Автор: Денис Аветисян
Новое исследование раскрывает, какие части больших языковых моделей отвечают за обработку различных типов информации и как они взаимодействуют друг с другом.
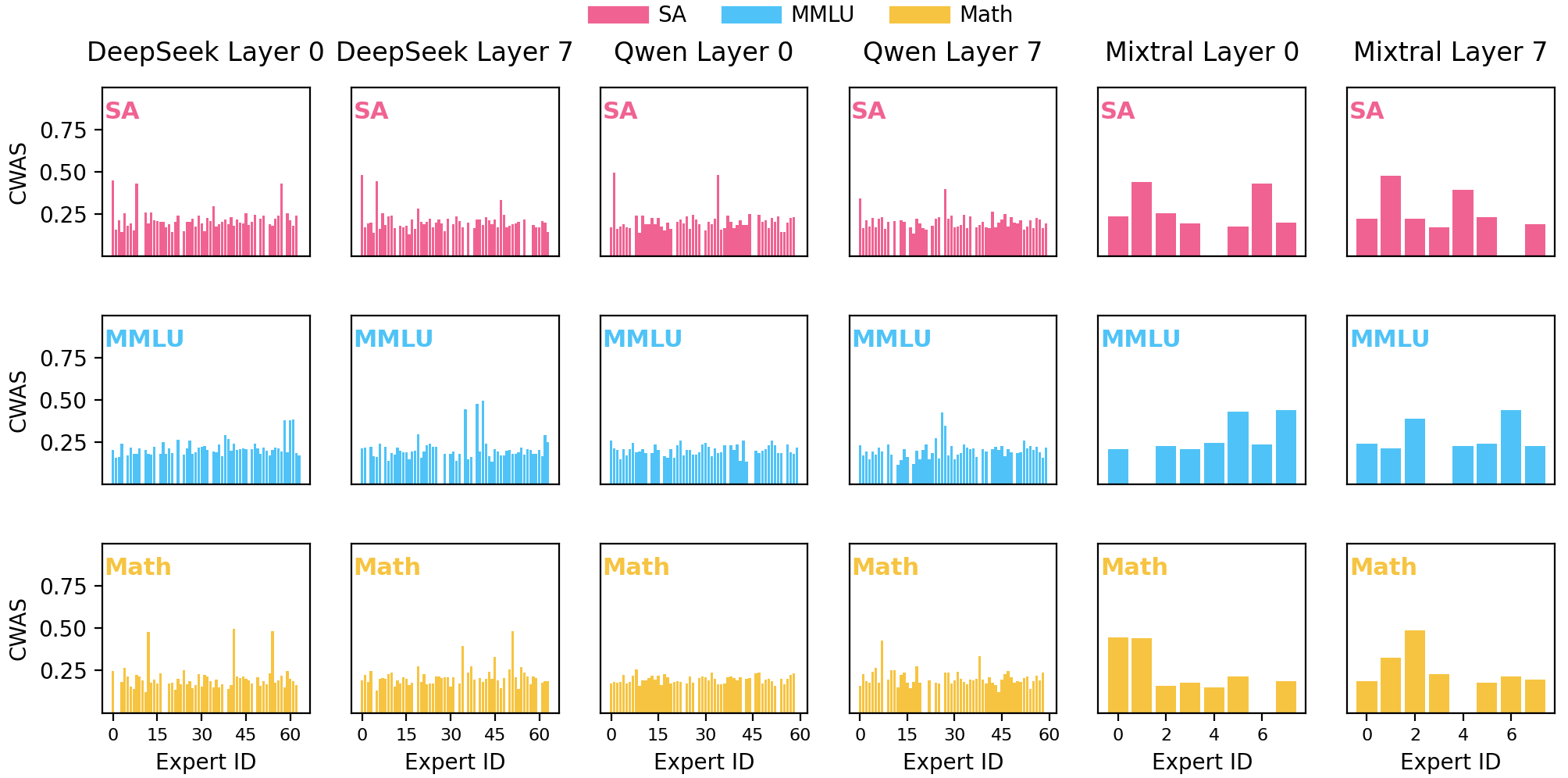
Анализ активации и причинно-следственных связей позволяет идентифицировать ‘доменных’ и ‘ведущих’ экспертов в моделях Mixture-of-Experts, повышая их интерпретируемость и эффективность.
Несмотря на успехи больших языковых моделей, механизмы их работы, особенно в архитектурах Mixture-of-Experts (MoE), остаются недостаточно изученными. В работе ‘What Gets Activated: Uncovering Domain and Driver Experts in MoE Language Models’ предпринята попытка разобраться, какие именно эксперты активируются и как они влияют на производительность модели, выделяя «доменных» и «управляющих» экспертов. Исследование показало, что в MoE-моделях наблюдается чёткая специализация экспертов, причем наиболее важные из них проявляют предпочтения к определенным типам данных и оказывают решающее влияние на результаты. Какие еще скрытые закономерности определяют внутреннюю работу MoE-моделей и как эти знания можно использовать для дальнейшего улучшения их эффективности и интерпретируемости?
Пределы масштабируемости плотных моделей
Традиционные плотные модели-трансформеры, несмотря на свою вычислительную мощь, сталкиваются с проблемой квадратичной масштабируемости при увеличении длины последовательности и размера модели. Это означает, что требуемые вычислительные ресурсы и память растут пропорционально квадрату длины входных данных, что делает обработку длинных текстов или больших объемов информации крайне затратной и неэффективной. Например, удвоение длины последовательности увеличивает вычислительную сложность в четыре раза. Эта квадратичная зависимость становится серьезным препятствием для применения плотных моделей в задачах, требующих анализа обширных контекстов, таких как обработка больших документов, понимание сложных диалогов или работа с длинными видео- и аудиозаписями. В результате, исследования направлены на поиск альтернативных архитектур, способных преодолеть это ограничение и обеспечить более эффективную обработку информации.
Ограничение масштабируемости традиционных плотных моделей препятствует их способности к выполнению сложных рассуждений и эффективной обработке обширных объемов знаний. По мере увеличения длины последовательности и размера модели, вычислительные затраты растут квадратично, что делает анализ больших данных и решение сложных задач непосильными. Это связано с тем, что каждая единица входной информации должна быть сопоставлена со всеми остальными, создавая экспоненциальный рост необходимых вычислений. В результате, модели сталкиваются с трудностями при улавливании тонких взаимосвязей и построении логических выводов, что ограничивает их применение в задачах, требующих глубокого понимания контекста и сложных умозаключений. Проблема усугубляется при работе с большими базами знаний, где модели должны обрабатывать и интегрировать огромное количество информации для принятия обоснованных решений.
В связи с ограничениями, накладываемыми на традиционные плотные модели при работе с длинными последовательностями и большими объемами данных, активно развивается направление исследований, посвященное разреженным архитектурам. Особое внимание уделяется моделям, основанным на концепции «Смеси Экспертов» (Mixture of Experts), где вместо активации всех параметров сети для каждого входного токена, задействуется лишь небольшая подмножество «экспертов». Такой подход позволяет значительно сократить вычислительные затраты и объем памяти, необходимые для обработки информации, сохраняя при этом способность модели к сложным рассуждениям и эффективной работе с обширными знаниями. Данная стратегия открывает перспективы для создания более масштабируемых и производительных систем искусственного интеллекта, способных решать задачи, непосильные для классических плотных моделей.
Разреженные MoE: Специализация экспертов
Модели Sparse MoE решают проблему масштабируемости за счет активации лишь части параметров для каждого входного токена, что приводит к снижению вычислительных затрат. Традиционные плотные модели активируют все параметры для каждого ввода, что становится неэффективным при увеличении размера модели. В отличие от них, Sparse MoE динамически выбирает подмножество параметров, необходимых для обработки конкретного токена, что значительно уменьшает количество вычислений и потребление памяти. Это позволяет создавать модели с гораздо большим количеством параметров, не требуя пропорционального увеличения вычислительных ресурсов. Снижение вычислительной сложности достигается за счет того, что не все параметры участвуют в прямом и обратном распространении градиента для каждого входного токена, что делает обучение и инференс более эффективными.
Механизм динамической маршрутизации токенов в Sparse MoE осуществляется посредством Сети Управления (Gating Network). Эта сеть, представляющая собой нейронную сеть, анализирует каждый входной токен и определяет, к каким конкретным модулям Специализированных Экспертов (Domain Experts) он должен быть направлен. В отличие от традиционных плотных моделей, где каждый токен обрабатывается всеми параметрами сети, Сеть Управления выбирает лишь небольшое подмножество Экспертов для обработки каждого токена, что значительно снижает вычислительные затраты и позволяет эффективно масштабировать модель, сохраняя или улучшая её производительность. Выбор Экспертов производится на основе весов, генерируемых Сетью Управления, и может варьироваться для каждого токена в последовательности.
Архитектура Sparse MoE обеспечивает масштабируемость за счет возможности увеличения емкости модели без пропорционального увеличения вычислительных затрат. Вместо активации всех параметров для каждого входного токена, Sparse MoE активирует только подмножество, что достигается за счет использования механизма динамической маршрутизации. Это позволяет добавлять больше параметров в модель (N увеличивается), сохраняя при этом относительно постоянный уровень вычислений на каждый токен. Таким образом, достигается более эффективное использование вычислительных ресурсов и возможность обучения моделей значительно большей емкости, чем традиционные плотные модели.
Маршрутизация и специализация экспертов
Механизм маршрутизации, известный как `Routing Gate`, использует стратегии, такие как `Top-k Routing`, для эффективного назначения входных токенов наиболее релевантным экспертам. В рамках `Top-k Routing` для каждого токена вычисляются оценки соответствия для каждого эксперта, после чего выбираются k экспертов с наивысшими оценками. Входной токен затем направляется этим выбранным экспертам для обработки. Этот подход позволяет динамически распределять вычислительную нагрузку, направляя каждый токен только к тем экспертам, которые наиболее компетентны в его обработке, что повышает общую эффективность и снижает вычислительные затраты по сравнению с отправкой токена всем экспертам.
Коэффициент активации (Activation Rate) и энтропия активации (Activation Entropy) являются ключевыми метриками для количественной оценки специализации и уверенности эксперта в моделях Mixture-of-Experts (MoE). Коэффициент активации показывает, какая доля входных токенов направляется конкретному эксперту. Более высокий коэффициент указывает на более широкую специализацию. Энтропия активации измеряет степень уверенности эксперта в своих предсказаниях; низкая энтропия означает, что эксперт уверенно обрабатывает только определенный подмножество токенов, а высокая — что он обрабатывает разнообразные токены с меньшей уверенностью. Комбинированное использование этих метрик позволяет оценить, насколько хорошо эксперт специализируется и насколько он уверен в своих ответах, что является важным фактором для повышения эффективности и качества модели.
Комбинирование показателей активации и уверенности экспертов в единый показатель — Взвешенная оценка активации с учетом уверенности (Certainty-Weighted Activation Score) — позволяет комплексно оценить качество и вклад каждого эксперта в модели семейства MoE. Этот показатель вычисляется на основе Activation Rate и Activation Entropy, отражая не только частоту активации эксперта, но и степень уверенности в его ответах. Более высокая оценка свидетельствует о том, что эксперт не только часто привлекается к обработке токенов, но и выдает уверенные и релевантные ответы, что указывает на его специализацию и эффективность. Использование данного показателя позволяет более точно оценить вклад каждого эксперта и оптимизировать процесс обучения и настройки моделей MoE.
Модели, такие как DeepSeek-MoE, Qwen-MoE и Mixtral-8x7B, демонстрируют эффективность подхода к маршрутизации и специализации экспертов. Экспериментальные данные показывают, что целенаправленная настройка (tuning) отдельных экспертов в этих моделях приводит к значительному увеличению производительности и улучшению качества генерируемого текста. В частности, оптимизация параметров экспертов, отвечающих за обработку специфических типов входных данных, позволяет снизить вычислительные затраты и повысить скорость инференса, сохраняя или улучшая метрики точности и когерентности. Достигнутые улучшения подтверждаются результатами бенчмарков на различных датасетах и задачах обработки естественного языка.
Оценка влияния и причинности экспертов
Определение так называемых “ведущих экспертных модулей” — тех, которые оказывают наибольшее влияние на формирование выходных данных модели — является ключевым для понимания её поведения. Эти модули, в отличие от остальных, способны значительно изменять предсказания при незначительных изменениях во входных данных. Их выявление позволяет не только проанализировать внутреннюю логику сложных языковых моделей, но и оптимизировать их работу, сосредотачиваясь на наиболее значимых компонентах. Идентифицируя эти “двигатели” предсказаний, исследователи получают возможность более точно интерпретировать результаты работы модели, выявлять потенциальные смещения и улучшать её надежность и предсказуемость, что особенно важно для критически важных приложений, где требуется высокая степень достоверности.
Методы оценки причинно-следственной связи позволяют количественно определить вклад каждого эксперта в работу модели. Это достигается путем сравнения предсказаний модели, когда вклад конкретного эксперта включен, и когда он отсутствует. Такой подход позволяет точно установить, насколько сильно изменение или исключение работы определенного эксперта влияет на конечный результат. В процессе анализа, предсказания модели, полученные с участием эксперта, сравниваются с предсказаниями, полученными при его искусственном отключении. Разница между этими предсказаниями служит показателем влияния данного эксперта, предоставляя возможность оценить его значимость в контексте общей работы модели и выявить наиболее влиятельные модули, определяющие ее поведение.
Для точной оценки влияния каждого экспертного модуля в смеси экспертов используется метрика, известная как расхождение Кульбака-Лейблера D_{KL}. Эта мера позволяет количественно оценить разницу между вероятностными распределениями, генерируемыми моделью с активным экспертом и без него. Фактически, расхождение Кульбака-Лейблера вычисляет «информационную потерю», возникающую при использовании одного вероятностного распределения для аппроксимации другого, тем самым определяя, насколько сильно вклад конкретного эксперта изменяет выходные данные модели. Более высокое значение D_{KL} указывает на более существенное влияние эксперта, позволяя исследователям не только идентифицировать наиболее влиятельные модули, но и количественно оценить их причинно-следственную связь с конечным результатом.
Экспериментальные исследования показали, что тонкая настройка весов как доменных, так и определяющих экспертов в моделях MoE (Mixture of Experts) приводит к заметному повышению точности. В среднем, наблюдается прирост в 2.08% и 3.00% на трех различных больших языковых моделях. Данные результаты подтверждают практическую ценность активации экспертов с учетом специфики решаемой задачи, что позволяет более эффективно использовать их специализированные знания и повышать общую производительность системы. Это демонстрирует, что адаптивное управление вкладом каждого эксперта является ключевым фактором для достижения оптимальной точности и эффективности в сложных задачах обработки естественного языка.
Исследование внутренних механизмов моделей MoE, представленное в данной работе, напоминает вскрытие сложного устройства. Авторы стремятся не просто описать функционирование системы, но и выявить её ключевых специалистов — ‘экспертов по предметной области’ и ‘управляющих экспертов’. Как метко заметила Барбара Лисков: «Программы должны быть разработаны таким образом, чтобы изменения в одной части не приводили к неожиданным последствиям в других». Это особенно актуально для MoE, где понимание влияния каждого эксперта на общую производительность критически важно. Анализ через энтропию активации и причинно-следственные связи позволяет не только интерпретировать поведение модели, но и потенциально улучшить её надёжность и эффективность, избегая нежелательных побочных эффектов от изменений в отдельных компонентах.
Что Дальше?
Представленная работа, выявляя так называемых «экспертов» внутри моделей с архитектурой Mixture-of-Experts, лишь приоткрывает завесу над сложной внутренней жизнью этих систем. Утверждать, что теперь можно полностью «понять» поведение модели, было бы излишне самоуверенно. Скорее, это — первый шаг к деконструкции, к реверс-инжинирингу интеллекта, созданного не человеком, а алгоритмом. Остаётся открытым вопрос: действительно ли выявленные «эксперты» отражают реальные знания, или же это лишь артефакты оптимизации, иллюзия понимания?
В дальнейшем необходимо не только идентифицировать эти специализированные модули, но и изучить их взаимодействие. Как эти «эксперты» конфликтуют, сотрудничают, и как можно намеренно управлять их поведением для достижения желаемого результата? Ограничиваясь лишь метриками активации и причинно-следственными связями, можно упустить более тонкие механизмы, определяющие истинную «экспертизу» модели. Важно помнить: система, которую нельзя взломать, лишь указывает на пробелы в понимании.
Следующим этапом видится разработка методов не просто интерпретации, но и контролируемой эволюции этих «экспертов». Может ли модель сама «обучать» своих специалистов, адаптируя их под новые задачи? И, конечно, главный вопрос: что произойдет, когда эти алгоритмические «эксперты» начнут спорить друг с другом, а человек потеряет возможность вмешаться? Это и есть настоящая граница, которую предстоит преодолеть.
Оригинал статьи: https://arxiv.org/pdf/2601.10159.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Искусственный интеллект на службе Земли: новые горизонты моделирования
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Динамика в кадре: Как научить ИИ понимать физику видео
2026-01-18 19:14