Автор: Денис Аветисян
Исследователи предлагают инновационный метод восстановления информации, основанный на использовании парных автоэнкодеров для решения сложных задач, связанных с неполными или поврежденными данными.
В статье представлен метод латентного пространства, использующий парные автоэнкодеры для эффективной реконструкции данных и улучшения решения обратных задач.
Несмотря на успехи современных методов решения обратных задач, несогласованность и неполнота наблюдательных данных часто приводят к неточным результатам. В данной работе, озаглавленной ‘Latent Space Inference via Paired Autoencoders’, предложен новый подход к построению скрытых пространств, основанный на использовании парных автокодировщиков для эффективной реконструкции данных и повышения точности решения обратных задач. Ключевой особенностью является возможность согласованной оптимизации в низкоразмерных информативных пространствах, что позволяет преодолеть ограничения, связанные с зашумленностью и неполнотой данных. Какие перспективы открываются для применения предложенного подхода в различных областях науки и техники, где актуальны задачи восстановления информации и параметрической идентификации?
Обратные задачи: Эхо скрытых причин
Во многих областях науки и техники постоянно возникает необходимость в решении обратных задач — определении причин, лежащих в основе наблюдаемых эффектов. Этот подход лежит в основе широкого спектра приложений, от медицинской диагностики, где по результатам сканирования необходимо восстановить изображение внутренних органов, до геофизических исследований, где по сейсмическим данным изучается структура недр Земли. В астрономии, например, обратные задачи используются для реконструкции изображений далеких галактик по данным, полученным телескопами. Инженеры используют их при разработке новых материалов, определяя свойства вещества по измеренным характеристикам. Суть этих задач заключается в том, чтобы, зная результаты какого-либо процесса, восстановить исходные условия или параметры, которые привели к этим результатам. Успешное решение обратных задач позволяет не только понять происходящие явления, но и предсказывать их развитие, что крайне важно для принятия обоснованных решений в различных сферах деятельности.
Обратные задачи часто характеризуются так называемой “некорректностью” (ill-posedness), что означает, что решение может быть неустойчивым или вовсе отсутствовать без применения специальных методов обработки. Это связано с тем, что небольшие изменения во входных данных — например, шум или погрешности измерений — могут приводить к существенным изменениям в полученном решении. Иными словами, задача не удовлетворяет основным требованиям благополучности решения: существованию, единственности и устойчивости. Для преодоления этой проблемы используются различные регуляризационные техники и методы стабилизации, направленные на получение физически правдоподобного и надежного результата, несмотря на неполноту или зашумленность исходной информации. В конечном итоге, корректное решение обратной задачи требует не просто математического формализма, но и глубокого понимания физической природы исследуемого процесса.
Процесс решения обратных задач существенно усложняется наличием шумов и неполнотой данных. Даже незначительные погрешности в измерениях или отсутствие части информации могут привести к значительным искажениям в получаемых результатах и нестабильности решения. Поэтому для надежного вывода причин из наблюдаемых эффектов необходимы устойчивые методы, способные эффективно фильтровать шумы и компенсировать недостающие данные. Разработка таких методов является ключевой задачей в различных областях науки и техники, от медицинской диагностики и геофизических исследований до обработки изображений и машинного обучения. Использование регуляризации, статистического моделирования и методов оптимизации позволяет получить более точные и надежные оценки параметров, даже в условиях высокой неопределенности.

Глубокое обучение: Архитектура предвидения
Глубокое обучение представляет собой эффективный подход к решению обратных задач, основанный на обучении сложным отображениям из наблюдаемых данных. В отличие от традиционных методов, требующих явного определения и решения прямой задачи, глубокие нейронные сети способны самостоятельно выучивать связь между входными данными и искомым решением. Этот процесс обучения осуществляется на больших объемах данных, позволяя сети аппроксимировать сложные нелинейные функции, описывающие взаимосвязь между наблюдениями и параметрами искомой модели или решения. Эффективность данного подхода особенно проявляется в задачах, где аналитическое решение прямой задачи затруднено или невозможно, а доступ к большому объему данных позволяет сети обобщать полученные знания и предсказывать решения для новых, ранее не встречавшихся случаев.
В основе глубокого обучения лежат архитектуры нейронных сетей, среди которых особое место занимают автоэнкодеры. Автоэнкодеры представляют собой тип нейронной сети, предназначенный для обучения эффективным представлениям данных. Они состоят из кодировщика, который сжимает входные данные в латентное пространство, и декодировщика, который реконструирует исходные данные из этого представления. Процесс обучения заставляет сеть извлекать наиболее значимые характеристики данных, формируя компактное и информативное представление, пригодное для последующего анализа и решения различных задач, таких как снижение размерности, обнаружение аномалий и генерация новых данных. x \rightarrow Encoder \rightarrow z \rightarrow Decoder \rightarrow \hat{x}, где x — входные данные, z — латентное представление, \hat{x} — реконструированные данные.
Обучение “сквозным выводом” (End-to-End Inference) позволяет нейронной сети напрямую изучать соответствие между входными данными и желаемым результатом, минуя необходимость в явном определении и формулировке промежуточных этапов решения задачи. Вместо того, чтобы разбивать проблему на отдельные подзадачи и разрабатывать алгоритмы для каждой из них, сеть самостоятельно извлекает необходимые признаки и устанавливает связи, оптимизируя процесс преобразования входных данных в выходные. Это особенно эффективно в задачах, где традиционные алгоритмические подходы требуют значительных усилий по проектированию и настройке, а также в случаях, когда явное описание промежуточных этапов затруднено или невозможно.

Paired Autoencoders: Гармония модели и наблюдения
Архитектуры Paired Autoencoder (PAE) основываются на обучении парных отображений между пространством наблюдений и параметрами модели. В отличие от традиционных автокодировщиков, которые стремятся реконструировать входные данные, PAE одновременно обучают отображение от наблюдений к параметрам модели и обратно. Это обеспечивает более стабильное обучение, поскольку изменения в пространстве наблюдений напрямую отражаются в параметрах модели и наоборот. Такой подход позволяет модели адаптироваться к изменениям в данных, сохраняя при этом согласованность между наблюдениями и соответствующими параметрами. Использование парных отображений эффективно снижает вероятность расхождения модели и повышает её устойчивость к шумам и неполным данным.
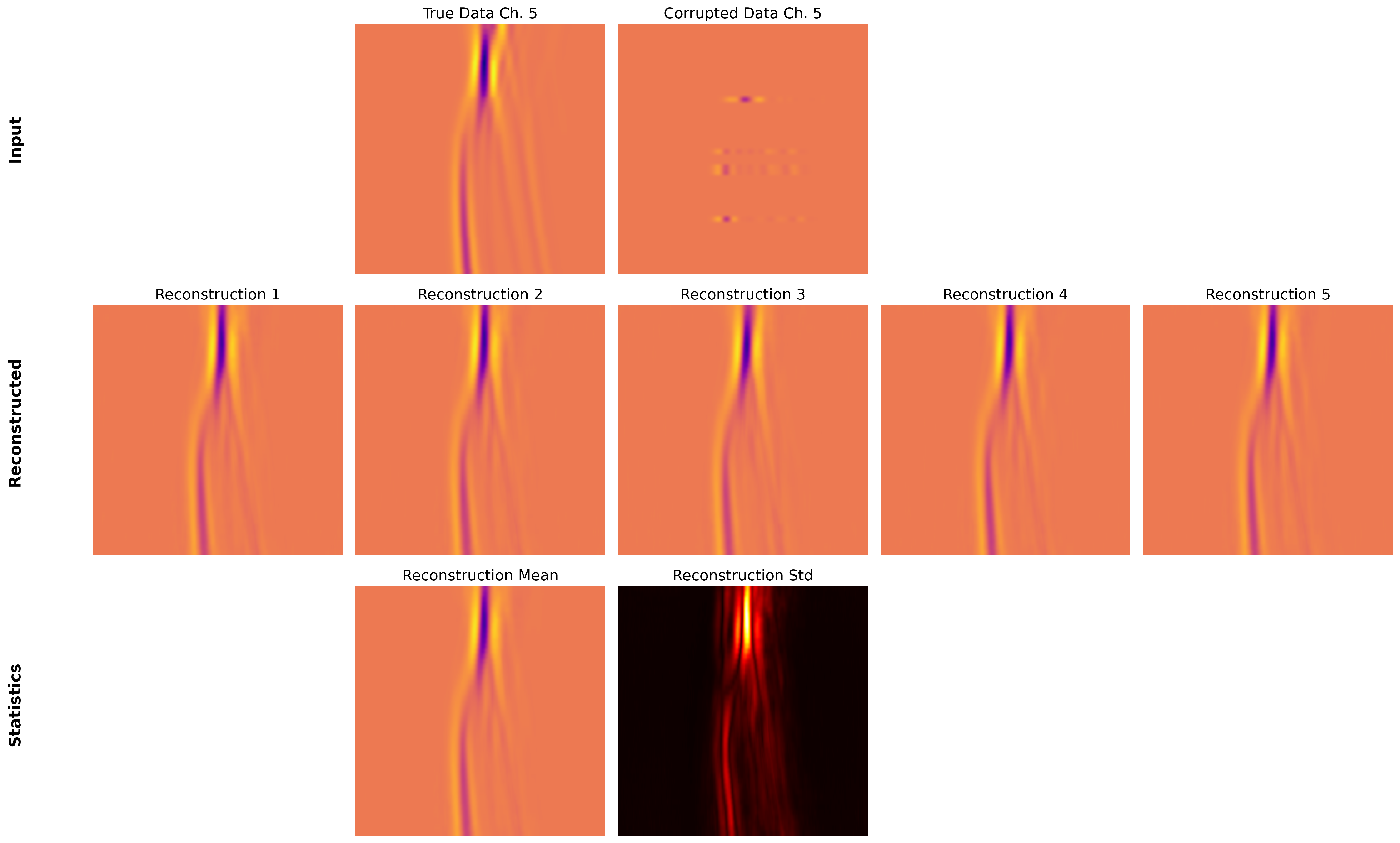
В архитектуре Paired Autoencoder, процесс LatentSpaceInference обеспечивает эффективное восстановление данных и количественную оценку неопределенности. Восстановление происходит за счет декодирования вектора из латентного пространства, что позволяет получить приближение исходных данных. Оценка неопределенности достигается путем анализа распределения в латентном пространстве; дисперсия в латентном представлении коррелирует с уровнем неопределенности при восстановлении. Это позволяет не только реконструировать данные, но и оценить достоверность реконструированного результата, что критически важно для приложений, требующих надежности и предсказуемости, например, в задачах прогнозирования и принятия решений. Использование p(z|x) для моделирования распределения латентных переменных позволяет получить вероятностную оценку неопределенности.
Вариационные автокодировщики (VAE) улучшают представление латентного пространства, моделируя вероятностное распределение над потенциальными решениями. Вместо кодирования входных данных в единственную точку в латентном пространстве, VAE кодируют их в параметры вероятностного распределения, обычно гауссовского. Это позволяет учитывать неопределенность и вариативность в данных, генерируя разнообразные и правдоподобные реконструкции. p(z|x) = N(\mu(x), \sigma^2(x)), где z — латентная переменная, x — входные данные, \mu(x) и \sigma^2(x) — среднее и дисперсия, вычисляемые нейронной сетью-кодировщиком. При генерации новых данных, сэмплирование из этого распределения позволяет получить различные правдоподобные решения, что делает VAE эффективными для задач генерации и обучения с подкреплением.
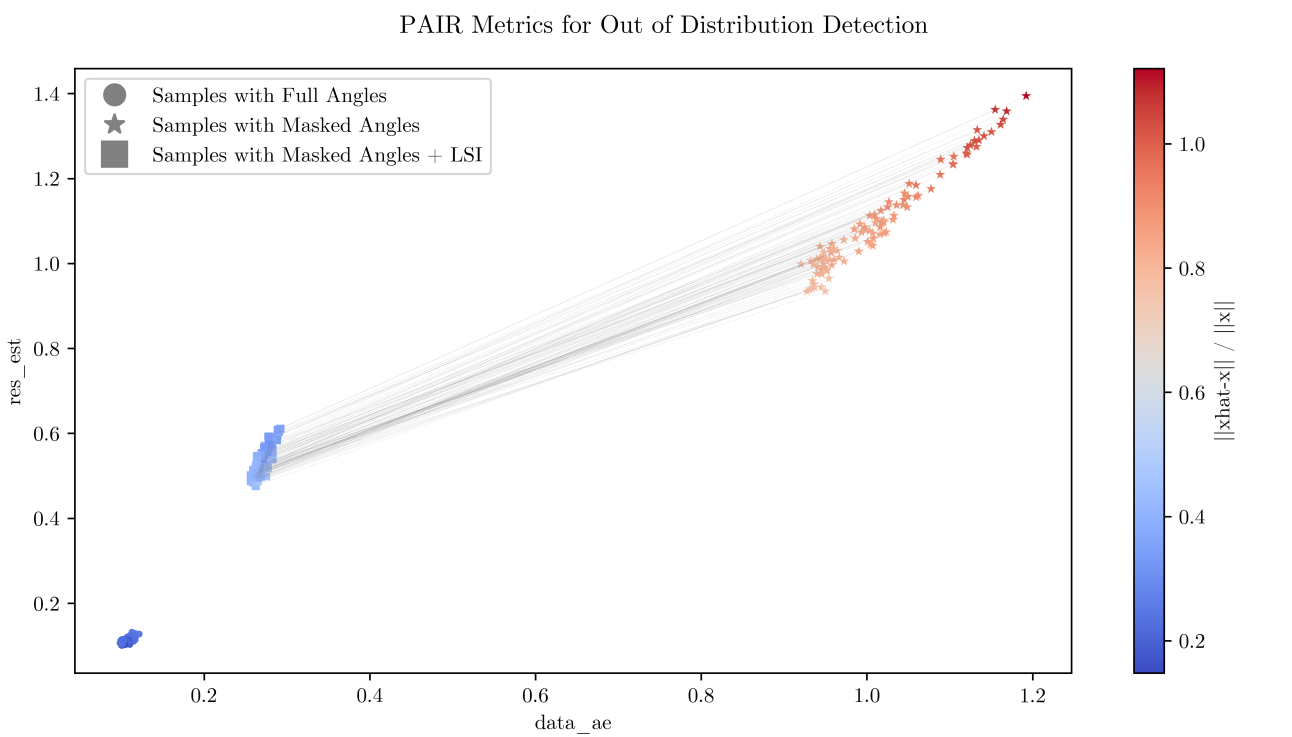
Воздействие и перспективы: Эхо в реальном мире
Данный подход находит непосредственное применение в решении важнейших обратных задач, в частности, в компьютерной томографии (КТ). Благодаря оптимизации алгоритмов реконструкции изображений, становится возможным значительно ускорить процесс диагностики и повысить её точность. Это достигается за счёт более эффективной обработки данных, полученных от томографа, что позволяет получать более четкие и детализированные изображения внутренних органов и тканей. В результате, врачи получают возможность быстрее и точнее ставить диагнозы, что критически важно для успешного лечения пациентов и повышения качества медицинской помощи. Применение данного подхода в КТ открывает новые перспективы для ранней диагностики заболеваний и персонализированной медицины.
Метод сейсмической инверсии получает значительное улучшение благодаря повышенной устойчивости предлагаемого подхода. Это позволяет создавать более четкие и детализированные изображения подповерхностных структур, что критически важно для эффективного поиска и разработки природных ресурсов. Улучшенная устойчивость снижает влияние шумов и погрешностей данных, обеспечивая более надежную интерпретацию сейсмической информации и, как следствие, более точное определение местоположения и объема залежей нефти, газа и других полезных ископаемых. Таким образом, данная разработка способствует оптимизации процессов геологоразведки и повышению экономической эффективности проектов в нефтегазовой отрасли.
В рамках данного подхода особое внимание уделяется не только реконструкции решения, но и оценке сопутствующей неопределенности. Интегрированные статистические методы позволяют получить не просто итоговый результат, но и надежные оценки погрешностей, что критически важно для принятия обоснованных решений. Применение статистического анализа, включающего, например, расчет доверительных интервалов и дисперсионный анализ, предоставляет пользователю информацию о вероятности получения корректного ответа и позволяет оценить риски, связанные с использованием реконструированного решения. Это особенно актуально в областях, где точность и надежность данных имеют первостепенное значение, таких как медицинская диагностика и геологоразведка, обеспечивая более уверенное и обоснованное принятие решений на основе полученных результатов.
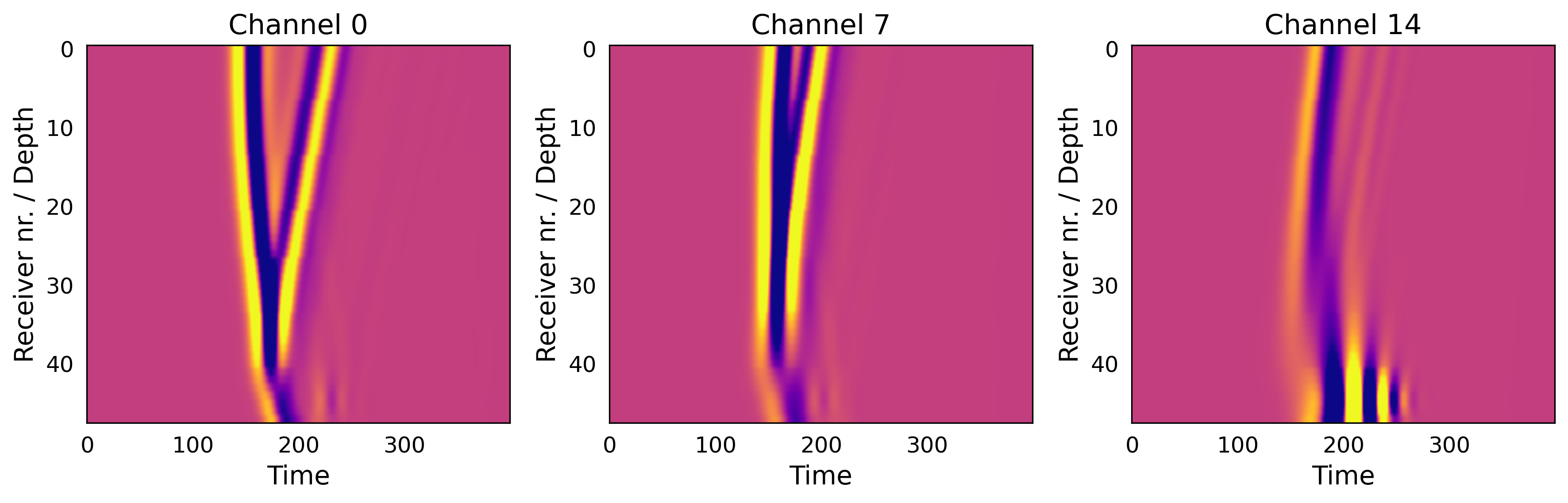
Работа демонстрирует, что попытки построить идеальную систему для реконструкции данных обречены на провал. Вместо этого, предлагаемый подход с использованием парных автоэнкодеров признает неотъемлемую неопределенность обратных задач. Он фокусируется не на абсолютной точности, а на эффективном исследовании латентного пространства для нахождения наиболее вероятного решения. Как однажды заметил Алан Тьюринг: «Нельзя ожидать, что машина мыслит, если мы не можем научить ее ошибаться». Данное исследование подтверждает эту мысль, показывая, что признание и управление ошибками — ключевой аспект в создании надежных систем для работы с неполными или поврежденными данными. Попытки обойти проблему неполноты данных приводят к уязвимым конструкциям, а адаптация к ней — к устойчивым экосистемам.
Что Дальше?
Предложенный подход, использующий парные автоэнкодеры для вывода в латентном пространстве, лишь слегка отодвигает неизбежное. Система, безусловно, улучшает реконструкцию данных и решение обратных задач, но каждая новая архитектура — это лишь более изощрённый способ отсрочить столкновение с фундаментальной неопределённостью. Она разделяет проблему, но не судьбу. Чем сложнее модель, тем более элегантно она провалится, когда реальность не совпадёт с её предположениями.
Очевидно, что дальнейшее увеличение сложности автоэнкодеров не приведёт к прорыву. Вместо этого, необходимо признать, что само понятие «реконструкции» иллюзорно. Данные всегда неполны, всегда зашумлены, всегда искажены. Будущие исследования должны сосредоточиться не на попытках восстановить утраченное, а на разработке систем, способных функционировать в условиях принципиальной неопределённости, извлекая полезные сигналы из хаоса, а не стремясь к недостижимому совершенству.
В конечном итоге, всё взаимосвязано, и всё, что связано, рано или поздно рухнет синхронно. Поэтому, вместо того чтобы строить всё более сложные сети, стоит задуматься о создании систем, способных к самовосстановлению и адаптации, систем, которые не стремятся к контролю над неопределённостью, а принимают её как неотъемлемую часть реальности.
Оригинал статьи: https://arxiv.org/pdf/2601.11397.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Оптимизация векторных представлений для эффективного поиска в памяти
- Обучение представлений для динамических систем: новый взгляд
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- 💸 Великобритания тратит 500 миллионов фунтов стерлингов на квантовые технологии – может быть, кот Шрёдингера только что разбогател?
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- LongCat-Video: ещё один «прорыв», который придётся поддерживать.
- Самообучающиеся агенты: как выявлять и исправлять ошибки
2026-01-20 22:00