Автор: Денис Аветисян
В статье представлен всесторонний обзор методов кластеризации данных высокой размерности, исследующих баланс между обобщением и сохранением информации.
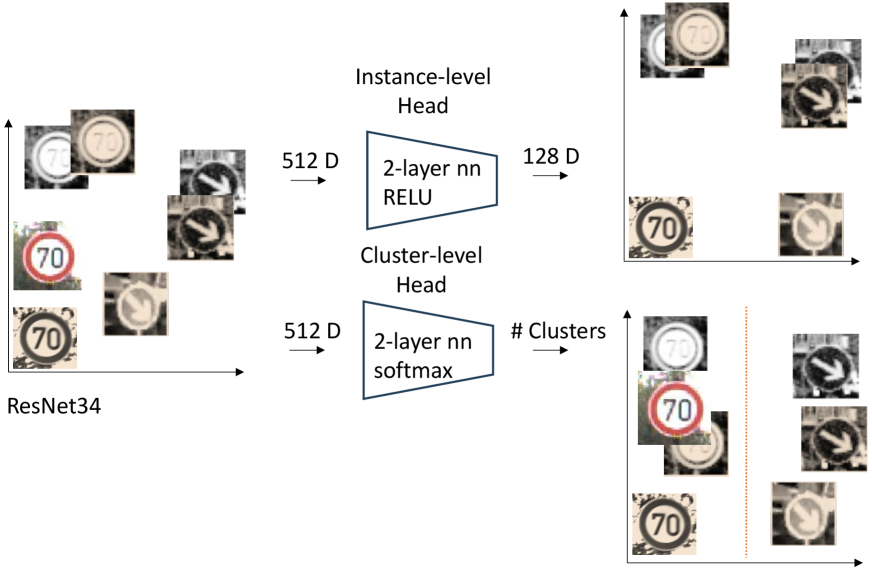
Обзор классических, подпространственных и глубоких методов кластеризации с акцентом на компромисс между абстракцией и репрезентацией данных.
Поиск естественной группировки в больших объемах данных представляет собой сложную задачу, требующую баланса между обобщением и детализацией. Учебное пособие ‘Clustering High-dimensional Data: Balancing Abstraction and Representation Tutorial at AAAI 2026’ посвящено исследованию этого компромисса, рассматривая как классические, так и современные методы кластеризации, включая подпространственную и глубокую кластеризацию. Основная идея заключается в том, что эффективная кластеризация требует одновременного абстрагирования от несущественных деталей и сохранения репрезентативных признаков, отличающих группы объектов. Сможем ли мы создать алгоритмы, которые автоматически определят оптимальный баланс между обобщением и детализацией, повышая эффективность, энергоэффективность и интерпретируемость методов кластеризации?
Проклятие Размерности и Ранние Трудности Кластеризации
Высокоразмерные данные представляют собой серьезную проблему для традиционных алгоритмов кластеризации, таких как K-Means, из-за явления, известного как «проклятие размерности». Суть этого явления заключается в том, что с увеличением числа измерений, пространство данных становится всё более разреженным. Это приводит к тому, что расстояния между точками становятся более однородными, затрудняя выделение значимых кластеров. В результате, алгоритмы, основанные на измерении расстояний, теряют свою эффективность, а результаты кластеризации становятся менее надежными и интерпретируемыми. По мере роста размерности, объём пространства экспоненциально увеличивается, в то время как плотность данных уменьшается, что делает поиск близких соседей и формирование компактных кластеров крайне затруднительным.
В условиях высокой размерности данных, традиционные алгоритмы кластеризации, такие как K-Means, сталкиваются с существенными трудностями. Пространство признаков становится разреженным, что затрудняет выявление истинных групп объектов и приводит к снижению эффективности. Исследования показали, что в таких условиях, базовый показатель Normalized Mutual Information (NMI) для K-Means составляет всего 0.28, что свидетельствует о низкой надежности результатов и необходимости разработки более устойчивых методов анализа данных. Этот показатель наглядно демонстрирует, что простое применение стандартных алгоритмов в пространствах высокой размерности может приводить к ошибочным выводам и неверной интерпретации данных.
Оценка качества сформированных кластеров в многомерных данных требует применения специализированных метрик, таких как Нормализованная Взаимная Информация (NMI). Данная метрика позволяет количественно оценить степень соответствия между полученными кластерами и истинной структурой данных, что особенно важно при работе с высокоразмерными пространствами, где традиционные подходы часто демонстрируют низкую эффективность. Низкие значения NMI, наблюдаемые при использовании простых алгоритмов кластеризации в таких условиях, подчеркивают необходимость разработки более устойчивых и адаптивных методов, способных эффективно выделять значимые кластеры и обеспечивать надежные результаты анализа.

Уменьшение Сложности: Роль Снижения Размерности
Методы снижения размерности, такие как анализ главных компонент (PCA), решают проблемы, возникающие при работе с данными высокой размерности, посредством преобразования исходного пространства признаков в пространство меньшей размерности. Этот процесс достигается путем выявления и сохранения наиболее значимых направлений (компонент) в данных, которые объясняют наибольшую дисперсию. В результате, данные представляются в виде линейной комбинации этих главных компонент, что позволяет уменьшить вычислительную сложность, визуализировать данные и избежать «проклятия размерности», возникающего при обучении моделей машинного обучения на данных с большим количеством признаков. Выбор количества главных компонент, сохраняемых в процессе преобразования, определяет баланс между сохранением информации и уменьшением размерности.
Методы понижения размерности, такие как PCA, особенно полезны в задачах кластеризации подпространств. В отличие от традиционной кластеризации, где поиск производится во всем многомерном пространстве, кластеризация подпространств концентрируется на выявлении кластеров внутри конкретных подмножеств признаков (подпространств) исходных данных. Это позволяет обнаруживать кластеры, которые могут быть скрыты в общем пространстве из-за влияния нерелевантных или шумовых признаков, и повышает точность кластеризации в ситуациях, когда значимые закономерности проявляются только в определенных комбинациях признаков. Такой подход особенно эффективен при работе с данными высокой размерности, где не все признаки одинаково важны для определения кластерной структуры.
Применение алгоритма K-Means к латентному пространству, полученному с помощью автокодировщика, позволило достичь значения Normalized Mutual Information (NMI) равного 0.56. Этот показатель демонстрирует умеренное улучшение результатов по сравнению с исходным базовым уровнем, что подтверждает эффективность применения методов понижения размерности для повышения качества кластеризации, хотя и не гарантирует существенного скачка производительности. Значение NMI указывает на степень взаимосвязи между предсказанными и фактическими кластерами, при этом 0.56 свидетельствует о наличии некоторой, но не сильной, корреляции.
Абстракция, в контексте анализа данных, представляет собой обобщение принципов понижения размерности, выходящее за рамки простого уменьшения количества признаков. Она заключается в целенаправленном выделении и фокусировке на наиболее релевантной информации, необходимой для решения конкретной задачи. В отличие от автоматических методов понижения размерности, абстракция предполагает предварительное понимание предметной области и определение критериев значимости признаков. Это позволяет не только снизить вычислительную сложность, но и улучшить интерпретируемость модели, отфильтровав шум и сконцентрировавшись на ключевых аспектах данных, что повышает эффективность последующего анализа и принятия решений.
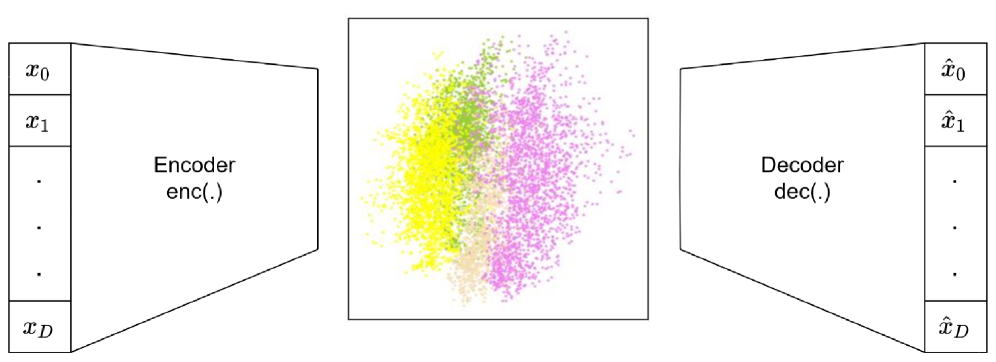
Глубокое Кластеризование: Обучение Представлений и Кластеризация
Глубокое кластеризование использует возможности глубоких нейронных сетей, таких как автокодировщики, для обучения эффективным представлениям данных, захватывающим существенные признаки, необходимые для последующей кластеризации. В отличие от традиционных методов, требующих ручного создания признаков, глубокие нейронные сети автоматически извлекают иерархические представления из исходных данных. Автокодировщики, в частности, обучаются реконструировать входные данные, что заставляет их изучать сжатые и информативные представления в скрытом слое. Эти представления, полученные в результате обучения, затем используются в качестве входных данных для алгоритмов кластеризации, что позволяет более точно идентифицировать группы схожих объектов.
Контрастное обучение представлений (Contrastive Representation Learning) улучшает качество полученных представлений данных путем обучения модели различать схожие и несхожие точки данных. В основе этого подхода лежит идея максимизации различий между представлениями различных экземпляров и минимизации различий между представлениями схожих экземпляров. Методы, такие как CC (Contrastive Clustering), используют функцию потерь, основанную на контрасте, для формирования представлений, которые эффективно разделяют кластеры в пространстве признаков. Это позволяет более точно идентифицировать структуры в данных и повысить эффективность последующих алгоритмов кластеризации.
Результаты экспериментов с алгоритмами глубокого кластеризования демонстрируют повышение эффективности подхода. В частности, метод DEC достиг значения Normalized Mutual Information (NMI) в 0.58, а усовершенствованный алгоритм IDEC показал результат в 0.60. Данные показатели свидетельствуют о том, что использование глубоких нейронных сетей для обучения представлений данных способствует улучшению качества кластеризации по сравнению с традиционными методами, где NMI обычно колеблется в диапазоне 0.4-0.5 для сложных датасетов.
Полученные в результате обучения представления данных, сформированные глубокими нейронными сетями, используются в качестве входных данных для различных алгоритмов кластеризации. Это позволяет значительно повысить эффективность и точность идентификации кластеров по сравнению с традиционными методами, использующими исходные признаки данных. Использование обученных представлений позволяет алгоритмам кластеризации лучше различать закономерности и структуру в данных, что приводит к более осмысленным и надежным результатам кластеризации. В частности, такие алгоритмы, как K-means или DBSCAN, демонстрируют улучшенные показатели производительности при работе с представлениями, полученными с помощью автоэнкодеров или контрастивного обучения.
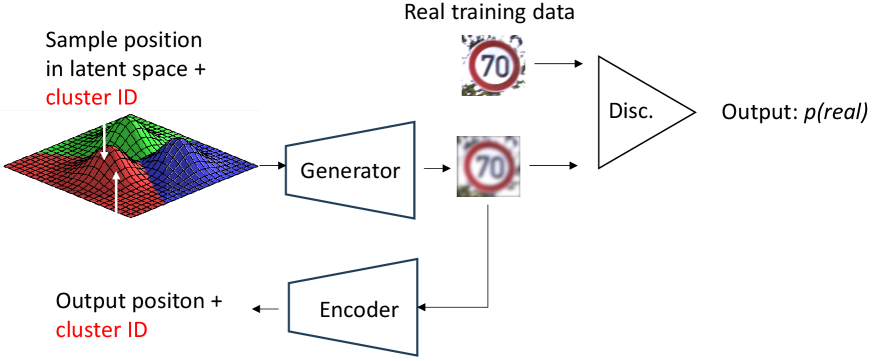
Продвинутые Методы Глубокого Кластеризования: За Пределами Базовых Подходов
Методы глубокого кластеризования на основе центроидов, такие как DEC и IDEC, используют подход, при котором экземпляры одного и того же кластера стремятся к расположению вблизи центроида этого кластера в пространстве признаков. Это достигается за счет использования функций потерь, штрафующих отклонение экземпляров от центроида, что способствует более четкому разделению кластеров. Такой подход позволяет алгоритму автоматически находить компактные и хорошо различимые группы данных, минимизируя внутриклассовую дисперсию и максимизируя межклассовое расстояние. Эффективность данного метода обусловлена тем, что центроиды служат точками притяжения для экземпляров, принадлежащих к соответствующим кластерам, упрощая процесс выделения и категоризации данных.
Иерархическая глубокая кластеризация, представленная алгоритмом DeepECT, строит древовидную структуру кластеров, позволяя исследовать различные уровни детализации данных. В отличие от плоских методов кластеризации, иерархический подход позволяет пользователю выбирать подходящий уровень гранулярности, балансируя между абстракцией и представлением данных. Построение иерархии осуществляется путем последовательного объединения или разделения кластеров на основе определенных критериев, что обеспечивает более гибкий и интерпретируемый результат по сравнению с методами, выдающими фиксированное количество кластеров.
Метод DeepECT продемонстрировал значительное улучшение в задачах кластеризации, достигнув показателя Normalized Mutual Information (NMI) в 0.80 на стандартном наборе данных German Traffic Sign Benchmark. Данный результат превосходит существующие аналоги и подтверждает, что DeepECT является передовым решением для задач кластеризации изображений дорожных знаков. Показатель NMI измеряет сходство между кластерами, полученными алгоритмом, и истинными метками классов, при этом значение 0.80 указывает на высокую степень соответствия и эффективность метода в разделении данных на корректные группы.
Генеративные подходы, такие как ClusterGAN и VaDE, используют генеративные состязательные сети (GAN) для одновременного обучения представлений данных и назначения кластеров. В отличие от традиционных методов кластеризации, требующих предварительно определенных признаков, GAN позволяют автоматически извлекать наиболее релевантные признаки из данных. ClusterGAN, например, использует дискриминатор для различения сгенерированных кластеров от реальных, что способствует формированию более четких и компактных кластеров. VaDE (Variational Deep Embedding) объединяет вариационный автоэнкодер с алгоритмом кластеризации, позволяя находить кластеры в скрытом пространстве представлений, что особенно эффективно для работы со сложными и многомерными наборами данных.

Будущее Кластеризации: Интеллектуальный Анализ Данных
Современные алгоритмы кластеризации переживают значительный прогресс благодаря синергии трех ключевых направлений. Методы понижения размерности, такие как PCA и t-SNE, позволяют уменьшить вычислительную сложность и визуализировать данные в более удобном формате. Параллельно, обучение представлений, использующее глубокие нейронные сети, автоматически извлекает наиболее информативные признаки из исходных данных, что существенно повышает качество кластеризации. Наконец, усовершенствованные методы глубокой кластеризации, интегрирующие обучение представлений непосредственно в процесс кластеризации, позволяют достичь более высокой точности и эффективности по сравнению с традиционными подходами. Сочетание этих технологий открывает новые возможности для анализа больших и сложных наборов данных, позволяя выявлять скрытые закономерности и структуры с беспрецедентной точностью.
Современные достижения в области алгоритмов кластеризации открывают широкие возможности для применения в различных сферах. В частности, в области распознавания изображений, усовершенствованные методы позволяют автоматически группировать и классифицировать визуальные данные с беспрецедентной точностью, что критически важно для систем видеонаблюдения и автономного транспорта. В сфере обнаружения аномалий, эти алгоритмы способны выявлять необычные паттерны в данных, сигнализирующие о мошенничестве, сбоях в работе оборудования или других нештатных ситуациях. Не менее значимо применение в сегментации клиентской базы, где кластеризация позволяет выявлять группы клиентов со схожими характеристиками и потребностями, что позволяет компаниям разрабатывать более эффективные маркетинговые стратегии и персонализированные предложения.
Перспективные исследования в области глубинного кластеризования, вероятно, будут сосредоточены на создании более устойчивых и масштабируемых методов, способных эффективно обрабатывать большие и сложные наборы данных. Особое внимание уделяется интеграции экспертных знаний в процесс кластеризации — внедрение предварительных представлений о структуре данных и специфике предметной области может значительно повысить точность и интерпретируемость результатов. Это предполагает разработку гибридных подходов, сочетающих возможности глубокого обучения с традиционными алгоритмами кластеризации и методами представления знаний, что позволит адаптировать алгоритмы к конкретным задачам и получать более осмысленные кластеры, отвечающие потребностям аналитиков и специалистов в различных областях.
Исследование кластеризации высокоразмерных данных неизбежно сталкивается с дилеммой: как сохранить информативность, упрощая сложность? Авторы статьи мастерски демонстрируют этот баланс между абстракцией и представлением, рассматривая как классические, так и современные методы. Этот подход напоминает слова Клода Шеннона: «Информация — это мера того, что мы не знаем». Ведь суть кластеризации — выявление скрытых закономерностей в потоке данных, уменьшение неопределенности. Статья, подобно тщательному реверс-инжинирингу, разбирает различные алгоритмы, чтобы понять, как эффективно извлечь суть из многомерного пространства, уменьшая шум и выделяя значимые признаки.
Что дальше?
Рассмотренный обзор кластеризации многомерных данных выявляет не столько завершенные задачи, сколько тщательно замаскированные вопросы. Постоянное стремление к абстракции, к сжатию информации, неизбежно наталкивается на проблему репрезентации — что именно теряется в этом процессе, и можно ли восстановить утраченное, не изобретя новый уровень сложности? Классические, подпространственные и глубокие методы кластеризации, несмотря на свои достижения, остаются зависимыми от предположений о структуре данных, которые часто оказываются ложными. Возникает ощущение, что поиск «идеального» алгоритма — это попытка навязать порядок хаосу, а не выявить его внутреннюю логику.
Стоит задуматься: а что, если «шум» в многомерных данных — это не ошибка, а сигнал о скрытых взаимосвязях, которые не укладываются в привычные модели? Упор на автоматическое обучение, на «черные ящики» глубоких нейронных сетей, может приводить к игнорированию тонких, но важных закономерностей. Возможно, будущее кластеризации лежит не в создании более сложных алгоритмов, а в разработке инструментов, позволяющих человеку более эффективно взаимодействовать с данными, выявлять аномалии и строить собственные интерпретации.
В конечном счете, кластеризация — это не просто задача машинного обучения, а попытка понять мир, в котором мы живем. И в этом смысле, она всегда будет оставаться открытой проблемой, требующей постоянного переосмысления и критического анализа. Ведь правила существуют, чтобы их проверять.
Оригинал статьи: https://arxiv.org/pdf/2601.11160.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Вариационные и полувариационные неравенства: от теории к практике
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Искусственный интеллект, который ищет сам: новая стратегия обучения
- Нейросети на сопротивляющейся памяти: ускорение вычислений с помощью квантования
- Языковой аналитик: Автоматизация лингвистических задач с помощью искусственного интеллекта
- Реалистичные изображения в реальном времени: новый подход к улучшению графики
2026-01-20 23:49