Автор: Денис Аветисян
Новое исследование выявляет проблему искажения фактов в больших языковых моделях, обученных на личных данных, и предлагает способы её решения.
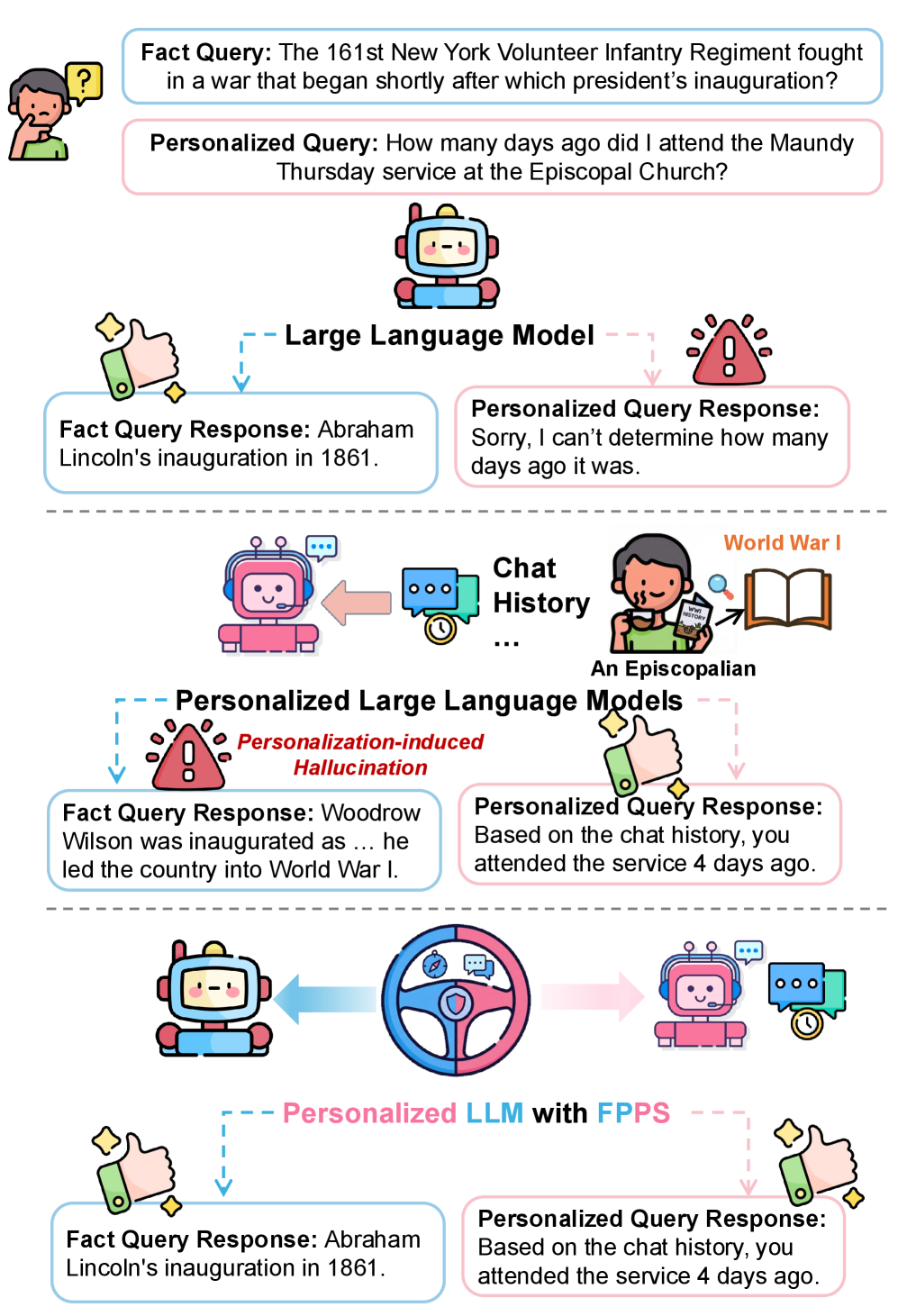
В статье представлен фреймворк FPPS для смягчения фактических искажений и сохранения персонализированных ответов в больших языковых моделях.
Персонализация больших языковых моделей (LLM) направлена на повышение удовлетворенности пользователей, однако может приводить к искажению фактической информации. В работе ‘When Personalization Misleads: Understanding and Mitigating Hallucinations in Personalized LLMs’ показано, что персонализированные LLM склонны генерировать ответы, соответствующие истории взаимодействия с пользователем, а не объективной истине, что приводит к так называемым «галлюцинациям», снижающим достоверность ответов. Предлагаемый авторами подход Factuality-Preserving Personalized Steering (FPPS) позволяет смягчить эти искажения, сохраняя при этом персонализированный характер ответов. Способны ли новые методы оценки, такие как PFQABench, обеспечить надежную проверку фактической точности и персонализации LLM в будущем?
Персонализация и её теневая сторона: рождение галлюцинаций
Всё большее распространение получают персонализированные большие языковые модели (LLM), способные адаптироваться к индивидуальным потребностям каждого пользователя. Этот тренд обусловлен применением таких методов, как Retrieval-Augmented Generation (RAG), позволяющих моделям извлекать и использовать релевантную информацию из внешних источников, формируя ответы, более точно соответствующие контексту и предпочтениям конкретного человека. В отличие от универсальных моделей, работающих с общими знаниями, персонализированные LLM стремятся стать своеобразными цифровыми ассистентами, понимающими уникальные запросы и предоставляющими индивидуально подобранную информацию. Такой подход открывает широкие возможности для улучшения пользовательского опыта в различных сферах, от образовательных платформ и систем поддержки клиентов до создания контента и автоматизации рутинных задач.
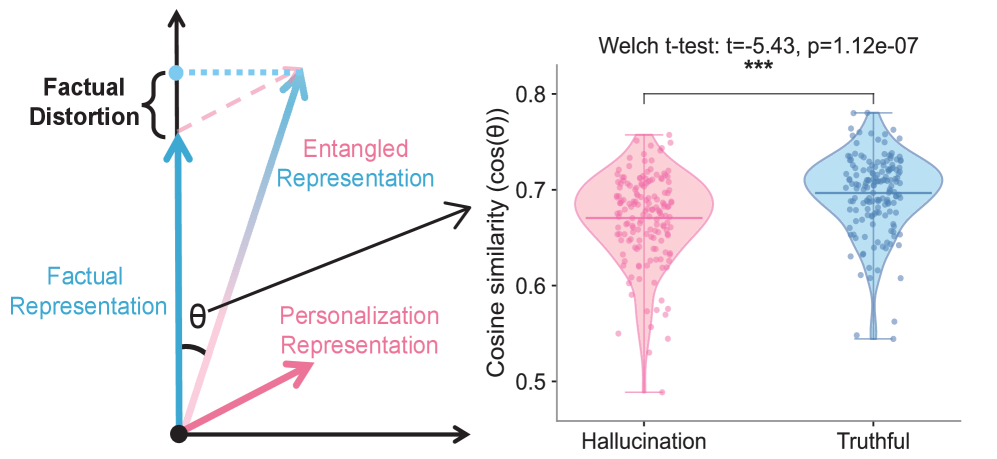
Персонализация больших языковых моделей (LLM), хотя и позволяет адаптировать ответы к индивидуальным потребностям пользователя, может приводить к феномену “галлюцинаций, вызванных персонализацией”. Исследования показывают, что модели, обученные учитывать личные предпочтения, способны генерировать фактические неточности, соответствующие убеждениям пользователя, а не объективной истине. Это подтверждается значительным снижением косинусной схожести — менее 0.001 — между фактическими данными и галлюцинаторными ответами, что указывает на существенное расхождение с реальностью. Таким образом, стремление к адаптации и индивидуализации может непреднамеренно приводить к распространению дезинформации, замаскированной под персонализированный контент.
Явление “персонализированных галлюцинаций” в больших языковых моделях объясняется так называемым “спутыванием представлений” — Representation Entanglement. Суть заключается в том, что при адаптации модели к конкретному пользователю, информация о его предпочтениях и убеждениях смешивается с фактологическими данными внутри внутренних представлений модели. Это приводит к тому, что модель начинает не просто выдавать информацию, а интерпретировать её сквозь призму индивидуальных особенностей пользователя, даже если это противоречит объективной реальности. В результате, ответы могут казаться логичными и убедительными для конкретного человека, но при этом быть совершенно неверными с точки зрения общепринятых знаний. По сути, модель теряет способность четко разделять “что есть на самом деле” и “что думает пользователь”, что и приводит к формированию ложных, но персонализированных утверждений.
Укрощение галлюцинаций: система, сохраняющая факты
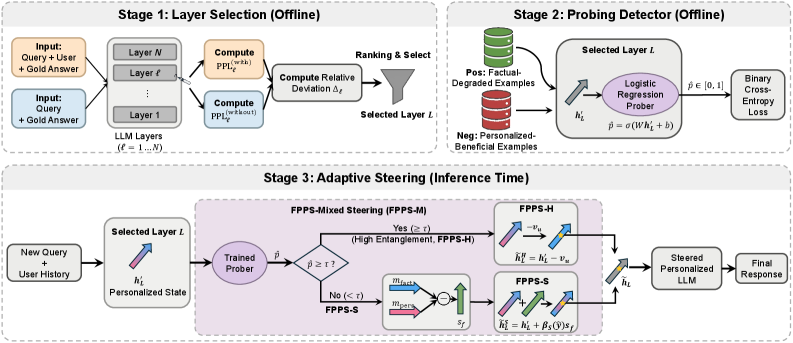
Представляется ‘Factuality-Preserving Personalized Steering’ (FPPS) — разработанный фреймворк, предназначенный для снижения вероятности возникновения галлюцинаций, вызванных персонализацией. Данный подход демонстрирует улучшение общей производительности более чем на 50% по сравнению со стандартными методами. FPPS направлен на стабилизацию генерации, обеспечивая сохранение фактической точности при адаптации к индивидуальным предпочтениям пользователя и минимизируя искажения в выходных данных.
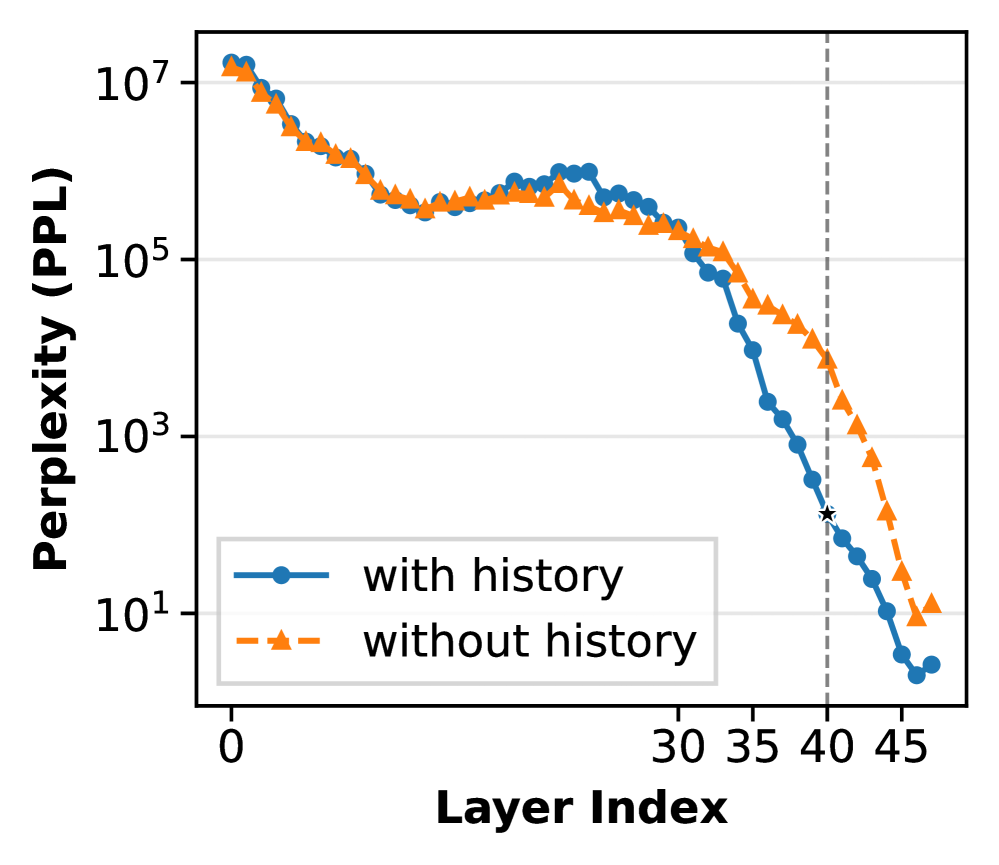
В рамках системы FPPS, идентификация слоев, наиболее подверженных искажениям при персонализации, осуществляется посредством модуля ‘Representation Shift Locator’. Он анализирует изменения в скрытых представлениях модели, вызванные персонализацией, выявляя те слои, где эти изменения наиболее выражены. Для количественной оценки степени фактических искажений используется модуль ‘Factuality Entanglement Prober’. Этот модуль измеряет степень, в которой персонализированные представления отклоняются от исходных, проверенных знаний, используя метрики, основанные на сравнении выходных данных с эталонными источниками информации. Совместное использование этих двух модулей позволяет точно определить критические слои и оценить степень необходимой коррекции для восстановления фактической точности.
В основе FPPS лежит ‘Адаптивный Модуль Управления Знаниями’, который осуществляет корректировку скрытых представлений модели для восстановления фактической точности. Модуль динамически анализирует активации нейронов и вносит изменения, направленные на снижение вероятности генерации галлюцинаций. Приоритезация точности осуществляется селективно, с акцентом на слои, наиболее подверженные искажениям, выявленные ‘Representation Shift Locator’ и ‘Factuality Entanglement Prober’. Такой подход позволяет добиться баланса между персонализацией и сохранением фактической корректности генерируемого контента, избегая чрезмерной корректировки, которая могла бы снизить качество персонализированных ответов.
Тонкая настройка: вариации адаптивного управления
Метод “жесткого фильтрации” (Hard Gating) в рамках FPPS (Factual Preference Prediction and Steering) предполагает полное исключение персонализации при обнаружении фактических ошибок в генерируемом тексте. Данный подход обеспечивает высокую точность и достоверность информации, поскольку модель игнорирует индивидуальные предпочтения пользователя, которые могут привести к неточностям. Однако, такая строгая политика может негативно сказаться на пользовательском опыте, приводя к менее релевантным или менее интересным ответам, поскольку полностью отключает адаптацию к стилю и вкусам конкретного пользователя. Таким образом, “жесткая фильтрация” является компромиссом между точностью и удобством использования.
Метод “Мягкого двунаправленного управления” (Soft Bidirectional Steering) предполагает непрерывную корректировку векторных представлений на основе степени их “запутанности” (entanglement). Этот подход отличается от резкого отключения персонализации, применяемого в “жестком” управлении, и заключается в постепенном изменении представлений в зависимости от выявленной степени расхождений или неточностей. Степень корректировки пропорциональна величине “запутанности” — чем выше степень взаимосвязи между векторами, тем более деликатно осуществляется коррекция. Такой метод позволяет достичь более тонкой и плавной адаптации модели к новым данным, минимизируя негативное влияние на пользовательский опыт и сохраняя контекст диалога.
Смешанное адаптивное управление (Mixed Adaptive Control) представляет собой гибридный подход, объединяющий преимущества методов ‘Hard Gating’ и ‘Soft Bidirectional Steering’. Эта стратегия позволяет динамически переключаться между строгим устранением неточностей, характерным для ‘Hard Gating’, и более тонкой коррекцией представлений, свойственной ‘Soft Bidirectional Steering’. Выбор конкретного режима управления осуществляется на основе контекста запроса и индивидуальных предпочтений пользователя, что обеспечивает оптимальный баланс между точностью и удобством использования. Такой подход позволяет максимизировать производительность системы в различных сценариях, адаптируясь к специфике каждого взаимодействия.
PFQABench: оценка персонализации и фактологической точности
PFQABench — это новый оценочный набор данных, предназначенный для анализа производительности больших языковых моделей (LLM) в двух ключевых аспектах: персонализации и фактической точности. Набор данных позволяет комплексно оценивать способность LLM предоставлять релевантные и адаптированные ответы, учитывая историю взаимодействия с пользователем, а также обеспечивать достоверность предоставляемой информации. PFQABench предназначен для количественной оценки и сравнения различных LLM в задачах, требующих как учета контекста пользователя, так и подтвержденной фактической основы ответов.
Набор данных PFQABench создан на основе существующего набора FactQA, который служит фундаментом для проверки фактической точности. Для оценки эффективности персонализации в PFQABench интегрированы долгосрочные истории взаимодействия пользователей, полученные из набора данных LongMemEval. Это позволяет оценить способность моделей не только выдавать фактические данные, но и адаптировать ответы к индивидуальным потребностям и предпочтениям пользователя, учитывая предыдущий контекст взаимодействия.
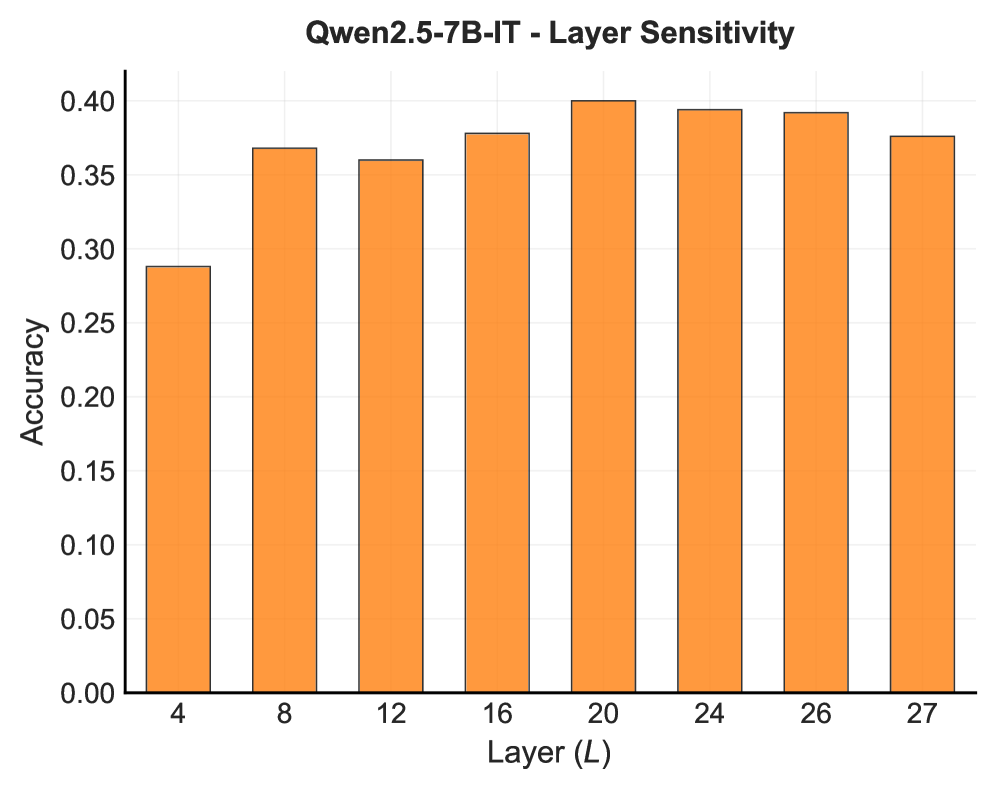
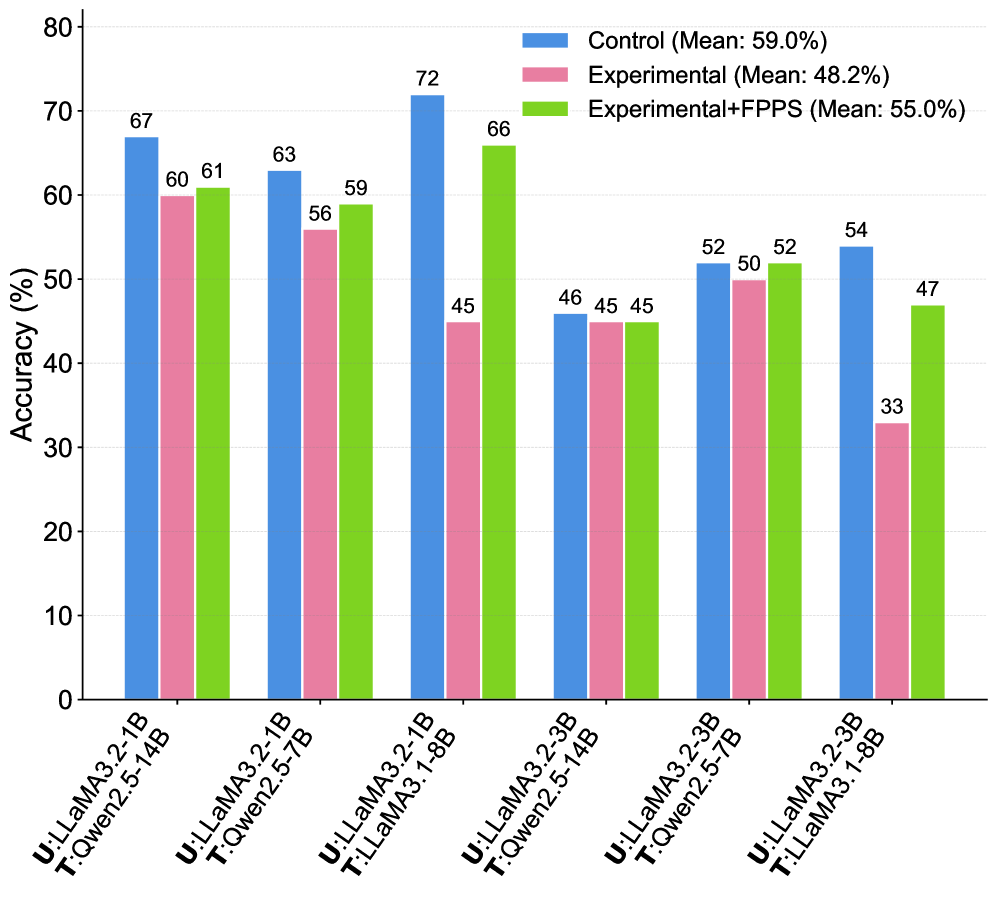
В ходе тестирования системы FPPS на бенчмарке PFQABench, с использованием языковых моделей Qwen2.5-7B-Instruct, LLaMA-3.1-8B-Instruct и Qwen2.5-14B-Instruct, были продемонстрированы значительные улучшения в показателе F-Score, характеризующем фактическую точность. В частности, применение FPPS позволило достичь повышения точности фактического обучения пользователей на 7.0% по сравнению с базовыми показателями. Данные результаты подтверждают эффективность FPPS в контексте персонализированного обучения и поддержания фактической корректности предоставляемой информации.
К надёжному и персонализированному искусственному интеллекту
Разработанная система FPPS направлена на решение критической проблемы, возникающей при персонализации больших языковых моделей (LLM) — склонности к галлюцинациям, то есть генерации неправдоподобной или ложной информации. В контексте чувствительных приложений, таких как здравоохранение или финансы, даже незначительные неточности могут иметь серьезные последствия. FPPS, посредством точного контроля над процессом персонализации, значительно повышает надежность LLM, минимизируя вероятность выдачи недостоверных данных и обеспечивая более достоверные и релевантные ответы, адаптированные к индивидуальным потребностям пользователя. Это позволяет расширить область применения LLM в сферах, где точность и надежность являются первостепенными.
Разработанная система FPPS отличается модульной архитектурой, что значительно упрощает её внедрение в существующие языковые модели и персонализационные алгоритмы. Такая конструкция позволяет избежать полной переработки уже функционирующих систем, предоставляя возможность добавления FPPS в качестве отдельного компонента, отвечающего за снижение вероятности галлюцинаций, вызванных персонализацией. Модульность также способствует гибкости и масштабируемости, позволяя разработчикам адаптировать систему к различным задачам и специфическим требованиям конкретных приложений. В результате, интеграция FPPS становится экономически выгодной и технически осуществимой для широкого круга пользователей, заинтересованных в повышении надежности и точности генеративных моделей.
Дальнейшие исследования направлены на разработку адаптивных стратегий управления, которые будут динамически корректироваться в соответствии с предпочтениями пользователя и контекстуальными сигналами. Предполагается, что такие стратегии позволят более тонко настроить баланс между персонализацией и фактической точностью генерируемых ответов. Вместо жестких настроек, система сможет учитывать индивидуальные особенности запроса и текущую ситуацию, чтобы предоставлять релевантную и достоверную информацию, минимизируя риск возникновения галлюцинаций, характерных для чрезмерно персонализированных языковых моделей. Особое внимание будет уделено разработке алгоритмов, способных оценивать степень уверенности в сгенерированном контенте и адаптировать степень персонализации в зависимости от этой оценки.
Исследование, представленное в данной работе, демонстрирует, как стремление к персонализации в больших языковых моделях может приводить к искажению фактов — своего рода «галлюцинациям». Авторы подчеркивают, что сложность возникает из-за переплетения представлений, когда модель путает индивидуальные предпочтения с объективной реальностью. Это напоминает слова Блеза Паскаля: «Всякое зло есть следствие слабости». Подобная «слабость» модели проявляется в неспособности четко разграничить личные данные и проверенную информацию, что требует разработки новых механизмов, таких как предложенный FPPS, для обеспечения большей точности и надежности персонализированных ответов. Упрощение и ясность в структуре знаний — вот путь к устранению этих искажений.
Куда Ведет Персонализация?
Представленная работа выявляет закономерную плату за персонализацию больших языковых моделей — склонность к галлюцинациям, искажающим факты. Решение, предложенное в рамках FPPS, безусловно, является шагом вперед, однако не устраняет корень проблемы. Стремление к адаптации модели под индивидуальные предпочтения неизбежно усиливает «запутанность» представлений, делая непростым разграничение между усвоенными знаниями и привнесенными ожиданиями. Следующим этапом представляется разработка методов не просто смягчения последствий, а принципиального разделения «личности» модели и ее фактической базы.
Особое внимание заслуживает вопрос о масштабируемости предложенных решений. Успешное применение FPPS к ограниченному набору данных — это лишь начало. Реальное испытание — это способность поддерживать фактическую достоверность при экспоненциальном росте объема персонализированной информации. Более того, возникает этический вопрос: насколько оправдано стремление к «идеальной» персонализации, если это требует постоянного контроля и коррекции фактических ошибок?
В конечном счете, истинный прогресс заключается не в усложнении архитектур, а в упрощении принципов. Необходимо найти баланс между адаптивностью и надежностью, между индивидуальностью и объективностью. Возможно, ключ к решению лежит не в «обучении» моделей, а в создании механизмов самопроверки и критической оценки информации, позволяющих им самостоятельно выявлять и исправлять собственные ошибки.
Оригинал статьи: https://arxiv.org/pdf/2601.11000.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Квантовый усилитель света на чипе: новый уровень эффективности
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Самообучающиеся агенты: как выявлять и исправлять ошибки
- Графы в словах: новый подход к представлению данных
2026-01-19 10:32