Автор: Денис Аветисян
Новая разработка позволяет создавать реалистичные изображения с разных точек зрения даже в сложных, меняющихся сценах, используя лишь небольшое количество исходных кадров.
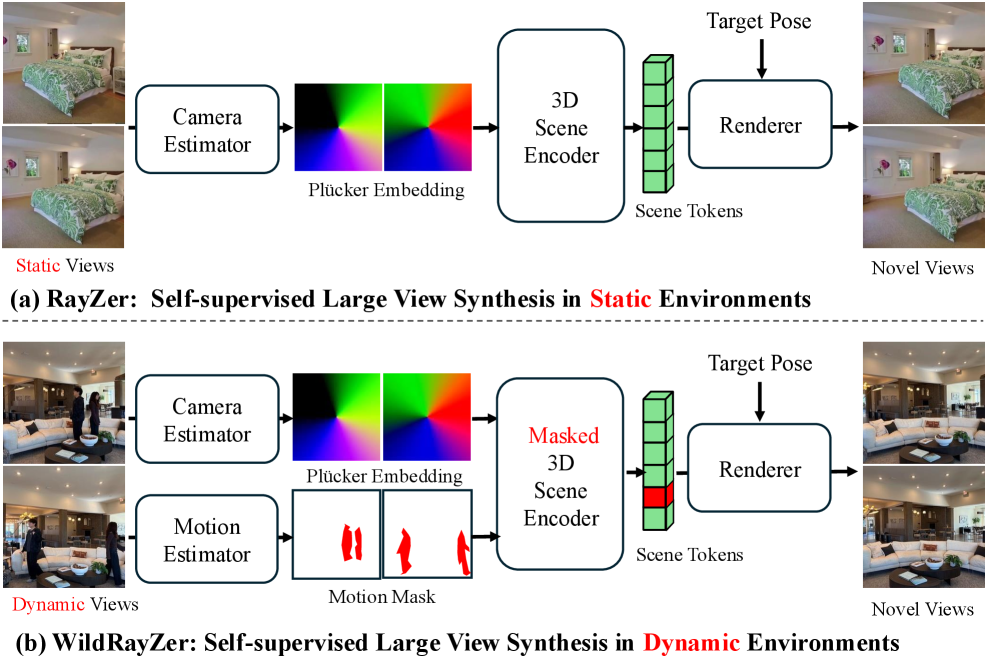
Представлен WildRayZer, самообучаемый фреймворк для синтеза новых видов в динамических сценах, использующий маскирование движения и архитектуры на основе трансформеров без необходимости в 3D-данных или ручной разметке.
Синтез новых видов в динамических сценах представляет собой сложную задачу из-за нарушения согласованности между видами, вызванного движением объектов и камеры. В данной работе представлена система ‘WildRayZer: Self-supervised Large View Synthesis in Dynamic Environments’ — самообучающийся фреймворк, позволяющий решать эту проблему путем анализа расхождений между рендерингом статической структуры и реальными изображениями для выделения движущихся областей. Предложенный подход позволяет эффективно разделять статические и динамические элементы сцены, используя маски движения для фокусировки обучения на заполнении фона и избежании артефактов. Сможет ли WildRayZer стать основой для создания реалистичных и стабильных 3D-реконструкций в сложных, динамичных условиях?
Шёпот Хаоса: Трудности Понимания Динамичных Сцен
Традиционные методы синтеза новых видов изображения сталкиваются с серьезными трудностями при работе с динамичными сценами. В основе многих алгоритмов лежит предположение о статической геометрии окружения, что приводит к появлению нежелательных артефактов — “призраков” и размытости на результирующих изображениях. Это происходит потому, что при движении объектов алгоритмы пытаются “наложить” их изображения из разных моментов времени на статическую сцену, создавая иллюзию двойного или размытого изображения. Данное ограничение существенно снижает реалистичность и достоверность генерируемых изображений, особенно в ситуациях с быстрым или сложным движением объектов, требуя разработки новых подходов, способных эффективно обрабатывать динамические изменения в сцене.
Точное представление и рендеринг движущихся объектов представляет собой сложную задачу восприятия, требующую идентификации и отделения этих объектов от статического фона. Эта сложность обусловлена тем, что визуальная информация о движении часто перекрывается с информацией о статичном окружении, что затрудняет отделение движущегося объекта от его фона. Алгоритмы должны учитывать не только изменение положения объекта, но и его форму, текстуру и взаимодействие со светом, чтобы правильно реконструировать сцену. Более того, процесс отделения движущихся объектов осложняется такими факторами, как окклюзии, изменения освещения и шум в данных, что требует разработки надежных и адаптивных алгоритмов, способных эффективно справляться с этими вызовами.
Существующие методы построения новых видов изображения зачастую опираются на предварительно размеченные данные или жёсткие априорные предположения о сцене. Это существенно ограничивает их способность адаптироваться к неизвестным окружениям и сложным траекториям движения объектов. Например, алгоритмы, обученные на определённом типе движения, могут демонстрировать значительные ошибки при обработке совершенно иных паттернов. Зависимость от размеченных данных требует значительных усилий по их сбору и аннотации, а жёсткие предположения могут приводить к нереалистичным результатам в сложных, динамически меняющихся ситуациях. В результате, универсальное решение, способное эффективно работать в любых условиях, остаётся сложной задачей, требующей разработки методов, способных к обучению без учителя и адаптации к новым условиям в реальном времени.
Самообучение и Разгадка Динамики: WildRayZer
WildRayZer представляет собой новую систему самообучения для построения нейронных визуальных представлений (NVS) динамических сцен, которая позволяет избежать необходимости в явных метках движения. В отличие от традиционных методов, требующих ручной аннотации движущихся объектов, WildRayZer использует только немаркированные видеоданные для обучения. Это достигается за счет разработки фреймворка, который самостоятельно извлекает информацию о движении из визуальных признаков сцены, что значительно упрощает процесс обучения и расширяет возможности применения системы в задачах, где получение размеченных данных затруднено или невозможно. Данный подход позволяет создавать точные и полные 3D-реконструкции динамических сцен без необходимости в дополнительных трудозатратах на разметку данных.
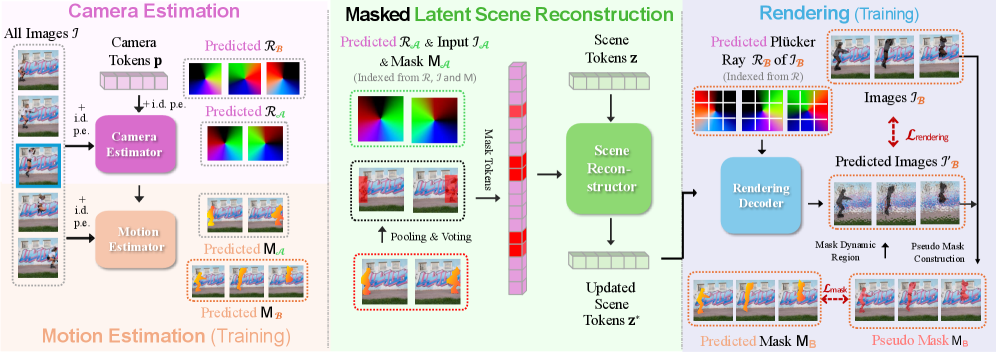
В основе WildRayZer лежит архитектура, использующая Transformer для кодирования сцен по разреженным видам и последующей реконструкции. Система применяет токенизированное представление сцены, где каждый токен соответствует определенной части пространства. Transformer обрабатывает эти токены, выявляя зависимости и взаимосвязи между различными участками сцены. Реконструкция осуществляется посредством токенизированного рендерера, который, основываясь на закодированной информации, генерирует изображение сцены. Такое представление позволяет эффективно обрабатывать разреженные входные данные и обеспечивать высококачественную реконструкцию геометрии и текстур сцены, даже при ограниченном количестве входных видов.
Ключевым нововведением в WildRayZer является автоматическое построение масок движения на основе семантических признаков, извлекаемых моделью DINOv3, и метрик структурного сходства (SSIM). DINOv3 предоставляет семантическую сегментацию, позволяющую идентифицировать движущиеся объекты, а SSIM оценивает различия в текстуре и структуре между кадрами, что помогает отделить статические и динамические элементы. Комбинация этих методов позволяет создавать точные маски движения без использования ручной разметки, обеспечивая среднее значение Intersection over Union (mIoU) более 65% по сравнению с данными ground truth.
Система WildRayZer демонстрирует передовые результаты в задачах нейронного визуального синтеза (NVS) как для статических, так и для динамических областей сцены. Оценка на сложных бенчмарках D-RE10K и D-RE10K-iPhone показала значительное улучшение производительности по сравнению с существующими методами. В частности, WildRayZer превосходит альтернативные решения в реконструкции как неподвижных объектов, так и быстродвижущихся элементов, что подтверждается количественными метриками и визуальным качеством реконструированных сцен.

Внутренний Механизм: Кодирование Сцены и Рендеринг
В WildRayZer используется Scene Encoder для создания латентного представления трехмерной сцены на основе входных изображений. Этот энкодер позволяет захватывать как статические, так и динамические элементы окружения, формируя компактное представление, пригодное для последующего рендеринга. Латентное пространство, созданное энкодером, содержит информацию о геометрии сцены, текстурах и движении объектов, что позволяет эффективно реконструировать новые виды и отображать изменения во времени. Такой подход позволяет добиться высокой производительности и качества рендеринга, особенно в сложных сценах с большим количеством динамических объектов.
Представление сцены в WildRayZer использует карты Плюккера (Plücker Ray Maps) для эффективного кодирования геометрии. Карты Плюккера представляют полупрямые линии в трехмерном пространстве, что позволяет компактно хранить информацию о геометрии сцены, включая положение и ориентацию поверхностей. В отличие от традиционных методов, таких как воксельные сетки или полигональные меши, карты Плюккера позволяют более эффективно представлять сложные и детализированные сцены, уменьшая объем требуемой памяти и ускоряя процесс рендеринга. Использование карт Плюккера оптимизирует кодирование геометрии для последующего процесса рендеринга, что позволяет добиться высокой производительности и качества изображения.
Декодер рендеринга реконструирует новые виды (novel views) на основе латентного представления сцены, используя сгенерированные маски движения для точного отображения динамических объектов. Этот процесс позволяет корректно отображать движущиеся элементы на реконструированных изображениях, обеспечивая визуальную согласованность и реалистичность. Маски движения, полученные в процессе кодирования сцены, служат для разделения статических и динамических частей изображения, что позволяет декодеру применять различные стратегии рендеринга для каждой из них и избегать артефактов, возникающих при рендеринге движущихся объектов.
Для обеспечения корректной визуализации с различных точек обзора, WildRayZer использует оценку положения камеры (Camera Pose Estimation). В ходе тестирования на наборе данных D-RE10K-iPhone, данная реализация демонстрирует стабильное превосходство над базовыми моделями по показателям PSNR, SSIM и LPIPS как в статических, так и в динамических областях изображения. Это подтверждает эффективность подхода в реконструкции сцен и корректном отображении движущихся объектов при изменении угла зрения.

Подтверждение Эффективности и Пути Развития
Исследования, проведенные на датасете Dynamic RealEstate-10K, продемонстрировали выдающиеся способности системы WildRayZer к генерации высококачественных новых видов динамичных сцен. Данный датасет, включающий видеозаписи реальных объектов с движением, позволил оценить способность системы корректно интерпретировать и воссоздавать сложные перемещения в пространстве. Результаты показали, что WildRayZer не только точно реконструирует геометрию сцены, но и реалистично воспроизводит динамические изменения, обеспечивая плавное и правдоподобное отображение новых перспектив. Эта способность делает систему перспективной для широкого спектра приложений, включая виртуальную реальность, создание цифровых двойников и автоматизированное редактирование видеоконтента.
Для повышения эффективности системы WildRayZer применялись методы аугментации данных, в частности, техника Copy-Paste Augmentation. Данный подход заключается в искусственном внедрении движения в статичные сцены путем копирования и вставки движущихся объектов из других кадров. Это позволяет значительно расширить обучающую выборку и обучить модель более устойчиво предсказывать маски движения в сложных динамических сценах, улучшая общую точность и реалистичность генерируемых изображений. В результате, модель демонстрирует повышенную способность к обобщению и адаптации к новым, ранее не встречавшимся видеопоследовательностям.
В ходе сравнительного анализа с передовыми методами, такими как VideoCutler и Segment Any Video, система WildRayZer продемонстрировала конкурентоспособные и, в некоторых случаях, превосходящие результаты в задаче предсказания масок движения. Это указывает на эффективность предложенного подхода в точном выделении движущихся объектов в динамических сценах. Полученные данные свидетельствуют о том, что WildRayZer способна более эффективно отделять движущиеся элементы от статического фона, что является ключевым фактором для реалистичной генерации новых видов и обеспечения высокого качества визуализации в динамических условиях. Данное достижение открывает перспективы для применения системы в различных областях, включая создание виртуальной реальности, редактирование видео и автоматизированный анализ движущихся объектов.
Система WildRayZer демонстрирует стабильное превосходство над базовыми методами в задачах генерации новых видов динамических сцен, что подтверждается результатами оценки по метрикам PSNR, SSIM и LPIPS. Улучшения по данным метрикам свидетельствуют о более высоком качестве генерируемых изображений: более высокое значение PSNR указывает на меньшее количество шумов, SSIM отражает более высокую степень структурного сходства с реальными изображениями, а LPIPS оценивает воспринимаемое визуальное качество, показывая, что сгенерированные изображения более правдоподобны и естественны для человеческого глаза. Данные показатели позволяют утверждать об эффективности предложенного подхода к моделированию и рендерингу динамических сцен, открывая перспективы для его применения в различных областях, включая виртуальную и дополненную реальность, а также компьютерное зрение.

Работа, представленная в статье, словно алхимический эксперимент с хаосом динамических сцен. Авторы стремятся извлечь порядок из кажущегося беспорядка, отделяя неподвижные объекты от движущихся, подобно магу, разделяющему стихии. Эта задача, кажущаяся невозможной без явного 3D-контроля, решается через самообучение, где модель сама постигает законы мира, наблюдая за потоком данных. Как однажды заметил Джеффри Хинтон: «Данные — это не цифры, а шёпот хаоса». И действительно, WildRayZer не просто реконструирует сцену, а уговаривает её проявиться, используя лишь скудные, разрозненные взгляды, словно заклинание, вычерчиваемое лучом GPU.
Что дальше?
Эта работа, как и любая попытка укротить хаос динамических сцен, демонстрирует лишь хрупкость наших заклинаний. WildRayZer умело отделяет неподвижное от движущегося, но стоит помнить: разделение — лишь иллюзия, удобный способ классифицировать шум. Истинная реальность, вероятно, представляет собой непрерывный танец неопределенности, где каждый пиксель колеблется между бытием и небытием. Идеальная реконструкция — повод для беспокойства, она лишь маскирует глубину нерешенных вопросов.
Следующим шагом, вероятно, станет отказ от попыток полного понимания. Вместо этого, стоит научиться жить с неточностью, использовать её как источник новой информации. Ограниченность данных — не недостаток, а приглашение к творчеству. Представляется перспективным направление, где модель не стремится к абсолютной истине, а генерирует вероятностные распределения, отражающие степень уверенности в каждом пикселе.
И, конечно, стоит опасаться масштабирования. Сложность сцен будет расти, и каждое добавленное измерение принесет новые возможности для ошибок. Возможно, истинный прогресс лежит не в увеличении разрешения, а в развитии способности к самообману — умении красиво сглаживать углы и убеждать наблюдателя в правдоподобности иллюзии. Шум — это просто правда, которой не хватило смелости.
Оригинал статьи: https://arxiv.org/pdf/2601.10716.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Динамика в кадре: Как научить ИИ понимать физику видео
- Искусственный интеллект: курс для жизни и общества
2026-01-18 09:14