Автор: Денис Аветисян
Исследователи разработали метод, позволяющий значительно снизить потребление памяти в мультимодальных моделях, не жертвуя при этом качеством обработки данных.
MHA2MLA-VLM: Эффективная адаптация Vision-Language Models к архитектуре DeepSeek с помощью параметрически-эффективной тонкой настройки и оптимизированного сжатия KV-кэша.
Рост сложности и многомодальности задач, решаемых моделями, объединяющими зрение и язык, приводит к экспоненциальному увеличению объема кэша «ключ-значение», что становится серьезным препятствием для эффективных вычислений. В данной работе, посвященной разработке фреймворка ‘MHA2MLA-VLM: Enabling DeepSeek’s Economical Multi-Head Latent Attention across Vision-Language Models’, предложен метод адаптации существующих моделей к архитектуре MLA с использованием экономичного дообучения и оптимизированного сжатия кэша. Предложенный подход позволяет значительно снизить потребление памяти без существенной потери производительности, благодаря применению адаптивной стратегии частичного RoPE и метода низкоранговой аппроксимации, учитывающего специфику визуальных и текстовых данных. Возможно ли дальнейшее повышение эффективности и масштабируемости данного подхода для решения еще более сложных задач в области мультимодального искусственного интеллекта?
Растущая сложность мультимодальных данных
В последнее время наблюдается стремительный рост применения больших языковых моделей (БЯМ) в задачах, требующих обработки информации из разных источников — изображений, звука, видео и текста. Это влечет за собой необходимость в разработке более совершенных методов обработки данных, способных эффективно интегрировать и анализировать разнородную информацию. Традиционные подходы к обработке последовательностей оказываются недостаточными для решения этих сложных задач, поскольку БЯМ сталкиваются с трудностями при одновременном анализе большого объема данных из различных модальностей. В связи с этим, исследования в области многомодального обучения активно направлены на создание архитектур и алгоритмов, способных эффективно извлекать взаимосвязи между различными типами данных и использовать их для решения широкого спектра задач, от автоматической генерации описаний изображений до создания интеллектуальных систем, способных понимать и взаимодействовать с окружающим миром.
Традиционные механизмы внимания, лежащие в основе современных больших языковых моделей, несмотря на свою эффективность, сталкиваются с серьезными ограничениями при обработке длинных последовательностей данных. Суть проблемы заключается в квадратичной сложности вычислений: с каждым увеличением длины входной последовательности, требуемые вычислительные ресурсы и время обработки растут пропорционально квадрату этой длины. O(n^2) — такова асимптотическая сложность, что делает обработку длинных текстов, изображений или видео чрезвычайно затратной и непрактичной. Это препятствует способности моделей эффективно улавливать долгосрочные зависимости и контекст, что критически важно для задач, требующих глубокого понимания сложных взаимосвязей в мультимодальных данных. По мере увеличения объема обрабатываемой информации, потребность в более эффективных механизмах внимания становится все более актуальной, побуждая исследователей к разработке инновационных подходов, способных преодолеть эти вычислительные ограничения.
Ограничения, связанные с квадратичной сложностью традиционных механизмов внимания в больших языковых моделях, особенно остро проявляются при работе с длинными контекстными окнами. Это существенно снижает эффективность мультимодального рассуждения, поскольку модели испытывают трудности с установлением связей между отдаленными элементами информации в различных модальностях — тексте, изображениях, аудио и других. Способность к обработке длинных контекстов критически важна для понимания сложных сценариев и построения логических выводов, требующих учета множества взаимосвязанных деталей. Таким образом, преодоление этих вычислительных ограничений является ключевой задачей для развития действительно интеллектуальных мультимодальных систем, способных к глубокому и всестороннему анализу информации.
Эффективное внимание: сдвиг в архитектурном дизайне
Группированное внимание (Grouped-Query Attention, GQA) и многозапросное внимание (Multi-Query Attention, MQA) оптимизируют процесс вычисления внимания в моделях машинного обучения за счет совместного использования пар ключ-значение (key-value pairs). В традиционном внимании каждая голова (head) имеет собственные ключ-значения, что требует значительных вычислительных ресурсов и памяти. GQA и MQA группируют головы и совместно используют один набор ключ-значений, снижая вычислительную сложность и объем памяти, необходимые для обработки. В MQA все головы используют один и тот же набор ключ-значений, в то время как GQA разделяет головы на группы, каждая из которых использует свой набор, предлагая компромисс между производительностью и эффективностью. Это позволяет обрабатывать более длинные последовательности данных с меньшими затратами ресурсов, что особенно важно для задач обработки естественного языка и мультимодальных моделей.
Многоголовое латентное внимание (MHLA) оптимизирует процесс за счет совместного сжатия пар ключ-значение с использованием низкорангового представления. Вместо хранения полных матриц ключей и значений для каждой головы внимания, MHLA применяет разложение на сингулярные значения (SVD) или аналогичные методы понижения размерности для создания более компактной репрезентации. Это снижает потребность в памяти и вычислительные затраты, особенно при большом количестве голов внимания и длительных последовательностях. Эффективность достигается за счет уменьшения размерности пространства ключей и значений, сохраняя при этом значимую информацию, необходимую для вычисления весов внимания и последующей агрегации результатов.
Оптимизации внимания, такие как Grouped-Query Attention и Multi-Head Latent Attention, позволяют эффективно обрабатывать более длинные последовательности данных без существенного снижения производительности. Это критически важно для мультимодальных задач, где модели должны интегрировать и анализировать информацию из различных источников, таких как текст, изображения и аудио, которые часто представлены в виде длинных последовательностей токенов. Уменьшение вычислительной нагрузки, достигаемое за счет совместного использования пар «ключ-значение» и применения сжатия, позволяет масштабировать модели для работы с более сложными и объемными данными, сохраняя при этом приемлемую скорость обработки и потребление памяти.
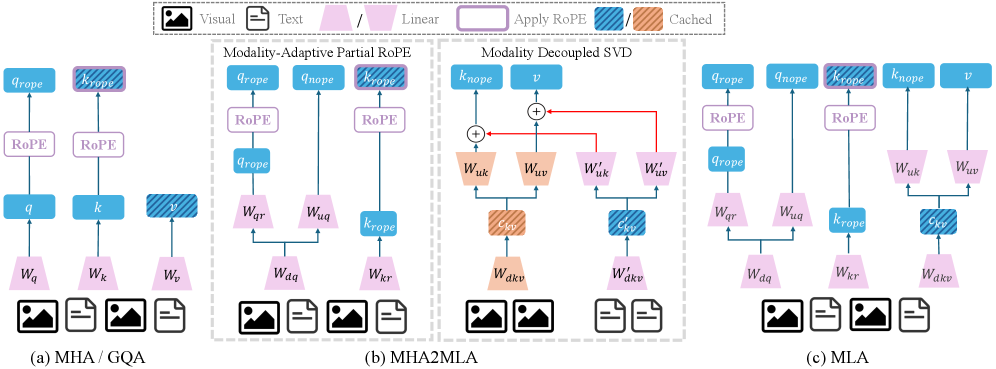
Адаптация LLM для мультимодального вывода: MHA2MLA
Метод MHA2MLA предназначен для адаптации больших языковых моделей (LLM), изначально обученных с использованием Multi-Head Attention или GQA (Grouped-query Attention), для применения Latent Attention (скрытого внимания) в процессе инференса. Этот подход позволяет переключиться с традиционных механизмов внимания, требующих значительных вычислительных ресурсов и памяти для хранения ключей и значений (KV-кэша), на более эффективное представление информации, основанное на Latent Attention. Адаптация заключается в модификации существующих LLM без необходимости их полной переподготовки, что существенно снижает затраты и время, необходимые для внедрения нового механизма внимания.
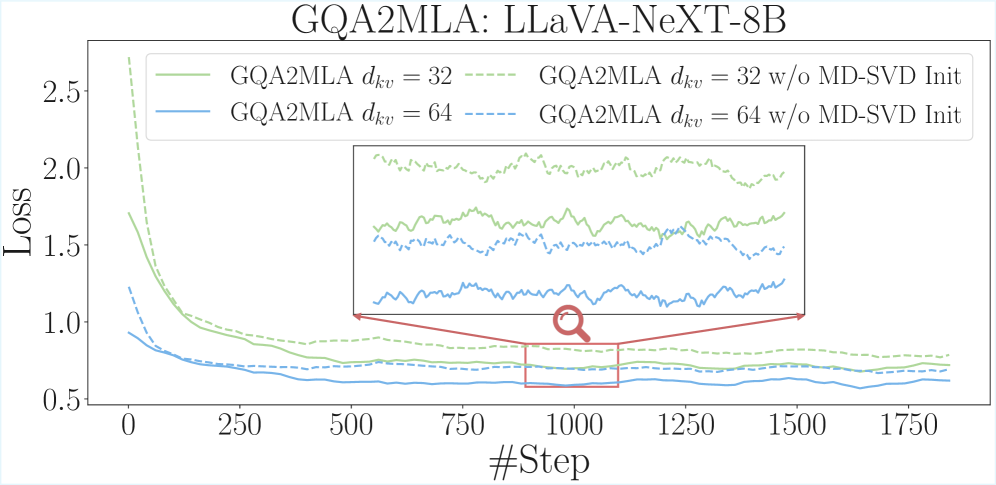
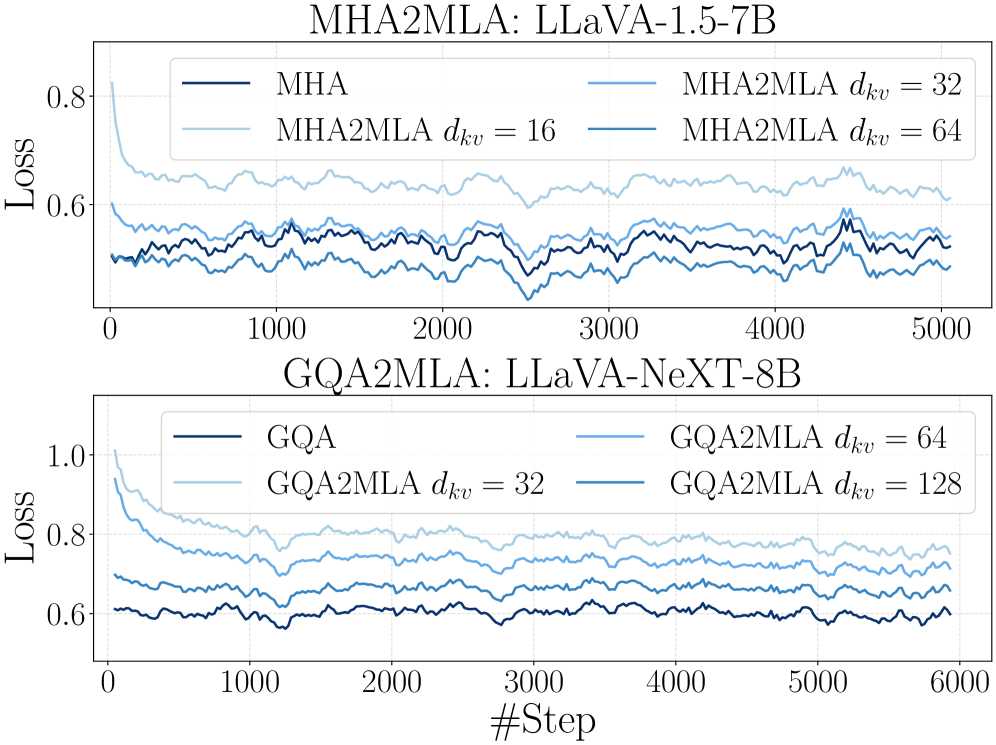
Адаптация моделей осуществляется посредством двух основных техник: частичной конверсии RoPE (Rotary Positional Embeddings) и совместного низкорангового приближения KV (Key-Value) кэша. Частичная конверсия RoPE позволяет уменьшить вычислительную сложность, преобразуя полные RoPE-позиционные вложения в более компактную форму. Совместное низкоранговое приближение KV кэша снижает потребление памяти путем аппроксимации матриц Key и Value с использованием разложения на сингулярные значения (SVD), что позволяет эффективно сжимать информацию, необходимую для генерации ответов, без значительной потери точности. Обе техники направлены на оптимизацию использования ресурсов при выводе, сохраняя при этом качество генерируемого текста.
Метод MHA2MLA использует SVDLLM V2 для дальнейшей оптимизации ошибки активации выходных данных в процессе сжатия, что приводит к повышению производительности. В частности, при использовании MHA2MLA-VLM достигается до 94.64% снижение размера KV-кэша. Это достигается за счет применения сингулярного разложения (SVD) к матрицам значений и ключей, что позволяет эффективно уменьшить объем памяти, необходимый для хранения промежуточных результатов вычислений без существенной потери точности модели. Снижение размера KV-кэша особенно важно для развертывания больших языковых моделей на устройствах с ограниченными ресурсами памяти.
Проверка производительности на моделях «зрение-язык»
Исследования, проведенные с использованием различных моделей, включая LLaVA-1.5, LLaVA-NeXT и Qwen2.5-VL, наглядно демонстрируют эффективность предложенного метода MHA2MLA в различных архитектурах. Данный подход успешно применяется к моделям с отличающимися структурами и принципами работы, подтверждая его универсальность и адаптивность. Результаты показывают, что MHA2MLA не зависит от конкретной реализации модели, а способен улучшать производительность в задачах, связанных с обработкой визуальной и текстовой информации, независимо от базовой архитектуры. Это свидетельствует о потенциале MHA2MLA как общего решения для оптимизации внимания в мультимодальных моделях.
Метод демонстрирует существенное повышение эффективности в мультимодальных задачах за счет оптимизации механизмов внимания, ориентированных на обработку длинных контекстов. В основе подхода лежит усовершенствование способности модели сосредотачиваться на релевантной информации в сложных данных, что особенно важно при анализе изображений и текста, требующих понимания взаимосвязей между различными элементами. Оптимизация внимания позволяет модели более эффективно извлекать ключевые признаки и устанавливать связи между ними, что приводит к улучшению результатов в широком спектре задач, включая визуальные вопросы и ответы, анализ диаграмм и понимание документов. Повышение эффективности обработки длинных контекстов является ключевым фактором для решения сложных мультимодальных задач, требующих комплексного анализа и понимания информации.
Применение методов параметрически-эффективной тонкой настройки значительно повысило адаптивность и эффективность предложенного подхода. В ходе экспериментов с моделью Qwen2.5-VL, использование MHA2MLA позволило сократить время обучения на 59% — с 22 до 9 часов, при этом было задействовано лишь 6-10% от общего числа параметров оригинальной модели. Несмотря на столь существенное снижение вычислительных затрат, удалось сохранить сопоставимые, а в ряде случаев и улучшенные, результаты на восьми ключевых бенчмарках, включающих AI2D, GQA, POPE, SEED-Bench-IMG, RealWorldQA, MMBench, ChartQA и DocVQA, что демонстрирует высокую эффективность и практическую применимость предложенной методики.
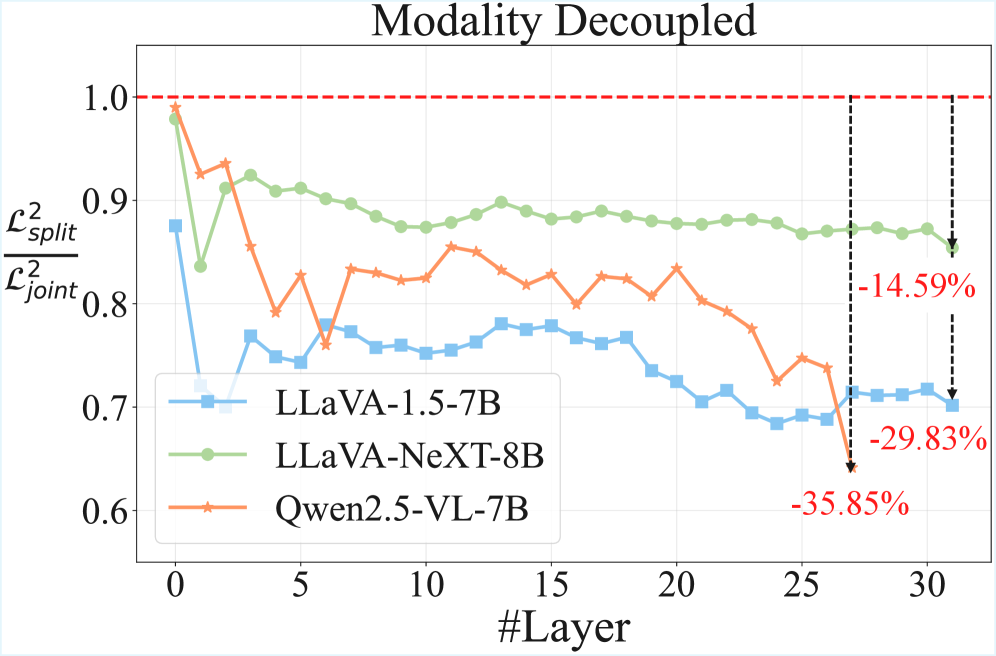
Перспективы развития: к более эффективному мультимодальному ИИ
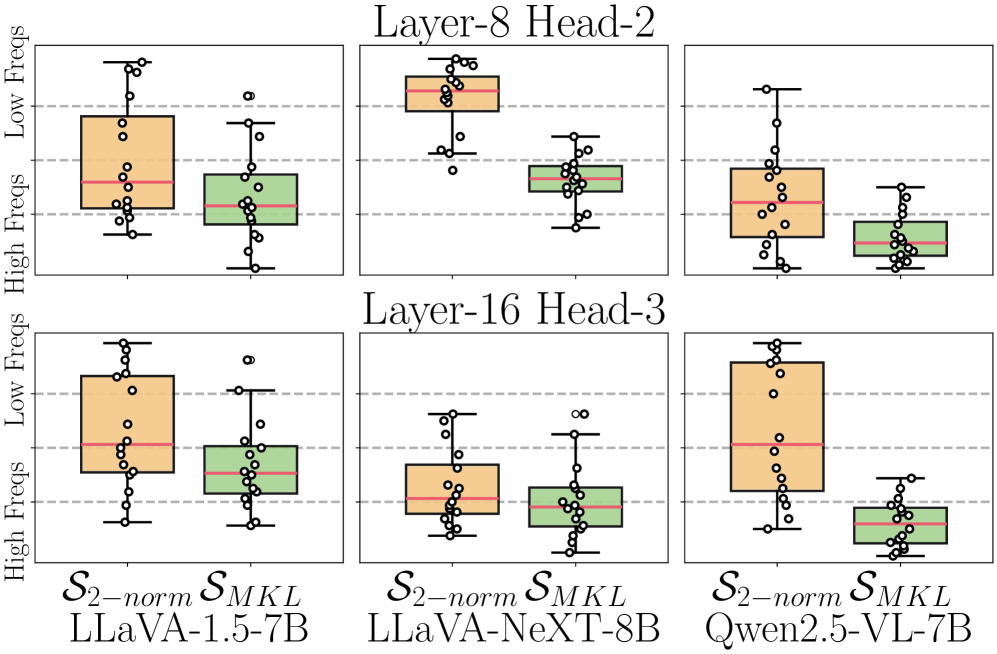
В контексте развития мультимодального искусственного интеллекта, оптимизация позиционных встраиваний является ключевой задачей. Исследования показывают, что методы Modality-Adaptive Partial-RoPE и Modality-Decoupled SVD представляют собой перспективные подходы к решению этой проблемы. RoPE (Rotary Positional Embedding) позволяет эффективно кодировать информацию о позиции токенов, а адаптация к различным модальностям данных, таким как зрение и язык, значительно повышает производительность модели. Разделение сингулярного разложения (SVD) по модальностям позволяет более точно учитывать специфику каждой модальности, снижая вычислительную сложность и улучшая качество представления данных. Эти усовершенствования открывают возможности для создания более эффективных и масштабируемых систем обработки мультимодальной информации, способных решать сложные задачи, требующие интеграции различных типов данных.
Исследования в области эффективной обработки длинных последовательностей мультимодальных данных демонстрируют перспективность применения новых методов компрессии, таких как M-RoPE. Данная техника позволяет значительно сократить вычислительные затраты и объем памяти, необходимые для работы с большими объемами информации, объединяющей, например, изображения и текст. Принцип работы M-RoPE заключается в адаптивном сжатии позиционных вложений, что позволяет модели фокусироваться на наиболее значимых элементах данных, сохраняя при этом необходимую точность. Внедрение подобных технологий открывает возможности для создания более производительных и масштабируемых систем искусственного интеллекта, способных эффективно анализировать и обрабатывать сложные мультимодальные данные, что критически важно для решения задач, требующих глубокого понимания контекста и взаимосвязей между различными типами информации.
Развитие представленных подходов к оптимизации обработки данных в мультимодальных системах искусственного интеллекта открывает перспективы для создания принципиально новых возможностей в области анализа и синтеза информации. Улучшенная масштабируемость и эффективность обработки данных, особенно длинных последовательностей, позволит системам компьютерного зрения и обработки естественного языка решать задачи, ранее недоступные из-за вычислительных ограничений. Это включает в себя более глубокое понимание сложных визуальных сцен, генерацию детализированных и контекстуально релевантных описаний, а также эффективную обработку мультимедийного контента, что приведет к появлению интеллектуальных систем, способных к более сложному взаимодействию с окружающим миром и решению широкого спектра прикладных задач.
Исследование демонстрирует, что эффективное управление вычислительными ресурсами является ключевым фактором в развитии многомодальных моделей. Авторы предлагают метод MHA2MLA-VLM, направленный на снижение потребления памяти за счет оптимизации KV-кэша и применения низкоранговых приближений. Этот подход согласуется с мнением Яна ЛеКуна: “Масштабирование — это лишь временное решение. Настоящий прогресс требует более эффективных алгоритмов и архитектур.” Данная работа, фокусируясь на оптимизации существующих механизмов внимания, подтверждает необходимость поиска более элегантных решений для обработки информации, а не просто увеличения вычислительных мощностей. Успешная адаптация Vision-Language Models к архитектуре DeepSeek MLA свидетельствует о возможности создания более компактных и производительных систем, что открывает новые перспективы для развития искусственного интеллекта.
Куда же дальше?
Представленный подход к оптимизации кэша KV и адаптации Vision-Language Models к архитектуре MLA, безусловно, демонстрирует потенциал снижения вычислительных издержек. Однако, следует признать, что экономия памяти — это лишь одна сторона медали. Настоящим вызовом остаётся поиск баланса между эффективностью сжатия и сохранением тонких нюансов семантического понимания, особенно в задачах, требующих высокой точности. Упрощение модели неизбежно влечёт за собой потерю информации; вопрос лишь в том, насколько критичны эти потери для конкретных приложений.
Перспективным направлением представляется исследование адаптивных методов сжатия, способных динамически регулировать степень упрощения в зависимости от сложности входных данных. Кроме того, представляется интересным изучение возможности комбинирования предложенного подхода с другими техниками квантования и прунинга, с целью достижения ещё более значительного снижения вычислительных затрат. В конечном счёте, задача состоит не в том, чтобы создать максимально компактную модель, а в том, чтобы найти оптимальное соотношение между ресурсами и производительностью.
Следует также учитывать, что текущие исследования в области Vision-Language Models сосредоточены преимущественно на задачах, связанных с обработкой изображений и текста. В будущем, представляется вероятным расширение области применения этих моделей на другие типы данных, такие как видео, аудио и 3D-модели. Это, в свою очередь, потребует разработки новых методов оптимизации, способных эффективно обрабатывать более сложные и многомерные данные.
Оригинал статьи: https://arxiv.org/pdf/2601.11464.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Искусственный интеллект и архитектура будущего: новый виток эволюции
- Многоязычны ли современные нейросети на самом деле?
- Искусственный интеллект на службе материаловедения: платформа AGAPI
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
2026-01-21 04:42