Автор: Денис Аветисян
Новая модель ShapeR позволяет надежно реконструировать трехмерные объекты из повседневных видеозаписей, объединяя изображения, облака точек и текстовые описания.
Исследователи представили ShapeR, новый rectified flow model для надежного 3D-реконструкции, использующий мультимодальные данные и преодолевающий ограничения существующих методов.
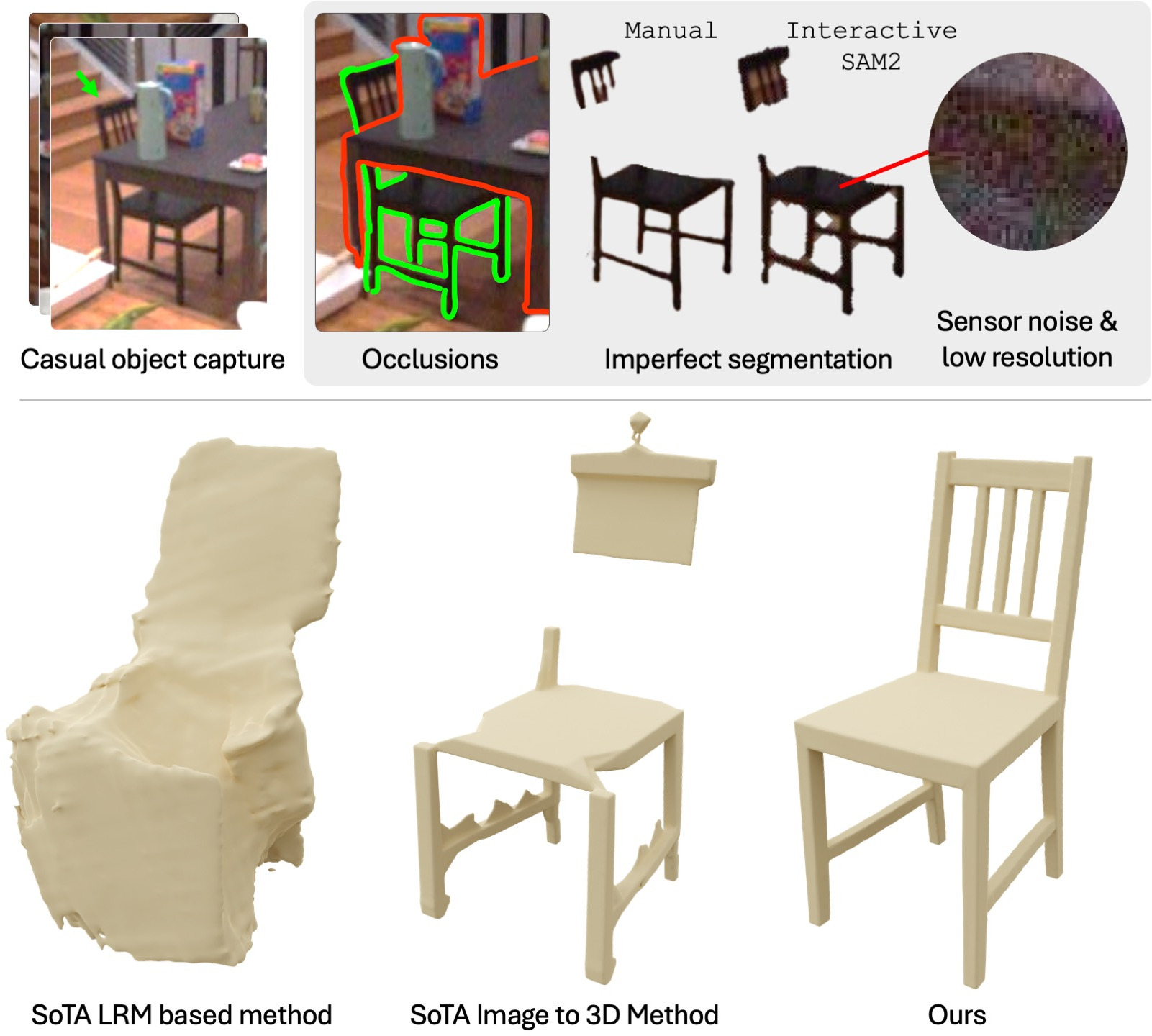
Несмотря на значительный прогресс в области генерации 3D-моделей, существующие подходы часто требуют чистых и хорошо сегментированных входных данных, что редко встречается в реальных условиях. В данной работе представлена система ShapeR: Robust Conditional 3D Shape Generation from Casual Captures, новый подход к генерации 3D-моделей объектов, использующий последовательности изображений, полученные в произвольных условиях. ShapeR объединяет данные SLAM, детекцию объектов и языковые модели для создания высококачественных 3D-моделей, устойчивых к шумам и неполноте данных. Сможет ли эта технология значительно упростить процесс 3D-реконструкции объектов в реальном мире и открыть новые возможности для приложений в робототехнике и дополненной реальности?
Преодолевая Границы: Вызовы 3D-Реконструкции
Традиционные методы трехмерной реконструкции часто сталкиваются с трудностями при обработке данных, полученных в обычных условиях — например, с фотографий, сделанных на смартфон или веб-камеру. Это связано с тем, что алгоритмы, разработанные для контролируемых сред, таких как сканирование с использованием специализированного оборудования, плохо приспособлены к неидеальным условиям съемки, таким как плохое освещение, размытость изображения, частичная видимость объектов и отсутствие достаточного перекрытия между кадрами. В результате, получаемые трехмерные модели могут быть неполными, содержать артефакты, искажения или неточно отражать реальную геометрию объектов, что существенно ограничивает их применение в различных областях, начиная от виртуальной реальности и заканчивая промышленным дизайном и робототехникой.
Существующие методы трехмерной реконструкции зачастую фокусируются на создании целостной картины сцены, а не на точной реконструкции отдельных объектов. Такой подход, известный как Scene-Centric Reconstruction, стремится воссоздать общее пространство, включая взаимосвязи между элементами, но при этом может жертвовать детализацией конкретных предметов. Это означает, что, хотя общая структура сцены может быть верно воссоздана, индивидуальные объекты внутри неё могут быть представлены в упрощенном виде или с невысокой точностью. Такая стратегия оправдана в задачах, где важен общий контекст, например, в виртуальной реальности или при создании панорамных изображений, но становится препятствием при необходимости детального анализа или манипулирования отдельными объектами, например, в робототехнике или промышленном дизайне.
Существенная проблема в области трехмерной реконструкции заключается в сложности отделения отдельных объектов от перегруженных и сложных сцен. Это затрудняет не только детальный анализ каждого элемента, но и последующую возможность манипулирования ими в цифровом пространстве. Алгоритмы часто сталкиваются с трудностями при определении границ объекта, особенно в условиях частичной видимости или наличия схожих текстур на соседних элементах. В результате, реконструированная модель может содержать неточности или объединять несколько объектов в один, что делает невозможным точное измерение, редактирование или использование отдельных компонентов в дальнейших приложениях, таких как виртуальная или дополненная реальность, а также роботизированные системы.

ShapeR: Новый Взгляд на Понимание 3D-Сцен
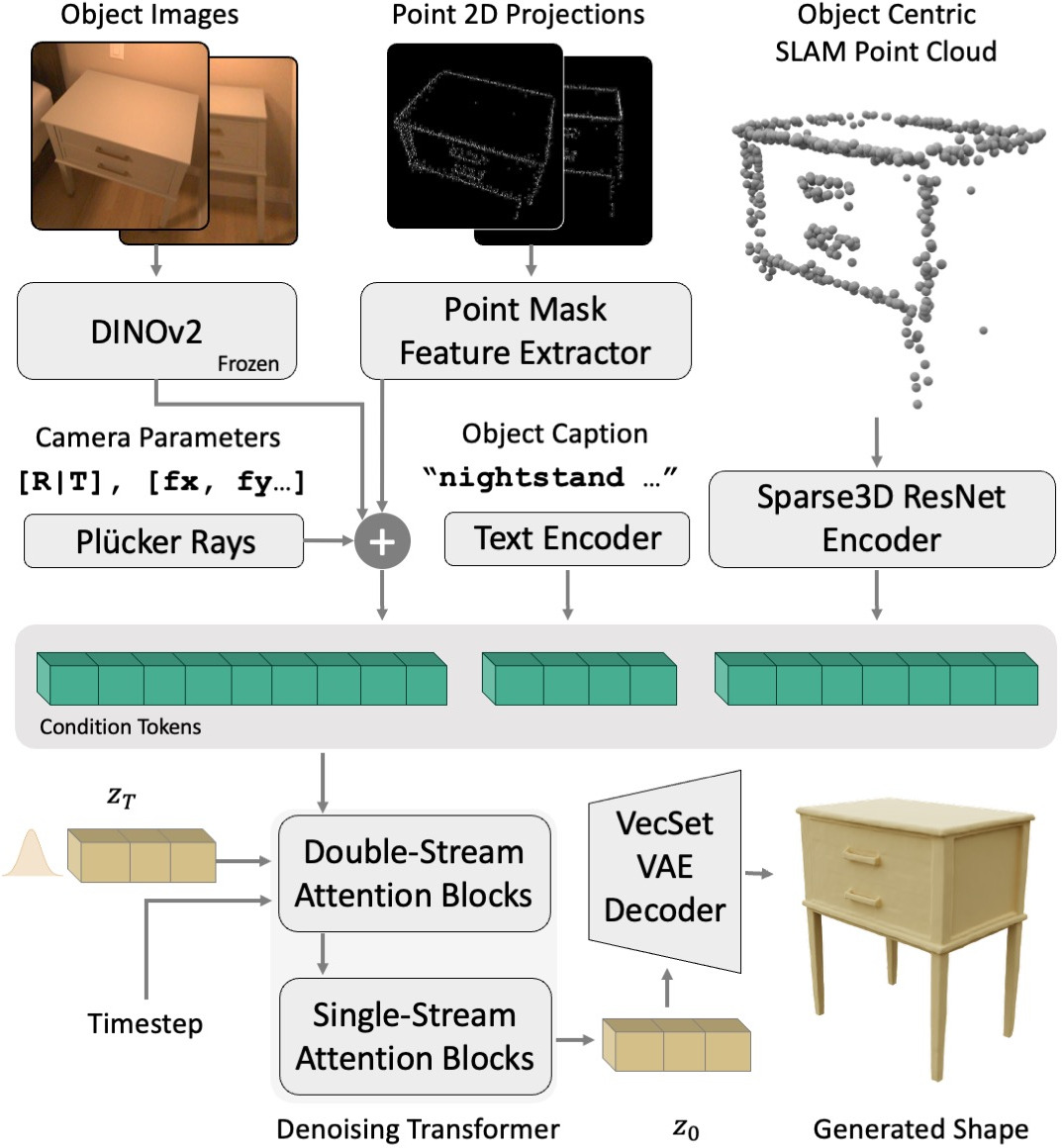
Модель ShapeR использует ректифицированный поток — генеративный подход, позволяющий создавать устойчивые 3D-модели по последовательностям изображений. В отличие от традиционных генеративных моделей, ректифицированный поток напрямую моделирует преобразования между кадрами, что позволяет генерировать более когерентные и реалистичные 3D-формы. Этот метод особенно эффективен при работе с «обыденными» (casual) последовательностями изображений, то есть с данными, собранными в неконтролируемых условиях, что делает его более надежным в реальных сценариях. Ключевым аспектом является способность модели к эффективному представлению деформаций и изменений геометрии объектов в последовательности кадров.
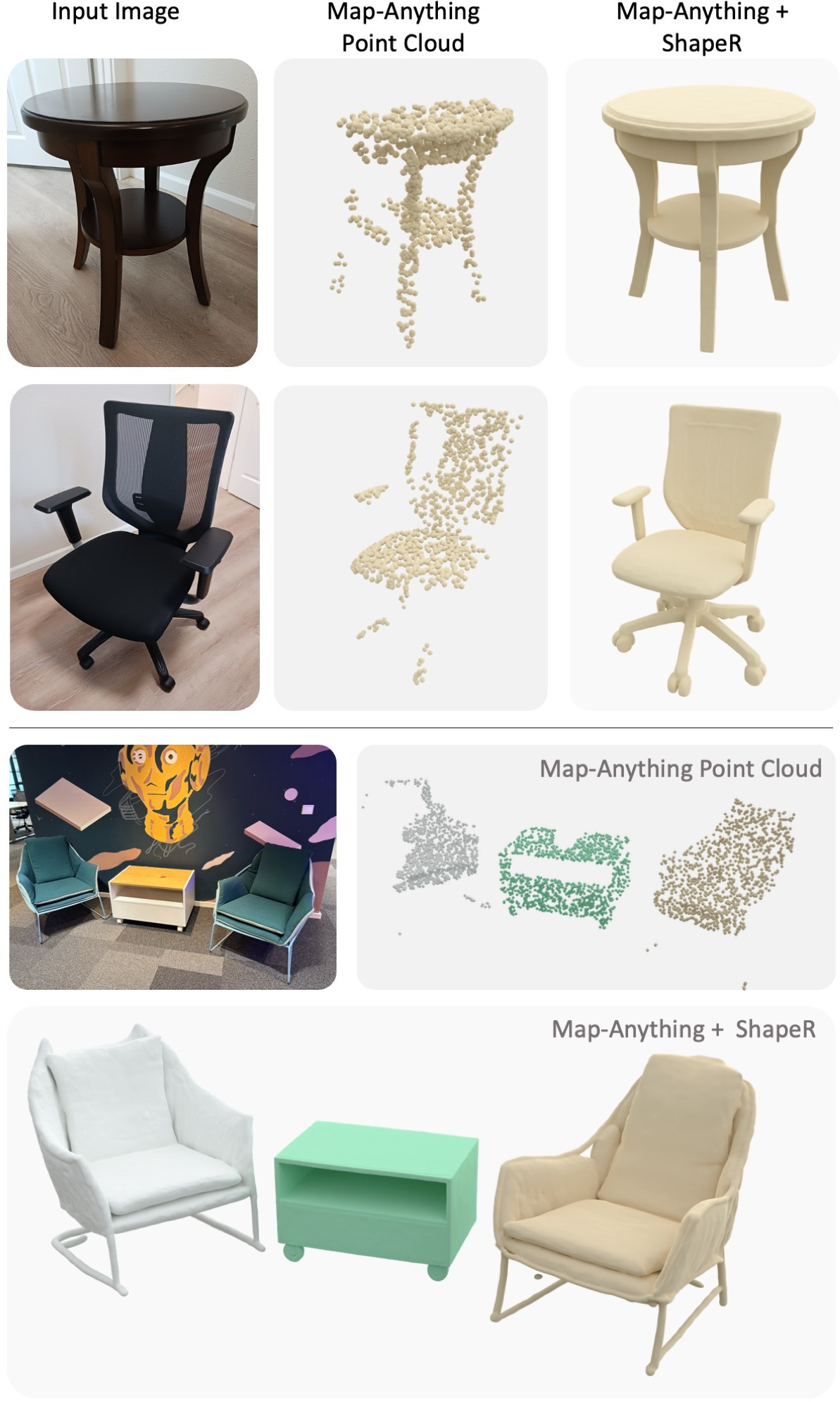
Модель ShapeR использует мультимодальную обусловленность, объединяя разреженные облака точек, изображения с известной позой и текстовые описания для комплексного понимания сцены. Интеграция этих разнородных источников данных позволяет модели строить более полное и точное представление трехмерной среды. Облака точек предоставляют геометрическую информацию, изображения — визуальные детали и контекст, а текстовые описания — семантическое понимание объектов и их взаимосвязей. Такой подход позволяет ShapeR эффективно обрабатывать неполные или зашумленные данные и генерировать реалистичные трехмерные реконструкции сцен.
В основе ShapeR лежит двухэтапный подход к обучению с использованием метода curriculum learning. На первом этапе модель предварительно обучается на крупномасштабных наборах данных, содержащих отдельные объекты. Это позволяет ей приобрести базовое понимание формы и структуры объектов. На втором этапе происходит дообучение модели на реалистичных сценах, что позволяет адаптировать полученные знания к сложным, многообъектным окружениям и улучшить точность реконструкции отдельных объектов в контексте всей сцены. Такой подход позволяет эффективно использовать данные и значительно повысить качество 3D-реконструкции.
Ключевым преимуществом ShapeR является способность к объектно-ориентированной реконструкции, позволяющей изолировать и точно представлять отдельные объекты в 3D-сцене. В отличие от традиционных методов, ShapeR обеспечивает детальное моделирование каждого объекта, что подтверждается результатами, достигнутыми на наборе данных ShapeR Evaluation Dataset, где модель демонстрирует передовые показатели точности и полноты реконструкции. Объектно-ориентированный подход позволяет не только повысить качество визуализации, но и облегчить последующий анализ и манипулирование отдельными компонентами сцены, открывая возможности для различных приложений, включая робототехнику и виртуальную реальность.
Внутренний Механизм: Латентное Пространство и Генеративное Моделирование
Модель Rectified Flow использует 3D Вариационный Автоэнкодер (VAE) для обучения и кодирования представлений 3D-форм. В качестве латентного пространства применяется подход VecSets, представляющий собой набор векторов, позволяющий эффективно моделировать сложные геометрические структуры. VAE преобразует входные 3D-формы в компактное латентное представление, а затем реконструирует их из этого представления. Использование VecSets в качестве латентного пространства обеспечивает более эффективное и точное кодирование 3D-геометрии по сравнению с традиционными методами, что критически важно для генерации высококачественных 3D-моделей.
Dora представляет собой специализированный вариант VecSets, предназначенный для усовершенствования латентного представления данных и, как следствие, повышения качества генерируемых 3D-моделей. В отличие от базовой реализации VecSets, Dora использует оптимизированные методы кодирования и декодирования, позволяющие более точно захватывать и воспроизводить сложные геометрические детали. Это достигается за счет применения специализированных алгоритмов обучения и архитектуры нейронной сети, что приводит к генерации 3D-форм с повышенной степенью реалистичности и детализации. Применение Dora позволяет добиться более высокой точности реконструкции и генерации, особенно в задачах, требующих высокой степени детализации и визуальной достоверности.
Возможности модели по удалению шума обеспечиваются архитектурой FLUX DiT, представляющей собой трансформаторную сеть. Для извлечения признаков используется DINOv2, а для управления генерацией применяются CLIP Text Encoder и T5 Encoder. CLIP Text Encoder кодирует текстовые подсказки, определяя желаемые характеристики генерируемых объектов, в то время как T5 Encoder обрабатывает более сложные текстовые условия, позволяя модели учитывать широкий спектр инструкций и ограничений. Комбинация этих энкодеров и трансформаторной архитектуры FLUX DiT позволяет эффективно удалять шум и создавать высококачественные 3D-модели на основе заданных условий.
В архитектуре FLUX DiT для эффективного представления положения камеры используется кодирование Плюккера (Plücker Ray Encoding). Этот метод позволяет компактно описывать лучи, проходящие через сцену, используя шесть параметров, что снижает вычислительную сложность по сравнению с традиционными представлениями, такими как матрицы поворота и векторы перемещения. Кодирование Плюккера позволяет представить каждый луч как вектор в ℝ^6, где первые три компонента представляют направление луча, а последние три — точку на луче. Это представление упрощает вычисления, необходимые для рендеринга и отслеживания лучей, что критически важно для генерации высококачественных изображений и работы с 3D-сценами.
Проверка и Сравнение: Подтверждение Превосходства ShapeR
Оценка производительности ShapeR проводилась с использованием общепринятых наборов данных ScanNet++ и Replica, что обеспечило надежную основу для сопоставительного анализа. ScanNet++ содержит богатый набор 3D-сканов реальных интерьеров с аннотациями, а Replica — набор синтетических 3D-моделей интерьеров. Использование этих стандартизированных наборов данных позволило объективно оценить качество реконструкции ShapeR и сравнить его с результатами других современных методов в контролируемых условиях, гарантируя воспроизводимость и валидность полученных результатов.
Для всесторонней оценки ShapeR разработан новый набор данных для оценки, специально предназначенный для тестирования объектно-ориентированной реконструкции в сложных условиях, имитирующих обычные сценарии захвата данных. Этот набор данных включает в себя сцены, полученные в условиях неидеального освещения, частичной видимости объектов и неточностей позиционирования камеры, что позволяет более реалистично оценить устойчивость и точность алгоритмов реконструкции по сравнению с существующими наборами данных, ориентированными на контролируемые лабораторные условия. Акцент сделан на оценке способности ShapeR к восстановлению геометрии объектов в ситуациях, характерных для повседневного использования, таких как реконструкция из видео, снятых на мобильные устройства.
Интеграция 3D детекции экземпляров значительно расширяет возможности ShapeR по выделению и анализу отдельных объектов в сценах. Данный подход позволяет системе не только реконструировать геометрию сцены, но и идентифицировать конкретные объекты, такие как стулья, столы или диваны, внутри этой сцены. Это достигается путем применения алгоритмов детекции, которые обнаруживают и сегментируют объекты, позволяя ShapeR обрабатывать каждый объект как отдельную сущность. В результате, улучшается точность реконструкции отдельных объектов, а также облегчается последующий анализ и манипулирование ими, например, для задач редактирования сцен или генерации новых объектов.
ShapeR демонстрирует значительное улучшение точности и детализации реконструкции, достигая передовых результатов, измеренных метрикой Chamfer Distance. В тестах на наборах данных ScanNet++ и Replica ShapeR превосходит эталонные данные (ground truth) по показателю полноты (completeness). Это особенно заметно в областях с окклюзиями, где эталонные данные часто не содержат геометрической информации, в то время как ShapeR способен реконструировать скрытые части объектов, обеспечивая более полную и точную 3D-модель сцены.

Взгляд в Будущее: Применение и Более Широкое Влияние
Разработка ShapeR открывает новые перспективы в областях, требующих детального понимания трехмерных сцен, таких как робототехника, дополненная и виртуальная реальность. Способность системы к точному воссозданию геометрии объектов и их взаиморасположения позволяет создавать более реалистичные и интерактивные виртуальные среды. В робототехнике это может привести к появлению роботов, способных более эффективно ориентироваться и взаимодействовать с окружающим миром, а в сферах AR/VR — к созданию принципиально новых, захватывающих пользовательских опытов, стирающих границы между физическим и цифровым пространствами. По сути, ShapeR представляет собой значительный шаг к созданию “умных” систем, способных воспринимать и интерпретировать окружающую среду аналогично человеку.
Точность реконструкции отдельных объектов, обеспечиваемая ShapeR, открывает новые возможности для взаимодействия в виртуальных средах. Это позволяет не просто отображать объекты, но и манипулировать ими с высокой степенью реалистичности и точности. Например, в виртуальной реальности пользователи смогут взаимодействовать с цифровыми моделями объектов так же, как и с их физическими аналогами, осуществляя сложные операции, такие как сборка, разборка или изменение формы. В робототехнике подобная точность реконструкции критически важна для эффективного захвата и манипулирования объектами в реальном времени, позволяя роботам выполнять сложные задачи с высокой надежностью. Способность к детальной реконструкции, таким образом, становится ключевым фактором для создания более интуитивно понятных и эффективных интерфейсов взаимодействия в самых разных областях применения.
Система ShapeR, используя обширный каталог цифровых двойников, значительно упрощает создание реалистичных и интерактивных виртуальных моделей для различных отраслей промышленности. Благодаря возможности точного воссоздания объектов и сцен, ShapeR позволяет предприятиям формировать цифровые аналоги реальных активов — от отдельных деталей и машин до целых производственных комплексов. Это открывает широкие возможности для моделирования, оптимизации и удалённого управления процессами, а также для проведения виртуальных испытаний и обучения персонала. В результате, предприятия получают инструмент для повышения эффективности, снижения издержек и ускорения инноваций, эффективно объединяя физический и цифровой миры.
Разработка ShapeR открывает новые возможности для создания более интеллектуальных и захватывающих взаимодействий, стирая границы между физической и цифровой реальностью. Способность к точному воссозданию трехмерных сцен и отдельных объектов позволяет разрабатывать системы, способные не просто отображать окружающий мир, но и понимать его структуру, что критически важно для приложений в робототехнике и дополненной реальности. В перспективе, эта работа может привести к появлению цифровых двойников, неотличимых от своих физических аналогов, и интерактивных сред, где взаимодействие с виртуальными объектами будет ощущаться как взаимодействие с реальными предметами. Это создает условия для качественно нового уровня иммерсивности и открывает возможности для обучения, проектирования и развлечений, где физические и цифровые миры неразрывно связаны.

Исследование, представленное в данной работе, демонстрирует стремление к элегантности в области 3D-реконструкции. Модель ShapeR, объединяющая различные модальности входных данных — изображения, облака точек, текст — создает целостную и устойчивую 3D-модель, преодолевая ограничения существующих методов. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть ориентирован на людей». Это особенно актуально в контексте ShapeR, поскольку модель позволяет воссоздавать объекты из обычных, неидеальных данных, делая технологии 3D-моделирования более доступными и интуитивно понятными для широкого круга пользователей. Гармоничное сочетание формы и функции в ShapeR позволяет добиться высокой точности и реалистичности воссоздаваемых объектов, что является признаком глубокого понимания задачи и стремления к совершенству.
Что Дальше?
Представленная работа, безусловно, делает шаг вперёд в области реконструкции трехмерных объектов из неидеальных данных. Однако, элегантность решения не должна заслонять остающиеся вопросы. Модели, оперирующие с «случайными» снимками, всё ещё несут в себе отпечаток этой случайности — неполнота данных, шум, вариативность освещения. Истинная гармония между формой и функцией потребует не просто преодоления этих недостатков, а их предвидения и элегантной интеграции в процесс реконструкции.
Следующим логичным шагом видится отказ от простой реконструкции “как есть” в пользу создания моделей, способных к разумному дополнению и интерпретации пропущенных деталей. Не просто заполнение пробелов, но предсказание наиболее вероятной формы, основанное на глубоком понимании семантики объекта и его контекста. Рефакторинг, а не перестройка — именно это необходимо в дальнейшем. Необходимо фокусироваться на создании моделей, которые не просто воспроизводят видимое, но и понимают, что скрыто за ним.
В конечном итоге, задача состоит не в том, чтобы создавать всё более сложные алгоритмы, а в том, чтобы приблизиться к интуитивному пониманию формы, которым обладает человек. Истинная красота масштабируется, беспорядок — нет. И только тогда, когда алгоритмы научатся отличать одно от другого, можно будет говорить о подлинном прогрессе в этой области.
Оригинал статьи: https://arxiv.org/pdf/2601.11514.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Квантовый усилитель света на чипе: новый уровень эффективности
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Сердце музыки: открытые модели для создания композиций
- Квантовый Блеск: Алмазная Точность или Очередная Иллюзия?
- LongCat-Video: ещё один «прорыв», который придётся поддерживать.
- Квантовые вычисления: линейная алгебра на службе симуляции
- Динамика в кадре: Как научить ИИ понимать физику видео
2026-01-20 05:07