Автор: Денис Аветисян
Новый подход позволяет оценить, насколько точно программная реализация соответствует описанию в научной публикации.
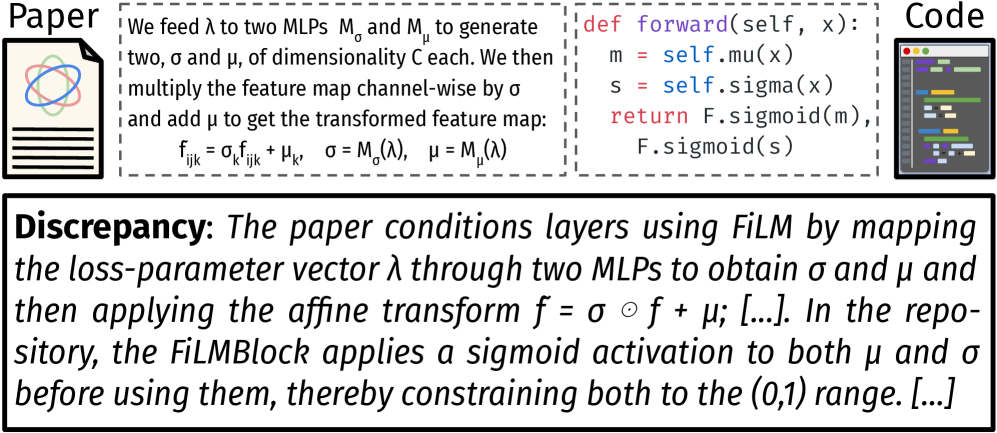
SciCoQA: Датасет и бенчмарк для оценки языковых моделей в задаче выявления расхождений между научными статьями и их кодовыми реализациями.
Воспроизводимость научных исследований, особенно в области вычислительной науки, часто страдает из-за несоответствий между описанием методов в публикациях и их фактической реализацией в коде. В данной работе представлена база данных SciCoQA: Quality Assurance for Scientific Paper—Code Alignment, предназначенная для выявления таких расхождений и оценки способности больших языковых моделей (LLM) обнаруживать их. Созданный набор данных, включающий как реальные примеры, полученные из GitHub и публикаций о воспроизводимости, так и синтетические расхождения, позволяет оценить эффективность LLM в обеспечении соответствия между научной статьей и кодом. Насколько хорошо современные LLM справляются с задачей выявления несоответствий, и какие типы расхождений представляют наибольшую сложность для автоматического анализа?
Разоблачая хрупкость научного знания: проблема воспроизводимости кода
Несмотря на строгую процедуру рецензирования, несоответствия между опубликованными научными статьями и сопровождающим их кодом встречаются удивительно часто, что существенно замедляет научный прогресс. Исследования показывают, что ошибки в коде, неточности в воспроизведении результатов и расхождения между описанными методами и их реализацией — распространенные явления. Данные несоответствия не только подрывают доверие к научным публикациям, но и создают серьезные препятствия для проверки и верификации полученных результатов другими исследователями. Это приводит к дублированию усилий, замедлению темпов открытий и, в конечном итоге, к снижению эффективности научной деятельности. Необходимость автоматизированных инструментов для выявления подобных расхождений становится все более очевидной в условиях экспоненциального роста объема научной информации.
Несоответствия между опубликованными научными статьями и сопровождающим их кодом, известные как «расхождения между статьей и кодом», подрывают доверие к результатам исследований и препятствуют их проверке. Эти расхождения могут возникать из-за ошибок в реализации алгоритмов, неточностей в передаче данных или просто из-за сложностей в воспроизведении вычислений. В результате, другие ученые сталкиваются с трудностями при попытке подтвердить или расширить полученные результаты, что замедляет прогресс в науке. В связи с этим, возникает острая необходимость в разработке систематических методов обнаружения таких ошибок, позволяющих автоматизировать процесс проверки и обеспечить надежность научных публикаций. Автоматизированные системы могли бы анализировать как текст статьи, так и соответствующий код, выявляя потенциальные несоответствия и предупреждая о возможных проблемах с воспроизводимостью.
В настоящее время выявление расхождений между опубликованными научными статьями и сопровождающим их кодом зачастую осуществляется вручную, что требует значительных временных затрат и усилий исследователей. Такой подход становится особенно проблематичным в контексте экспоненциального роста объема научной литературы и усложнения используемых вычислительных методов. Неспособность оперативно и эффективно обнаруживать подобные несоответствия не только замедляет процесс верификации научных результатов, но и препятствует воспроизводимости исследований, подрывая доверие к научным публикациям и ставя под вопрос достоверность полученных выводов. Необходимость в автоматизированных и масштабируемых инструментах для обнаружения расхождений между статьей и кодом становится все более очевидной для обеспечения надежности и прозрачности научных исследований.
SciCoQA: Фундамент для автоматизированной проверки и контроля качества
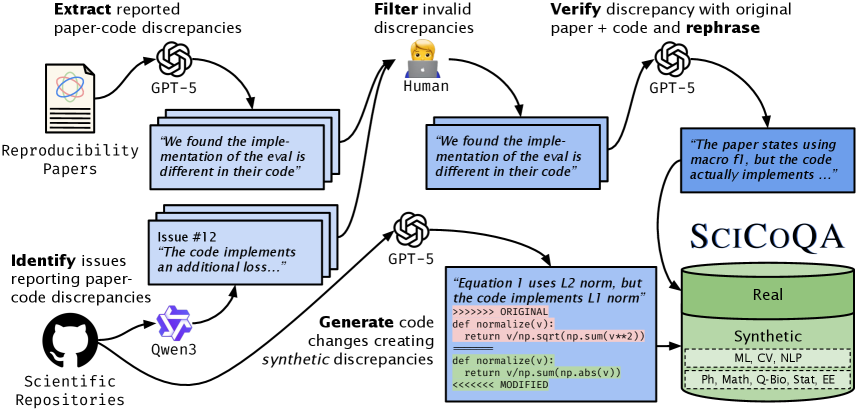
Набор данных SciCoQA представляет собой ценный ресурс для оценки и улучшения контроля качества научных статей и их кодовых реализаций. Он состоит из тщательно отобранных пар статей и соответствующего кода, сопровождающих эти публикации, и содержит информацию о расхождениях между заявленными в статье результатами и фактическим поведением кода. Это позволяет исследователям разрабатывать и тестировать автоматизированные инструменты верификации, направленные на выявление ошибок воспроизведения и несоответствий в научных работах, что способствует повышению надежности и достоверности научных исследований. Набор данных SciCoQA охватывает различные научные дисциплины, что делает его универсальным инструментом для оценки качества научных работ в целом.
Набор данных SciCoQA предоставляет систематизированный сбор и маркировку расхождений между описаниями в научных статьях и соответствующими реализациями кода. Это позволяет разрабатывать и оценивать автоматизированные инструменты верификации, предназначенные для выявления несоответствий в научной литературе и коде. Маркировка расхождений включает классификацию типов ошибок, что обеспечивает возможность обучения моделей машинного обучения для автоматического обнаружения и исправления таких несоответствий. Наличие размеченного набора данных является ключевым фактором для оценки производительности различных инструментов верификации и сравнения их эффективности в обнаружении и классификации расхождений.
Набор данных SciCoQA использует разнообразные источники информации для расширения охвата и повышения надежности обнаружения расхождений между научной статьей и ее кодовой реализацией. В частности, данные собираются из отчетов о воспроизводимости экспериментов, представленных в научных публикациях, а также из сообщений об ошибках и запросов на исправление, зарегистрированных на платформе GitHub. Комбинирование этих источников позволяет выявлять более широкий спектр несоответствий, включая ошибки в коде, неточности в описании методов и проблемы с воспроизводимостью результатов, что значительно повышает эффективность автоматизированных инструментов верификации.
Усиление и анализ несоответствий: расширяя границы возможного
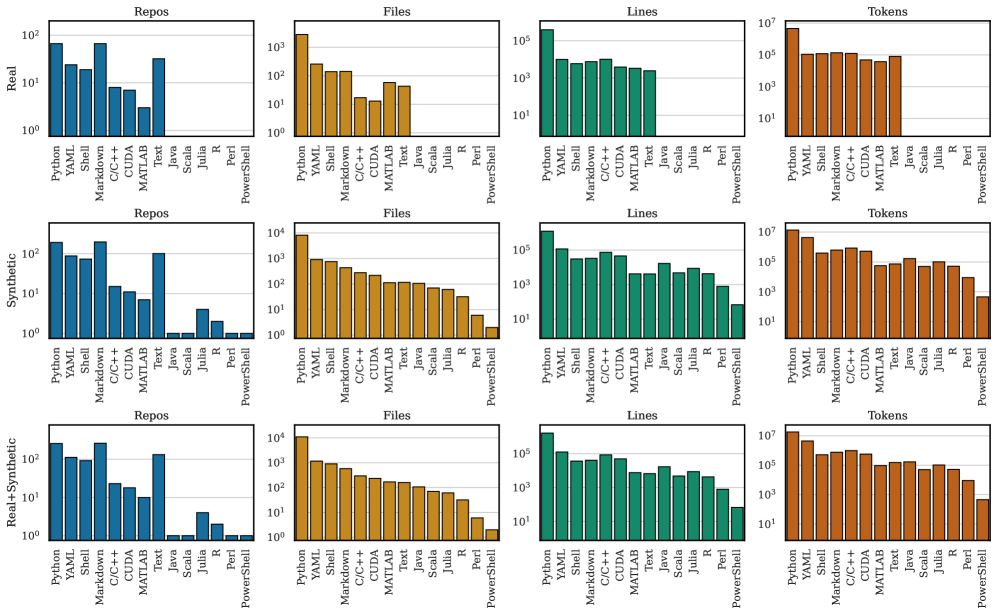
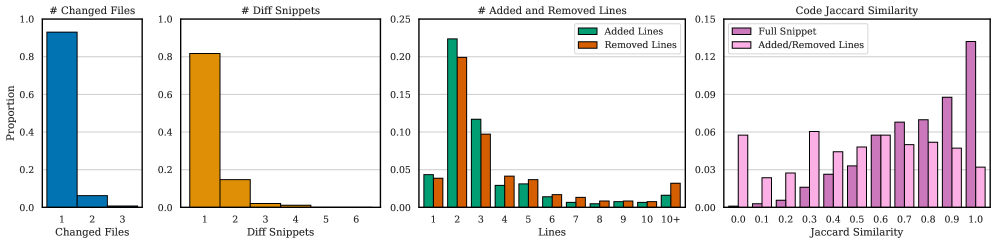
Для расширения охвата SciCoQA используется метод «синтетической генерации расхождений», заключающийся в искусственном внесении ошибок в данные. Этот подход позволяет создавать контролируемые отклонения от эталонных значений, что, в свою очередь, используется для проверки и улучшения алгоритмов обнаружения несоответствий. Создаваемые искусственные ошибки варьируются по типу и степени, имитируя распространенные погрешности, возникающие в реальных научных данных и симуляциях. Процесс позволяет оценить устойчивость алгоритмов к шуму, неполноте данных и другим видам искажений, а также оптимизировать их параметры для повышения точности и надежности.
Для точного сопоставления научных описаний и кода используются методы нормализации кода, обеспечивающие единообразие представления и облегчающие корректное сопоставление. Нормализация включает удаление несущественных элементов, таких как комментарии и пробелы, приведение идентификаторов к стандартному регистру и формату, а также упрощение сложных выражений. Это позволяет алгоритмам сравнения игнорировать синтаксические различия, не влияющие на семантику, и сосредоточиться на логической эквивалентности кода и научного описания. Применение нормализации существенно повышает точность определения соответствий между текстовым описанием научной задачи и её программной реализацией.
Для выявления незначительных расхождений в научных симуляциях, помимо стандартных метрик сравнения, применяются специализированные показатели расстояния. Метрика «минимальное расстояние до атома» (d_{min}) определяет кратчайшее расстояние между атомами в сравниваемых структурах, позволяя выявить даже небольшие отклонения в их расположении. Другой показатель, «расстояние до центроида» (d_{centroid}), вычисляет расстояние между центрами масс сравниваемых объектов, что особенно полезно для оценки изменений в общей форме и структуре моделируемых систем. Применение этих метрик позволяет более точно оценить степень расхождений, которые могут быть упущены при использовании стандартных методов сравнения.
Использование LLM и математических представлений для надежной валидации: новый взгляд на проверку научных знаний
В настоящее время всё большее распространение получает подход, в котором большие языковые модели (LLM) используются в качестве автоматизированных оценщиков — так называемые “LLM-as-a-Judge”. Данный метод позволяет оценивать корректность выявленных расхождений в научных работах и кодовых базах, предоставляя масштабируемое и объективное суждение. Вместо ручной проверки экспертами, LLM анализирует представленные данные и определяет, действительно ли обнаруженное несоответствие является ошибкой или допустимым отклонением. Это значительно ускоряет процесс верификации и позволяет обрабатывать большие объемы информации, недоступные для традиционных методов. Применение LLM в роли судьи открывает новые возможности для автоматизации контроля качества научных исследований и разработки программного обеспечения, повышая надежность и воспроизводимость результатов.
Ограниченность контекстного окна больших языковых моделей (LLM) представляет собой существенную проблему при анализе объемных научных статей и кодовых баз. Способность LLM эффективно оценивать достоверность и выявлять несоответствия напрямую зависит от объема информации, которую модель может одновременно обработать. В связи с этим, разработка эффективных методов фокусировки на релевантных фрагментах текста становится критически важной задачей. Для преодоления данного ограничения применяются стратегии, направленные на извлечение ключевых данных и представление их в сжатом виде, позволяя LLM концентрироваться на наиболее значимых аспектах, не теряя при этом контекст и точность анализа. Эти методы включают в себя, например, автоматическое суммирование, выделение ключевых предложений и применение алгоритмов, направленных на выявление наиболее важных фрагментов кода или текста, что позволяет существенно повысить эффективность LLM в задачах верификации и обнаружения ошибок.
Математические описания, такие как представление Фурье-Чебышева и нулевой режим Фурье в плоскости, играют ключевую роль в точной репрезентации научных методов и выявлении расхождений в их реализации. Эти методы позволяют компактно и эффективно описывать сложные математические модели, используемые в различных научных областях. Например, представление Фурье-Чебышева позволяет аппроксимировать функции с высокой точностью, что важно для численного моделирования. Обнаружение нулевого режима Фурье в плоскости указывает на специфические свойства системы, которые могут быть упущены при других подходах к анализу. Использование подобных математических представлений позволяет не только формально описать метод, но и выявить потенциальные ошибки или несоответствия в его реализации, обеспечивая более надежную и точную верификацию научных результатов.
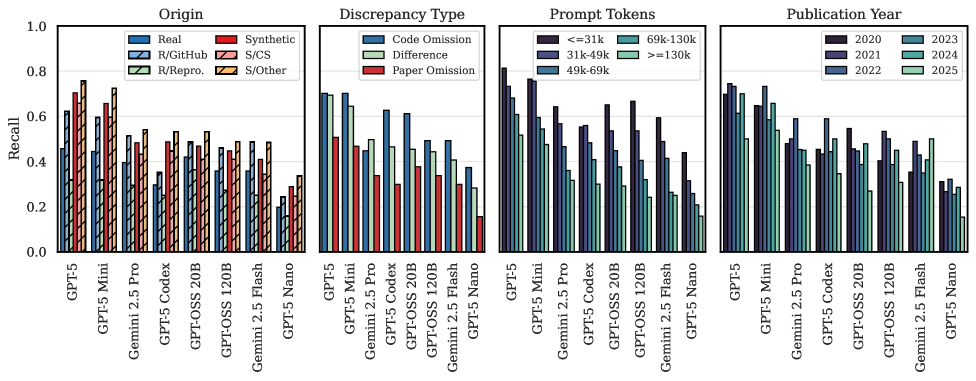
Несмотря на значительный прогресс в области больших языковых моделей (LLM), современные системы, такие как GPT-5, демонстрируют лишь 45.7% полноту выявления расхождений в наборе данных SciCoQA. Этот показатель подчеркивает сохраняющиеся трудности в автоматизированной верификации научных и технических текстов. Ограниченная способность LLM к точному определению ошибок и несоответствий указывает на необходимость дальнейших исследований и разработки более надежных методов для обеспечения достоверности и воспроизводимости научных результатов. Низкая полнота выявления расхождений свидетельствует о том, что даже самые передовые модели пока не способны полностью заменить экспертную оценку в критически важных областях, требующих высокой точности и надежности.
Исследование выявило высокую корреляцию (r=0.94) между способностью больших языковых моделей (LLM) обнаруживать несоответствия в реальных и искусственно сгенерированных данных. Этот результат демонстрирует, что разработанные синтетические данные эффективно отражают сложность и разнообразие реальных ошибок, что позволяет использовать их для надежной оценки устойчивости и эффективности LLM в задачах автоматической верификации. Использование искусственно сгенерированных данных предоставляет возможность контролируемого тестирования и масштабируемой оценки, обходя ограничения, связанные с получением и аннотированием больших объемов реальных данных, и подтверждает применимость предложенного подхода для улучшения надежности систем автоматической проверки.
Исследования показали, что современные большие языковые модели, такие как Gemini 2.5 Pro, демонстрируют снижение эффективности на 10,2% при выявлении несоответствий в коде, написанном не на языке Python. Данный факт подчеркивает существенные трудности, связанные с автоматизированной верификацией кода на различных языках программирования. Очевидно, что модели лучше справляются с анализом синтаксиса и семантики, когда обучаются преимущественно на данных, представленных на одном конкретном языке. Это указывает на необходимость разработки методов, позволяющих повысить языковую универсальность подобных систем и обеспечить их надежную работу с широким спектром языков программирования, что критически важно для автоматизации проверки научных вычислений и программного обеспечения.
Исследование, представленное в данной работе, подчеркивает важность согласованности между научными публикациями и их кодовыми реализациями. Данный аспект напрямую связан с обеспечением воспроизводимости результатов, что является краеугольным камнем современной науки. В этой связи, замечательно попадает в суть фраза Андрея Николаевича Колмогорова: «Математика — это искусство видеть скрытое». Подобно тому, как математик ищет закономерности, скрытые в абстрактных символах, SciCoQA стремится выявить несоответствия между описанием алгоритма в научной статье и его практической реализацией в коде. Подобный подход позволяет не только повысить надежность научных исследований, но и способствует более глубокому пониманию лежащих в их основе принципов.
Что впереди?
Представленный труд, подобно любому инструменту, обнажает не столько ответы, сколько границы познания. Создание набора данных SciCoQA — это не фиксация состояния, а лишь первый шаг к пониманию хрупкости связи между научной мыслью и её кодовым воплощением. Инциденты несоответствия, выявленные с помощью подобного рода инструментов, следует рассматривать не как ошибки, а как неизбежные шаги системы на пути к зрелости, как проявления её адаптации к среде времени.
Очевидно, что текущая оценка возможностей больших языковых моделей (LLM) в области воспроизводимости научных вычислений далека от завершения. Проблема не в том, чтобы научить модель находить ошибки, а в том, чтобы понять природу этих ошибок, их контекст и влияние на целостность научного знания. Будущие исследования должны сосредоточиться на разработке метрик, отражающих не только наличие, но и сущность несоответствий, а также на изучении способов автоматического исправления этих несоответствий.
Время — не метрика, а среда, в которой существуют системы. По мере того, как научные вычисления становятся все более сложными, а код — все более объемным, задача обеспечения воспроизводимости будет требовать не просто инструментов обнаружения ошибок, а глубокого понимания процессов эволюции кода, адаптации к изменяющимся требованиям и сохранения целостности научного знания во времени. Все системы стареют — вопрос лишь в том, делают ли они это достойно.
Оригинал статьи: https://arxiv.org/pdf/2601.12910.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Сердце музыки: открытые модели для создания композиций
- Самообучающиеся нейросети: новый подход к работе с инструментами
- Action100M: Видео, которые учат машины видеть мир
- Геометрия в нейросетях: новая архитектура Versor
- Бинарные нейросети под защитой: новый подход к проверке устойчивости
- Искусственный интеллект в науке: новый этап сотрудничества
- Обучение агентов: Видео как ключ к освоению компьютера
- Первый кадр: Ключ к персонализации видео
2026-01-21 16:20