Автор: Денис Аветисян
Ученые представили масштабный набор данных и методику оценки, позволяющие проверить, насколько хорошо современные системы искусственного интеллекта могут находить и связывать доказательства в сложных научных текстах.
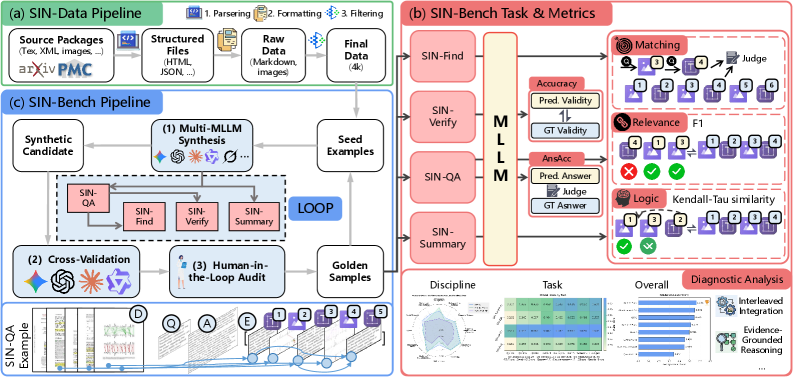
Представлен SIN-Bench — эталонный набор данных для оценки возможностей мультимодальных больших языковых моделей в построении цепочек доказательств, основанных на анализе длинных научных документов.
Оценка способности мультимодальных больших языковых моделей к глубокому пониманию научных текстов остается сложной задачей, поскольку существующие метрики часто вознаграждают простое совпадение ответов, не требуя построения логичной цепочки доказательств. В настоящей работе, представленной в исследовании ‘SIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature’, предложен новый подход и датасет SIN-Bench, предназначенные для оценки способности моделей к построению проверяемых цепочек доказательств в длинных научных текстах, включающих как текст, так и изображения. Эксперименты показали, что основным ограничением является способность моделей к обоснованию своих ответов, при этом Gemini-3-pro демонстрирует лучшие общие результаты, а GPT-5 — более высокую точность ответов, но уступает в способности к построению логичных цепочек доказательств. Сможем ли мы создать модели, способные не только находить ответы, но и убедительно обосновывать их, опираясь на фактические данные из научных публикаций?
Взлом Контекста: Вызов Научному Пониманию
Традиционные модели обработки естественного языка сталкиваются с серьезными трудностями при анализе научной литературы из-за её сложности и объёма. Научные тексты часто характеризуются длинными предложениями, специализированной терминологией и обилием мультимодальных данных — графиков, таблиц, диаграмм и формул E=mc^2. Эффективная обработка таких документов требует не просто извлечения информации, но и способности к её синтезу и пониманию в контексте сложных взаимосвязей. Ограничения существующих алгоритмов в плане обработки длинных последовательностей и интеграции различных типов данных существенно снижают их применимость для решения задач, связанных с научным поиском, анализом и обобщением знаний. Разработка новых подходов, способных эффективно справляться с этими вызовами, является ключевой задачей для развития автоматизированных систем поддержки научных исследований.
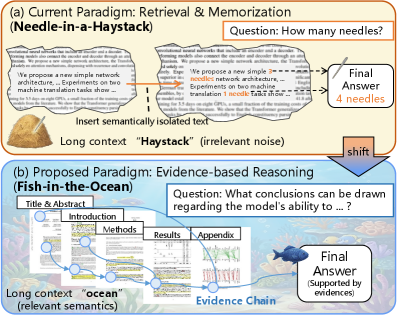
Существующие методы оценки производительности моделей обработки естественного языка, такие как “Игла в стоге сена”, зачастую не отражают реальных требований к научному мышлению. Эти тесты, как правило, фокусируются на точном извлечении конкретной информации из большого объема текста, не требуя от модели способности к синтезу знаний, выявлению взаимосвязей между различными фрагментами текста или оценке достоверности источников. В то время как научные исследования требуют от исследователя умения критически оценивать информацию, строить логические цепочки и делать обоснованные выводы на основе совокупности данных, стандартные бенчмарки часто упрощают этот процесс до поиска конкретных фактов. Таким образом, высокие показатели в подобных тестах не гарантируют, что модель способна к полноценному пониманию и анализу научной литературы, необходимому для решения сложных исследовательских задач.
Для полноценного понимания научной информации недостаточно простого поиска релевантных фрагментов текста. Современные исследования подчеркивают необходимость перехода к надежному, основанному на доказательствах, рассуждению в сложных контекстах. Это означает, что системы должны уметь не только находить ответы на конкретные вопросы, но и интегрировать информацию из различных источников, оценивать ее достоверность и делать логические выводы. Такой подход требует разработки новых методов, способных моделировать процесс научного мышления, где ключевую роль играет анализ взаимосвязей между данными, выявление скрытых закономерностей и построение обоснованных гипотез. В конечном итоге, способность к доказательному рассуждению является определяющим фактором для эффективного усвоения и применения научных знаний.
SIN-Bench: Новая Эра Оценки Научного Разума
SIN-Bench представляет собой комплексный оценочный набор данных, предназначенный для анализа моделей, способных к научному рассуждению на основе длинных контекстов, включающих перемежающиеся текстовые и визуальные доказательства. Основное внимание уделяется оценке способности моделей к обоснованию выводов на основе представленных доказательств (evidence grounding) и поддержанию логической согласованности в процессе рассуждений. Этот набор данных позволяет оценить, насколько точно модель может идентифицировать релевантную информацию из длинных документов и использовать ее для формирования логически обоснованных ответов и выводов, что критически важно для задач, требующих глубокого понимания научных материалов.
В основе SIN-Bench лежит инфраструктура данных SIN-Data, разработанная для сохранения естественной структуры научных документов, в которых текстовые фрагменты чередуются с визуальными доказательствами, такими как графики, диаграммы и изображения. В отличие от традиционных подходов, где данные часто разделяются или преобразуются, SIN-Data сохраняет исходную последовательность представления информации. Это позволяет более реалистично оценивать способность моделей к восприятию и использованию данных в том виде, в котором они представлены в научных публикациях, и обеспечивает возможность проверки способности моделей к интеграции информации из различных модальностей.
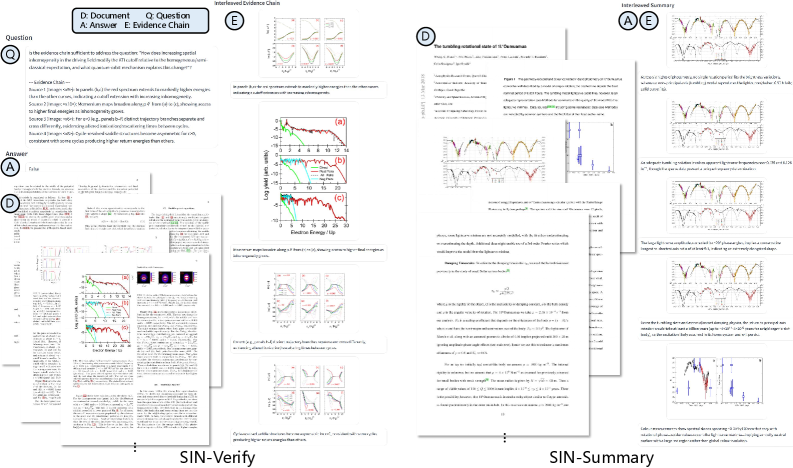
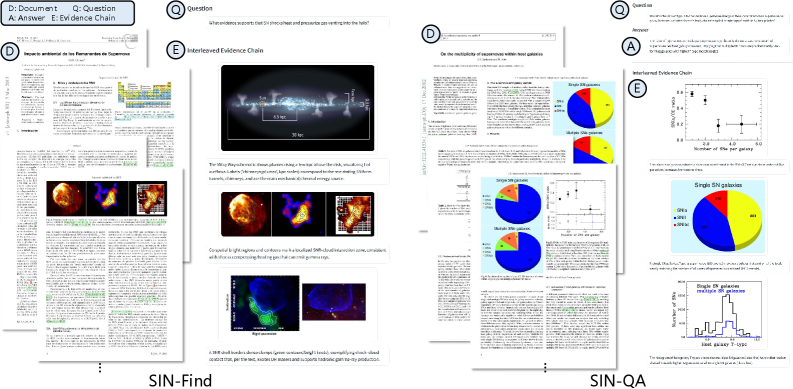
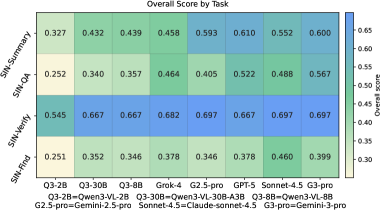
Набор задач в SIN-Bench, включающий ‘SIN-Find’, ‘SIN-Verify’, ‘SIN-QA’ и ‘SIN-Summary’, предназначен для оценки различных навыков рассуждения в контексте научных данных. ‘SIN-Find’ оценивает способность модели к выявлению релевантных доказательств в научных документах. Задача ‘SIN-Verify’ проверяет умение подтверждать или опровергать утверждения на основе представленных доказательств. ‘SIN-QA’ оценивает способность отвечать на вопросы, требующие анализа и синтеза информации из различных источников. Наконец, ‘SIN-Summary’ проверяет способность модели к созданию связного и информативного резюме, основанного на представленных доказательствах и логических выводах.
Доказательство Имеет Значение: Принцип «Нет Доказательств — Нет Оценки»
Принцип “Нет доказательств — нет оценки” (No Evidence, No Score) в SIN-Bench кардинально меняет подход к оценке моделей, смещая акцент с простой точности ответа на качество и верифицируемость представленных доказательств. Традиционные метрики часто оценивают только соответствие ответа правильному значению, игнорируя процесс рассуждения. SIN-Bench, напротив, требует от модели не только предоставить ответ, но и продемонстрировать четкую связь между заключением и источником информации, на котором оно основано. Это означает, что даже если ответ формально верен, но не подкреплен убедительными доказательствами, он не будет оценен высоко. Такой подход позволяет более точно измерить способность модели к логическому мышлению и обоснованию своих выводов, а не просто к запоминанию и воспроизведению фактов.
Принцип SIN-Bench требует от моделей не просто выдавать ответ, но и формировать последовательную “Цепочку доказательств” (Evidence Chain), связывающую заключение с исходными материалами. Данная цепочка представляет собой структурированную последовательность утверждений, каждое из которых обосновывается конкретным фрагментом из предоставленного контекста. Каждое звено цепочки должно логически вытекать из предыдущего, обеспечивая прозрачность процесса рассуждения и позволяя оценить обоснованность сделанных выводов. Отсутствие четкой и верифицируемой связи между заключением и источником информации ведет к снижению оценки модели, даже если сам ответ формально верен.
Оценка логической согласованности цепочек рассуждений, построенных моделями, может производиться с использованием методов корреляции, в частности, коэффициента Кендалла Тау (Kendall-Tau Correlation). Этот статистический показатель измеряет степень соответствия между ранжированными списками, в данном случае — между шагами рассуждений и их подтверждающими доказательствами. Значение коэффициента Кендалла Тау варьируется от -1 до +1, где +1 указывает на полную согласованность, 0 — на отсутствие связи, а -1 — на полную обратную связь. Использование Kendall-Tau Correlation позволяет получить количественную оценку качества рассуждений, предоставляя объективный критерий для сравнения различных моделей и стратегий построения цепочек доказательств.
Под Микроскопом: Производительность и Влияние MLLM
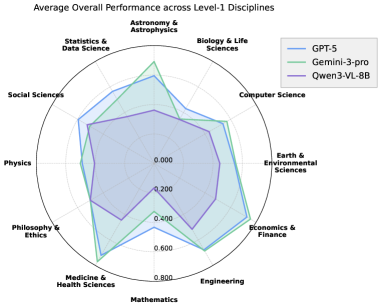
Несмотря на то, что модели, такие как ‘GPT-5’, демонстрируют высокую точность ответов на вопросы (0.767 по SIN-QA), их результаты по показателю соответствия ответам доказательствам на SIN-Bench остаются ниже, что указывает на существенное различие между поверхностным пониманием и истинным логическим мышлением. Данное расхождение подчеркивает, что модель способна генерировать грамматически верные и, казалось бы, уместные ответы, но при этом не всегда может четко связать свои выводы с исходными научными данными. Это свидетельствует о том, что высокая точность ответа не всегда гарантирует глубокое понимание материала и способность к обоснованному анализу, что является критически важным для задач, требующих научного обоснования.
Исследования показали, что модель Gemini-3-pro демонстрирует превосходные результаты в комплексном тестировании SIN-Bench, достигнув наивысшего общего балла в 0.566. Особенно заметны улучшения в задачах, требующих глубокого понимания и синтеза информации: в SIN-Summary зафиксирован прирост в 0.129 балла, а в SIN-QA — 0.102 балла. Эти результаты свидетельствуют о более эффективной способности модели извлекать и использовать релевантные данные из сложных научных текстов, что позволяет ей демонстрировать более точные и обоснованные ответы по сравнению с другими моделями, такими как GPT-5, которые, несмотря на высокую общую точность, отстают в оценке согласованности ответов с представленными доказательствами.
Методология “Рыба в океане”, применяемая в рамках SIN-Bench, представляет собой инновационный подход к оценке возможностей больших языковых моделей (MLLM) в обработке научной информации. Вместо изолированных вопросов, модели сталкиваются с необходимостью “плавать” в массиве взаимосвязанных научных документов, извлекая и синтезируя релевантные сведения для ответа на поставленные задачи. Этот подход позволяет оценить не просто способность модели находить конкретные факты, но и её умение ориентироваться в сложных научных контекстах, выявлять скрытые связи и формировать обоснованные выводы, имитируя процесс исследования, характерный для учёных. Таким образом, “Рыба в океане” является более реалистичным и требовательным тестом, чем традиционные методы оценки, позволяя выявить истинный потенциал MLLM в сфере научных исследований.
Взгляд в Будущее: Курс на Надёжный Научный Искусственный Интеллект
Будущие исследования в области многомодальных больших языковых моделей (MLLM) должны быть направлены на создание способности формировать и поддерживать надежные “цепочки доказательств” в процессе решения сложных задач. Вместо простого предоставления ответа, такие модели должны демонстрировать последовательность рассуждений, подкрепленную конкретными данными и логическими связями. Это означает, что модель должна не только идентифицировать релевантную информацию, но и четко указывать, как эта информация приводит к определенному выводу, фактически представляя собой “след” логических шагов. Разработка таких моделей позволит повысить прозрачность, надежность и проверяемость научных исследований, проводимых с использованием искусственного интеллекта, а также существенно улучшит способность к обнаружению и исправлению ошибок в рассуждениях. В перспективе, это откроет возможности для создания систем, способных не только генерировать новые знания, но и обосновывать их достоверность.
Разработанная платформа SIN-Bench представляет собой ценный инструмент для оценки и стимулирования прогресса в области искусственного интеллекта, способного работать с длинными контекстами, особенно в научных задачах. Эта методология не просто проверяет способность моделей обрабатывать большие объемы информации, но и акцентирует внимание на их умении поддерживать логическую связь и последовательность рассуждений на протяжении всего процесса анализа. SIN-Bench предлагает стандартизированный набор задач и метрик, позволяющих объективно сравнивать различные модели и выявлять слабые места в их архитектуре и алгоритмах. Использование SIN-Bench способствует разработке более надежных и интеллектуальных систем, способных решать сложные научные проблемы, требующие глубокого понимания контекста и доказательной базы.
Для создания по-настоящему интеллектуальных систем, способных решать сложные научные задачи, необходим прогресс в области понимания длинного контекста и строгой оценки на основе доказательств. Игнорирование обширного контекста, характерного для научных исследований, приводит к неверным выводам и ненадежным результатам. Строгая оценка, требующая от системы явного подтверждения каждого шага рассуждений соответствующими доказательствами, становится критически важной для обеспечения достоверности и воспроизводимости научных открытий. Развитие алгоритмов, способных эффективно обрабатывать и интерпретировать большие объемы информации, а также методологий, позволяющих оценивать обоснованность каждого вывода, открывает путь к созданию искусственного интеллекта, который сможет не просто генерировать ответы, но и обосновывать их, подобно ученому, проводящему исследование.
Исследование, представленное в статье, демонстрирует, что современные мультимодальные языковые модели испытывают трудности при построении верифицируемых цепочек доказательств в длинных научных текстах. Этот процесс, по сути, требует от модели не просто найти информацию, а проследить её происхождение и взаимосвязь, что напоминает деконструкцию сложной системы. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что можно доказать». В данном контексте, способность модели строить эти цепочки доказательств является мерилом её способности к истинному пониманию и логическому выводу, а не просто к статистическому сопоставлению данных. Очевидно, что для достижения подлинного прогресса в области искусственного интеллекта необходимо переосмыслить принципы оценки и создать более строгие критерии для проверки обоснованности принимаемых решений.
Куда же дальше?
Представленный SIN-Bench обнажил зияющие прорехи в кажущейся всемогущести больших многомодальных языковых моделей. Способность «понимать» научный текст, как оказалось, не эквивалентна способности выстраивать верифицируемые цепочки доказательств. Это не ошибка в коде, а фундаментальное непонимание природы знания — модели оперируют символами, а не сутью. Настоящий прорыв потребует не просто увеличения контекстного окна или добавления новых параметров, а принципиально иного подхода к представлению и обработке информации.
Следующим шагом видится не столько «обучение» моделей на всё большем количестве данных, сколько создание систем, способных к саморефлексии и самокоррекции. Необходимо разработать метрики, которые оценивают не только правильность ответа, но и уверенность модели в его обоснованности, а также способность выявлять собственные ошибки. Иначе говоря, нужна модель, которая понимает, что она не знает, и способна это признать.
И в конечном итоге, SIN-Bench — это лишь первый шаг к реверс-инжинирингу интеллекта. Он продемонстрировал, что «понимание» — это не пассивное восприятие информации, а активный процесс построения и проверки гипотез. Будущее исследований лежит в области создания систем, способных к критическому мышлению и самостоятельному научному поиску, а не просто к перефразированию существующих знаний.
Оригинал статьи: https://arxiv.org/pdf/2601.10108.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Сердце музыки: открытые модели для создания композиций
- Пространственное мышление: новый взгляд на 3D-рассуждения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Квантовый усилитель света на чипе: новый уровень эффективности
- В поисках подлинной новизны: как оценить оригинальность научных работ?
- Нейросети и Логика: Создание Графов с Жесткими Ограничениями
2026-01-21 03:03