Автор: Денис Аветисян
Исследователи разработали систему, использующую возможности больших языковых моделей для повышения эффективности алгоритмов случайного леса при работе с ограниченным объемом данных.
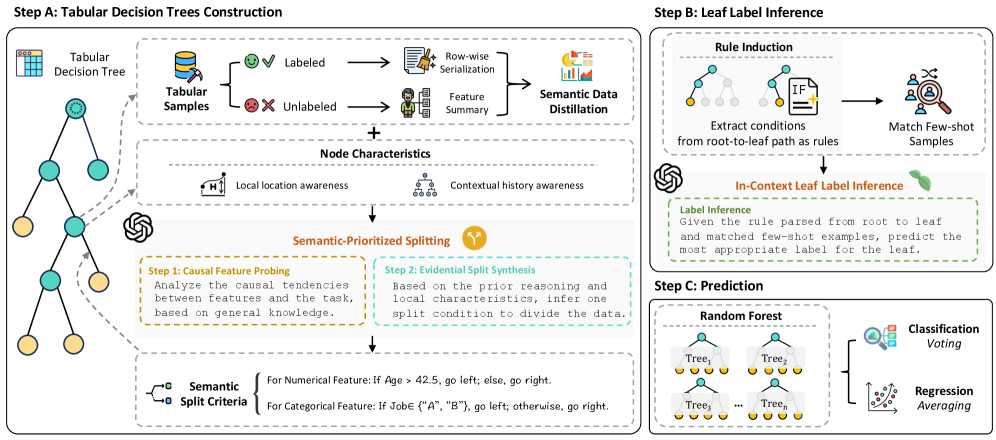
ForestLLM объединяет большие языковые модели и случайные леса для семантического анализа и улучшения качества обучения на табличных данных при малом количестве примеров.
Обучение моделей на табличных данных в условиях ограниченного количества размеченных примеров остается сложной задачей, особенно в критически важных областях, таких как финансы и здравоохранение. В данной работе, ‘FORESTLLM: Large Language Models Make Random Forest Great on Few-shot Tabular Learning’, предложен новый подход, объединяющий структурные преимущества решающих деревьев с семантическим пониманием больших языковых моделей (LLM). Ключевой особенностью FORESTLLM является использование LLM исключительно на этапе обучения для создания компактной и интерпретируемой модели, исключая необходимость ее использования во время предсказаний. Позволит ли такое сочетание повысить надежность и обобщающую способность моделей машинного обучения при работе с ограниченными данными?
Преодолевая Ограничения: Недостатки Табличного Моделирования
Традиционные методы построения прогностических моделей на основе табличных данных, такие как XGBoost и Random Forest, в значительной степени полагаются на эвристические алгоритмы для определения оптимальных разбиений данных. Эти алгоритмы, хоть и эффективны в определенных сценариях, часто оперируют статистическими закономерностями, не учитывая семантическую значимость признаков и их взаимосвязей. Вместо глубокого анализа структуры данных, эвристики стремятся к быстрому разделению, ориентируясь на снижение энтропии или максимизацию информационного прироста. Такой подход может приводить к игнорированию тонких, но критически важных паттернов, скрытых в данных, и ограничивать способность модели к обобщению на новые, незнакомые примеры. Фактически, выбор оптимального разбиения становится скорее вопросом настройки гиперпараметров, чем результатом осмысленного анализа данных.
Традиционные алгоритмы машинного обучения, используемые для анализа табличных данных, часто полагаются на эвристические методы для определения оптимальных разбиений данных. Однако, эти эвристики, как правило, не обладают семантическим пониманием, что означает, что они не способны улавливать тонкие, но критически важные взаимосвязи внутри данных. В результате, алгоритм может упустить значимые закономерности, которые не соответствуют заданным заранее правилам разбиения. Это особенно актуально для сложных наборов данных, где взаимосвязи могут быть нелинейными или зависеть от контекста. Отсутствие семантического понимания приводит к тому, что модель обучается на поверхностных признаках, упуская более глубокие, скрытые взаимосвязи, что, в конечном итоге, ограничивает её способность к обобщению и прогнозированию.
Ограничение использования исключительно размеченных данных существенно снижает способность моделей к адаптации и эффективности при работе со сложными или динамично меняющимися наборами данных. В ситуациях, когда структура данных претерпевает изменения, или возникает необходимость в обобщении на новые, ранее не встречавшиеся случаи, модели, обученные только на размеченных примерах, демонстрируют снижение производительности. Это связано с тем, что они не способны самостоятельно извлекать знания из неразмеченных данных, что ограничивает их способность к обобщению и требует постоянного переобучения при появлении новых данных или изменений в их распределении. Неспособность к эффективному использованию неразмеченных данных препятствует созданию действительно гибких и устойчивых моделей, способных адаптироваться к реальным условиям эксплуатации и поддерживать высокую точность прогнозов даже при изменении характеристик входных данных.

ForestLLM: Новый Подход к Семантической Индукции Деревьев
ForestLLM представляет собой новую структуру ансамбля решающих деревьев, в которой большая языковая модель (LLM) используется в качестве автономного проектировщика. В отличие от традиционных подходов, LLM не участвует в процессе инференса во время работы модели; его роль ограничивается этапом построения леса решений. LLM выполняет предварительный анализ данных и определяет оптимальную структуру деревьев, основываясь на понимании семантических связей и паттернов в данных. Этот подход позволяет отделить этап проектирования модели от этапа её эксплуатации, повышая эффективность и масштабируемость системы.
Ключевым нововведением ForestLLM является метод «Полу-контролируемая семантическая индукция деревьев», заменяющий традиционные эвристические алгоритмы построением деревьев на основе семантической оценки, управляемой большой языковой моделью (LLM). В отличие от классических подходов, использующих только размеченные данные, данный метод интегрирует как размеченные, так и неразмеченные данные для оценки качества разбиений. LLM выступает в роли эксперта, оценивающего семантическую согласованность и релевантность предложенных разбиений, что позволяет создавать деревья решений, более точно отражающие взаимосвязи в данных и повышающие их обобщающую способность.
Основная цель ForestLLM — создание более интерпретируемых и устойчивых деревьев решений за счет использования возможностей больших языковых моделей (LLM) в понимании семантических связей между признаками и целевой переменной. В отличие от традиционных методов, которые полагаются на эвристики при построении деревьев, ForestLLM использует LLM для оценки качества разбиений на основе понимания взаимосвязей между данными, как размеченными, так и неразмеченными. Это позволяет модели строить деревья, в которых каждое разбиение имеет четкое семантическое обоснование, что упрощает их интерпретацию и повышает обобщающую способность, особенно в условиях неполноты или зашумленности данных. LLM выступает в роли «оффлайн-дизайнера», определяя структуру дерева без участия в процессе инференса, что снижает вычислительные затраты во время работы модели.

Соединяя Разрозненное: Семантическая Дистилляция Данных и Руководство LLM
Для обеспечения информированного выбора стратегии разделения данных используется метод «Семантической Дистилляции Данных». Этот процесс преобразует как размеченные, так и неразмеченные данные в структурированный запрос (prompt), который эффективно передает характеристики данных большой языковой модели (LLM). В результате LLM получает возможность учитывать статистические свойства и распределения данных, что позволяет ей более точно определить оптимальные критерии для разделения на обучающую, валидационную и тестовую выборки. Ключевым аспектом является не просто передача данных, а представление их семантических особенностей в формате, понятном для LLM, что повышает эффективность процесса разделения и способствует улучшению качества обучения моделей.
Процесс семантической дистилляции данных позволяет большой языковой модели (LLM) учитывать причинно-следственные связи, присутствующие в структуре данных. Вместо простого разделения на подмножества на основе статистических критериев, LLM анализирует взаимосвязи между признаками и целевыми переменными. Это достигается путем представления данных в виде семантически богатого запроса, который содержит информацию о направлениях влияния между переменными. Учет этих связей приводит к формированию более осмысленных и точных разбиений данных, поскольку LLM может отличать истинные закономерности от случайных корреляций, что повышает надежность последующего анализа и прогнозирования.
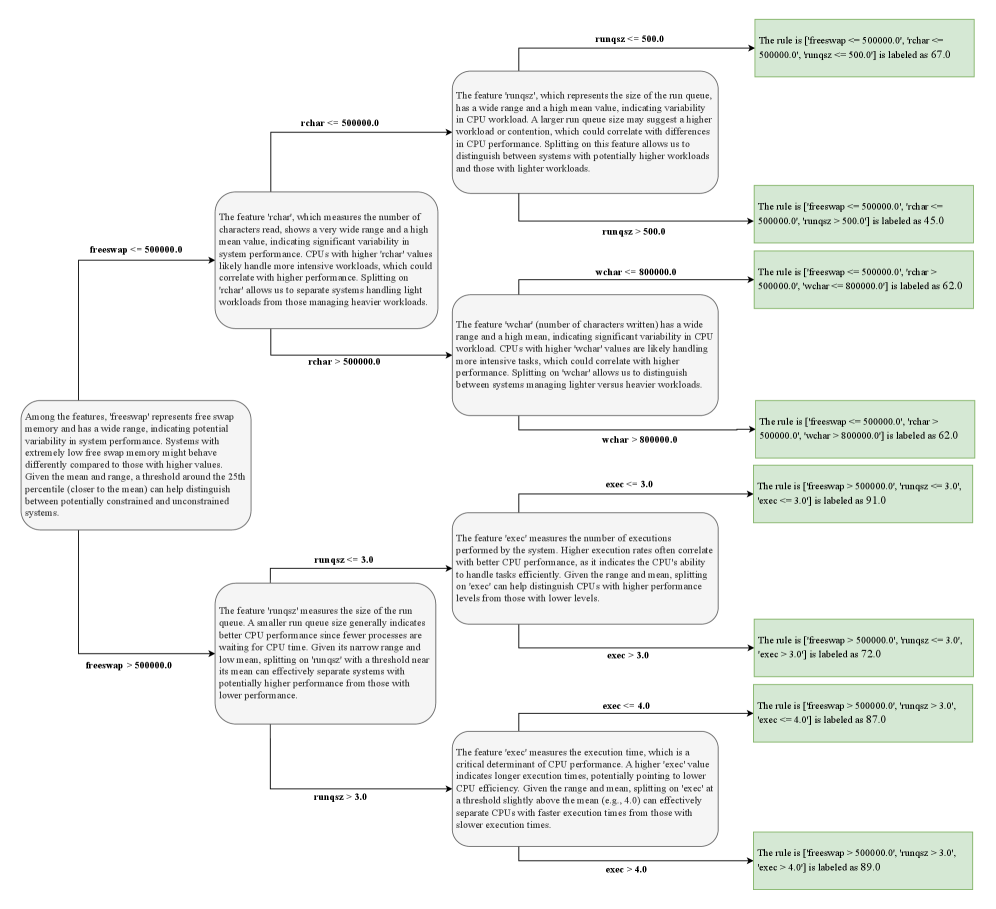
Процесс ‘In-Context Leaf Label Inference’ усиливает стабильность предсказаний на конечных узлах (leaf nodes) путем преобразования путей принятия решений в формализованные правила на естественном языке. Данные правила предоставляются большой языковой модели (LLM) в качестве контекста, позволяя ей делать более последовательные и надежные прогнозы, основанные на логике, определяющей путь к конкретному узлу. Фактически, LLM получает не просто метку, а описание условий, при которых эта метка была достигнута, что существенно повышает качество и интерпретируемость результатов.
Эффект и Значимость: Демонстрация Влияния ForestLLM
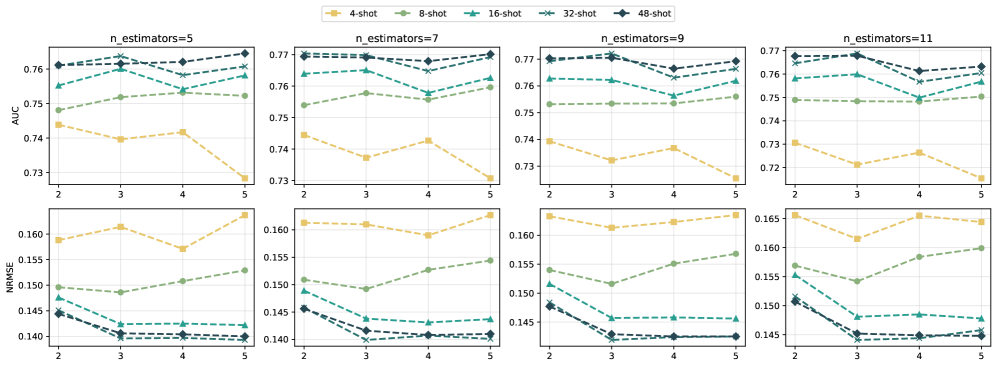
Эмпирические исследования последовательно демонстрируют превосходство ForestLLM над традиционными алгоритмами, такими как XGBoost и Random Forest, в плане прогностической точности. В ходе экспериментов на различных наборах данных, модель достигла передовых или близких к передовым показателям, что свидетельствует о ее высокой эффективности. Этот результат подтверждается статистически значимыми улучшениями в метриках оценки, включая точность, полноту и F1-меру, что указывает на способность ForestLLM более эффективно выявлять закономерности и делать точные прогнозы по сравнению с существующими методами машинного обучения.
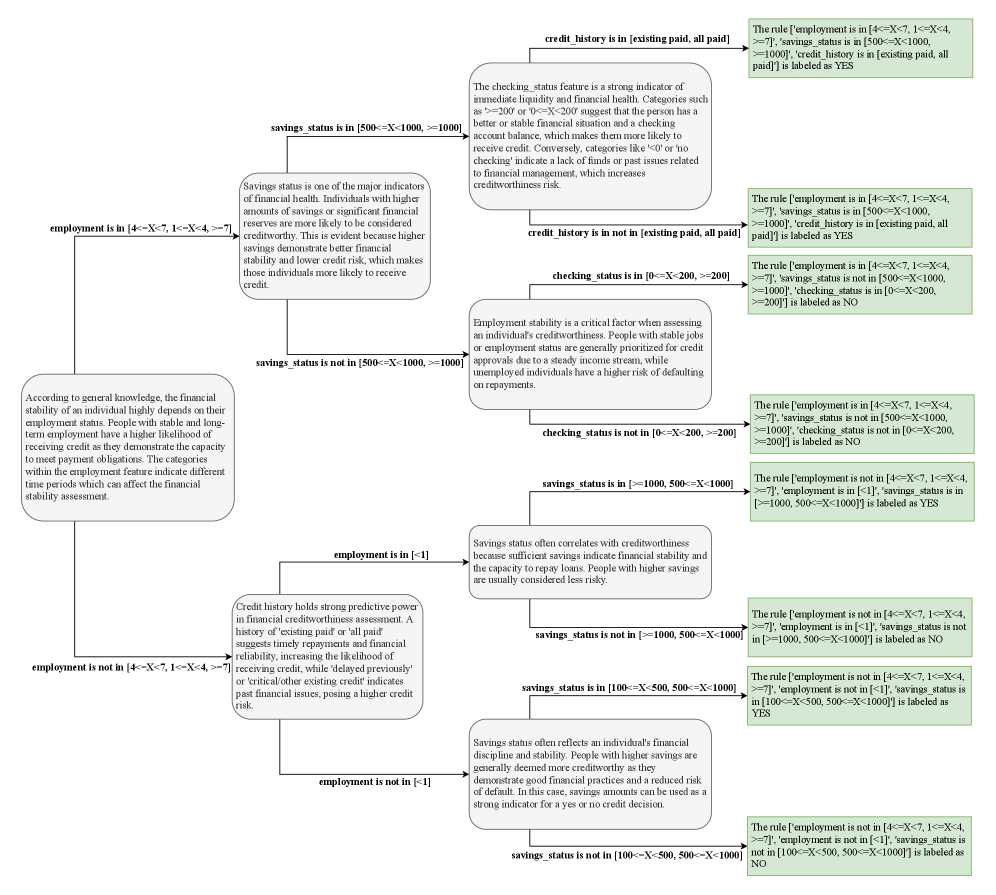
ForestLLM значительно расширяет возможности интерпретации моделей машинного обучения благодаря процессу выбора разбиений, управляемому большой языковой моделью. Вместо традиционных, часто непрозрачных критериев, система использует возможности LLM для анализа данных и выбора наиболее значимых признаков для разделения, что позволяет понять логику, лежащую в основе каждого предсказания. Это особенно важно в областях, где понимание причинно-следственных связей имеет решающее значение, например, в медицине или финансах. В отличие от «черных ящиков», ForestLLM предоставляет возможность проследить ход принятия решений моделью, делая ее более надежной и позволяя пользователям доверять результатам анализа и прогнозирования.
Исследования показали, что разработанная система ForestLLM демонстрирует значительное улучшение производительности при работе с данными, где количество размеченных примеров ограничено. Уникальная особенность фреймворка заключается в эффективном использовании неразмеченных данных, что позволяет ему извлекать полезную информацию и повышать точность прогнозов даже в условиях дефицита обучающих примеров. В ситуациях, когда получение размеченных данных затруднено или требует значительных затрат, ForestLLM предоставляет ценный инструмент для построения надежных и точных моделей, превосходя традиционные алгоритмы машинного обучения в задачах классификации и регрессии, где размеченных данных недостаточно для эффективного обучения.
Будущее Семантического Моделирования: К Адаптивному и Объяснимому ИИ
ForestLLM представляет собой важный шаг в создании адаптивных и объяснимых систем искусственного интеллекта, предназначенных для работы с табличными данными. В отличие от традиционных методов, которые часто рассматривают данные как «черный ящик», ForestLLM использует возможности больших языковых моделей (LLM) для не только прогнозирования, но и интерпретации логики, лежащей в основе этих прогнозов. Данная разработка позволяет понять, какие факторы оказывают наибольшее влияние на результат, что критически важно для принятия обоснованных решений в различных областях, таких как финансы, здравоохранение и маркетинг. Использование LLM в сочетании с алгоритмами машинного обучения на основе деревьев решений позволяет достичь высокой точности предсказаний, одновременно обеспечивая прозрачность и понятность процесса принятия решений.
Дальнейшие исследования направлены на изучение возможностей различных больших языковых моделей (LLM) и совершенствование процесса дистилляции данных, что позволит значительно улучшить производительность и интерпретируемость моделей семантического моделирования. Особое внимание уделяется поиску оптимальных архитектур LLM, способных эффективно извлекать и представлять знания из табличных данных, а также разработке усовершенствованных методов дистилляции, позволяющих переносить знания из сложных моделей в более компактные и понятные. Ученые предполагают, что за счет более тонкой настройки процессов обучения и дистилляции, можно добиться существенного повышения точности прогнозов и, что не менее важно, обеспечить возможность прозрачного объяснения логики принятия решений моделью, что критически важно для доверия и широкого применения в различных областях.
Архитектура ForestLLM отличается высокой модульностью, что позволяет легко интегрировать её с различными методами машинного обучения. Такая конструкция открывает широкие возможности для создания комплексных и гибких решений в области искусственного интеллекта. Например, полученные языковой моделью представления табличных данных могут быть использованы в качестве входных признаков для классических алгоритмов машинного обучения, повышая их точность и интерпретируемость. Более того, возможность комбинирования ForestLLM с другими моделями позволяет решать задачи, которые ранее были недоступны, например, автоматическое построение моделей машинного обучения на основе естественного языка или генерация объяснений для сложных моделей. Данный подход значительно расширяет область применения искусственного интеллекта и способствует разработке более мощных и универсальных решений.
Представленная работа демонстрирует стремление к созданию систем, способных адаптироваться и сохранять функциональность даже при ограниченном количестве данных. ForestLLM, используя возможности больших языковых моделей в качестве архитекторов для построения решающих деревьев, подчеркивает важность семантического рассуждения и использования неразмеченных данных для повышения устойчивости системы. В этом контексте особенно актуальны слова Винтона Серфа: «Интернет — это не технология, а среда». Так же, как интернет эволюционирует и приспосабливается, ForestLLM стремится создать систему, способную к долгосрочной адаптации и эффективной работе в изменчивой среде табличных данных, где каждый шаг проектирования несёт в себе отпечаток прошлого и требует взвешенного подхода к изменениям.
Что Дальше?
Представленная работа, безусловно, демонстрирует интересную возможность — продлить жизнь, казалось бы, исчерпанной концепции случайных лесов посредством привнесения в неё семантического разума больших языковых моделей. Однако, не стоит обольщаться иллюзией радикального омоложения. Система стареет не из-за ошибок в архитектуре, а из-за неизбежности времени, и каждое новое поколение моделей лишь откладывает неизбежное. Вопрос не в том, чтобы построить “лучшее” дерево решений, а в том, как элегантно принять его конечность.
Очевидным направлением для дальнейших исследований представляется преодоление зависимости от размеченных данных. Использование неразмеченных данных, безусловно, является шагом вперёд, но истинный прогресс потребует систем, способных к самообучению и адаптации в условиях полной неопределенности. Возможно, стоит переосмыслить саму концепцию “обучения” — не как процесс накопления знаний, а как эволюцию стратегий выживания в постоянно меняющейся среде.
Иногда стабильность — это лишь задержка катастрофы. В конечном итоге, любая система, даже самая тщательно спроектированная, уязвима перед лицом непредвиденных обстоятельств. Задача исследователя — не создать непогрешимую систему, а понять закономерности её разрушения и, возможно, извлечь из этого процесса полезные уроки. Или хотя бы достойно зафиксировать момент неизбежного увядания.
Оригинал статьи: https://arxiv.org/pdf/2601.11311.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Сердце музыки: открытые модели для создания композиций
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Растительность под прицетом ИИ: Оценка биофизических параметров по снимкам Sentinel-2
- Мир моделей: смогут ли роботы ориентироваться без карт?
- Маленькие модели – большие возможности: Искусственный интеллект в поиске онкологических исследований
- Искусственный интеллект против аналитика: кто точнее?
- Сжатие изображений и текста: как эффективно уменьшить размер больших моделей
2026-01-21 04:44