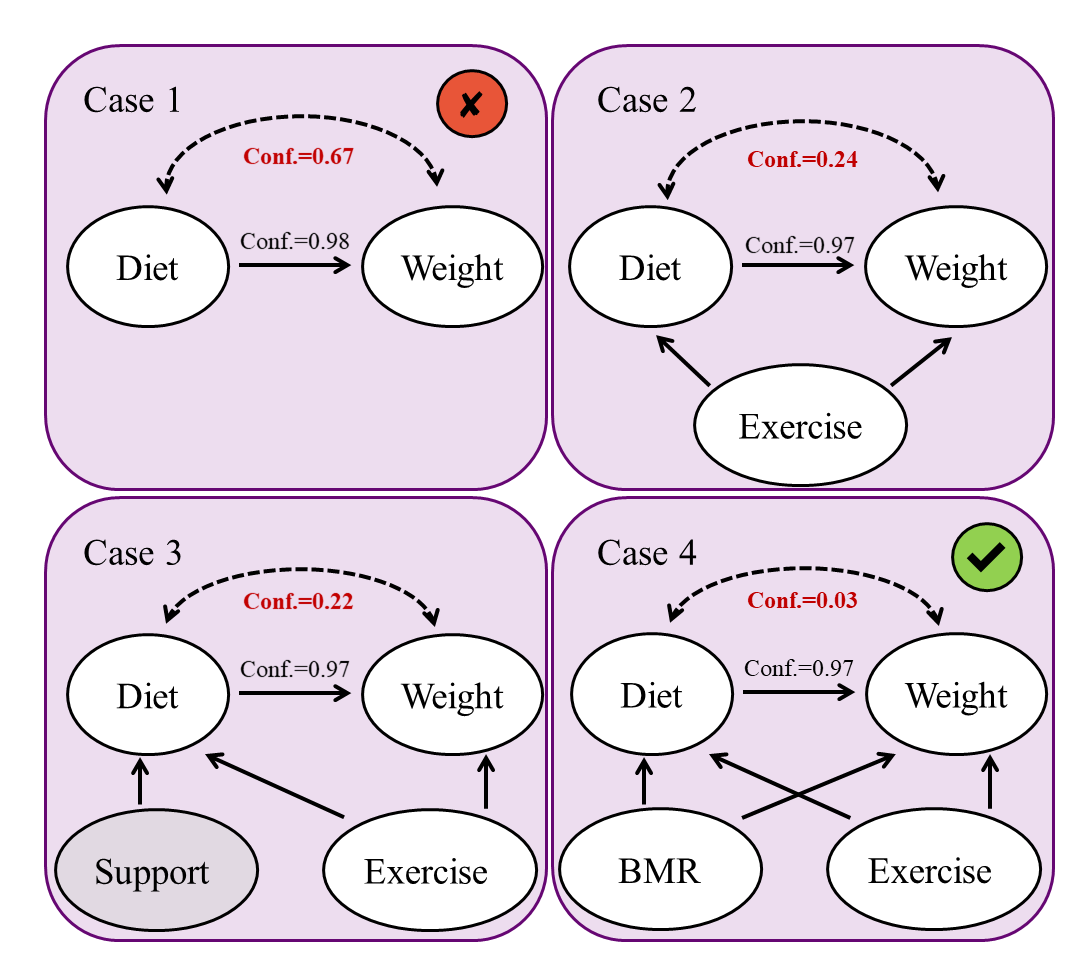
Расширение границ: Приложения и будущие направления
Метод Tree-Query, в сочетании с прямым обращением к большим языковым моделям (LLM), значительно расширяет границы Data-Free Causal Discovery — выявления причинно-следственных связей без использования традиционных наборов данных. Данный подход позволяет исследовать сложные системы, где сбор эмпирических данных затруднен или невозможен, используя знания, заложенные в LLM. Вместо анализа статистических закономерностей, Tree-Query формирует вопросы к языковой модели, выстраивая причинно-следственные гипотезы и проверяя их логическую состоятельность. Это открывает принципиально новые возможности для причинного анализа в областях, таких как первоначальные этапы научных исследований, оценка эффективности политических мер и прогнозирование последствий сложных решений, где традиционные методы анализа данных оказываются неэффективными или неприменимыми.
Подход, основанный на применении Tree-Query, существенно расширяет возможности причинно-следственного анализа в областях, где доступ к данным ограничен или вовсе отсутствует. Это открывает принципиально новые перспективы для проведения исследований на ранних стадиях научных открытий, когда эмпирические данные еще не собраны, а также для оценки потенциальных последствий предлагаемых политических решений. Возможность проведения причинного анализа, опирающегося на знания, а не на большие объемы данных, позволяет исследователям выдвигать и проверять гипотезы о причинно-следственных связях в условиях неопределенности, что особенно актуально для сложных систем, где сбор данных затруднен или невозможен. Таким образом, данный подход предоставляет ценный инструмент для формирования обоснованных выводов и принятия взвешенных решений в широком спектре областей, от фундаментальной науки до государственного управления.
Дальнейшие исследования направлены на повышение эффективности и масштабируемости алгоритма Tree-Query, что позволит применять его к более сложным и крупным системам. Особое внимание уделяется разработке новых методов генерации контраргументов, способных проверить устойчивость выявленных причинно-следственных связей. Исследователи стремятся создать алгоритм, который не только обнаруживает потенциальные причинные связи, но и активно ищет слабые места в этих выводах, генерируя альтернативные объяснения и сценарии. Такой подход позволит существенно повысить надежность и достоверность результатов, а также выявить скрытые факторы, влияющие на исследуемую систему, что особенно важно при принятии критически важных решений в областях науки и политики.
Слияние возможностей больших языковых моделей и причинно-следственного вывода открывает принципиально новые перспективы в понимании и воздействии на сложные системы. Этот симбиоз позволяет не просто выявлять корреляции в данных, но и устанавливать причинно-следственные связи, что критически важно для принятия обоснованных решений и прогнозирования последствий. Способность языковых моделей к анализу и генерации текста, в сочетании с методами причинно-следственного вывода, позволяет исследовать гипотетические сценарии, оценивать эффективность различных вмешательств и оптимизировать стратегии управления в самых разнообразных областях — от здравоохранения и экономики до экологии и социальных наук. Подобный подход обещает революционизировать способы моделирования сложных систем, позволяя перейти от реактивного анализа данных к проактивному управлению и предвидению.
Исследование представляет собой попытку не просто обнаружить причинно-следственные связи, но и сделать этот процесс прозрачным и надежным. Авторы предлагают метод Tree-Query, который, используя возможности больших языковых моделей, позволяет исследовать причинные структуры с повышенной точностью. Этот подход созвучен мысли Джона фон Неймана: «В науке не бывает абсолютно верных ответов, есть лишь более или менее вероятные модели». Подобно тому, как Tree-Query оценивает достоверность открываемых связей, фон Нейман подчеркивает необходимость критической оценки любой научной модели. В конечном счете, работа направлена на создание системы, способной не только устанавливать причинно-следственные связи, но и оценивать степень уверенности в этих выводах, что является ключевым шагом к построению действительно надежного и полезного знания.
Что дальше?
Представленный подход, манипулируя языковыми моделями для выявления причинно-следственных связей, открывает ящик Пандоры. Вместо слепого доверия к «черным ящикам», исследователи получают инструмент для деконструкции, для реверс-инжиниринга самой логики, лежащей в основе наблюдаемых корреляций. Однако, иллюзия прозрачности — всего лишь иллюзия. Вопрос не в том, насколько точно модель описывает причинность, а в том, насколько глубоко она способна её понять. Ибо причинность — это не просто связь между событиями, а контекст, намерения, даже абсурд.
Следующий этап — это выход за рамки статичных структурных моделей. Необходимо исследовать динамические системы, где причинность меняется со временем, где обратные связи и нелинейные эффекты усложняют картину. Использование языковых моделей для моделирования агентов, способных к обучению и адаптации, может стать следующим прорывом. При этом, важно помнить: ошибки в причинном графе — это не просто неточности, а потенциальные уязвимости, которые могут быть использованы для манипулирования системой.
И, наконец, стоит задуматься о границах применимости подобного подхода. Возможно ли, используя языковые модели, выявить причинность в системах, принципиально отличающихся от человеческого опыта? Может ли машина понять мотивы, лежащие в основе иррационального поведения? Или мы, в конечном итоге, просто создаем еще один инструмент для подтверждения собственных предрассудков, облаченный в научную оболочку?
Оригинал статьи: https://arxiv.org/pdf/2601.10137.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Динамика в кадре: Как научить ИИ понимать физику видео
- Искусственный интеллект: курс для жизни и общества
2026-01-18 07:38