Автор: Денис Аветисян
Новый подход позволяет большим языковым моделям более точно следовать инструкциям, используя явное моделирование логики этих инструкций.
Представлен фреймворк LsrIF, объединяющий логическую структуру и обучение с подкреплением для повышения производительности и интерпретируемости моделей, следующих инструкциям.
Несмотря на значительные успехи больших языковых моделей, следование сложным инструкциям, содержащим логические зависимости и условные переходы, остается сложной задачей. В данной работе представлена методика LSRIF: Logic-Structured Reinforcement Learning for Instruction Following, предлагающая новый подход к обучению моделей следованию инструкциям путем явного моделирования логической структуры как в процессе построения данных, так и в разработке системы вознаграждений. Эксперименты демонстрируют, что предложенный фреймворк значительно улучшает способность моделей к следованию инструкциям и общему рассуждению, а также повышает интерпретируемость процесса принятия решений. Позволит ли явное моделирование логики инструкций создавать более надежные и понятные системы искусственного интеллекта?
За гранью последовательной обработки: Необходимость логического следования инструкциям
Современные языковые модели часто демонстрируют трудности при обработке сложных инструкций, требующих логических умозаключений и соблюдения ограничений. Они могут успешно выполнять простые задачи, но сталкиваются с проблемами, когда необходимо учитывать несколько взаимосвязанных условий или последовательно применять правила. Например, при выполнении директивы, включающей одновременно требование отсортировать данные по нескольким критериям и исключить определенные элементы, модели часто допускают ошибки или выдают неполные результаты. Это связано с тем, что существующие архитектуры в основном ориентированы на последовательную обработку информации, что затрудняет эффективное управление сложными логическими связями и поддержание согласованности при выполнении многоступенчатых инструкций. В результате, точность и надежность выполнения сложных задач значительно снижается, что ограничивает возможности применения таких моделей в критически важных областях.
Современные языковые модели зачастую испытывают трудности при обработке сложных инструкций из-за принципиальных ограничений последовательной обработки информации. Традиционный подход, при котором команды выполняются одна за другой, не позволяет эффективно учитывать параллельные зависимости, условные переходы или строгий порядок выполнения, заложенные в инструкции. Например, задача, требующая одновременного выполнения нескольких действий с последующим объединением результатов, или необходимость выполнить определенное действие только при соблюдении конкретных условий, значительно усложняется. Данное ограничение препятствует точному исполнению многокомпонентных директив и снижает эффективность моделей в сценариях, требующих строгого соблюдения логической структуры и взаимосвязей между различными частями инструкции.
Ограничения в способности современных языковых моделей следовать сложным инструкциям напрямую влияют на их эффективность в задачах, требующих точного выполнения многоступенчатых директив. Например, при планировании последовательности действий, где каждый шаг зависит от предыдущего или от соблюдения определенных условий, модели часто допускают ошибки или не могут найти оптимальное решение. Это особенно заметно в сценариях, где необходимо учитывать множество взаимосвязанных ограничений — например, при составлении расписания с учетом доступности ресурсов и приоритетов, или при сборке сложного объекта по инструкции с учетом порядка и совместимости деталей. Неспособность адекватно обрабатывать такие задачи демонстрирует, что простая последовательная обработка информации недостаточна для достижения действительно интеллектуального поведения, и подчеркивает необходимость разработки новых подходов к обучению и архитектуре моделей.
LsrIF: Структурированный подход к улучшению следования инструкциям
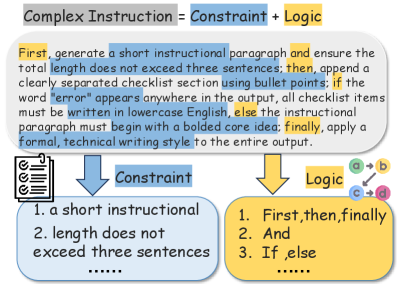
Представляется LsrIF — новая схема обучения, объединяющая создание набора данных и структурированное моделирование вознаграждения. Данная схема предполагает одновременную разработку обучающего набора данных и алгоритма, который оценивает действия модели, принимая во внимание логическую структуру инструкций. Такой подход позволяет более эффективно согласовать поведение модели с намерениями, выраженными в инструкциях, путем явного учета логических связей между их компонентами. В рамках LsrIF, процесс обучения оптимизирован для максимизации вознаграждения, отражающего не только корректность выполнения инструкций, но и соответствие логической последовательности действий заданному формату.
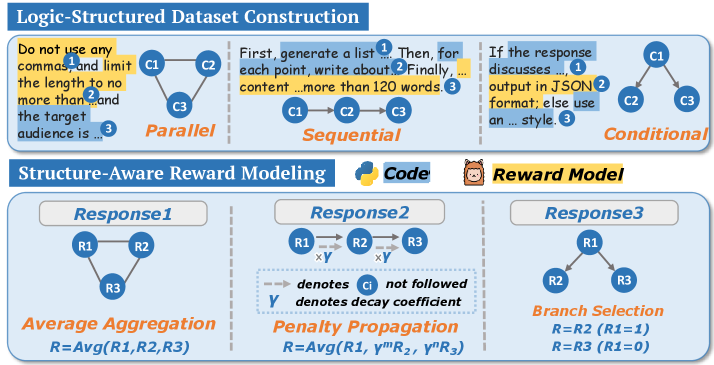
Набор данных LsrInstruct, используемый в рамках LsrIF, содержит инструкции, охватывающие различные логические структуры. Он включает в себя примеры с последовательным (sequential) выполнением задач, параллельным (parallel) выполнением нескольких независимых задач, а также инструкции, требующие условного (conditional) выполнения действий в зависимости от определенных условий. Такое разнообразие позволяет модели обучаться пониманию и следованию инструкциям, содержащим сложные логические зависимости и ветвления, что способствует повышению её способности к решению задач, требующих логического мышления и планирования.
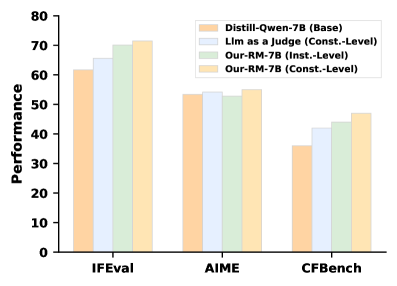
В основе LsrIF лежит разработанная методология структурно-ориентированного моделирования вознаграждения (LsRM), предназначенная для согласования сигналов вознаграждения с логической семантикой инструкций. LsRM анализирует структуру инструкций, выделяя последовательные, параллельные и условные логические блоки, и на основе этого формирует более точные и релевантные сигналы вознаграждения для обучения модели. Результаты показывают, что применение LsRM обеспечивает достижение передовых показателей на бенчмарках IFEval и Enigmata, превосходя существующие подходы к обучению моделей следования инструкциям.
Декомпозиция логических структур: Механизмы вознаграждения для параллельных, последовательных и условных ограничений
Механизм вознаграждений LsRM применяет усредненное агрегирование (Average Aggregation) для параллельных ограничений. Это означает, что при оценке выполнения нескольких параллельных условий, вознаграждение рассчитывается как среднее значение вознаграждений за каждое отдельное условие. Такой подход позволяет системе эффективно оценивать выполнение множества независимых требований, при этом общее вознаграждение отражает среднюю степень их успешного выполнения. Использование усредненного агрегирования упрощает процесс оценки и обеспечивает сбалансированную оценку в случаях, когда требуется выполнить несколько условий одновременно.
При обработке последовательных ограничений в LsRM используется механизм распространения штрафов (Penalty Propagation). Этот метод предполагает снижение вознаграждения не только за нарушение текущего ограничения, но и за ошибки, допущенные на предыдущих шагах последовательности. Таким образом, неудача на ранней стадии последовательности приводит к кумулятивному снижению общей оценки, что стимулирует модель к более аккуратному выполнению каждого этапа и предотвращает распространение ошибок. Данный подход позволяет модели эффективно оценивать и корректировать последовательные рассуждения, повышая общую надежность и точность вывода.
Механизм «Выбор ветви» (Branch Selection) в LsRM предполагает, что вознаграждение за выполнение ограничений в условных структурах присваивается только тем ограничениям, которые находятся в корректной ветви выполнения. Это означает, что если условие выполняется, вознаграждение начисляется только ограничениям, соответствующим этой ветви, а ограничения из невыполненной ветви игнорируются. Такой подход направлен на повышение точности, поскольку система фокусируется на релевантных ограничениях, избегая ложных срабатываний и нерелевантных проверок, что особенно важно для сложных условных конструкций.
Комбинация описанных механизмов вознаграждения — Average Aggregation для параллельных ограничений, Penalty Propagation для последовательных и Branch Selection для условных — в сочетании с LsrIF позволила добиться улучшения до 25.2% в бенчмарке IFEval при использовании модели Qwen2.5-1.5B-Instruct. Данный прирост производительности подтверждает эффективность предложенного подхода к декомпозиции логических структур и оптимизации вознаграждений для улучшения качества генерируемых ответов.

Обучение и оптимизация: Group Relative Policy Optimization для логического следования инструкциям
Обучение фреймворка LsrIF осуществляется с использованием алгоритма обучения с подкреплением Group Relative Policy Optimization (GRPO). GRPO представляет собой метод, оптимизирующий политику агента путем группировки схожих состояний и вычисления относительных преимуществ действий в этих группах. Этот подход позволяет снизить дисперсию оценок и ускорить процесс обучения, особенно в задачах, требующих последовательного принятия решений, таких как следование логическим инструкциям. В рамках LsrIF, GRPO используется для тонкой настройки языковой модели, направленной на генерацию ответов, удовлетворяющих заданным логическим условиям и ограничениям.
Проверка ограничений является критически важным компонентом обучения модели, обеспечивающим соответствие генерируемых ответов заданным условиям и требованиям. Этот процесс включает в себя автоматизированную оценку каждого ответа на предмет соблюдения всех указанных ограничений, таких как формат, длина, наличие определенных ключевых слов или исключение нежелательной информации. Несоблюдение ограничений приводит к штрафным санкциям в процессе обучения с подкреплением, направленным на повышение надежности и точности модели при следовании логическим инструкциям. Эффективная проверка ограничений является необходимым условием для обеспечения корректности и полезности генерируемых ответов, особенно в задачах, где точность и соответствие требованиям имеют первостепенное значение.
Механизмы внимания в рамках LsrIF позволяют модели фокусироваться на наиболее релевантных токенах входной последовательности, что повышает точность генерируемых ответов. Учет важности токенов осуществляется посредством взвешивания, при котором токенам, оказывающим наибольшее влияние на логическое следование инструкциям, присваиваются более высокие веса. Это позволяет модели более эффективно обрабатывать сложные запросы и генерировать ответы, соответствующие заданным ограничениям и логической структуре инструкции, что, в свою очередь, способствует повышению общей производительности системы.
В процессе обучения LsrIF, корректировка параметров модели посредством алгоритма Group Relative Policy Optimization (GRPO) приводит к повышению точности интерпретации и выполнения логических инструкций. Экспериментальные данные демонстрируют, что данная оптимизация обеспечивает прирост производительности до 7.0% на бенчмарке CFBench для модели Qwen2.5-7B-Instruct. Улучшение связано с более эффективной адаптацией весов модели к сложным логическим зависимостям, что позволяет генерировать более корректные и релевантные ответы.

Перспективы: К надёжному и обобщённому логическому мышлению в языковых моделях
Предложенный подход LsrIF закладывает перспективную основу для создания языковых моделей, способных к надёжному и обобщённому логическому мышлению. В отличие от существующих методов, которые часто сталкиваются с трудностями при решении задач, требующих сложных умозаключений, LsrIF демонстрирует потенциал в построении моделей, устойчивых к изменениям в формулировках и способных применять логические принципы к новым, ранее не встречавшимся ситуациям. Данная архитектура позволяет модели не просто запоминать ответы, а овладевать навыками логического анализа, что открывает возможности для решения широкого спектра задач, требующих интеллектуального подхода и точного выполнения инструкций. Подобный прогресс является важным шагом на пути к созданию искусственного интеллекта, способного к действительно глубокому пониманию и эффективному применению логических принципов в реальных условиях.
Дальнейшие исследования направлены на расширение возможностей данной структуры, позволяя ей обрабатывать более сложные логические конструкции и интегрировать внешние знания. Предполагается, что увеличение масштаба и включение разнообразных источников информации значительно повысит способность языковых моделей к рассуждениям, приближая их к уровню человеческого понимания. В частности, планируется разработка методов, позволяющих модели не просто выполнять логические операции, но и применять полученные знания к новым, ранее не встречавшимся задачам, что откроет перспективы для создания действительно интеллектуальных систем, способных к самостоятельному обучению и адаптации.
Исследования продемонстрировали значительный прогресс в области логического мышления языковых моделей. В частности, применение разработанного подхода позволило добиться повышения точности решения арифметических задач Enigmata на 18.0% по сравнению с моделью Distill-Qwen-14B. Данный результат свидетельствует о потенциале новой методики для улучшения способности искусственного интеллекта к решению сложных количественных задач, требующих последовательного применения логических операций и арифметических вычислений. Улучшение производительности на Enigmata указывает на перспективность дальнейшей разработки и оптимизации подхода для повышения общей надежности и обобщающей способности языковых моделей в области логического мышления.
Предложенный подход знаменует собой важный шаг на пути к созданию искусственного интеллекта, способного не просто обрабатывать, но и по-настоящему понимать и выполнять сложные инструкции с логической точностью. Вместо простого сопоставления шаблонов, система стремится к осмыслению взаимосвязей между элементами задачи, что позволяет ей решать проблемы, требующие дедукции и абстрактного мышления. Это открывает перспективы для разработки ИИ, способного к более гибкому и надежному выполнению задач в различных областях, от автоматизированного планирования до анализа сложных научных данных. В перспективе, подобные системы смогут не только отвечать на вопросы, но и объяснять ход своих рассуждений, обеспечивая прозрачность и доверие к принимаемым решениям.
Наблюдатель отмечает, что стремление к совершенству в следовании инструкциям, как это демонстрирует LsrIF, неизбежно сталкивается с суровой реальностью продакшена. Идея явного моделирования логики инструкций, хоть и элегантна, лишь откладывает неизбежное — ведь любое развертывание рано или поздно приведет к сбоям. Как говорил Блез Паскаль: «Все великие дела требуют времени». Здесь же, время лишь добавляет сложности, ведь логическая структура, выстроенная в теории, может быть нарушена непредсказуемыми условиями эксплуатации. Всё, что можно задеплоить — однажды упадёт, но зато красиво умирает, в попытке следовать заданной логике.
Куда же мы катимся?
Представленный подход, безусловно, добавляет ещё один уровень сложности в и без того запутанный процесс обучения больших языковых моделей. Логическая структуризация инструкций — идея, конечно, привлекательная, но не стоит забывать, что в реальном мире инструкции редко бывают логичными. Скорее, это хаотичные запросы, сформулированные пользователями, которые, вероятно, не читали ни одного учебника по логике. Если система стабильно падает при попытке интерпретировать их, значит, она хотя бы последовательна.
В перспективе, вероятно, нас ждёт гонка вооружений между всё более сложными методами моделирования инструкций и всё более изощрёнными способами их намеренного искажения. “Облачные” решения, конечно, облегчат масштабирование, но это всё тот же самый код, только дороже. И, честно говоря, не стоит обольщаться насчёт интерпретируемости. Мы не пишем код — мы просто оставляем комментарии будущим археологам, которые будут пытаться понять, что мы вообще имели в виду.
В конечном счёте, задача сводится не к созданию идеально логичных систем, а к разработке достаточно надёжных, чтобы справляться с хаосом. Или, по крайней мере, падать предсказуемо. Надежды на “искусственный интеллект” остаются, как обычно, на уровне энтузиазма. Вероятно, через десять лет появятся новые “революционные” подходы, которые потребуют ещё больше вычислительных ресурсов и, конечно же, создадут новый техдолг.
Оригинал статьи: https://arxiv.org/pdf/2601.06431.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Искусственный интеллект на службе Земли: новые горизонты моделирования
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Динамика в кадре: Как научить ИИ понимать физику видео
2026-01-18 19:12