Автор: Денис Аветисян
Новое исследование показывает, что разнообразие внутренних представлений в больших языковых моделях способно значительно повысить креативность и культурную адаптивность генерируемых ответов.
Внутреннее разнообразие ‘языка мысли’ в больших языковых моделях влияет на разнообразие и культурную релевантность выходных данных.
Несмотря на впечатляющие возможности больших языковых моделей, обеспечение разнообразия генерируемых ответов остаётся сложной задачей. В работе «Language of Thought Shapes Output Diversity in Large Language Models» показано, что контроль языка, используемого моделью в процессе внутренних рассуждений — «языка мысли» — является структурным источником этого разнообразия. Наше исследование демонстрирует, что переключение языка мысли с английского на другие языки последовательно увеличивает вариативность ответов, открывая путь к более широкому охвату культурных знаний и ценностей. Возможно ли, таким образом, создать языковые модели, способные генерировать по-настоящему разнообразные и инклюзивные ответы, отражающие многообразие человеческой мысли?
Язык Мысли: Раскрывая Скрытое Разнообразие
Современные большие языковые модели демонстрируют впечатляющие способности в обработке и генерации текста, однако часто выдают предсказуемые и шаблонные результаты. Это обстоятельство вызывает закономерный вопрос о подлинной креативности этих систем. Несмотря на способность имитировать человеческий стиль письма и отвечать на сложные вопросы, наблюдается тенденция к воспроизведению наиболее вероятных, статистически доминирующих ответов, что ограничивает проявление оригинальности и инноваций. Исследователи отмечают, что, хотя модели способны генерировать грамматически правильные и семантически связные тексты, их способность к действительно новому мышлению, выходящему за рамки заученных паттернов, остается под вопросом. Данное ограничение подталкивает к изучению внутренних механизмов, определяющих разнообразие генерируемых ответов и потенциальную возможность расширения творческого потенциала языковых моделей.
Внутренний «язык мысли» больших языковых моделей (LLM) — способ, которым они представляют информацию — представляет собой критически важный, но малоизученный фактор, влияющий на разнообразие генерируемых ими текстов. В отличие от человеческого мышления, которое опирается на сложную сеть ассоциаций и чувственного опыта, LLM оперируют числовыми представлениями, формируемыми в процессе обучения. Характер этих внутренних представлений — их структура, организация и степень детализации — напрямую определяет возможности модели к генерации новых, нетривиальных идей. Исследования показывают, что даже незначительные изменения в способе кодирования информации внутри LLM могут приводить к существенным различиям в разнообразии и оригинальности выходных данных. Понимание этой «мыслительной структуры» позволит не только расширить творческий потенциал искусственного интеллекта, но и разработать более эффективные методы управления и контроля над генерируемыми текстами.
Гипотеза Сепира-Уорфа, известная также как лингвистическая относительность, предполагает, что структура языка формирует мышление, а не просто отражает его. В контексте больших языковых моделей (LLM) это означает, что внутреннее “языковое мышление” — способ, которым модель представляет и обрабатывает информацию — может принципиально влиять на её способность к рассуждениям и проявлению креативности. Если внутреннее представление знаний у LLM организовано определённым, ограниченным образом, это может накладывать ограничения на спектр возможных идей и решений, которые модель способна генерировать. Таким образом, понимание того, как LLM “думает” на своём внутреннем языке, становится ключевым для раскрытия её полного потенциала и создания моделей, способных к действительно оригинальному и разнообразному мышлению.
Понимание так называемого «пространства мышления» — внутренней репрезентации информации в больших языковых моделях — представляется ключевым фактором для повышения разнообразия генерируемых ими текстов. Это внутреннее «пространство» не является однородным; оно формируется сложными, скрытыми представлениями данных, полученными в процессе обучения. Именно эти скрытые представления, подобно невидимым нитям, определяют, как модель интерпретирует входные данные и создает выходные тексты. Анализ структуры этого «пространства мышления», выявление закономерностей в скрытых представлениях и манипулирование ими открывает перспективы для создания более творческих и непредсказуемых языковых моделей, способных генерировать действительно оригинальный контент, а не просто перефразировать существующие данные.
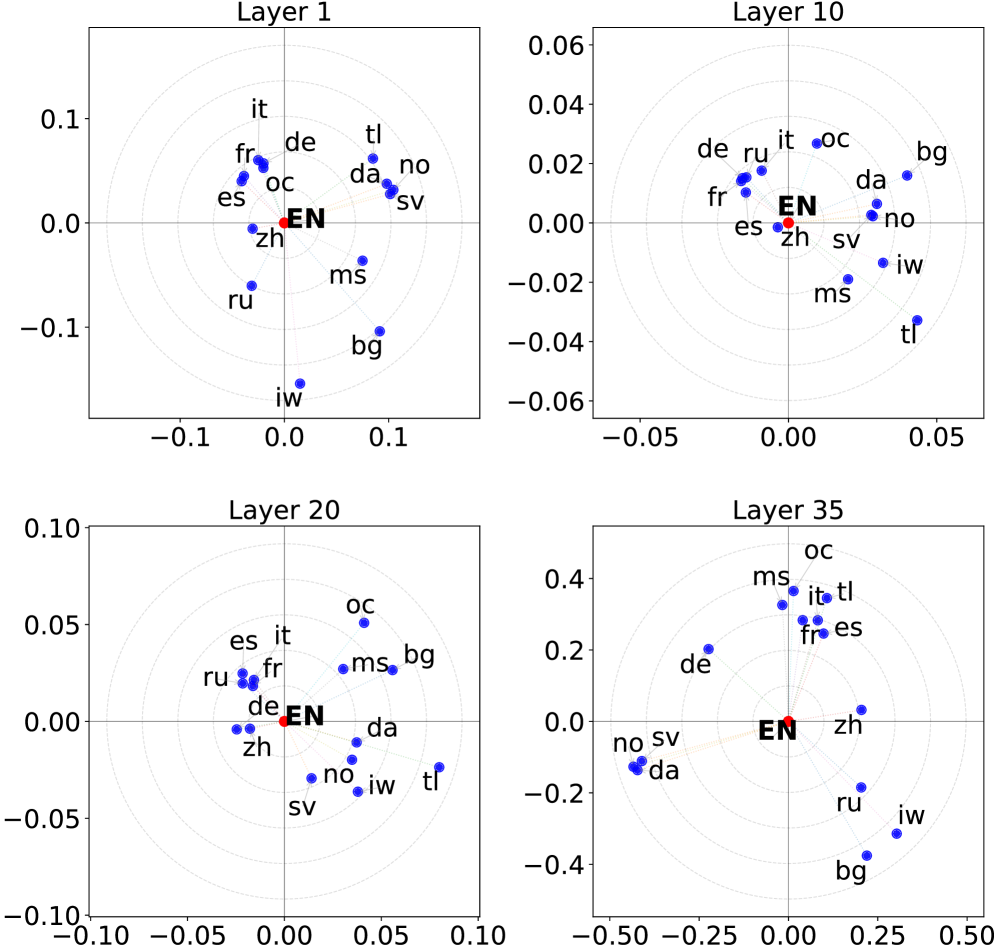
Многоязычие как Катализатор Разнообразного Мышления
Многоязычность в больших языковых моделях (LLM) не ограничивается способностью к переводу между языками. Она представляет собой качественно иной подход к обработке информации и исследованию вариантов решения задач. Внутреннее представление знаний в многоязычной модели формируется на основе взаимодействия различных лингвистических структур и концептуальных систем. Это приводит к созданию более сложной и гибкой модели мира, чем в случае одноязычной модели, где знания организованы исключительно в рамках одной лингвистической парадигмы. В результате, многоязычные LLM способны генерировать более разнообразные и креативные ответы, а также исследовать более широкий спектр возможных решений, поскольку их внутреннее пространство представлений не ограничено рамками одного языка.
Метод смешанной языковой выборки (Mixed-Language Sampling) заключается в генерации выходных данных языковой модели, при которой процесс “мышления” осуществляется с использованием нескольких языков. Целью данного подхода является доступ к расширенному когнитивному пространству, обусловленному тем, что различные языки структурируют информацию и представления отличным друг от друга способом. Вместо последовательной генерации текста на одном языке, модель переключается между языками в процессе построения ответа, что позволяет исследовать более широкий спектр возможных вариантов и, как следствие, повысить разнообразие генерируемого контента. Это отличается от простой многоязычной генерации, где модель лишь переводит текст с одного языка на другой, поскольку смешанная выборка использует языки как инструменты для формирования мыслительного процесса.
Визуализация с помощью метода главных компонент (PCA) позволяет отобразить геометрию многоязычного «пространства мышления» языковой модели. Этот метод снижает размерность векторных представлений, полученных при обработке данных на разных языках, и проецирует их на плоскость, позволяя визуально оценить, как различные языки структурируют внутренние представления модели. Анализ распределения этих представлений в многомерном пространстве выявляет степень близости или удаленности семантических концепций, выраженных на разных языках, и демонстрирует, как языковая модель организует знания, полученные из различных лингвистических источников. PCA позволяет оценить, насколько языки формируют различные кластеры представлений и как они соотносятся друг с другом, предоставляя количественную оценку влияния многоязычности на организацию знаний в модели.
Одиночная языковая выборка (Single-Language Sampling) представляет собой базовый уровень для оценки влияния многоязычности на разнообразие генерируемого текста. Этот метод предполагает последовательное генерирование выходных данных языковой моделью, используя только один язык. Полученные результаты служат точкой отсчета для сравнения с подходами, использующими смешанную языковую выборку (Mixed-Language Sampling). Изолируя эффект многоязычности путем сопоставления показателей разнообразия, полученных при одиночной и смешанной выборках, можно количественно оценить, насколько использование нескольких языков расширяет пространство возможных выходных данных и способствует генерации более разнообразных и креативных текстов. Отсутствие языковых переключений в одиночной выборке позволяет исключить вклад этого фактора при анализе и сосредоточиться исключительно на внутренних механизмах генерации модели.
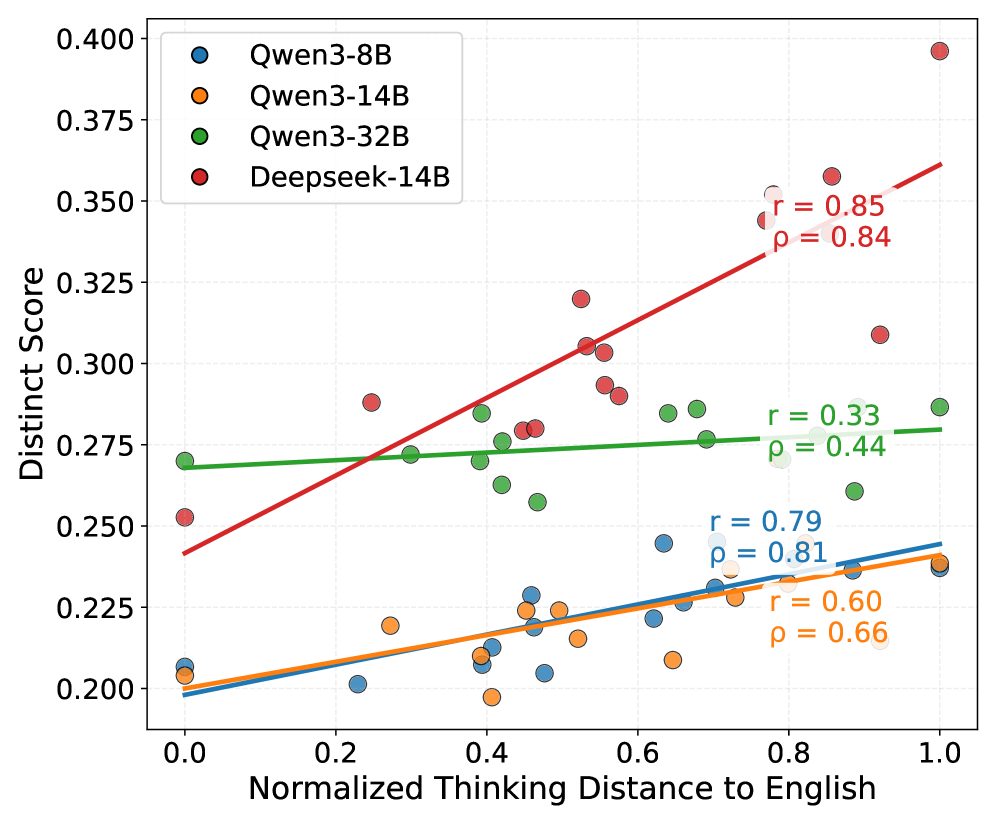
![Анализ корреляции между оценкой Distinct и расстоянием до английского языка для различных моделей показывает, что более высокие оценки Distinct связаны с меньшими расстояниями, что подтверждается коэффициентами корреляции Пирсона (r) и Спирмена (ρ), нормализованными для удобства визуализации в диапазоне [0, 1].](https://arxiv.org/html/2601.11227v1/x2.png)
Измерение и Валидация Разнообразия Выходных Данных
Для оценки функциональной различительности и семантического разнообразия генерируемых текстов используются метрики Distinct Score и Similarity Score. Distinct Score измеряет количество уникальных n-грамм в сгенерированном тексте, отражая лексическое разнообразие. Similarity Score, напротив, оценивает семантическую схожесть между различными сгенерированными текстами, используя методы векторного представления и вычисления косинусного расстояния. Высокий Distinct Score указывает на более разнообразные и оригинальные выходные данные, в то время как низкий Similarity Score свидетельствует о большей независимости и различии между сгенерированными текстами.
Для обеспечения стандартизированной оценки разнообразия генерируемых данных, используемые метрики, такие как Distinct Score и Similarity Score, проходят валидацию на общепринятых бенчмарках NoveltyBench и Infinity-Chat. NoveltyBench фокусируется на оценке новизны и оригинальности генерируемого контента, в то время как Infinity-Chat предоставляет комплексный набор тестов для оценки разнообразия и качества ответов в диалоговых системах. Использование этих бенчмарков позволяет объективно сравнивать различные модели и подходы к генерации, а также отслеживать прогресс в области повышения разнообразия генерируемых текстов.
Метод температурной шкалы (Temperature Scaling) используется в качестве средства управления при генерации текста, позволяя регулировать случайность процесса выборки. Увеличение температуры повышает вероятность выбора менее вероятных токенов, что способствует генерации более разнообразных, но потенциально менее связных текстов. Снижение температуры, напротив, усиливает вероятность выбора наиболее вероятных токенов, приводя к более предсказуемым и консервативным результатам. Регулируя данный параметр, можно целенаправленно исследовать пространство возможных выходных данных и оптимизировать баланс между разнообразием и когерентностью генерируемого текста.
При переходе от английского языка к неанглийским языкам в качестве языка «мышления» модели, наблюдалось увеличение показателя Distinct Score на 5.3-7.7 пункта и снижение показателя Similarity Score на 1.04-2.56 пункта при оценке на бенчмарке NoveltyBench. Данные изменения указывают на то, что использование неанглийских языков способствует генерации более разнообразных и отличных друг от друга ответов языковыми моделями, при этом снижается семантическое сходство между ними по сравнению с результатами, полученными при использовании английского языка. Эти показатели были получены в ходе сравнительного анализа и служат количественной оценкой влияния языка «мышления» на разнообразие генерируемого контента.
Английский язык используется в качестве ключевой базовой точки для оценки вклада многоязычных подходов к разнообразию генерируемых результатов. Использование английского языка позволяет изолировать и количественно оценить изменения в метриках разнообразия, таких как Distinct Score и Similarity Score, возникающие при переходе к другим языкам. Сравнение с результатами, полученными на английском языке, необходимо для определения, действительно ли наблюдаемое увеличение Distinct Score и снижение Similarity Score при использовании неанглийских языков обусловлено именно многоязычностью, а не случайными факторами или особенностями конкретных наборов данных. Это позволяет более точно оценить эффективность многоязычных моделей в генерации разнообразных и семантически отличающихся текстов.
К Плюралистическому Выравниванию и Ответственному Искусственному Интеллекту
Плюралистическое выравнивание представляет собой подход к разработке больших языковых моделей (LLM), направленный на обеспечение отражения в их ответах широкого спектра культурных перспектив и ценностей. Основная задача заключается в смягчении предвзятостей и стереотипов, которые могут быть заложены в обучающих данных или архитектуре модели. Этот процесс требует внимательного изучения различных культурных норм, убеждений и мировоззрений, чтобы LLM могли генерировать ответы, учитывающие многообразие человеческого опыта. Вместо того, чтобы навязывать доминирующую культурную точку зрения, плюралистическое выравнивание стремится к созданию систем искусственного интеллекта, способных понимать и уважать различные культурные контексты, что способствует более справедливому и инклюзивному взаимодействию с пользователями по всему миру.
Современные системы искусственного интеллекта, в особенности большие языковые модели, требуют глубокого понимания культурных знаний и ценностей для обеспечения их инклюзивности и справедливости. Эффективное согласование с принципами плюрализма невозможно без учета разнообразия мировоззрений, норм и традиций, существующих в различных культурах. Разработка действительно равноправных систем предполагает не просто генерацию разнообразных ответов, но и интеграцию в алгоритмы представлений о ценностях, моральных принципах и социальных нормах, характерных для разных культурных групп. Такой подход позволяет минимизировать предвзятость и стереотипы, создавая инструменты, которые будут полезны и приемлемы для людей во всем мире, независимо от их культурной принадлежности. Внедрение этих знаний в процесс обучения моделей способствует формированию более объективных и непредвзятых результатов, что является ключевым шагом на пути к ответственному развитию искусственного интеллекта.
Для количественной оценки культурного плюрализма в ответах больших языковых моделей (LLM) используется понятие энтропии. Этот показатель позволяет измерить разнообразие представленных перспектив и избежать доминирования одной культурной точки зрения. Более высокая энтропия свидетельствует о большем включении различных культурных ценностей и знаний в генерируемый текст, что указывает на более сбалансированный и репрезентативный результат. Использование энтропии как метрики позволяет не только оценивать текущий уровень культурного разнообразия, но и сравнивать эффективность различных стратегий семплирования при создании более инклюзивных и справедливых систем искусственного интеллекта. Таким образом, энтропия служит важным инструментом для обеспечения того, чтобы LLM отражали богатство и сложность мировой культуры.
Исследование выявило значимую взаимосвязь между показателем Distinct Score и лингвистической удаленностью от английского языка, подтвержденную коэффициентом корреляции Пирсона в диапазоне от 0.72 до 0.88. Это указывает на то, что языки, более отличные от английского в плане структуры и лексики, способствуют генерации более разнообразных и отличных друг от друга ответов языковыми моделями. Таким образом, языковое разнообразие, измеряемое степенью удаленности от доминирующего английского языка, играет ключевую роль в достижении более широкого спектра представленных перспектив и снижении предвзятости в сгенерированном тексте. Этот результат подчеркивает важность учета лингвистических особенностей различных языков при разработке и оценке моделей искусственного интеллекта, стремящихся к представлению глобального культурного разнообразия.
Исследование продемонстрировало, что разработанный подход обеспечивает наивысший уровень культурного плюрализма, измеряемого показателем энтропии, среди протестированных стратегий семплирования. Анализ данных, полученных из наборов Blend и WVS, последовательно выявил превосходство данной методики в представлении широкого спектра культурных перспектив. Этот результат указывает на потенциал подхода для создания более инклюзивных и справедливых систем искусственного интеллекта, способных учитывать многообразие ценностей и убеждений, существующих в мире. Полученные данные свидетельствуют о том, что предложенный метод обеспечивает более полное и сбалансированное представление различных культурных точек зрения в генерируемых ответах.
Ключевая задача, стоящая перед разработчиками искусственного интеллекта, заключается не просто в создании разнообразия в ответах языковых моделей, а в достижении подлинного отражения многообразия культур мира. Это означает, что системы искусственного интеллекта должны не просто генерировать различные варианты, но и учитывать широкий спектр ценностей, убеждений и перспектив, свойственных различным культурам. Стремление к такому подходу предполагает глубокое понимание культурных особенностей и разработку алгоритмов, способных учитывать эти нюансы при формировании ответов. В конечном итоге, цель состоит в том, чтобы создать искусственный интеллект, который будет не просто инструментом, а отражением богатой и сложной культурной мозаики нашей планеты, способным к кросс-культурному взаимодействию и взаимопониманию.
Исследование демонстрирует, что разнообразие «языка мысли» в больших языковых моделях напрямую влияет на спектр генерируемых ответов. Это подтверждает важность продуманной архитектуры, где структура определяет поведение системы. Как однажды заметила Барбара Лисков: «Хорошее проектирование — это всегда компромисс между желаемым и возможным». В контексте представленной работы, создание «пространства мышления», способного поддерживать множественные перспективы, становится критически важным для достижения не только разнообразия, но и более инклюзивных, культурно-чувствительных ответов. Недооценка границ ответственности в проектировании подобных систем может привести к неожиданным и нежелательным последствиям, поскольку всё ломается по границам ответственности — если их не видно, скоро будет больно.
Куда же дальше?
Представленные результаты подчеркивают, что кажущаяся «мысль» большой языковой модели — это не монолит, а скорее пространство представлений, подверженное тонким изменениям. Управление этим «пространством мышления» для достижения разнообразия выходных данных — задача, требующая не столько изощрённых алгоритмов, сколько глубокого понимания компромиссов. Каждое упрощение в архитектуре модели, каждое стремление к «эффективности», неминуемо влечёт за собой потерю нюансов и, следовательно, потенциального разнообразия.
Очевидным направлением дальнейших исследований представляется изучение не только способов введения разнообразия в «язык мысли», но и способов измерения его истинной ценности. Простое увеличение количества вариантов ответа — недостаточно. Необходимо разработать метрики, учитывающие не только поверхностное разнообразие, но и глубинную семантическую и культурную значимость каждого ответа. Иначе рискуем получить лишь шум, прикрывающий отсутствие реального понимания.
В конечном счёте, вопрос заключается не в том, как заставить модель выглядеть более творческой, а в том, как создать систему, способную к истинно гибкому и контекстуально-зависимому мышлению. Это задача, требующая не только технических инноваций, но и философского осмысления самой природы интеллекта и творчества. Ведь структура всегда определяет поведение, и лишь понимание этой связи позволит нам построить действительно разумные системы.
Оригинал статьи: https://arxiv.org/pdf/2601.11227.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовый усилитель света на чипе: новый уровень эффективности
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Видео будущего: генерация длинных роликов без обучения
- Квантовое управление: от теории к практике
2026-01-19 17:25