Автор: Денис Аветисян
Новое исследование демонстрирует, как можно значительно улучшить способность нейросетей понимать сложные видеозаписи, снятые от первого лица, и отвечать на вопросы о них.
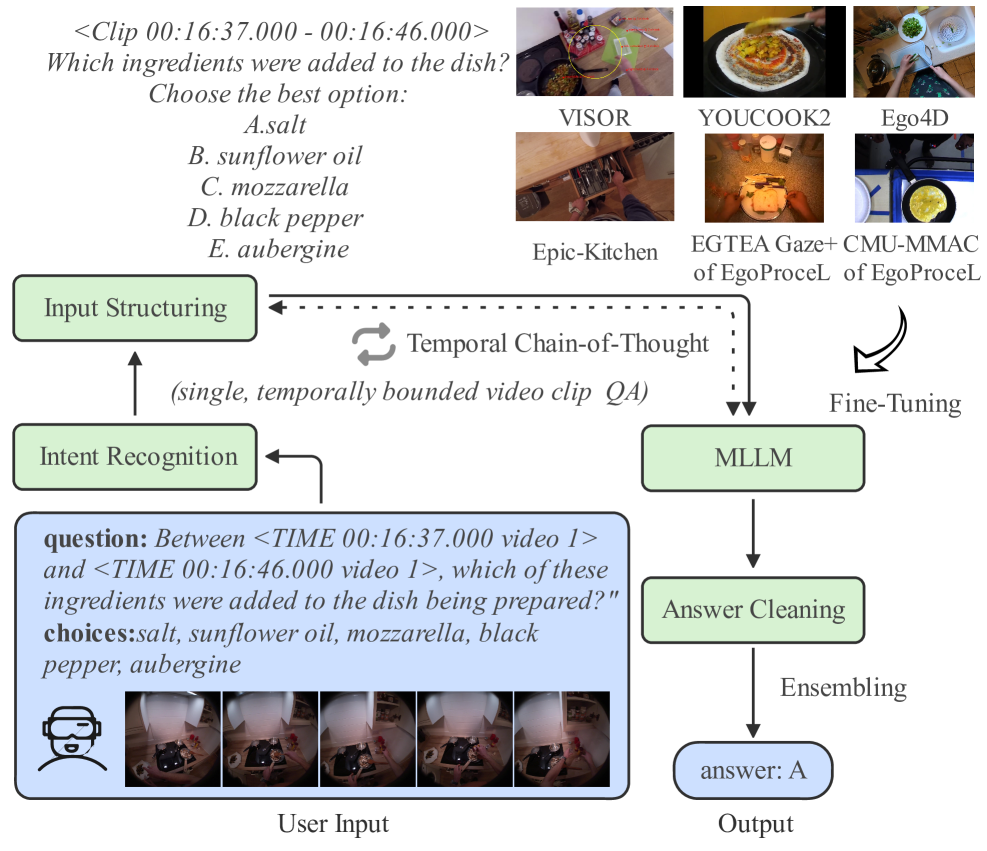
В статье представлен комплексный подход, включающий предварительную обработку данных, тонкую настройку моделей и стратегию Temporal Chain-of-Thought, для решения задач визуальных вопросов и ответов на наборе данных HD-EPIC.
Несмотря на успехи больших языковых моделей, понимание видеоданных, особенно в контексте эгоцентричной перспективы, остается сложной задачей. В данной работе, ‘Optimizing Multimodal LLMs for Egocentric Video Understanding: A Solution for the HD-EPIC VQA Challenge’, предложен комплексный подход к оптимизации мультимодальных LLM для решения задачи визуального вопросно-ответного анализа (VQA) по эгоцентричным видеоданным. Разработанная система, включающая предварительную обработку данных, тонкую настройку модели Qwen2.5-VL и инновационную стратегию Temporal Chain-of-Thought (T-CoT), достигла значительного улучшения точности на датасете HD-EPIC VQA. Какие еще методы можно использовать для повышения эффективности LLM в анализе и интерпретации динамических визуальных сцен?
Понимание Визуального Мира: Вызовы Эгоцентричного VQA
Традиционные системы визуального вопросно-ответного анализа (VQA) испытывают значительные трудности при обработке видеоданных, полученных от первого лица, так называемой “эгоцентрической” перспективы. В отличие от анализа статических изображений или видео, снятых со стороны, эгоцентрические данные представляют собой поток визуальной информации, тесно связанный с действиями и точкой зрения конкретного человека. Это создает уникальные проблемы, поскольку модели VQA должны не только распознавать объекты и события, но и учитывать динамичную перспективу, частичное наблюдение за сценой и неявные намерения действующего лица. Сложность заключается в том, что стандартные архитектуры VQA, разработанные для более общих сценариев, часто не способны эффективно обрабатывать эту субъективную и динамичную визуальную информацию, что приводит к снижению точности и надежности ответов на вопросы.
Современные мультимодальные большие языковые модели (MLLM) испытывают значительные трудности при обработке видеоданных от первого лица, поскольку временная последовательность действий и необходимость выводить контекст из субъективной точки зрения представляют собой серьезные препятствия. В отличие от анализа статических изображений, понимание видео требует от модели не только идентификации объектов, но и отслеживания их изменений во времени, а также интерпретации действий, выполняемых наблюдателем. Субъективная перспектива усложняет задачу, поскольку требует от модели учитывать точку зрения действующего лица, что часто включает в себя неявные знания о его намерениях и окружающей среде. Таким образом, стандартные архитектуры, разработанные для обработки статических данных, оказываются недостаточно эффективными для анализа динамичных, субъективных видео, что подчеркивает необходимость разработки новых методов, способных к глубокому временному рассуждению и пониманию контекста.
Для успешного решения проблем, возникающих при анализе видео из первого лица, необходимы модели, обладающие глубоким пониманием временных зависимостей. Существующие архитектуры машинного обучения, как правило, испытывают трудности с анализом последовательностей событий и установлением причинно-следственных связей во времени. Они часто фокусируются на статичных изображениях или краткосрочных взаимодействиях, упуская из виду долгосрочные зависимости, критически важные для интерпретации действий, происходящих с точки зрения конкретного наблюдателя. Разработка моделей, способных эффективно моделировать временные паттерны и делать обоснованные выводы о происходящем на основе контекста, является ключевой задачей для продвижения в области Visual Question Answering в egocentric сценариях.
Основа для Понимания: Qwen2.5-VL и Тонкая Настройка
В качестве основы для нашей системы эгоцентрического VQA (Visual Question Answering) мы используем Qwen2.5-VL — мощную открытую многомодальную языковую модель (MLLM). Qwen2.5-VL предоставляет предварительно обученную архитектуру, способную обрабатывать как визуальные, так и текстовые данные, что позволяет ей эффективно понимать и отвечать на вопросы, касающиеся видеоконтента, снятого от первого лица. Использование открытой модели обеспечивает прозрачность и возможность модификации для адаптации к специфическим требованиям нашей задачи и позволяет избежать ограничений, связанных с проприетарными решениями.
Для адаптации модели к задачам, связанным с egocentric видео, критически важным является проведение тонкой настройки на разнообразных наборах данных, включающих EPIC-KITCHENS, CMU-MMAC, Ego4D, VISOR, YOUCOOK2 и EGTEA Gaze+ из EgoProceL. Использование этих наборов данных позволяет модели освоить специфические визуальные паттерны и временные зависимости, характерные для видео, снятых от первого лица. Разнообразие данных обеспечивает обобщающую способность модели и повышает её эффективность в решении задач, связанных с пониманием и анализом egocentric видеоконтента.
Процесс тонкой настройки модели на разнообразных наборах данных, включающих EPIC-KITCHENS, CMU-MMAC, Ego4D, VISOR, YOUCOOK2 и EGTEA Gaze+ из EgoProceL, позволяет модели освоить специфические визуальные паттерны и временные зависимости, характерные для видео, снятых от первого лица. В результате, точность модели при решении задач многошаговой локализации (Multi-Step Localization) повышается с 22% до 26% после проведения тонкой настройки. Это демонстрирует значительное улучшение производительности модели в контексте понимания и интерпретации последовательностей визуальных данных, полученных от первого лица.
Углубление Понимания: Предварительная Обработка Данных и Рассуждения
Эффективное распознавание намерения вопроса достигается за счет анализа входных модальностей и уточнения запроса, что обеспечивает получение многомодальной языковой моделью (MLLM) четких и однозначных инструкций. Анализ входных модальностей позволяет определить тип и структуру входных данных (текст, изображение и т.д.), что необходимо для корректной интерпретации вопроса. Уточнение запроса включает в себя перефразирование, удаление неоднозначностей и добавление контекста, чтобы MLLM могла точно понять, что требуется. Оптимизация запроса напрямую влияет на качество ответа и снижает вероятность ошибочной интерпретации.
Для повышения эффективности решения задач, связанных с временной логикой, используется двухэтапный подход рассуждений (Two-Stage Reasoning) в сочетании с методом Temporal Chain-of-Thought (T-CoT) подсказками. В ходе тестирования на бенчмарке HD-EPIC VQA, применение целенаправленных улучшений входных данных позволило добиться прироста точности на 3,5%. Дальнейшее использование стратегии T-CoT обеспечило дополнительное увеличение точности на 3,0%, что свидетельствует о синергетическом эффекте от комбинирования этих двух методов.
Предварительная обработка данных оптимизирует входные данные для модели Qwen2.5-VL-7B, повышая её способность к пониманию и точному ответам на сложные вопросы, связанные со временем. Экспериментально установлено, что использование алфавитных перечислений даёт прирост точности в 1.6%, межвариантного пробела — 1.8%, точек с запятой — 2.0%, а разделения новой строкой — 2.4%. Эти методы позволяют улучшить структурирование входных данных, что положительно сказывается на производительности модели при решении задач, требующих анализа временных последовательностей и взаимосвязей.
Оптимизация Результатов: Постобработка и Ансамблирование
Постобработка, включающая очистку ответов (Answer Cleaning) и ансамблирование, направлена на снижение вероятности ошибок и повышение надежности ответов модели. Очистка ответов предполагает фильтрацию и коррекцию сгенерированных ответов для удаления нерелевантной или неточной информации. Ансамблирование заключается в генерации нескольких предсказаний и последующем агрегировании их, например, с помощью голосования большинства, что позволяет уменьшить влияние индивидуальных смещений модели или неверных выводов. Применение данных методов позволяет добиться повышения точности на 0.8% за счет очистки ответов, что свидетельствует об их эффективности в улучшении качества и надежности системы.
Использование метода генерации нескольких предсказаний и последующего голосования большинством позволяет снизить влияние индивидуальных смещений модели или ошибочных выводов. В процессе Answer Cleaning, применение данной стратегии привело к повышению точности на 0.8%. Суть подхода заключается в том, что потенциальные ошибки в отдельных предсказаниях компенсируются корректными ответами, полученными в результате других итераций генерации, что повышает общую надежность системы.
В результате применения методов постобработки и ансамблирования была создана устойчивая и точная система VQA, предназначенная для работы с реальными сценариями. После тонкой настройки системы достигнута точность в 25% для локализации шагов (Step Localization) и 28% для приблизительной локализации шагов (Rough Step Localization). Данные показатели демонстрируют значительное улучшение по сравнению с исходными значениями, подтверждая эффективность предложенных методов повышения надежности и точности системы.
Взгляд в Будущее: Влияние и Перспективы Развития
Наше исследование продемонстрировало впечатляющий потенциал точно настроенных мультимодальных больших языковых моделей (MLLM) в решении сложных задач визуального рассуждения, имитирующих восприятие от первого лица. Этот подход позволяет моделям интерпретировать визуальную информацию, словно они “видят” мир глазами пользователя, что критически важно для понимания контекста и принятия решений в реальном времени. Способность MLLM анализировать изображения и одновременно применять языковые знания открывает новые горизонты для автоматизации задач, требующих не только распознавания объектов, но и понимания их взаимосвязей и намерений, что является важным шагом к созданию более интеллектуальных и адаптивных систем.
Разработанная технология открывает широкие возможности в различных областях. В сфере вспомогательной робототехники она позволит создавать более интеллектуальных помощников, способных понимать и реагировать на визуальные команды и потребности человека в реальном времени. В области персонализированной медицины система может использоваться для анализа изображений, полученных с носимых устройств, и предоставления индивидуальных рекомендаций по здоровью. Кроме того, технология способствует развитию более интуитивных интерфейсов взаимодействия человек-компьютер, позволяя пользователям управлять устройствами и приложениями с помощью естественных визуальных сигналов, что значительно упрощает процесс коммуникации и повышает эффективность работы.
Наши дальнейшие исследования направлены на значительное расширение существующих наборов данных, что позволит моделям обучаться на более разнообразных и реалистичных сценариях. Особое внимание мы уделяем разработке усовершенствованных стратегий рассуждений, выходящих за рамки простого распознавания объектов и включающих причинно-следственные связи и прогнозирование. Ключевой задачей является повышение способности модели к обобщению, то есть к успешной работе в принципиально новых, ранее не встречавшихся условиях, что критически важно для надежного применения в реальном мире. Это потребует не только увеличения объема данных, но и внедрения методов обучения, позволяющих модели адаптироваться к изменениям окружающей среды и эффективно использовать полученные знания в новых ситуациях.
Исследование демонстрирует, что эффективное понимание видеоданных требует не просто обработки визуальной информации, но и выстраивания логической цепочки рассуждений во времени. Авторы подчеркивают важность предобработки данных и тонкой настройки больших языковых моделей для достижения высокой производительности в задачах визуального вопросно-ответного анализа (VQA). Как однажды отметила Фэй-Фэй Ли: «Искусственный интеллект должен быть построен на основе понимания, а не просто на распознавании образов». Данное утверждение особенно актуально в контексте анализа эгоцентричных видео, где необходимо улавливать сложные временные зависимости и интерпретировать действия в реальном времени, чтобы обеспечить осмысленные ответы на поставленные вопросы. Успешное применение Temporal Chain-of-Thought prompting подтверждает, что структурированный подход к рассуждениям значительно улучшает способность модели к пониманию и генерации осмысленных ответов.
Что дальше?
Представленная работа, безусловно, демонстрирует прогресс в обучении больших языковых моделей пониманию эгоцентричного видео. Однако, кажущееся решение задачи не должно вводить в заблуждение. Остается открытым вопрос о подлинном ‘понимании’ — действительно ли модель оперирует смыслами, или лишь искусно сопоставляет паттерны? Дальнейшее исследование должно быть направлено на разработку метрик, способных оценить не просто точность ответа, но и глубину осмысления визуальной информации, а также временных связей.
Особый интерес представляет проблема обобщения. Модели, успешно работающие с HD-EPIC, часто демонстрируют существенное снижение производительности при столкновении с незнакомыми сценариями или условиями съемки. Поиск способов повышения робастности и адаптивности, возможно, через использование самообучения или обучения с подкреплением, представляется перспективным направлением. Впрочем, всегда существует риск, что улучшение производительности лишь маскирует более глубокие недостатки в архитектуре или методологии обучения.
Наконец, стоит задуматься о границах применимости подобного подхода. Сможет ли модель, обученная понимать действия человека в повседневной жизни, быть использована для решения более сложных задач, требующих не только визуального восприятия, но и здравого смысла, интуиции и способности к абстрактному мышлению? Пока это остается скорее вопросом философии, чем технической реализации.
Оригинал статьи: https://arxiv.org/pdf/2601.10228.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Искусственный интеллект на службе Земли: новые горизонты моделирования
- Навстречу новым открытиям: Адронные коллайдеры в действии
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
2026-01-18 17:49