Автор: Денис Аветисян
Новое исследование оценивает, насколько современные модели поиска, управляемые инструкциями, способны поддерживать пользователей в процессе открытий и исследования новых тем.
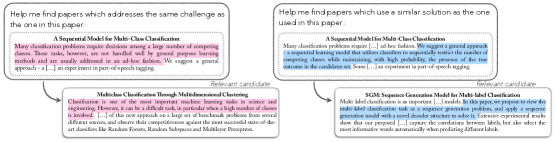
Оценка эффективности моделей, обученных следовать инструкциям, в задачах исследовательского поиска, выявила улучшения в релевантности ранжирования, но и недостатки в точности следования указаниям и чувствительности к нюансам запросов.
Поиск информации, особенно исследовательский, часто затруднен нечетко сформулированными запросами и меняющимися потребностями пользователя. В данной работе, посвященной исследованию ‘Can Instructed Retrieval Models Really Support Exploration?’, оценивается эффективность моделей извлечения информации, ориентированных на следование инструкциям, в контексте аспекно-зависимого исследовательского поиска. Полученные результаты демонстрируют улучшение релевантности ранжирования при использовании таких моделей, однако, способность точно интерпретировать инструкции и адаптироваться к нюансам запроса остается недостаточно развитой. Действительно ли текущие модели способны обеспечить полноценную поддержку длительных исследовательских сессий, требующих высокой чувствительности к инструкциям пользователя?
Поиск в Эпоху Неопределенности: Вызовы и Перспективы
Традиционные поисковые системы часто оказываются неэффективными в ситуациях, когда пользователь лишь начинает изучение темы и не имеет четко сформулированного запроса. В подобных сценариях, известных как исследовательский поиск, требуется не просто найти документы, соответствующие ключевым словам, а помочь пользователю сформировать общее представление о предметной области. Обычно, стандартные алгоритмы, ориентированные на точное соответствие запросу, выдают ограниченный набор результатов, не способствуя расширению кругозора и выявлению взаимосвязей между различными аспектами темы. Это особенно актуально в областях, где пользователь не является экспертом и нуждается в помощи для навигации по сложному информационному пространству, стремясь к более глубокому и всестороннему пониманию.
Эффективный исследовательский поиск требует адаптации моделей извлечения информации для понимания намерений пользователя, выходящих за рамки простых ключевых слов, что обуславливает необходимость более тонкого подхода. Традиционные системы часто ориентируются исключительно на соответствие запроса и документов по заданным терминам, игнорируя скрытые смыслы и контекст, которые важны для формирования общей картины. Современные исследования направлены на разработку моделей, способных улавливать нюансы запроса, определять его широкую тематику и предлагать релевантные документы, даже если они не содержат точных ключевых слов. Такой подход позволяет пользователю постепенно уточнять свои потребности и расширять свои знания в интересующей области, не ограничиваясь узким кругом результатов, соответствующих буквальному тексту запроса. В результате, поиск становится не просто извлечением информации, а процессом исследования и открытия новых знаний.
Существующие методы информационного поиска зачастую неспособны в полной мере использовать контекстную информацию, содержащуюся в исходных документах, что значительно ограничивает возможности эффективной навигации по информационному пространству. Вместо глубокого анализа семантических связей и тематической близости, многие системы ограничиваются поверхностным сопоставлением ключевых слов, игнорируя нюансы и скрытые смыслы. Это приводит к тому, что результаты поиска оказываются недостаточно релевантными и не позволяют пользователю быстро и эффективно расширить свои знания по интересующей теме. Неспособность извлекать и использовать контекст из начальных документов особенно критична в ситуациях, когда пользователь сам не может четко сформулировать запрос и нуждается в направленной помощи в исследовании новой области знаний.
В условиях современной информационной перегрузки, когда объемы данных растут экспоненциально, потребность в гибких и адаптивных методах поиска становится особенно актуальной. Пользователи, сталкиваясь со сложными и многогранными задачами, часто не могут сформулировать четкие запросы, и традиционные поисковые системы, ориентированные на ключевые слова, оказываются неэффективными. Адаптивные методы, способные учитывать контекст, намерения пользователя и эволюционировать в процессе взаимодействия с информацией, позволяют эффективно ориентироваться в сложных информационных ландшафтах, открывая новые возможности для исследований, обучения и принятия обоснованных решений. Способность системы не просто находить документы по запросу, а предлагать релевантный контент, расширять область поиска и учитывать изменяющиеся потребности пользователя, является ключевым фактором успешного информационного поиска в эпоху больших данных.
Инструктируемый Поиск: Новый Взгляд на Интеллектуальные Системы
Инструктируемые поисковые системы (Instructed Retrievers) представляют собой решение для повышения точности поиска за счет включения в процесс обработки естественных языковых инструкций. Вместо простого сопоставления ключевых слов, эти системы используют возможности больших языковых моделей (LLM) для интерпретации пользовательского запроса, сформулированного в виде инструкции, и уточнения результатов поиска в соответствии с подразумеваемым намерением пользователя. Это позволяет не только находить документы, содержащие конкретные термины, но и учитывать контекст и смысл запроса, обеспечивая более релевантные и полезные результаты поиска.
Модели, использующие подход Instructed Retrieval, применяют большие языковые модели (LLM) для обработки инструкций на естественном языке и соответствующей адаптации стратегий поиска информации. LLM анализирует предоставленные инструкции, определяя ключевые аспекты запроса и релевантные критерии отбора документов. На основе этого анализа, модель динамически корректирует процесс поиска, изменяя параметры ранжирования, расширяя или сужая область поиска, и применяя фильтры для более точного соответствия между запросом пользователя и извлекаемым контентом. Данный подход позволяет учитывать не только ключевые слова, но и семантическое значение запроса, а также контекст, что значительно повышает качество и релевантность результатов поиска.
Для оптимизации ранжирования, основанного на больших языковых моделях (LLM), используются методы, такие как промптинг с парным ранжированием. Этот подход предполагает предоставление LLM пар документов и инструкции выбрать наиболее релевантный для заданного запроса. Множество таких пар формируют обучающий набор, который позволяет модели научиться оценивать релевантность документов на основе сравнения. В процессе обучения LLM корректирует свои параметры, чтобы максимизировать вероятность выбора более релевантного документа в каждой паре, тем самым улучшая качество ранжирования поисковой выдачи. Эффективность данного метода заключается в возможности обучения LLM непосредственно на данных о предпочтениях пользователей, выраженных через сравнение релевантности документов.
Инструктируемые системы поиска (Instructed Retrievers) решают проблему несоответствия между информационными потребностями пользователя и содержанием документов за счет явного предоставления инструкций, определяющих критерии релевантности. Вместо неявного сопоставления запроса и документов, пользователь формулирует задачу, указывая, какие аспекты документа наиболее важны для ответа на вопрос. Это позволяет системе более точно интерпретировать намерение пользователя и отбирать документы, максимально соответствующие заданным требованиям, значительно повышая эффективность поиска и качество предоставляемой информации. Фактически, это смещение акцента от простого поиска по ключевым словам к пониманию смысла запроса.
Оценка Инструкций: Набор Данных CSFCube
Набор данных CSFCube представляет собой надежный эталон для оценки систем поиска по инструкциям в сценариях разведочного поиска. Он состоит из запросов и связанных с ними документов, а также инструкций, определяющих определенные аспекты, которые модель должна учитывать при ранжировании результатов. CSFCube разработан для оценки способности модели следовать этим инструкциям, выходя за рамки стандартной релевантности поиска. Набор данных включает в себя разнообразные типы инструкций и предоставляет метрики для количественной оценки как релевантности ранжирования, так и способности следовать инструкциям, что позволяет проводить всестороннюю оценку систем поиска по инструкциям в условиях, требующих от модели адаптации к конкретным требованиям пользователя.
Набор данных CSFCube позволяет оценить, насколько точно модели следуют инструкциям, касающимся конкретных аспектов запроса или исходного документа. Оценка проводится путем формулирования инструкций, направленных на акцентирование внимания модели на определенных частях информации, например, определение ключевых терминов, перефразирование запроса с учетом конкретного аспекта или выбор только тех документов, которые соответствуют заданному критерию. Анализ результатов позволяет определить, способна ли модель не только находить релевантную информацию, но и интерпретировать и применять заданные инструкции для уточнения процесса поиска и повышения точности отбора документов.
Для количественной оценки релевантности ранжирования и способности модели следовать инструкциям в наборе данных CSFCube используются метрики NDCG@20 и p-MRR. Однако, наблюдается непоследовательность в представлении улучшений, выраженных через NDCG@20, в различных результатах исследований. Это означает, что хотя увеличение значения NDCG@20 может указывать на повышение качества ранжирования, величина этого улучшения не всегда стандартизирована или четко определена в разных экспериментах, что затрудняет прямое сравнение эффективности различных моделей и стратегий.
Для оценки адаптивности моделей при следовании инструкциям в CSFCube используются различные типы инструкций: определения, перефразировки и выделение аспектов. Результаты показывают, что стратегия выделения аспектов демонстрирует наилучшее следование инструкциям, однако приводит к снижению релевантности ранжирования. В то же время, использование общих инструкций (без конкретизации) приводит к значениям p-MRR, близким к нулю, что свидетельствует об отсутствии реакции модели на инструкции и, фактически, о её игнорировании.
Современные Модели и Аспектно-Ориентированный Поиск
Современные модели поиска информации, такие как Specter2, SciNCL и otAspire, демонстрируют значительный прогресс в области извлечения релевантных данных. В отличие от традиционных методов, эти модели способны учитывать семантическое значение запроса и контекст информации, что позволяет им достигать более высоких показателей точности, особенно в специализированных областях знаний. Specter2, например, оптимизирован для работы с научными текстами, SciNCL — для поиска в медицинских базах данных, а otAspire фокусируется на аспектах запроса, обеспечивая более точное соответствие между запросом пользователя и извлекаемой информацией. Подобные разработки открывают новые возможности для создания интеллектуальных систем поиска, способных эффективно решать сложные информационные задачи и предоставлять пользователям наиболее релевантные результаты.
Поиск, ориентированный на аспекты, представляет собой усовершенствованную методику, позволяющую значительно повысить точность результатов за счет концентрации на релевантных характеристиках запроса. Вместо обработки запроса как единого целого, модели, такие как otAspire, выделяют ключевые аспекты, позволяя системе находить информацию, наиболее точно соответствующую конкретным потребностям пользователя. Этот подход особенно полезен при работе со сложными запросами, требующими учета различных контекстов и нюансов, и позволяет получать более целевые и полезные результаты по сравнению с традиционными методами поиска.
Мощные большие языковые модели, такие как GritLM-7B и gpt-4o, демонстрируют значительный потенциал в области поисковых систем с инструкциями, позволяя формулировать запросы на естественном языке и получать релевантные результаты. Несмотря на то, что эти модели способны понимать сложные инструкции и адаптировать поиск под конкретные потребности, количественная оценка улучшения качества поиска, выраженная через метрику NDCG@20, остается непоследовательной. Хотя в некоторых случаях наблюдается повышение точности, единой и надежной закономерности, подтверждающей существенное превосходство этих моделей по сравнению с традиционными подходами, не выявлено. Это подчеркивает необходимость дальнейших исследований для более точной оценки преимуществ и оптимизации больших языковых моделей в контексте поисковых систем.
Несмотря на достигнутый прогресс в области поиска информации, объединение передовых моделей, таких как Specter2 и otAspire, с аспектуальным поиском не всегда приводит к ожидаемому улучшению качества результатов. Анализ показывает, что многие модели демонстрируют нелогичное или нечувствительное к инструкциям поведение. Показатель p-MRR, оценивающий релевантность найденных результатов, в ряде случаев колеблется от отрицательных значений до приблизительно 0.2, что указывает на существенные ограничения в способности моделей точно интерпретировать запросы и предоставлять соответствующие ответы, даже при использовании сложных методов поиска и учёте аспектов запроса.
Исследование показывает, что, несмотря на улучшения в ранжировании релевантности, инструктивные извлекатели всё ещё испытывают трудности с последовательным выполнением инструкций, особенно когда они требуют нюансированного подхода. Это подтверждает идею о том, что структура определяет поведение системы: если инструкции нечеткие или противоречивые, результат будет непредсказуемым. Брайан Керниган однажды заметил: «Простота — это высшая степень изысканности». Это особенно верно в контексте поисковых систем; сложность, скрывающаяся за инструкциями, может сделать систему хрупкой и неэффективной. Авторы статьи, исследуя CSFCube, как способ оценить аспекты поисковых запросов, демонстрируют, что истинная эффективность заключается не в количестве функций, а в их ясности и согласованности.
Куда Ведет Исследование?
Представленная работа выявляет любопытный парадокс: улучшение ранжирования релевантности при использовании управляемого поиска информации не гарантирует последовательного следования инструкциям. Каждое новое ограничение, каждая добавленная зависимость от лингвистических указаний, несет в себе скрытую цену свободы — сужение пространства поиска, снижение чувствительности к тонким нюансам запроса. Это напоминает попытку управления сложным организмом, где вмешательство в одну систему неизбежно влияет на все остальные.
Будущие исследования должны сосредоточиться не только на совершенствовании алгоритмов, но и на понимании границ применимости лингвистических инструкций. Особенно важно исследовать, как структурированные запросы, подобные представлению CSFCube, влияют на способность системы к исследованию, а не только к извлечению заранее известных фактов. Необходимо разработать метрики, способные оценивать не просто релевантность, а истинную исследовательскую ценность найденной информации.
В конечном счете, вопрос заключается не в том, насколько хорошо система выполняет инструкции, а в том, насколько она способна к самостоятельному обучению и адаптации. Элегантный дизайн поисковой системы рождается из простоты и ясности, но истинная сила проявляется в ее способности к непредсказуемым открытиям, к выходу за рамки заданных параметров.
Оригинал статьи: https://arxiv.org/pdf/2601.10936.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Устойчивое обучение языковых моделей: новый подход к контролю стратегии
- Сердце музыки: открытые модели для создания композиций
- Квантовый усилитель света на чипе: новый уровень эффективности
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Взгляд под капот: Анализ кода, сгенерированного нейросетями
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Искусственный интеллект: курс для жизни и общества
- Самостоятельность в эпоху ИИ: Как студенты учатся учиться с искусственным интеллектом
2026-01-20 18:28