Автор: Денис Аветисян
Новое исследование показывает, что для обучения мультимодальных систем важнее не количество данных, а их качество и сложность.
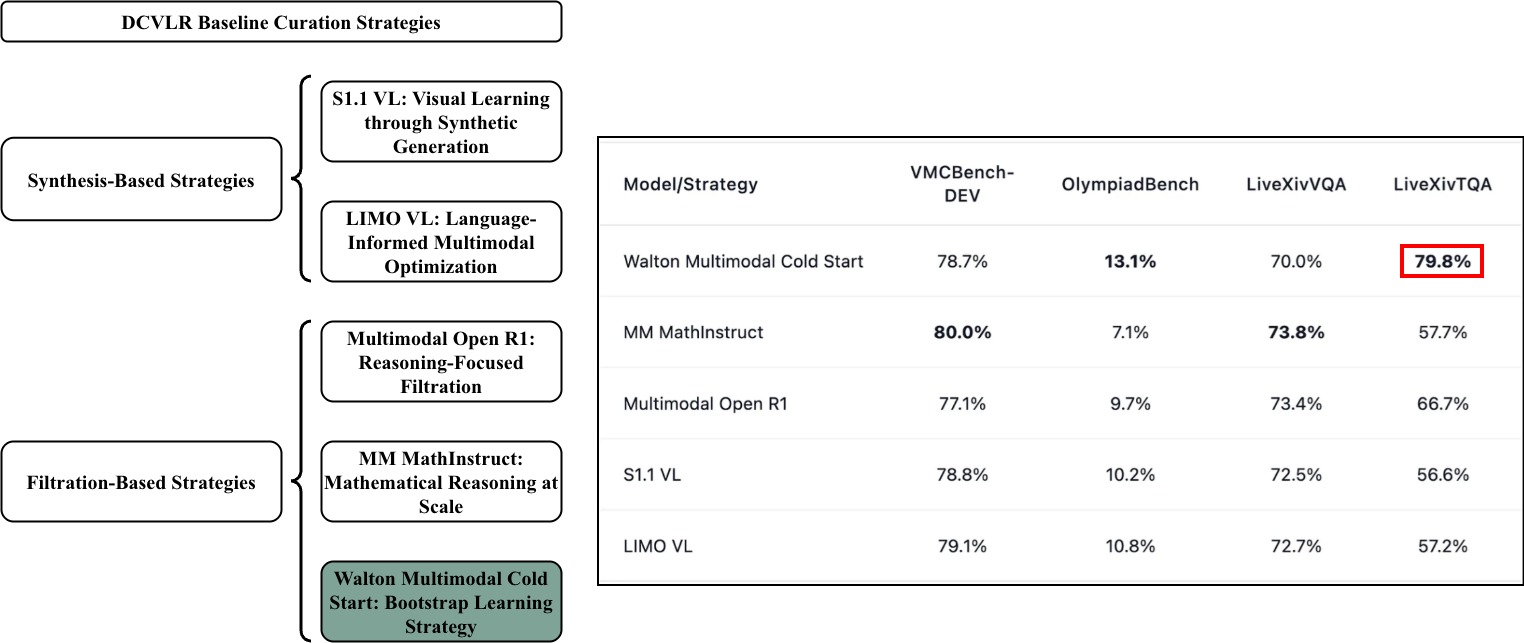
Анализ результатов челленджа DCVLR демонстрирует, что фильтрация сложных, но обучаемых примеров эффективнее увеличения размера датасета или использования эвристик разнообразия.
Несмотря на растущий объем доступных данных, эффективность обучения моделей мультимодального рассуждения остается сложной задачей. В работе «What Matters in Data Curation for Multimodal Reasoning? Insights from the DCVLR Challenge» исследуется роль курации данных в контексте соревнования DCVLR, позволяющего изолировать влияние отбора данных при фиксированной модели и протоколе обучения. Полученные результаты демонстрируют, что отбор примеров на основе уровня сложности является ключевым фактором повышения производительности, превосходя увеличение размера датасета или применение эвристик разнообразия. Можно ли разработать более эффективные стратегии курации данных, учитывающие как сложность примеров, так и их согласованность для достижения более устойчивого и эффективного мультимодального рассуждения?
Пределы Данных: Ограничения Мультимодального Рассуждения
Современные модели, объединяющие обработку изображений и естественного языка, демонстрируют впечатляющий прогресс, однако их возможности принципиально ограничены объемом и качеством обучающих данных. Несмотря на растущую вычислительную мощность и усовершенствованные архитектуры, такие модели, как правило, показывают насыщение в производительности при недостаточном количестве или нерепрезентативном наборе данных. По сути, способность модели к рассуждению и обобщению напрямую зависит от того, насколько разнообразен и всеобъемлющ опыт, полученный в процессе обучения. Поэтому, несмотря на значительные достижения, дальнейший прогресс в области мультимодального искусственного интеллекта требует не только разработки новых алгоритмов, но и создания более масштабных и качественных обучающих наборов данных, отражающих сложность реального мира.
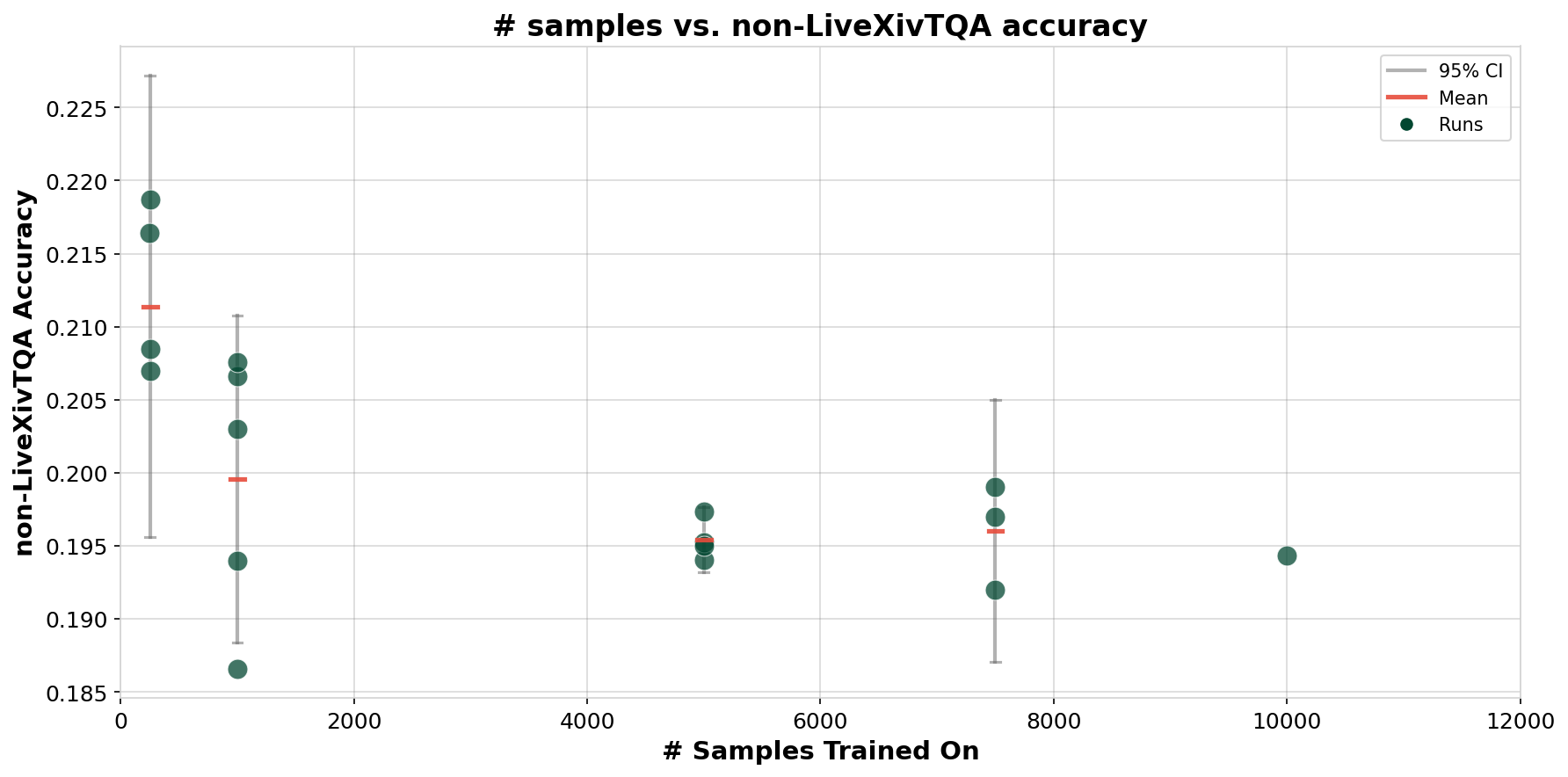
Исследования показывают, что простое увеличение объёма данных для обучения мультимодальных моделей, таких как Vision-Language Models (VLMs), рано или поздно наталкивается на предел эффективности — так называемый “Режим Насыщения”. На практике это проявляется в том, что после достижения определенного порога, примерно 1000 примеров в бенчмарках вроде LiveXivTQA, дальнейшее наращивание объёма данных перестаёт приносить существенного прироста точности. Несмотря на значительные вычислительные затраты и усилия, направленные на сбор и обработку дополнительных данных, наблюдается стабилизация показателей, что указывает на необходимость пересмотра подходов к обучению и разработке более эффективных методов использования существующих ресурсов. Это подчеркивает важность не только количества, но и качества, а также разнообразия данных, используемых для обучения моделей.
Несмотря на ценность существующих наборов данных, таких как LiveXivTQA, представляющих собой важный шаг в развитии мультимодальных моделей, они могут не в полной мере отражать всё многообразие реальных задач, требующих рассуждений на основе визуальной и текстовой информации. Исследования показывают, что простое увеличение размера этих наборов данных, превышающее 1000 примеров, не всегда приводит к стабильному улучшению средней точности моделей. Это указывает на то, что ключевым фактором является не только количество данных, но и их качество, разнообразие и репрезентативность, способные эффективно охватить все нюансы сложных сценариев мультимодального мышления. Таким образом, дальнейший прогресс требует разработки более продуманных и разнообразных наборов данных, которые смогут стимулировать развитие действительно интеллектуальных систем.
Стратегическое Курирование Данных для Улучшенного Рассуждения
Задача DCVLR (Data Curation for Visual Language Reasoning) представляет собой строгую платформу для оценки влияния стратегий курирования данных на производительность мультимодального рассуждения. Она позволяет изолировать и количественно оценить вклад различных методов курирования, таких как фильтрация по сложности, от других факторов, влияющих на обучение моделей. Ключевой особенностью DCVLR является стандартизированный набор данных и метрик, что обеспечивает воспроизводимость и сравнимость результатов различных подходов к курированию данных. Это позволяет исследователям объективно оценить эффективность техник, направленных на улучшение способности моделей к обработке и интеграции визуальной и текстовой информации для решения задач рассуждения.
Эффективная курация данных выходит за рамки простого увеличения объема обучающей выборки; она требует тщательного отбора и подготовки примеров. Методы, такие как фильтрация по сложности (Difficulty-Based Filtering), показали себя как основной фактор, определяющий прирост производительности моделей. Этот подход заключается в приоритезации примеров, вызывающих наибольшие затруднения у модели, что позволяет создать целенаправленный обучающий сигнал и ускорить процесс сходимости. В отличие от случайного добавления данных, целенаправленный отбор примеров, основанный на оценке их сложности, позволяет более эффективно использовать вычислительные ресурсы и добиться значительных улучшений в производительности модели при решении задач мультимодального рассуждения.
Приоритизация примеров, вызывающих затруднения у модели, позволяет создать целенаправленный обучающий сигнал и ускорить сходимость процесса обучения. Вместо равномерного использования всего набора данных, фокусировка на сложных примерах обеспечивает более эффективное использование вычислительных ресурсов и позволяет модели быстрее улучшать свои показатели в областях, где она изначально испытывала трудности. Такой подход, известный как curriculum learning, предполагает постепенное увеличение сложности обучающих данных, что способствует более стабильному и быстрому обучению, особенно в задачах, требующих мультимодального рассуждения. Эффективность данного метода подтверждается экспериментальными данными, демонстрирующими значительное увеличение скорости сходимости и повышение общей производительности модели.
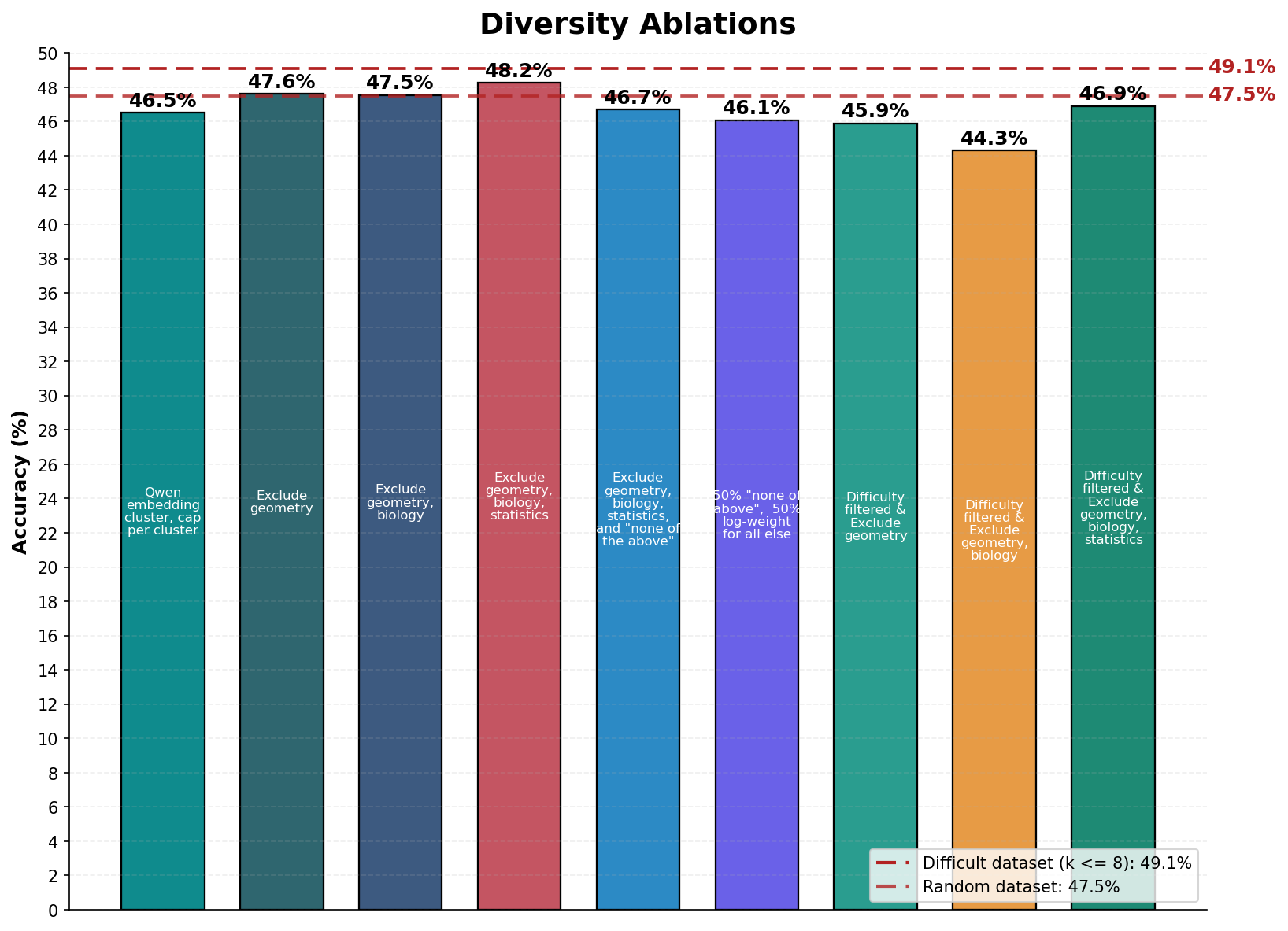
Максимизация Разнообразия и Представительности в Датасетах
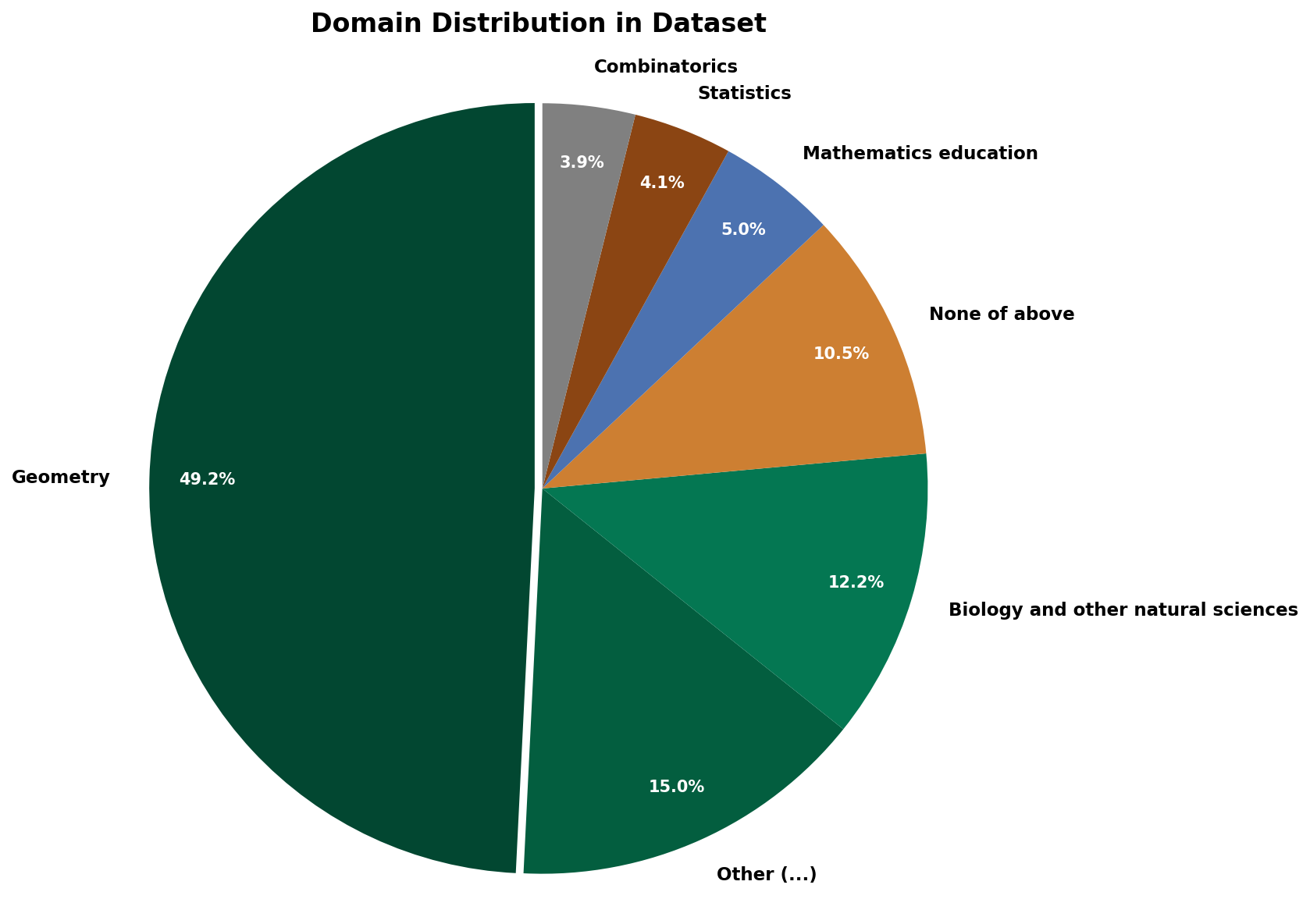
Метод кластеризации для обеспечения разнообразия использует векторное представление данных (Embedding Space) для выявления и отбора наиболее репрезентативных примеров. Данный подход предполагает, что примеры, близкие друг к другу в Embedding Space, представляют собой схожие концепции или паттерны. Путем кластеризации всего набора данных и последующего отбора примеров из каждого кластера, обеспечивается более широкое покрытие исходного распределения данных и, как следствие, уменьшается вероятность перепредставленности отдельных подмножеств или концепций в итоговом наборе данных. Эффективность метода зависит от качества Embedding Space, который должен адекватно отражать семантические различия между примерами.
Для обеспечения сбалансированности и снижения предвзятости в наборах данных применяется балансировка по категориям, основанная на Математической Классификации (MSC). MSC представляет собой иерархическую систему классификации математических работ, позволяющую точно определять предметные области и обеспечивать пропорциональное представление различных разделов математики в данных. Использование MSC позволяет избежать перекосов, возникающих при неравномерном представлении отдельных областей, что критически важно для обучения моделей, способных эффективно работать с разнообразными математическими задачами и материалами. Пропорциональное распределение данных по категориям MSC гарантирует, что модели не будут демонстрировать предвзятость в отношении определенных математических дисциплин, обеспечивая более справедливую и надежную работу.
Синтетические наборы данных, такие как CoSyn-400K, могут использоваться для расширения существующих данных, однако требуют тщательной доработки. Необходимость в этом обусловлена тем, что первоначальное качество генерируемых данных может быть недостаточным для эффективного обучения моделей. Для улучшения качества трассировок (trace quality) применяются современные языковые модели, в частности GPT-4o, которые позволяют повысить реалистичность и согласованность сгенерированных данных, приближая их к характеристикам реальных данных и снижая потенциальные искажения.
В качестве отправной точки для формирования нашей кураторской коллекции данных мы использовали набор Walton Multimodal Cold Start. Этот набор данных послужил базовым уровнем, от которого мы отталкивались при дальнейшем расширении и дополнении. Использование Walton Multimodal Cold Start позволило нам создать начальный корпус, который впоследствии был увеличен и адаптирован для решения конкретных задач, требующих более широкого и разнообразного набора данных. Дальнейшее развитие коллекции включало добавление новых примеров и модификацию существующих, что обеспечило повышение ее репрезентативности и эффективности.
Влияние на Будущие Мультимодальные Системы Искусственного Интеллекта
Результаты, полученные в ходе соревнований DCVLR Challenge, наглядно демонстрируют, что продуманный отбор данных может значительно превзойти простое увеличение их объема, даже при использовании фиксированного протокола обучения. Данное исследование показало, что ключевым фактором повышения производительности является фильтрация данных на основе их сложности, позволяющая модели концентрироваться на наиболее информативных примерах. Вместо слепого наращивания объёма датасета, эффективная курация позволяет добиться существенного улучшения качества обучения и, следовательно, более высокой точности и надежности мультимодальных систем искусственного интеллекта. Такой подход открывает новые перспективы для разработки более эффективных моделей, способных решать сложные задачи в различных областях, от автоматического описания изображений до ответов на вопросы, основанные на визуальной информации.
Исследования показали, что ключевым фактором повышения эффективности мультимодальных систем искусственного интеллекта является фильтрация данных на основе их сложности. В ходе экспериментов установлено, что отбор наиболее сложных примеров для обучения существенно превосходит по результатам простое увеличение объема данных. При этом, широко используемые методы, направленные на обеспечение разнообразия обучающей выборки, не привели к дополнительному улучшению производительности. Таким образом, акцент на сложности данных, а не на их разнообразии, представляется наиболее перспективным подходом к разработке более эффективных и интеллектуальных мультимодальных систем, способных решать широкий спектр задач, от генерации подписей к изображениям до ответов на вопросы, основанные на визуальной информации.
Предложенные методы, продемонстрировавшие эффективность в соревновании DCVLR, обладают широким потенциалом применения в различных областях мультимодального искусственного интеллекта. От генерации описаний к изображениям и ответов на вопросы, основанных на визуальной информации, до более сложных задач, включающих анализ видео, обработку речи и объединение нескольких сенсорных модальностей, принципы стратегической курации данных могут значительно улучшить производительность моделей. Особенно ценно то, что фокус на отборе сложных, но релевантных примеров, превосходит простые подходы к увеличению объема обучающих данных, открывая возможности для создания более эффективных и обобщающих систем, способных решать широкий спектр задач, выходящих за рамки конкретного соревнования.
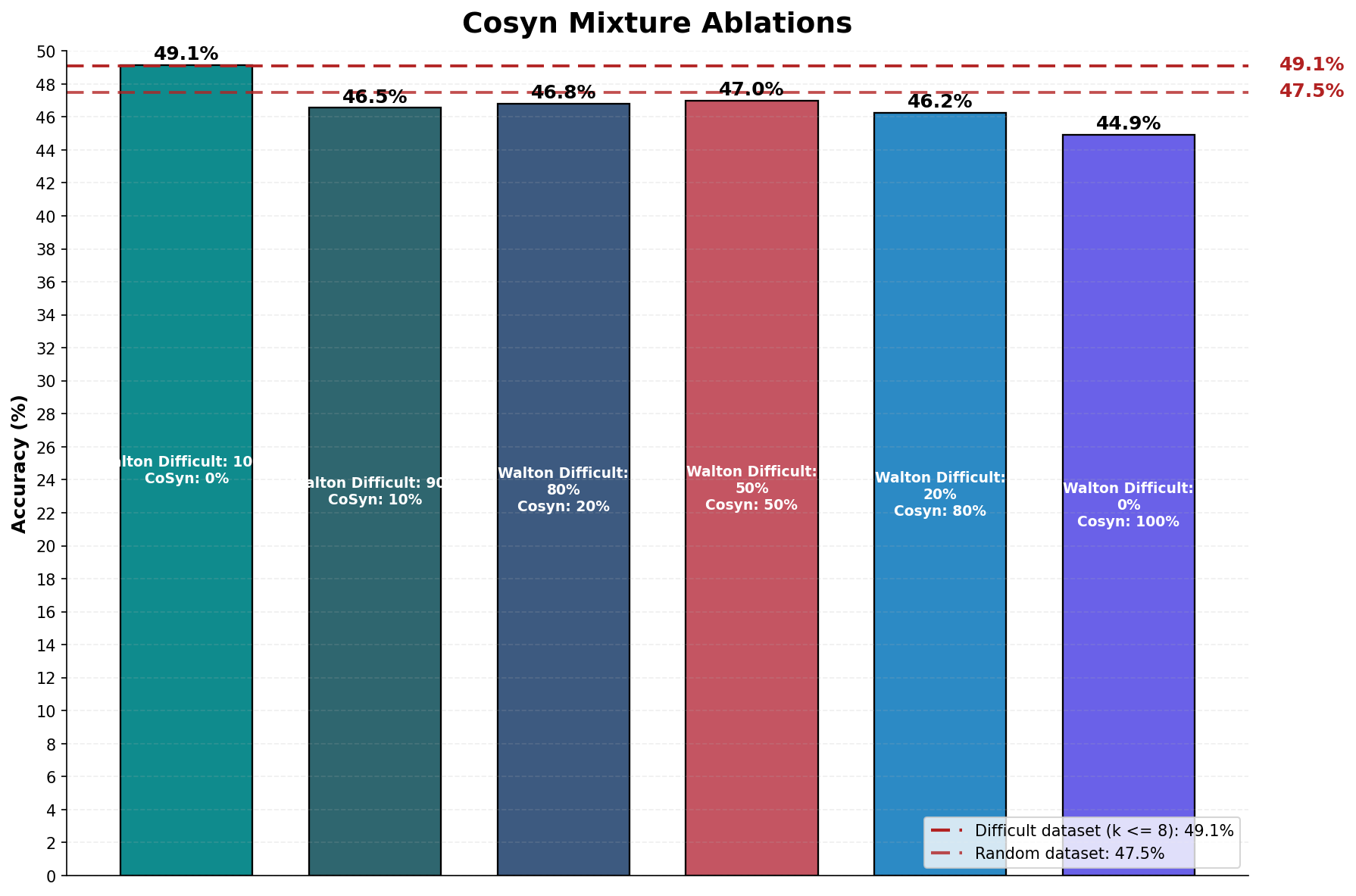
Исследование, представленное в данной работе, подтверждает важность тщательно подобранных данных для обучения мультимодальных систем. Авторы показывают, что фильтрация сложных, но обучаемых примеров оказывает большее влияние на производительность, чем простое увеличение размера датасета или применение эвристик разнообразия. Этот подход напоминает принцип эволюционного развития системы: небольшие, целенаправленные изменения в структуре данных могут привести к значительным улучшениям в её функциональности. Как точно заметил Анри Пуанкаре: «Наука не состоит из ряда истин, а из методов их открытия». В данном случае, метод заключается в осознанном формировании данных, что позволяет эффективно решать задачи мультимодального рассуждения и создавать более надежные и адаптивные системы.
Куда Ведут Эти Пути?
Представленное исследование демонстрирует, что в задачах мультимодального рассуждения, искусное отсеивание примеров, представляющих подлинную сложность, но остающихся обучаемыми, оказывается более плодотворным, чем простое наращивание объемов данных или применение эвристик, направленных на повышение разнообразия. Однако, следует помнить: любая система ломается по границам ответственности — если эти границы не проявлены в процессе отбора данных, рано или поздно последуют болезненные последствия. Недостаточно просто отфильтровать «плохие» примеры; необходимо понимать, какие ошибки они маскируют и почему возникают.
Очевидным следующим шагом представляется разработка более точных метрик сложности, учитывающих не только поверхностные характеристики данных, но и их влияние на внутреннее представление модели. Необходимо исследовать, как эти метрики могут быть использованы для динамической адаптации процесса обучения, позволяя модели фокусироваться на наиболее информативных и сложных примерах. Важно помнить, что увеличение масштаба данных само по себе не решает проблемы; структура данных определяет поведение системы, и без вдумчивого подхода к организации этой структуры, любое увеличение масштаба будет лишь усугублять существующие недостатки.
В конечном итоге, успех в мультимодальном рассуждении потребует не только совершенствования алгоритмов и метрик, но и глубокого понимания принципов, лежащих в основе восприятия и познания. Иначе, мы рискуем создать системы, которые лишь имитируют интеллект, оставаясь слепыми к подлинной сложности окружающего мира. И в этом, пожалуй, заключается самая сложная и интересная задача, стоящая перед исследователями.
Оригинал статьи: https://arxiv.org/pdf/2601.10922.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовый усилитель света на чипе: новый уровень эффективности
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Видео будущего: генерация длинных роликов без обучения
- Квантовое управление: от теории к практике
2026-01-20 00:08