Автор: Денис Аветисян
Исследователи представили TAG-MoE — систему, позволяющую нейросетям более эффективно решать различные задачи генерации и редактирования изображений, избегая конфликтов и оптимизируя специализацию.
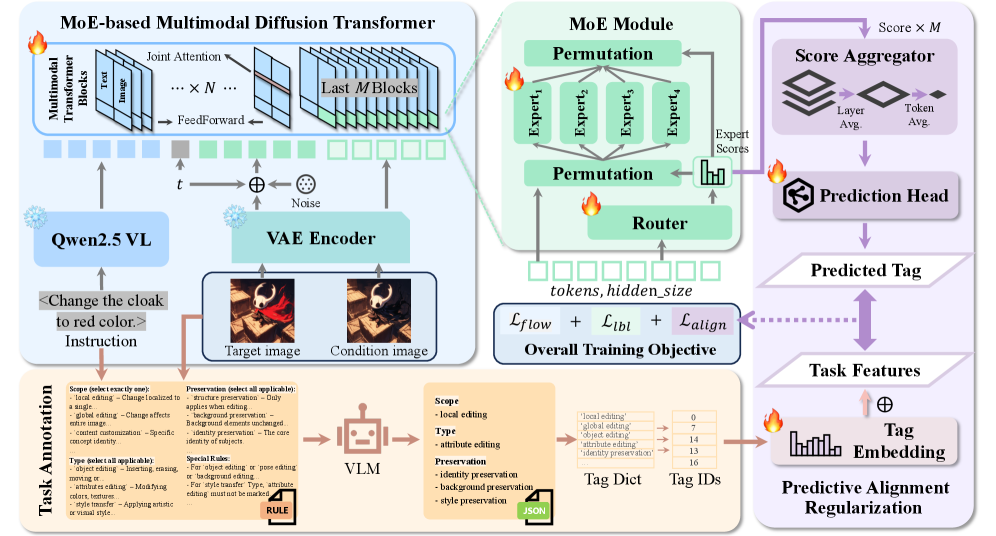
TAG-MoE — это новая разреженная архитектура Mixture-of-Experts с иерархической аннотацией задач и регуляризацией предсказуемого выравнивания, значительно улучшающая производительность в унифицированной генерации и редактировании изображений.
Единые модели генерации и редактирования изображений часто страдают от взаимного влияния задач в архитектурах плотных трансформеров. В данной работе, ‘TAG-MoE: Task-Aware Gating for Unified Generative Mixture-of-Experts’, предлагается новый подход к управлению маршрутизацией в разреженных моделях Mixture-of-Experts (MoE), основанный на семантическом анализе задачи и иерархической аннотации. Внедряя предсказательную регуляризацию для согласования внутренних решений маршрутизации с высокоуровневыми семантическими намерениями, авторы демонстрируют значительное снижение интерференции между задачами и эффективную специализацию экспертов. Возможно ли дальнейшее развитие этого подхода для создания еще более гибких и универсальных моделей генерации изображений?
Вызов Универсальной Генерации Изображений
Современные модели генерации изображений зачастую демонстрируют высокую специализацию, успешно справляясь с узким кругом задач, но испытывая трудности при переходе к новым. Это связано с явлением, известным как “интерференция задач” — когда обучение модели новым навыкам приводит к ухудшению производительности в уже освоенных областях. Суть проблемы заключается в том, что нейронные сети, оптимизированные для конкретных типов изображений или манипуляций, не способны эффективно обобщать полученные знания и адаптироваться к разнообразным запросам. В результате, попытки объединить несколько специализированных моделей в единую систему часто приводят к снижению общей производительности и требуют значительных усилий по их координации и оптимизации, что делает создание универсальной системы генерации изображений сложной задачей.
Увеличение масштаба моделей генерации изображений, хотя и привело к заметным улучшениям, демонстрирует тенденцию к уменьшению отдачи от вложенных ресурсов. Исследования показывают, что простое наращивание количества параметров не обеспечивает подлинную обобщающую способность, необходимую для эффективной работы с разнообразными задачами и данными. Вместо этого, акцент смещается в сторону разработки более эффективных архитектур, способных извлекать максимальную пользу из ограниченных вычислительных ресурсов. Эти новые подходы направлены на оптимизацию структуры модели и алгоритмов обучения, чтобы добиться значительного улучшения производительности без дальнейшего увеличения размера модели, открывая путь к более устойчивым и доступным решениям в области генерации изображений.
Современные системы генерации изображений сталкиваются с существенной проблемой — обеспечением плавных переходов между различными задачами манипулирования. Вместо того чтобы гибко адаптироваться к новым инструкциям, большинство моделей демонстрируют “забывание” предыдущих навыков при обучении новым, что приводит к неконсистентным результатам. Иными словами, система, успешно изменяющая стиль изображения, может испытывать трудности с добавлением или удалением объектов, если эти задачи не были предусмотрены во время обучения. Эта неспособность к универсальному управлению ограничивает потенциал генеративных моделей и подчеркивает необходимость разработки архитектур, способных к одновременному выполнению и бесшовному переключению между разнообразными визуальными преобразованиями, что является ключевым шагом к созданию действительно интеллектуальных систем генерации изображений.

TAG-MoE: Архитектура, Оптимизированная для Задач
TAG-MoE представляет собой новую архитектуру, основанную на фреймворке Mixture of Experts (MoE), предназначенную для создания специализированных путей обработки данных для каждой конкретной задачи. В отличие от традиционных MoE-моделей, где маршрутизация осуществляется на основе входных данных, TAG-MoE позволяет динамически активировать определенные эксперты, что обеспечивает более эффективное использование ресурсов и повышение производительности при решении различных задач. Ключевым отличием является создание отдельных путей обработки для каждого типа задачи, что минимизирует интерференцию между ними и способствует более точным и быстрым результатам. Архитектура обеспечивает масштабируемость и адаптивность к новым задачам без необходимости переобучения всей модели.
Архитектура TAG-MoE использует ‘Иерархическую Семантическую Аннотацию Задач’ для декомпозиции сложных задач на управляемые дескрипторы. Этот процесс предполагает разбиение исходной задачи на последовательность семантических признаков, представляющих собой иерархическую структуру. Каждый уровень иерархии описывает задачу с разной степенью детализации, что позволяет системе более точно определять, какие эксперты в модели наиболее подходят для обработки конкретного аспекта задачи. Полученные дескрипторы служат входными данными для механизма маршрутизации, направляя информацию к соответствующим экспертам, специализирующимся на конкретных типах операций или признаках изображения.
Архитектура TAG-MoE динамически активирует определенные эксперты в зависимости от входных данных, что позволяет избежать интерференции между различными задачами обработки изображений. Вместо использования единой модели для всех задач, TAG-MoE направляет каждый входной запрос к подмножеству экспертов, наиболее подходящих для его обработки. Этот механизм позволяет оптимизировать производительность на широком спектре задач, таких как стилизация, редактирование объектов и восстановление изображений, за счет снижения вычислительных затрат и повышения точности результатов по сравнению с моделями, использующими все эксперты для каждой задачи.

Прогностическое Выравнивание для Надежной Маршрутизации
Регуляризация предсказательного выравнивания (Predictive Alignment Regularization) заключается в установлении корреляции между семантикой задачи и внутренней «сигнатурой маршрутизации» (Routing Signature) сети MoE в процессе обучения. Данный метод предполагает, что структура активаций, определяющая выбор экспертов в сети MoE, должна соответствовать смысловому содержанию входной задачи. В ходе обучения применяется механизм, побуждающий внутренние представления сети (сигнатуру маршрутизации) отражать семантические характеристики задачи, что достигается путем минимизации расхождения между семантическим представлением задачи и распределением активаций экспертов. Это позволяет сети более эффективно использовать свои эксперты и улучшает обобщающую способность модели, особенно в условиях новых, ранее не встречавшихся задач.
Для обеспечения согласованности между семантикой задачи и выбором экспертов в сети MoE используется ‘Глобальное Семантическое Вложение’. Данное вложение формируется путем кодирования описания задачи в векторное представление, которое служит входным сигналом для механизма маршрутизации. В процессе обучения, это вложение сопоставляется с внутренними параметрами маршрутизации, позволяя сети предсказывать наиболее подходящих экспертов для решения конкретной задачи. Использование ‘Глобального Семантического Вложения’ позволяет эффективно передавать информацию о задаче механизму выбора экспертов, повышая точность и эффективность работы сети.
Предсказание оптимальной маршрутизации на основе семантики задачи позволяет повысить обобщающую способность модели и снизить потребность в специализированной настройке для каждой конкретной задачи. Использование семантической информации в качестве входных данных для процесса маршрутизации позволяет модели динамически адаптировать выбор экспертов в зависимости от характера входных данных. Это приводит к более эффективному использованию параметров модели и улучшает её способность к адаптации к новым, ранее не встречавшимся задачам, тем самым уменьшая зависимость от большого количества данных для тонкой настройки под каждую отдельную задачу.
Комплексное Бенчмаркинг и Производительность
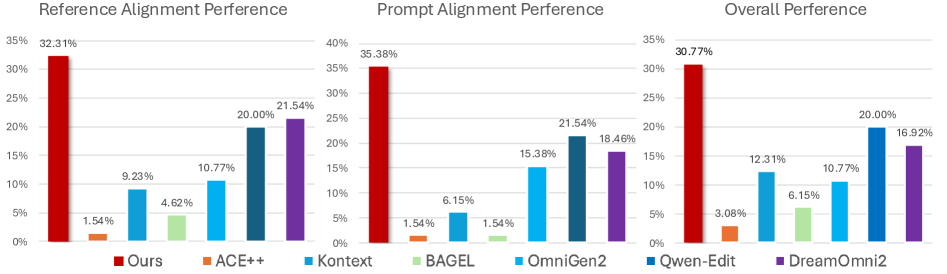
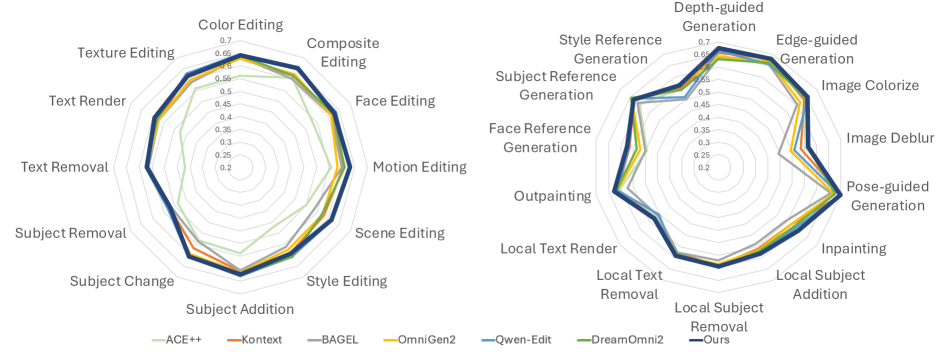
Модель TAG-MoE продемонстрировала передовые результаты на ключевых бенчмарках, включая ‘ICE-Bench’, ‘EmuEdit-Bench’, ‘DreamBench++’ и ‘OmniContext’, что свидетельствует о её высокой универсальности и способности эффективно решать разнообразные задачи. Данное достижение подтверждает, что TAG-MoE способна успешно справляться с широким спектром требований к генерации и редактированию изображений, превосходя существующие аналоги в различных сценариях. Высокие показатели на этих бенчмарках указывают на способность модели генерировать изображения высокого качества и точности, адаптируясь к различным стилям и контекстам, что делает её ценным инструментом для исследователей и разработчиков в области компьютерного зрения и искусственного интеллекта.
Для всесторонней оценки качества генерируемых изображений и точности выполнения поставленных задач применялись строгие метрики, такие как ‘CLIP Score’ и ‘VLLMQA Score’. ‘CLIP Score’ позволяет измерить соответствие изображения текстовому описанию, оценивая семантическое сходство между ними, в то время как ‘VLLMQA Score’ фокусируется на проверке корректности выполнения конкретных инструкций в рамках визуальных задач. Использование данных метрик обеспечило объективную и количественную оценку производительности модели, позволяя сравнить её с другими существующими методами и продемонстрировать её превосходство в создании визуально реалистичных и семантически точных изображений.
Результаты исследований демонстрируют значительное превосходство TAG-MoE над существующими методами как по точности, так и по эффективности. В частности, модель достигла показателя CLIP-cap более 0.5 на бенчмарке ICE-Bench, что позволило ей не только превзойти все открытые аналоги, но и показать лучшие результаты по сравнению с некоторыми закрытыми моделями. Данный результат свидетельствует о высокой способности TAG-MoE к генерации изображений, соответствующих текстовым запросам, и о её эффективности в решении сложных задач визуального редактирования, подтверждая её перспективность в области искусственного интеллекта.
В ходе комплексного тестирования модель TAG-MoE продемонстрировала выдающиеся результаты на различных бенчмарках. В частности, она достигла наивысшего показателя vllmqa как на EmuEdit-bench, так и на GEdit-bench, что свидетельствует о её превосходстве в задачах редактирования изображений на основе текстовых запросов. Кроме того, модель установила новые стандарты производительности, добившись лучших в отрасли (state-of-the-art, SOTA) оценок Face-ref и Style-ref на DreamBench++ и OmniContext. Это подтверждает способность TAG-MoE генерировать изображения с высокой степенью детализации и соответствием заданному стилю, что делает её перспективным инструментом для широкого спектра приложений в области компьютерного зрения и генеративного искусства.
Проведенные исследования с участием 65 респондентов и охватившие 50 различных сценариев продемонстрировали, что модель TAG-MoE достигла наивысшего общего показателя выбора среди представленных вариантов. Этот результат указывает на то, что пользователи последовательно предпочитают изображения, сгенерированные TAG-MoE, что свидетельствует о превосходном качестве и релевантности создаваемых ею визуализаций. Высокий показатель выбора, полученный в ходе пользовательских исследований, подтверждает объективные метрики, такие как CLIP Score и VLLMQA Score, и подчеркивает способность модели TAG-MoE эффективно соответствовать ожиданиям пользователей и создавать визуально привлекательный и информативный контент.
Представленная работа демонстрирует элегантный подход к проблеме унифицированной генерации и редактирования изображений. Авторы, подобно умелым архитекторам, предлагают TAG-MoE — систему, где каждый «эксперт» специализируется на определенной задаче, избегая ненужного вмешательства и повышая эффективность. Это напоминает слова Дэвида Марра: «Сложность — это признак плохого дизайна. Хороший дизайн должен быть простым и понятным». В данном случае, сложность решается за счет иерархической аннотации задач и предсказуемой регуляризации, что позволяет достичь семантического выравнивания и избежать хаоса в процессе генерации. Использование sparse MoE, где каждый эксперт берет на себя свою роль, подтверждает принцип: красота масштабируется, беспорядок — нет.
Куда Далее?
Представленная работа, несомненно, демонстрирует элегантность подхода к проблеме унифицированной генерации и редактирования изображений. Однако, подобно любому тщательному построению, она обнажает новые грани нерешенных вопросов. Очевидно, что иерархическая аннотация задач, хоть и эффективна, требует значительных усилий по ручной маркировке. Будущие исследования могли бы сосредоточиться на автоматизации этого процесса, возможно, используя методы самообучения или слабо контролируемого обучения, чтобы снизить зависимость от экспертных знаний.
Более того, несмотря на заявленное снижение интерференции между задачами, остается открытым вопрос о полной изоляции экспертов. Каждый элемент системы должен быть на своём месте, создавая целостность, но насколько глубока эта интеграция? Вероятно, стоит исследовать способы динамического перераспределения экспертов и адаптации их специализации в реальном времени, чтобы добиться ещё большей гибкости и эффективности.
В конечном итоге, успех TAG-MoE — это не столько достижение конечной точки, сколько указание направления. Истинная гармония между формой и функцией заключается не в решении всех проблем, а в умении правильно формулировать следующие вопросы. Следующим шагом, вероятно, станет исследование возможности применения подобного подхода к более сложным мультимодальным задачам, где взаимодействие между различными типами данных требует ещё более тонкой настройки и координации.
Оригинал статьи: https://arxiv.org/pdf/2601.08881.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Искусственный интеллект на службе Земли: новые горизонты моделирования
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Динамика в кадре: Как научить ИИ понимать физику видео
2026-01-18 17:41