Автор: Денис Аветисян
Новый подход позволяет точно предсказывать свойства молекул, используя ограниченное количество размеченных данных и учитывая контекст их структуры.
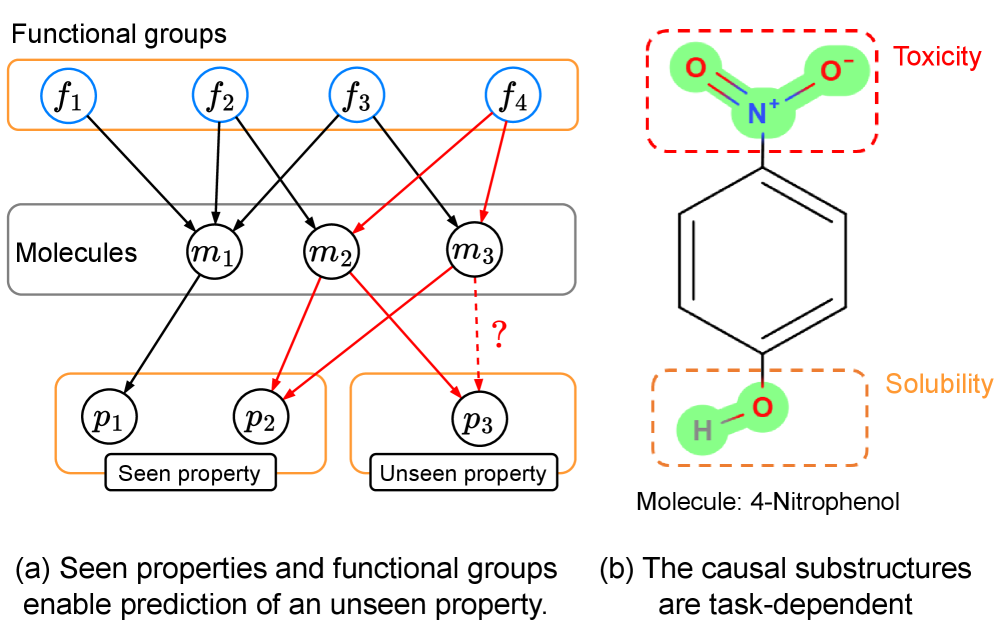
В статье представлена система CaMol, использующая причинно-следственный вывод и графовые нейронные сети для выявления ключевых причинно-следственных подструктур в молекулах.
Предсказание свойств молекул становится все более востребованной задачей, однако существующие методы испытывают трудности в условиях ограниченного количества размеченных данных. В работе, посвященной ‘Context-aware Graph Causality Inference for Few-Shot Molecular Property Prediction’, предложен новый подход, использующий контекстно-зависимый анализ причинно-следственных связей в графах молекул. Разработанная система CaMol позволяет эффективно выявлять ключевые структурные элементы, определяющие конкретные свойства, и достигать высокой точности предсказаний при минимальном объеме обучающих данных. Способствует ли такой подход созданию более интерпретируемых и надежных моделей для открытия новых материалов и лекарственных препаратов?
Разрушая Границы: Проблема Недостатка Данных в Молекулярных Исследованиях
Предсказание молекулярных свойств играет ключевую роль в разработке новых лекарственных препаратов и материалов, однако этот процесс требует огромного объема данных. Эффективное определение характеристик молекул, таких как растворимость, токсичность или проводимость, позволяет значительно ускорить процесс поиска перспективных кандидатов и снизить затраты на эксперименты. Именно поэтому, доступ к обширным и достоверным базам данных молекулярных свойств является критически важным для успеха в этих областях науки. Без достаточного количества данных, модели машинного обучения оказываются неспособными к созданию точных и надежных прогнозов, что существенно ограничивает возможности инноваций в фармацевтике и материаловедении.
Традиционные методы машинного обучения, несмотря на свою эффективность при работе с большими объемами данных, демонстрируют значительные трудности в условиях ограниченного количества размеченных молекулярных структур. Это особенно актуально для задач открытия новых лекарственных средств и материалов, где получение экспериментальных данных является дорогостоящим и трудоемким процессом. Недостаток информации приводит к переобучению моделей, снижая их способность к обобщению и предсказанию свойств неизвестных соединений. В результате, прогресс в разработке новых молекул замедляется, а поиск перспективных кандидатов становится менее эффективным, подчеркивая необходимость разработки альтернативных подходов, способных эффективно использовать скудные ресурсы данных.
Сложность молекулярных структур требует перехода к парадигмам обучения, эффективно использующим ограниченные данные. Традиционные методы машинного обучения, требующие обширных наборов данных для достижения высокой точности, часто оказываются неэффективными при работе с молекулами. Это связано с огромным химическим пространством и экспоненциальным ростом числа возможных молекулярных конфигураций. Вместо запоминания паттернов из больших объемов данных, современные подходы фокусируются на извлечении максимальной информации из небольших наборов, используя, например, трансферное обучение, активное обучение и генеративные модели. Такие методы позволяют не только предсказывать свойства молекул с высокой точностью, но и эффективно исследовать химическое пространство, открывая возможности для создания новых материалов и лекарственных препаратов, даже при ограниченном количестве исходных данных.

Мета-Обучение: Искусство Обучения на Ограниченных Данных
Мета-обучение представляет собой эффективный подход к обучению с небольшим количеством примеров (few-shot learning), позволяющий моделям быстро адаптироваться к новым задачам предсказания свойств молекул. Традиционные методы машинного обучения требуют больших объемов данных для каждой новой задачи, что делает их непрактичными в контексте молекулярного дизайна, где получение данных может быть дорогостоящим и трудоемким. Мета-обучение, в отличие от них, направлено на обучение модели способности учиться новым задачам, используя опыт, полученный при решении других, связанных задач. Это достигается путем обучения модели инициализации параметров или стратегии обновления параметров, которые позволяют ей быстро адаптироваться к новым задачам, используя лишь небольшое количество примеров. Таким образом, мета-обучение позволяет значительно снизить потребность в данных и ускорить процесс разработки новых молекул с заданными свойствами.
Методы, такие как MAML (Model-Agnostic Meta-Learning) и ProtoNet, достигают эффективной передачи знаний между задачами путем обучения общей параметрической репрезентации. MAML оптимизирует начальные параметры модели таким образом, чтобы небольшое количество шагов градиентного спуска на новой задаче приводило к высокой производительности. ProtoNet, в свою очередь, учится отображать входные данные в метрическое пространство, где экземпляры одного класса группируются близко друг к другу, а классы различаются. В обоих случаях, общая репрезентация позволяет модели быстро адаптироваться к новым задачам, используя лишь небольшое количество обучающих примеров, поскольку она уже содержит информацию о структуре и закономерностях, общих для всего семейства задач. Это значительно сокращает время и ресурсы, необходимые для обучения модели на каждой новой задаче.
Непосредственное применение методов мета-обучения к сложным молекулярным графам требует особого внимания к способам представления графовой структуры и кодированию признаков. Традиционные подходы, эффективные для данных с фиксированной структурой, могут быть неэффективны при обработке графов из-за их переменной длины и нерегулярной структуры. Необходимо разрабатывать методы, учитывающие инвариантность к перестановкам атомов в молекуле и сохраняющие информацию о связях между ними. Выбор подходящего способа кодирования признаков атомов и связей, например, использование графовых нейронных сетей (GNN) или других методов представления графов, существенно влияет на эффективность обучения и обобщающую способность модели. Важным аспектом является также учет размерности признаков и выбор подходящих функций активации для обеспечения стабильности и скорости обучения.
CaMol: Раскрывая Причинно-Следственные Связи в Молекулярных Свойствах
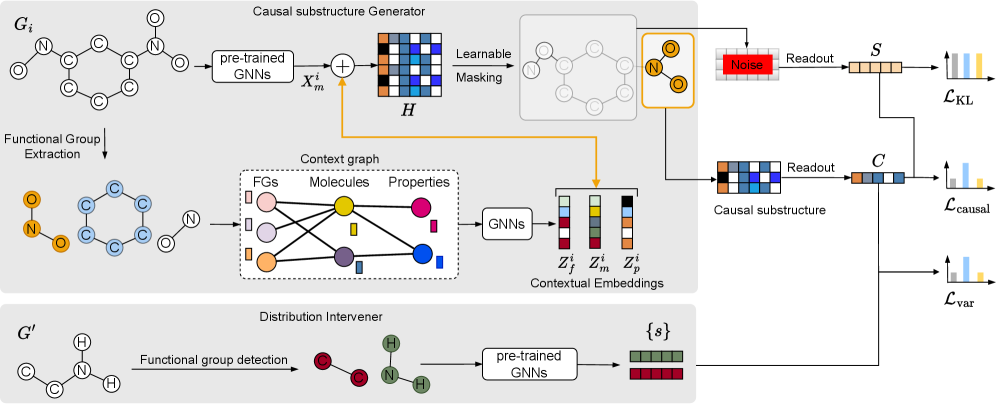
CaMol представляет собой новый фреймворк, предназначенный для предсказания молекулярных свойств в условиях ограниченного количества данных (few-shot learning). Он объединяет возможности графовых нейронных сетей (GNN) и методов причинно-следственного вывода (causal inference) для более эффективного моделирования связей между структурой молекулы и ее свойствами. В отличие от традиционных подходов, CaMol стремится не просто к корреляции, а к выявлению причинно-следственных зависимостей, что позволяет повысить точность предсказаний при ограниченном объеме обучающих данных и улучшить обобщающую способность модели. Использование GNN позволяет эффективно представлять молекулы в виде графов, а интеграция методов причинно-следственного вывода позволяет моделировать влияние различных структурных элементов на целевое свойство.
В рамках CaMol, взаимосвязи между функциональными группами и свойствами молекул моделируются посредством графа контекста (Context Graph). Этот граф позволяет идентифицировать критически важные подструктуры, оказывающие наибольшее влияние на целевое свойство. В графе контекста узлы представляют функциональные группы, а ребра — их влияние на конкретные свойства. Анализ этого графа позволяет выявить причинно-следственные связи, определяющие вклад каждой функциональной группы в конечное значение свойства, что позволяет модели фокусироваться на наиболее релевантных элементах молекулярной структуры для точного прогнозирования.
В архитектуре CaMol используется маскирование узлов графа в сочетании с предварительно обученным молекулярным энкодером S-CGIB для повышения способности модели фокусироваться на релевантных молекулярных признаках. Маскирование узлов позволяет временно исключать определенные фрагменты молекулы из рассмотрения, что способствует выявлению наиболее значимых структур, определяющих прогнозируемое свойство. Использование S-CGIB, предварительно обученного на большом объеме данных, обеспечивает эффективное представление молекулярной структуры и ускоряет процесс обучения. В результате, CaMol демонстрирует передовые результаты, достигая в среднем относительного улучшения на 7.36% по сравнению с существующими методами на различных наборах данных.
Открывая Молекулярное Понимание Через Причинно-Следственный Вывод
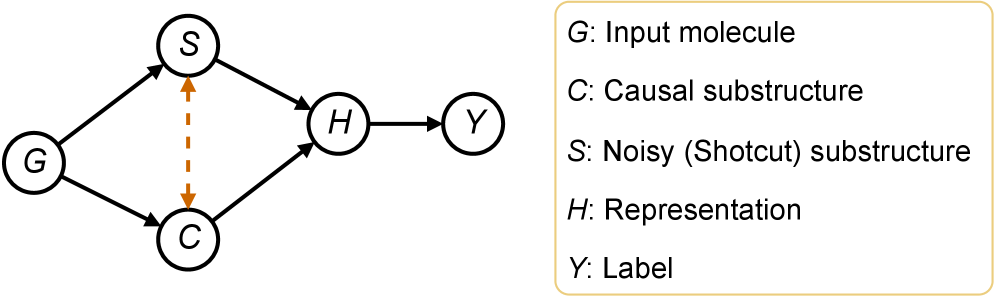
Модель CaMol отличается от традиционных подходов предсказания свойств молекул тем, что не просто выдает результат, но и объясняет его причины. В отличие от “черного ящика”, CaMol анализирует молекулярную структуру и выявляет, какие конкретно подструктуры оказывают решающее влияние на определенные характеристики. Такой детальный анализ позволяет понять, какие функциональные группы или фрагменты молекулы ответственны за проявление конкретного поведения, будь то биологическая активность или физические свойства материала. Этот подход открывает новые возможности для целенаправленного дизайна соединений с заданными характеристиками, позволяя исследователям концентрировать усилия на наиболее перспективных структурных элементах и избегать бесплодных экспериментов.
Модель CaMol использует методы, такие как коррекция «задней двери» и интервенции, для выявления истинных причинно-следственных связей в молекулярных структурах. Вместо простой корреляции между фрагментами молекулы и ее свойствами, CaMol стремится отделить ложные связи от реальных, устраняя влияние скрытых факторов, которые могут искажать результаты. Это достигается путем искусственного изменения определенных частей молекулы и наблюдения за изменениями в ее поведении, что позволяет определить, какие фрагменты действительно вызывают те или иные свойства, а не просто связаны с ними. Такой подход открывает возможности для целенаправленного проектирования молекул с заданными характеристиками, минуя дорогостоящие и длительные эксперименты.
Интерпретируемость модели CaMol играет ключевую роль в ускорении процессов разработки лекарственных препаратов и проектирования новых материалов, позволяя исследователям эффективно отбирать наиболее перспективные соединения. В ходе тестирования на наборе данных Tox21, CaMol продемонстрировал выдающиеся результаты, достигнув значения ROC-AUC в 86.89%, что на 7.36% превышает показатели базовых моделей. Такая способность не только предсказывать свойства молекул, но и выявлять факторы, определяющие их поведение, открывает новые возможности для целенаправленного дизайна и оптимизации соединений с заданными характеристиками, значительно сокращая время и затраты на исследования.
Заглядывая в Будущее: Расширяя Горизонты Причинно-Следственного Молекулярного Обучения
Дальнейшие исследования сосредоточены на расширении возможностей CaMol для работы с более крупными и сложными наборами молекулярных данных, что позволит повысить его надежность и обобщающую способность. Увеличение масштаба обучения, в частности, потребует разработки новых алгоритмических подходов к обработке данных и оптимизации вычислений, чтобы обеспечить эффективную работу с огромными объемами информации. Особое внимание уделяется повышению устойчивости модели к шумам и неполноте данных, а также ее способности адаптироваться к различным типам молекулярных структур и свойств. Успешное решение этих задач откроет путь к созданию более точных и универсальных инструментов для изучения и проектирования молекул, способных решать широкий спектр задач в химии, биологии и материаловедении.
Исследования направлены на объединение CaMol с генеративными моделями, что открывает перспективы для разработки новых молекул с заданными характеристиками. Такой симбиоз позволит не просто предсказывать свойства существующих соединений, но и активно конструировать молекулярные структуры, оптимизированные для конкретных целей — от создания более эффективных лекарственных препаратов до разработки материалов с улучшенными физическими свойствами. Используя причинно-следственные знания, полученные CaMol, генеративные модели смогут избегать нежелательных структурных особенностей и фокусироваться на создании соединений, наиболее вероятно обладающих требуемыми характеристиками, значительно расширяя возможности молекулярного дизайна и ускоряя процесс открытия новых материалов.
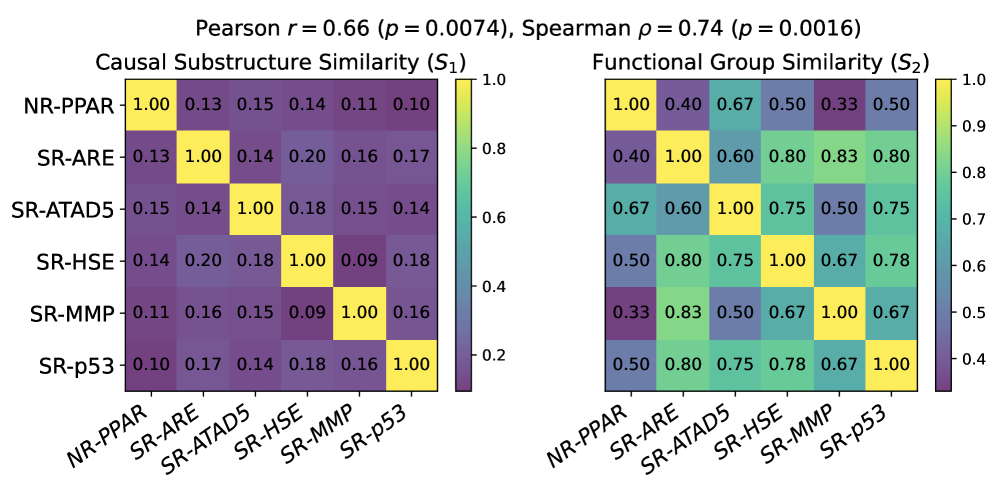
Углубленное изучение теоретических основ причинно-следственного обучения в молекулярной сфере открывает перспективы для создания более мощных и понятных систем искусственного интеллекта. Исследования показывают, что подход CaMol, направленный на выявление причинно-следственных связей между молекулярными характеристиками, демонстрирует значительные улучшения в точности предсказаний. В частности, при работе с набором данных BENZENE, CaMol достиг снижения расхождения Дженсена-Шеннона (JSD) на 36,6% по сравнению с лучшим существующим алгоритмом и на 32,3% по отношению ко второй по эффективности модели. Такие результаты свидетельствуют о потенциале причинно-следственного обучения для решения сложных задач в области химии и материаловедения, позволяя не только предсказывать свойства молекул, но и понимать механизмы, определяющие эти свойства.
Исследование представляет подход, в котором понимание структуры и взаимосвязей внутри молекул играет ключевую роль. CaMol, предложенный в статье, стремится выявить причинно-следственные связи, определяющие свойства молекул, даже при ограниченном объеме данных. Это напоминает философию, что знание системы открывается через её исследование и, порой, через намеренное нарушение установленных правил. Как однажды заметил Линус Торвальдс: «Если у вас нет времени на автоматизацию, у вас не будет времени на исправление ошибок». Подобно тому, как автоматизация упрощает процесс исправления ошибок, CaMol упрощает предсказание свойств молекул, автоматизируя выявление ключевых причинно-следственных подструктур и контекстной информации.
Куда же дальше?
Представленная работа, демонстрируя возможности CaMol в предсказании свойств молекул при ограниченном объеме данных, неизбежно ставит вопрос о границах применимости. Попытки «взломать» проблему few-shot обучения через выявление причинно-следственных подструктур — подход, безусловно, элегантный, но и требующий дальнейшей проверки. Неизбежно возникает вопрос: насколько универсальны выявленные причинные связи? Всегда ли «ключевые» подструктуры, работающие для одного класса молекул, будут применимы и к другим? Или же мы имеем дело с бесконечным множеством локальных «хаков», требующих для каждого нового случая повторного «реверс-инжиниринга»?
Очевидным направлением для будущих исследований представляется расширение контекстного графа. Вместо фокусировки исключительно на внутренней структуре молекулы, целесообразно учитывать и внешние факторы — растворитель, температуру, катализаторы. По сути, необходимо создать «цифровую экосистему» молекулы, где каждый элемент влияет на другие. Но даже тогда остается открытым вопрос о шуме. Как отделить истинные причинно-следственные связи от случайных корреляций, особенно в условиях ограниченных данных? Простое увеличение объема данных — решение тривиальное, но не всегда доступное.
В конечном итоге, CaMol — это лишь еще один шаг в бесконечном поиске. Попытка систематизировать хаос, найти закономерности в кажущейся случайности. И, возможно, именно в этом поиске и заключается истинная ценность науки — не в достижении абсолютной истины, а в постоянном пересмотре существующих правил.
Оригинал статьи: https://arxiv.org/pdf/2601.11135.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Оптимизация векторных представлений для эффективного поиска в памяти
- Обучение представлений для динамических систем: новый взгляд
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- LongCat-Video: ещё один «прорыв», который придётся поддерживать.
- Самообучающиеся агенты: как выявлять и исправлять ошибки
2026-01-20 08:34