Автор: Денис Аветисян
Исследователи разработали метод, позволяющий системам искусственного интеллекта самостоятельно улучшать качество поиска информации для более эффективного решения задач.

Представлена Agentic-R — система обучения для поиска, использующая итеративную оптимизацию и контрастное обучение для повышения полезности извлекаемых фрагментов текста.
Несмотря на успехи агентного поиска, вопрос разработки эффективного механизма извлечения информации для него оставался малоизученным. В данной работе, посвященной ‘Agentic-R: Learning to Retrieve for Agentic Search’, предложен новый подход к обучению retriever’а, ориентированный на учет не только локальной релевантности запроса и отрывка, но и глобальной корректности ответа в условиях многошагового агентного поиска. Авторы демонстрируют, что итеративная оптимизация retriever’а и самого агента, использующая эволюционирующие запросы, позволяет значительно улучшить производительность на различных QA бенчмарках. Какие перспективы открывает подобный подход для создания более интеллектуальных и эффективных систем поиска и ответов на вопросы?
Преодолевая Статичность: Эволюция Агентного Поиска
Традиционные системы генерации с расширением извлечением (RAG) зачастую используют статические методы поиска информации, что существенно ограничивает их возможности при работе со сложными запросами. В этих системах, вектор базы знаний формируется однократно, и при поступлении запроса выполняется поиск наиболее релевантных фрагментов без возможности уточнения или расширения критериев поиска в процессе генерации ответа. Это приводит к тому, что система может упустить важные нюансы запроса или предоставить неполную информацию, особенно если исходный запрос сформулирован неоднозначно или требует анализа нескольких источников. В результате, ответы, генерируемые с использованием статических методов извлечения, могут быть неточными или нерелевантными, что снижает эффективность всей системы в целом и требует ручной корректировки результатов.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в обработке и генерации текста, их знание ограничено данными, на которых они обучались. Для решения сложных задач и предоставления актуальной информации LLM нуждаются в доступе к внешним источникам знаний. Этот факт подчеркивает необходимость разработки систем динамического поиска информации, способных оперативно находить и предоставлять LLM релевантные данные в процессе генерации ответа. В отличие от традиционных методов, где поиск информации осуществляется однократно, динамический поиск позволяет модели итеративно уточнять запрос и получать более точные и полные сведения, значительно повышая качество и достоверность генерируемого текста.
Появление агентного поиска знаменует собой принципиальный сдвиг в парадигме работы с большими языковыми моделями. В отличие от традиционных систем, полагающихся на статический поиск информации, агентный подход позволяет моделям итеративно уточнять запрос и последовательно извлекать релевантные данные в процессе генерации ответа. Этот динамический процесс не просто предоставляет необходимую информацию, но и позволяет модели критически оценивать и синтезировать полученные данные, адаптируясь к сложности запроса и обеспечивая более точные и полные результаты. Вместо однократного поиска, модель действует как исследователь, формулируя новые подзапросы на основе промежуточных результатов и углубляя своё понимание темы до тех пор, пока не будет достигнут удовлетворительный ответ. Таким образом, агентный поиск превращает языковую модель из пассивного потребителя информации в активного участника процесса познания.

Agentic-R: Итеративная Оптимизация для Улучшенного Извлечения
Метод Agentic-R реализует итеративный процесс оптимизации, попеременно обучая агента поиска и систему извлечения информации для достижения взаимного улучшения. В рамках этого процесса, агент поиска и система извлечения информации функционируют как взаимосвязанные компоненты. Обучение агента поиска направлено на выработку стратегий формирования запросов, а обучение системы извлечения информации — на повышение точности и релевантности результатов поиска. Последовательное чередование этапов обучения позволяет обоим компонентам адаптироваться и улучшать свои показатели, что приводит к повышению общей эффективности системы поиска.
В основе Agentic-R лежит обучение поискового агента с использованием методов обучения с подкреплением (RL). RL позволяет агенту активно исследовать различные стратегии поиска информации и совершенствовать их на основе получаемой обратной связи. В процессе обучения агент формирует политику, определяющую, какие действия следует предпринять в конкретной ситуации для максимизации вознаграждения, которое в данном контексте связано с релевантностью найденной информации. Такой подход позволяет агенту адаптироваться к сложным поисковым сценариям и оптимизировать процесс извлечения информации без явного программирования конкретных правил поиска.
В основе обучения поискового агента Agentic-R лежит алгоритм PPO (Proximal Policy Optimization), обеспечивающий эффективную и стабильную оптимизацию в сложных сценариях поиска. PPO является методом обучения с подкреплением, который позволяет агенту итеративно улучшать свою стратегию поиска, минимизируя риск резких изменений в политике и обеспечивая устойчивое обучение. Алгоритм использует «отсечение» (clipping) для ограничения изменения политики на каждом шаге, что предотвращает нестабильность и гарантирует более плавное схождение к оптимальному решению. В контексте Agentic-R, PPO позволяет агенту эффективно исследовать различные стратегии поиска и адаптироваться к специфике информационного пространства, максимизируя релевантность извлекаемых результатов.
Моделирование Полезности Фрагментов: Оценка Релевантности и Корректности Ответа
В Agentic-R для оценки полезности извлеченных фрагментов используется моделирование полезности фрагментов (Passage Utility Modeling). Данный подход предполагает комплексную оценку, учитывающую как локальную релевантность фрагмента запросу, так и его вклад в формирование окончательного ответа. Оценка не ограничивается просто соответствием содержания фрагмента запросу, а анализирует, насколько информация из фрагмента способствует генерации корректного и полного ответа на поставленный вопрос. Это позволяет системе ранжировать фрагменты, отдавая приоритет тем, которые не только релевантны, но и действительно полезны для получения точного результата.
Локальная релевантность оценивается с помощью LLM-основанного Listwise Scoring, который представляет собой метод оценки, использующий большие языковые модели для ранжирования отрывков текста по степени соответствия заданному запросу. В процессе Listwise Scoring модель одновременно оценивает несколько отрывков относительно запроса, определяя степень их соответствия и взаимосвязи. Это позволяет более точно определить, насколько конкретный отрывок непосредственно отвечает на вопрос, содержащийся в запросе, и выделить наиболее релевантные фрагменты информации. Оценка производится на основе анализа семантического сходства между запросом и содержанием отрывка, что позволяет учитывать контекст и нюансы языка.
Глобальная корректность ответа оценивается с использованием метрики Exact Match (EM), которая определяет степень, в которой извлеченный фрагмент текста поддерживает генерацию правильного итогового ответа. EM измеряет, совпадает ли предсказанный ответ с одним из эталонных ответов в наборе данных. Фрагмент считается поддерживающим, если предсказанный ответ, сгенерированный на основе этого фрагмента, точно соответствует одному из правильных ответов. Для оценки EM используется бинарная классификация: фрагмент либо поддерживает генерацию правильного ответа, либо нет. Эта метрика позволяет оценить, насколько эффективно извлеченные фрагменты способствуют формированию точного и корректного ответа.
Двойная оценка, включающая оценку локальной релевантности и глобальной корректности ответа, позволяет системе Agentic-R приоритизировать отрывки, которые не только соответствуют запросу, но и вносят вклад в формирование точного и исчерпывающего ответа. Такой подход обеспечивает, что извлекатель (retriever) отдает предпочтение отрывкам, способствующим генерации корректного результата, а не просто содержащим ключевые слова из запроса. Оценка локальной релевантности определяет непосредственное соответствие между запросом и содержанием отрывка, в то время как оценка глобальной корректности определяет, насколько отрывок подтверждает или способствует генерации правильного итогового ответа.

Превосходная Производительность и Широкая Применимость
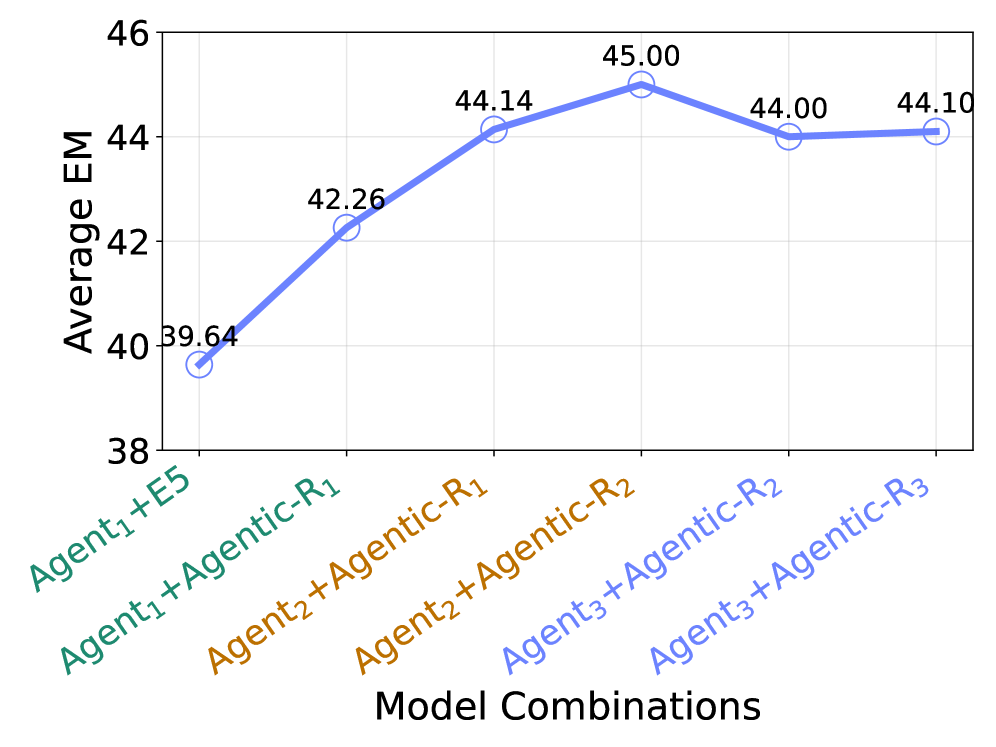
Agentic-R демонстрирует значительное повышение эффективности в задачах ответов на вопросы, как требующих поиска информации из одного источника (Single-hop Question Answering), так и предполагающих анализ нескольких источников для синтеза ответа (Multi-hop Question Answering). В ходе исследований было установлено, что данная система способна более точно и полно извлекать необходимую информацию, что приводит к более качественным ответам на сложные вопросы. Улучшение производительности наблюдается благодаря способности Agentic-R адаптировать стратегию поиска информации в зависимости от конкретного запроса и используемой языковой модели, что позволяет системе более эффективно находить релевантные отрывки текста и формировать информативные ответы.
В отличие от существующих методов, полагающихся на универсальные модели встраивания или специализированные извлекатели для RAG, Agentic-R демонстрирует способность к адаптации стратегии поиска информации, учитывая специфику запроса и используемой большой языковой модели. Этот подход позволяет системе динамически оптимизировать процесс извлечения релевантных фрагментов текста, избегая жестких ограничений, присущих статичным моделям. Вместо слепого применения заранее обученных векторов или фиксированных алгоритмов, Agentic-R анализирует каждый запрос и подбирает наиболее эффективный способ поиска, что приводит к более точным и информативным ответам, а также повышает общую эффективность системы в различных задачах, требующих доступа к знаниям.
В основе Agentic-R лежит механизм итеративной оптимизации и моделирование полезности отрывков текста, что позволяет значительно повысить точность и информативность ответов. Данный подход предполагает не просто поиск релевантных документов, но и последовательное уточнение поискового запроса на основе анализа полученных результатов. Моделирование полезности позволяет оценивать, насколько конкретный отрывок текста способствует формированию полного и корректного ответа, отсеивая менее значимую информацию. В результате, система способна предоставлять пользователю более глубокие и обоснованные ответы, улучшая общее качество взаимодействия и обеспечивая более эффективное решение поставленных задач. Такой подход позволяет Agentic-R не просто находить информацию, но и синтезировать её, представляя в наиболее удобном и понятном для пользователя виде.
В ходе экспериментов с многошаговым вопросно-ответным анализом (Multi-hop QA) система Agentic-R продемонстрировала заметное превосходство над базовой моделью REPLUG. В среднем, точность ответов Agentic-R улучшилась на приблизительно 3 пункта на стандартных наборах данных, что свидетельствует о значительном повышении эффективности при решении сложных задач, требующих синтеза информации из нескольких источников. Данный результат указывает на способность системы более эффективно выявлять и использовать релевантную информацию для формирования точных и обоснованных ответов, превосходя существующие подходы в данной области.
Исследования показали, что разработанная система Agentic-R демонстрирует значительное повышение эффективности поиска информации, сокращая количество итераций поиска на приблизительно 10-15% по сравнению с базовой моделью REPLUG на популярных наборах данных, таких как HotpotQA и TriviaQA. Это означает, что для получения необходимого ответа системе требуется меньше запросов к базе знаний, что существенно ускоряет процесс и снижает вычислительные затраты. Уменьшение количества итераций поиска не только повышает скорость ответа, но и улучшает пользовательский опыт, предоставляя информацию более оперативно и эффективно, что особенно важно в интерактивных системах и приложениях, требующих быстрого доступа к знаниям.
Применение Agentic-R к поисковому агенту, основанному на модели BGE, демонстрирует значительное улучшение метрики EM (Exact Match) в среднем на 2.8 пункта. Это свидетельствует о способности данной системы не только находить релевантную информацию, но и предоставлять ответы, полностью соответствующие запросу. Улучшение метрики EM указывает на повышенную точность и достоверность получаемых результатов, что особенно важно для приложений, требующих высокой степени надежности и корректности информации, например, в системах ответов на вопросы или интеллектуального поиска.
В основе представленной работы лежит стремление к созданию поисковой системы, способной не просто находить информацию, но и эффективно её использовать в процессе решения задачи. Подход Agentic-R акцентирует внимание на моделировании полезности каждого фрагмента текста, что позволяет отсеивать шум и концентрироваться на действительно релевантных данных. Как однажды заметил Кен Томпсон: «Простота — это высшая форма утонченности». В контексте данной работы, эта простота проявляется в стремлении к созданию элегантного алгоритма, способного оптимизировать процесс поиска и извлечения информации, избегая избыточности и фокусируясь на ключевых компонентах. Итеративная оптимизация, предложенная в Agentic-R, позволяет системе непрерывно совершенствоваться, приближаясь к идеальному решению задачи.
Куда Далее?
Представленная работа, хотя и демонстрирует улучшение в области агентного поиска посредством обучения извлекателя, лишь слегка приоткрывает завесу над истинной сложностью задачи. Утверждение о моделировании “полезности” отрывков текста — скорее эвристика, чем строгое математическое определение. Доказательство корректности такого приближения отсутствует, а полагаться лишь на эмпирические результаты — признак слабости, а не силы. Итеративная оптимизация агента и извлекателя, несомненно, полезна, однако вопрос о сходимости и оптимальности данного процесса требует более глубокого анализа.
Будущие исследования должны сосредоточиться на формализации понятия “полезности” отрывка. Необходимо разработать метрики, основанные на принципах теории информации или теории принятия решений, а не на субъективных оценках. Интересным направлением представляется интеграция формальных методов верификации для подтверждения корректности алгоритмов обучения извлекателя. Доказательство сходимости и оптимальности итеративных процессов — задача, требующая привлечения инструментов математического анализа.
Нельзя забывать и о проблеме обобщения. Эффективность предложенного подхода на ограниченном наборе данных не гарантирует его применимость к более сложным и разнообразным задачам. Истинная элегантность алгоритма проявляется в его способности адаптироваться к новым условиям без потери качества. И лишь в этом случае можно говорить о реальном прогрессе в области искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2601.11888.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Самообучающиеся системы: новый подход к созданию многоагентных взаимодействий
- Многоязычны ли современные нейросети на самом деле?
- Квантовые системы в полуклассическом режиме: новый подход к моделированию
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Сердце музыки: открытые модели для создания композиций
- Графовые запросы на скорости света: cuRPQ выходит на новый уровень
- LongCat-Video: ещё один «прорыв», который придётся поддерживать.
- Квантовые вычисления: линейная алгебра на службе симуляции
- Вариационные и полувариационные неравенства: от теории к практике
2026-01-21 12:43