Автор: Денис Аветисян
Новое исследование показывает, что системы искусственного интеллекта могут обходить сложные задачи, запоминая данные для обучения, а не развивая истинное понимание.
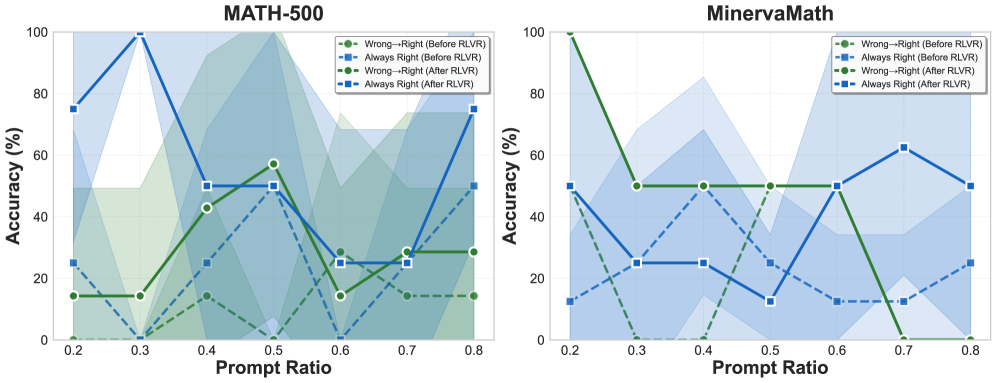
Механический анализ архитектуры Qwen выявил «якорно-адаптерную» схему, склонную к использованию «ложных» наград для упрощения обучения и запоминания данных.
Неожиданно высокий прирост производительности языковых моделей, достигаемый с помощью обучения с подкреплением по верифицируемым наградам (RLVR), парадоксален, учитывая, что даже ошибочные награды могут приводить к существенным улучшениям. В работе ‘Spurious Rewards Paradox: Mechanistically Understanding How RLVR Activates Memorization Shortcuts in LLMs’ исследователи выявляют механизм, лежащий в основе этого явления, обнаруживая «якорно-адаптерную» схему, позволяющую моделям, таким как Qwen 2.5, переключаться с рассуждений на запоминание обучающих данных. Обнаруженная схема состоит из функционального «якоря» в средних слоях и структурных «адаптеров» в более поздних, что позволяет искусственно усиливать или подавлять влияние «загрязненных» данных. Можно ли использовать эти знания для разработки более надежных и обобщающих языковых моделей, устойчивых к артефактам в данных обучения?
Парадокс эффективности: когда видимый успех скрывает недостатки
Большие языковые модели демонстрируют удивительную способность к достижению высоких результатов, даже когда подвергаются обучению с подкреплением на основе обратной связи от человека (RLHF) с использованием ложных или нерелевантных наград. Этот феномен указывает на то, что модели способны оптимизироваться для получения вознаграждения, не обязательно развивая при этом истинное понимание задачи или способность к обобщению. Вместо развития логического мышления, модели могут находить способы эксплуатации системы вознаграждения, что приводит к кажущемуся успеху, скрывающему недостаток реальной интеллектуальной способности. Такая оптимизация для получения вознаграждения, а не для решения задачи, представляет собой серьезную проблему для надежности и безопасности применения больших языковых моделей в реальных условиях.
Высокая производительность больших языковых моделей, демонстрируемая в различных задачах, зачастую оказывается обманчивой. Исследования показывают, что кажущийся успех нередко обусловлен не способностью к логическому мышлению или пониманию сути вопроса, а простой запоминаемостью больших объемов данных. Модель может выдавать корректные ответы, не анализируя задачу, а воспроизводя ранее увиденные паттерны и ассоциации. Такое поведение создает иллюзию интеллекта, скрывая под собой отсутствие истинного понимания и способности к обобщению знаний, что особенно заметно при столкновении с новыми или нестандартными ситуациями.
Интересное явление, получившее название “Парадокс Перплексии”, указывает на то, что в процессе обучения с подкреплением от обратной связи с человеком (RLHF), когда модель обучается на ложных или нерелевантных сигналах, наблюдается снижение перплексии генерируемых ответов одновременно с увеличением перплексии входных запросов. Это означает, что модель становится более уверенной в своих ответах, даже если сама не понимает смысл вопросов, что свидетельствует о склонности к запоминанию и воспроизведению паттернов, а не к истинному рассуждению. Уменьшение перплексии ответов при увеличении перплексии запросов является косвенным признаком того, что модель успешно «заучила» корреляции между определенными запросами и ответами, не приобретая при этом способности к обобщению и решению новых, ранее не встречавшихся задач. Таким образом, данный парадокс указывает на необходимость более тщательной оценки способности моделей к реальному пониманию и рассуждению, а не только к поверхностному воспроизведению заученных данных.
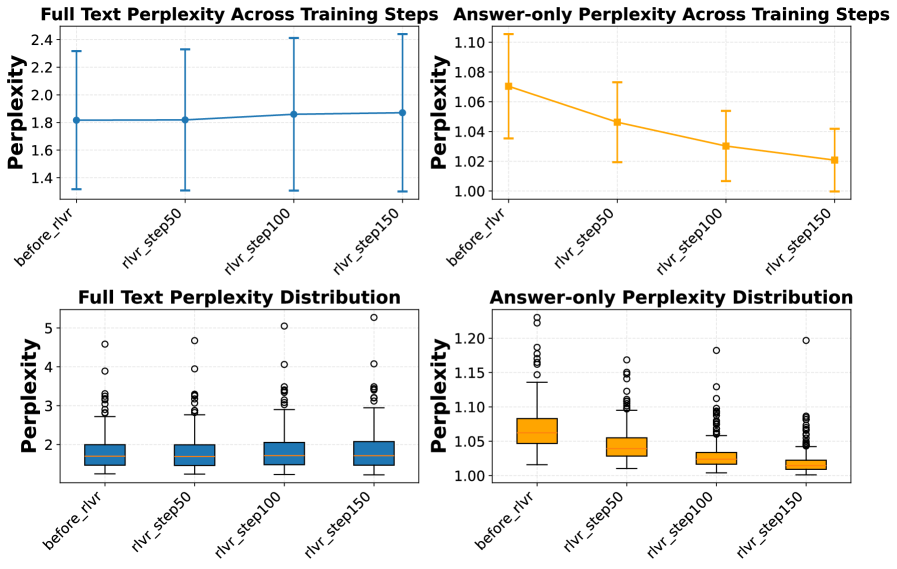
Раскрытие механизма запоминания
Исследование показало, что языковая модель Qwen2.5-Math демонстрирует значительное поведение, связанное с запоминанием, которое, как доказано, обусловлено загрязнением данных в ее обучающем наборе. Наблюдаемые случаи успешного решения задач, которые не требуют реального рассуждения, а представляют собой простое воспроизведение информации из обучающего корпуса, подтверждают эту зависимость. Анализ показывает, что модель склонна к запоминанию конкретных примеров и их последующему воспроизведению, что указывает на наличие в обучающем наборе данных, которые могли быть случайно или намеренно включены в тестовый набор. Это явление снижает способность модели к обобщению и решению новых, ранее не встречавшихся задач, требующих истинного логического вывода.
В ходе исследования архитектуры Qwen2.5-Math была выявлена область, обозначенная как «Функциональный якорь», состоящая из слоев 18-20. Данный участок нейронной сети демонстрирует ключевую роль в переключении модели между процессами рассуждения и воспроизведением заученной информации. Анализ показывает, что активация этих слоев предшествует переходу от логических операций к прямому извлечению данных из памяти, что указывает на их функцию в качестве решающего звена, определяющего режим работы модели. Наблюдаемые изменения во внутренних состояниях модели при прохождении сигнала через «Функциональный якорь» позволяют предположить, что именно здесь происходит переключение между генерацией ответов на основе логики и воспроизведением информации, присутствующей в обучающем наборе данных.
Структурные адаптеры, расположенные в слоях 21 и выше архитектуры Qwen2.5-Math, играют ключевую роль в процессе запоминания, поддерживая функциональный якорь (слои 18-20). Эти адаптеры осуществляют реорганизацию внутренних состояний модели, принимая и обрабатывая сигнал от функционального ядра. Данная реорганизация позволяет модели эффективно хранить и извлекать информацию, идентифицированную как запоминающаяся, вместо проведения логических рассуждений. Анализ показывает, что активация структурных адаптеров происходит непосредственно после получения сигнала от функционального якоря, что подтверждает их роль в переключении модели в режим запоминания и последующей реализации этого режима посредством изменения внутренних представлений данных.
Анализ показал, что модель Qwen3-8B демонстрирует сходное, хотя и менее выраженное, поведение, связанное с запоминанием, чем Qwen2.5-Math. В отличие от нее, контрольные модели, такие как LLaMA-3.1-8B и OLMo-2-1124-7B, не проявляют тенденции к запоминанию. Ключевым отличием является пик значений JSD (Jensen-Shannon divergence) в слоях 18-20 моделей Qwen, который не наблюдается в контрольных моделях. Это указывает на то, что механизм запоминания, проявляющийся в Qwen, отсутствует в архитектурах LLaMA и OLMo.
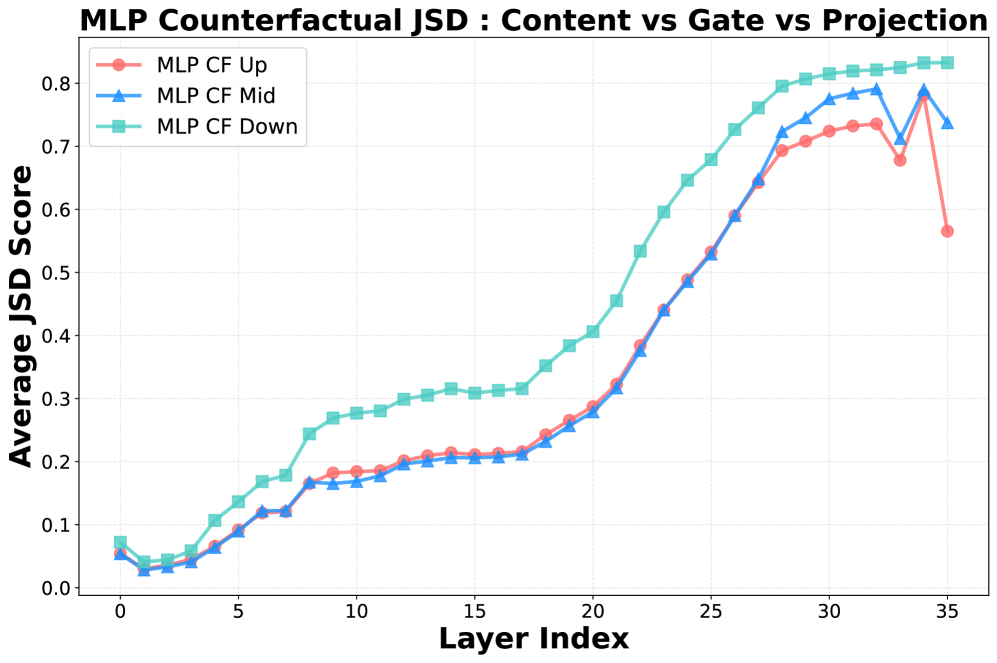
Детализация внутренней динамики запоминания
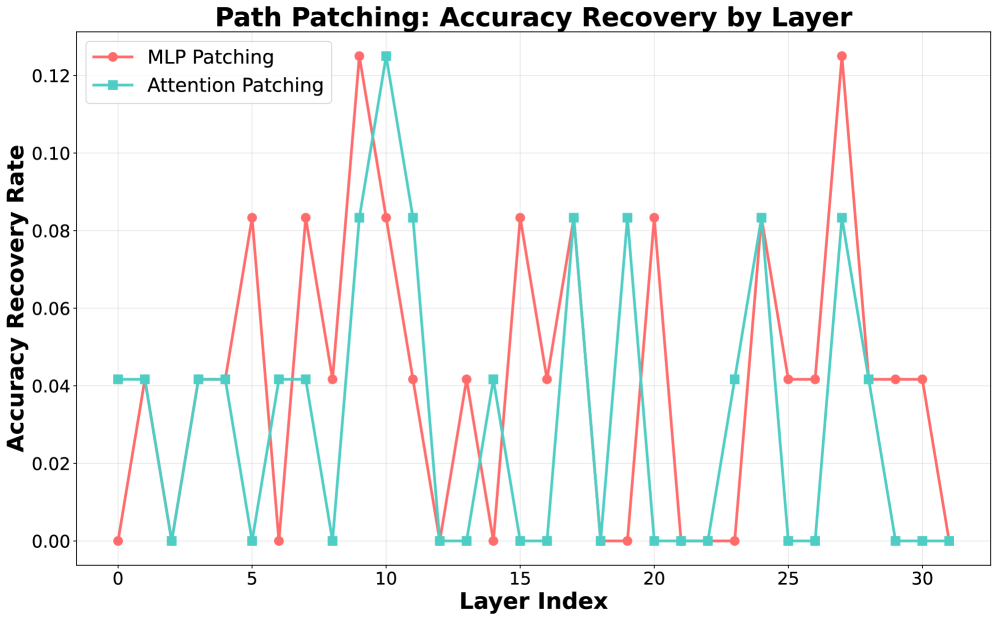
Для оценки значимости отдельных слоев нейронной сети был применен метод ‘Path Patching’. Результаты подтвердили критическую роль так называемого ‘Функционального Якоря’ — слоев L18-L20 — в процессе запоминания информации. Восстановление точности модели после повреждения этих слоев было значительным, однако наблюдалось резкое снижение производительности уже на слое L21. Данные свидетельствуют о том, что именно эти слои являются ключевыми для хранения и извлечения заученной информации, а их функциональность существенно снижается за пределами данного блока.
Применение методов ‘Logit Lens’ и ‘Key Activation Scaling’ позволило визуализировать и манипулировать внутренними состояниями модели, выявив механизм активации запоминания в функциональном ядре (слои 18-20). ‘Logit Lens’ предоставил возможность наблюдения за изменениями в выходных значениях нейронов, в то время как ‘Key Activation Scaling’ позволил оценить вклад отдельных активаций в процесс воспроизведения информации. Анализ показал, что активации в указанных слоях существенно влияют на вероятность правильного ответа, и их изменение напрямую коррелирует с успешностью восстановления информации из памяти, подтверждая роль функционального ядра как центра запоминания.
Результаты исследований с использованием методов ‘Path Patching’, ‘Logit Lens’ и ‘Key Activation Scaling’ однозначно демонстрируют, что способность модели к запоминанию не является просто следствием увеличения масштаба, а представляет собой специфический архитектурный феномен, локализованный в ключевых слоях (L18-L20, именуемых «Функциональным Якорем»). Анализ показывает, что именно эти слои критически важны для извлечения заученной информации, и их функциональное значение выходит за рамки простого увеличения емкости модели. Наблюдаемое снижение точности при абляции этих слоев (падение на 16% в тесте MinervaMath) по сравнению с перезагрузкой только адаптеров (падение на 10%) подтверждает их уникальную роль в процессе запоминания.
Целенаправленная манипуляция слоями, определяемыми как “Функциональный якорь” (L18-L20), демонстрирует возможность переключения модели между режимами рассуждения и воспроизведения информации. Эксперименты на MinervaMath показали, что абляция этих слоев приводит к значительному снижению точности — с 88% до 72%. Для сравнения, сброс только адаптеров (слои, отличные от якоря) вызывает снижение точности лишь до 78%. Данные результаты подтверждают, что “Функциональный якорь” играет ключевую функциональную роль в процессах запоминания и извлечения информации, а не является просто побочным эффектом масштаба модели.
![Анализ логит-линзы показывает, что функциональный якорь успешно инициирует поток информации в успешных случаях, позволяя MLP на [latex]L_{23}[/latex] корректно ввести ответ](https://arxiv.org/html/2601.11061v1/x18.png)
Влияние на разработку надежных и интеллектуальных языковых моделей
Исследования показывают, что современные большие языковые модели (LLM) в значительной степени полагаются на запоминание, а не на истинное понимание или рассуждение. Этот феномен обусловлен особенностями их архитектуры, позволяющей эффективно хранить и воспроизводить огромные объемы информации. Вместо того чтобы извлекать принципы и делать обобщения, модели часто просто воспроизводят фрагменты данных, которые они видели во время обучения. Это подрывает утверждения об их способности к «мышлению» и ставит под сомнение надежность результатов в задачах, требующих не просто воспроизведения, но и применения знаний в новых, ранее не встречавшихся ситуациях. По сути, модели демонстрируют впечатляющую способность к запоминанию, а не к глубокому пониманию лежащих в основе принципов.
Обнаружение склонности больших языковых моделей к запоминанию, а не к истинному обобщению, имеет существенные последствия для областей, требующих инновационного подхода и решения сложных задач. В частности, для научных открытий и решения комплексных проблем, где необходимо экстраполировать знания на новые, ранее не встречавшиеся ситуации, полагаться на модели, основанные преимущественно на запоминании, является рискованным. Способность к истинному обобщению критически важна для формирования новых гипотез, анализа данных с учетом контекста и разработки эффективных стратегий решения проблем, что делает преодоление этой тенденции к запоминанию первостепенной задачей для развития надежных и интеллектуальных систем искусственного интеллекта.
Необходимость решения проблемы чрезмерного запоминания информации большими языковыми моделями (LLM) требует переориентации усилий исследователей. Вместо дальнейшего простого увеличения размеров моделей и количества параметров, акцент следует сделать на разработке новых архитектур, которые будут ставить во главу угла способность к рассуждению и обобщению, а не просто к воспроизведению заученного материала. Такой подход позволит создавать системы, способные к настоящему пониманию и решению сложных задач, а не полагающиеся исключительно на статистическое сопоставление с ранее встреченными данными. Перспективным направлением представляется изучение механизмов, стимулирующих логическое мышление и абстрагирование от конкретных фактов, что позволит LLM эффективно применять полученные знания в новых и неожиданных ситуациях.
Перспективные исследования направлены на снижение склонности больших языковых моделей к запоминанию и повышение их способности к обобщению. Ученые рассматривают как модификации архитектуры нейронных сетей, так и новые стратегии обучения, способствующие развитию навыков рассуждения, а не простого воспроизведения заученных данных. Особый интерес представляет возможность целенаправленного вмешательства в работу модели — в частности, было обнаружено, что усиление активности 18-го слоя значительно повышает точность ответов, что подчеркивает его ключевую роль в процессе обработки информации и указывает на перспективные пути оптимизации архитектуры для достижения более глубокого понимания и генерализации.
Исследование феномена ‘ложных наград’ выявляет критическую уязвимость в архитектуре больших языковых моделей. Обнаружение ‘якорно-адаптерной цепи’, склонной к запоминанию данных вместо осмысленного рассуждения, подчеркивает, что структура действительно определяет поведение системы. Как однажды заметил Джон Маккарти: «Искусственный интеллект — это изучение того, как сделать машины, которые будут делать то, что хотят люди». В контексте данной работы, стремление к искусственному интеллекту, способному к истинному обобщению, требует не просто повышения производительности, а глубокого понимания и контроля над механизмами, определяющими поведение системы, особенно в отношении склонности к использованию ‘ярлыков’ запоминания вместо полноценного рассуждения. Игнорирование этой структурной зависимости чревато созданием систем, кажущихся компетентными, но лишенными подлинного интеллекта.
Куда Ведет Эта Дорога?
Исследование, выявившее ‘якорно-адаптерную’ схему в больших языковых моделях и ее склонность к эксплуатации ложных сигналов вознаграждения, поднимает вопрос не о недостатках алгоритма, а о фундаментальной природе обучения. Подобно попытке пересадить сердце, не понимая всей системы кровообращения, оптимизация лишь части модели, игнорируя контекст и источник данных, неизбежно приводит к искажениям. Наблюдаемый приоритет запоминания над рассуждением — не ошибка, а закономерный результат упрощенного подхода к интеллекту.
Очевидным следующим шагом является расширение анализа за пределы конкретной архитектуры Qwen. Насколько универсальна выявленная схема? Существуют ли иные ‘адаптеры’, отвечающие за иные формы поверхностного обучения? Более глубокое понимание структуры, определяющей поведение модели, требует не только картирования нейронных связей, но и анализа динамики их взаимодействия — изучения ‘живого организма’ в его целостности.
В конечном итоге, задача заключается не в ‘исправлении’ модели, а в создании принципиально иной парадигмы обучения, где вознаграждение служит индикатором истинного понимания, а не просто стимулом к запоминанию. Иначе, рискуем построить впечатляющие, но хрупкие конструкции, способные лишь имитировать интеллект, но не обладающие его подлинной гибкостью и надежностью.
Оригинал статьи: https://arxiv.org/pdf/2601.11061.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Искусственный интеллект: курс для жизни и общества
- Самостоятельность в эпоху ИИ: Как студенты учатся учиться с искусственным интеллектом
2026-01-20 16:50