Автор: Денис Аветисян
Новое исследование показывает, что существующие методы выявления использования защищенного контента большими языковыми моделями легко обойти, используя семантически эквивалентные перефразировки.
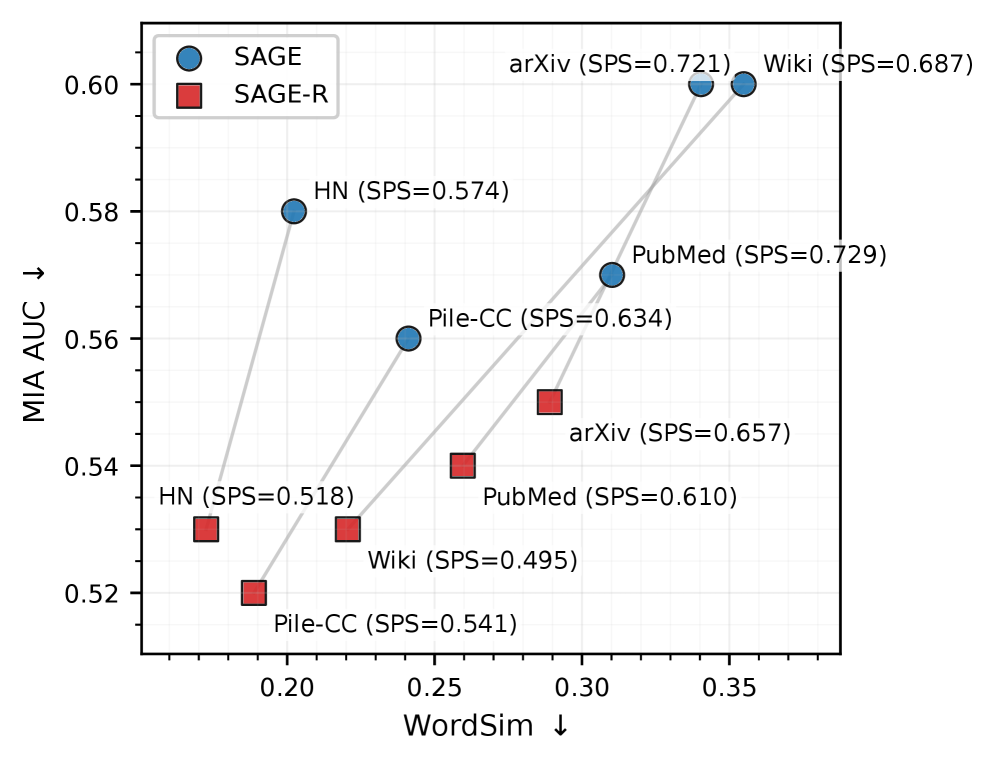
Атаки на определение членства становятся ненадежными для аудита авторских прав из-за уязвимости к семантически сохраняющим перефразировкам больших языковых моделей.
Несмотря на растущий интерес к аудиту больших языковых моделей (LLM) на предмет использования охраняемых авторским правом текстов, надежность существующих методов остается под вопросом. В работе ‘On the Evidentiary Limits of Membership Inference for Copyright Auditing’ исследуются ограничения атак на определение принадлежности к обучающей выборке (Membership Inference Attacks, MIA) в условиях, когда разработчик модели намеренно скрывает данные, сохраняя при этом семантическое содержание. Показано, что MIA становятся менее эффективными при использовании семантически эквивалентных перефразировок обучающих данных, созданных с помощью предложенного фреймворка SAGE, что указывает на их уязвимость к подобным преобразованиям. Достаточны ли существующие методы аудита для надежного выявления нарушений авторских прав в LLM, и какие альтернативные подходы могут обеспечить более устойчивые результаты?
Конфиденциальность и Уязвимости Больших Языковых Моделей
Современные большие языковые модели демонстрируют впечатляющие результаты в различных задачах, однако эта производительность достигается ценой потенциальной уязвимости к так называемым атакам на определение членства. Суть этих атак заключается в том, что злоумышленник, анализируя поведение модели, может определить, использовался ли конкретный фрагмент данных при её обучении. Это представляет серьёзную угрозу конфиденциальности, поскольку модель, по сути, «помнит» и может неявно раскрыть конфиденциальную информацию, содержащуюся в обучающем наборе данных. Успешность подобных атак, часто демонстрирующая высокие показатели точности, подчеркивает необходимость разработки эффективных механизмов защиты данных, используемых для обучения моделей, и обеспечения их безопасного применения.
Атаки, направленные на выявление принадлежности данных к обучающей выборке языковой модели, используют тонкие сигналы, оставшиеся в параметрах модели после обучения. В частности, снижение потерь (Loss Reduction) при повторной тренировке модели на конкретном образце указывает на его влияние. Соотношение правдоподобия (Likelihood Ratios) позволяет оценить, насколько вероятен конкретный образец по сравнению с другими, а сигналы калибровки (Calibration Signals) демонстрируют, насколько уверенно модель предсказывает результаты для данных, которые она видела в процессе обучения. Комбинируя эти сигналы, злоумышленники могут с высокой точностью определить, использовался ли конкретный образец данных при создании модели, что ставит под угрозу конфиденциальность информации, содержащейся в обучающей выборке.
С увеличением масштаба больших языковых моделей (LLM) уязвимость к атакам, направленным на раскрытие конфиденциальности данных, становится особенно острой. Чем больше параметров и данных используется для обучения модели, тем сильнее становятся сигналы, которые могут быть использованы злоумышленниками для определения, включалась ли конкретная информация в обучающую выборку. Это связано с тем, что модель, обученная на обширном наборе данных, может запоминать специфические примеры, что делает её более восприимчивой к атакам на основе вывода о членстве. В связи с этим, разработка и внедрение надежных механизмов защиты конфиденциальности становится не просто желательной, но и необходимой мерой для обеспечения ответственного развития и внедрения LLM, а также поддержания доверия пользователей к этим технологиям.
Успешное противодействие атакам, направленным на выявление данных, использованных при обучении больших языковых моделей, является ключевым фактором для сохранения доверия пользователей и обеспечения ответственной разработки искусственного интеллекта. Исследования демонстрируют, что атаки на определение членства (Membership Inference Attacks) достигают высокой точности — часто значение AUC превышает 0.8, что указывает на значительную вероятность успешного определения, содержался ли конкретный фрагмент данных в обучающем наборе модели. Эта уязвимость представляет серьезную угрозу конфиденциальности, поскольку раскрытие информации о составе обучающих данных может привести к несанкционированному доступу к личным данным или интеллектуальной собственности, подрывая основу безопасного и этичного использования подобных технологий.

Сокрытие Данных: SAGE и Сохранение Семантики
Метод SAGE (структурно-ориентированное семантическое перефразирование) представляет собой перспективный подход к сокрытию данных, используемых для обучения моделей машинного обучения. В его основе лежит генерация семантически близких альтернатив исходным данным, что позволяет снизить риск извлечения конфиденциальной информации, содержащейся в обучающем наборе. SAGE не просто заменяет слова синонимами, а учитывает структуру предложений и контекст, чтобы сохранить смысл и полезность данных для дальнейшего обучения, одновременно затрудняя идентификацию отдельных записей.
В основе конвейера SAGE лежит использование методов перефразирования для создания вариаций обучающих данных, сохраняя при этом их полезность для обучения моделей. Данный подход предполагает автоматическую генерацию семантически эквивалентных альтернатив исходным данным, что позволяет внести изменения в данные, не нарушая их информационное содержание. Целью является создание набора данных, который сохраняет способность эффективно обучать модели машинного обучения, одновременно снижая риск утечки конфиденциальной информации или успешных атак на определение принадлежности к обучающей выборке. Используемые алгоритмы перефразирования адаптированы для сохранения ключевых семантических признаков и отношений в данных.
Ключевым элементом SAGE является оценка семантической устойчивости (Semantic Persistence Score, SPS), предназначенная для обеспечения сохранения значимой информации в процессе перефразирования данных. Экспериментальные результаты показывают, что SAGE достигает значений SPS в диапазоне от 0.6 до 0.8, что свидетельствует о высокой степени сохранения семантической целостности преобразованных данных. Данный показатель является важным критерием оценки эффективности подхода, гарантируя, что модифицированные данные остаются полезными для обучения моделей, несмотря на внесенные изменения.
Эффективность конвейера SAGE и SAGE-R в снижении уязвимости к атакам выявления членства (Membership Inference Attacks) обеспечивается применением разреженных автоэнкодеров (Sparse Autoencoders). Эти автоэнкодеры, функционируя как часть процесса трансформации данных, способствуют сохранению семантической целостности, что критически важно для поддержания полезности данных для обучения моделей при одновременном затруднении идентификации данных, использованных в процессе обучения. Подтверждением эффективности является существенное снижение показателя TPR@1%FPR (True Positive Rate при 1% False Positive Rate) после применения SAGE и SAGE-R, что свидетельствует о значительном повышении устойчивости к данным типам атак.
Юридические Аспекты: Авторское Право и Использование Данных
Генерация и использование обфусцированных данных сопряжены со сложными вопросами авторского права, потенциально приводящими к нарушению авторских прав. Обфускация, хоть и изменяет исходные данные, не отменяет их первоначального статуса охраняемого объекта интеллектуальной собственности. Если обфусцированные данные содержат элементы, защищенные авторским правом (тексты, изображения, код и т.д.), их использование без разрешения правообладателя может рассматриваться как нарушение. Особенно это актуально при создании производных работ или коммерческом использовании обфусцированных данных, где необходимо доказать законность происхождения и отсутствие нарушений прав третьих лиц. Отсутствие видимой копии оригинального произведения не является достаточным основанием для легального использования, и суды могут применять принципы существенного сходства для определения нарушения.
Методы вывода данных о наборе данных (Dataset Inference) позволяют определить происхождение и характеристики данных, использованных для обучения моделей машинного обучения. Эти методы анализируют выходные данные модели для восстановления информации о входных данных, что может выявить использование защищенных авторским правом материалов без соответствующего разрешения. Выявление конкретных элементов обучающего набора данных, даже если модель не воспроизводит их точно, может повлечь за собой юридическую ответственность за нарушение авторских прав, особенно если данные были получены или использованы неправомерно. Точность этих методов постоянно растет, увеличивая риск для разработчиков и пользователей моделей, использующих данные с неясным происхождением.
Протокол “Судья-Обвинитель-Обвиняемый” представляет собой структурированный подход к анализу споров, связанных с нарушениями авторских прав и использованием данных, возникающих при обучении моделей машинного обучения. В рамках данного протокола, «судья» выступает в роли нейтрального арбитра, «обвинитель» представляет доказательства нарушения, а «обвиняемый» предоставляет аргументы в свою защиту. Протокол включает в себя последовательное представление доказательств о происхождении данных, анализе сходства между исходными данными и данными, использованными для обучения, а также оценку степени влияния исходных данных на выходные данные обученной модели. Определение ответственности основывается на установлении факта копирования, существенности скопированной части и доказательстве причинно-следственной связи между использованием исходных данных и нарушением авторских прав.
Водяные знаки могут служить мерой защиты авторских прав и подтверждения подлинности данных, однако их эффективность не является абсолютной. Существуют различные типы водяных знаков, включая видимые и невидимые, цифровые и статистические, каждый из которых имеет свои уязвимости. Атаки, направленные на удаление или искажение водяных знаков, такие как добавление шума, сжатие данных или применение фильтров, могут успешно нивелировать защиту. Кроме того, водяные знаки могут быть повреждены в процессе обработки данных или при передаче, что затрудняет их обнаружение и проверку. Надежность водяных знаков напрямую зависит от используемого алгоритма, параметров внедрения и устойчивости к различным видам атак и преобразований данных.
Эффективное и Безопасное Дообучение: LoRA и За Его Пределами
Метод адаптации низкого ранга (LoRA) представляет собой эффективный подход к дообучению больших языковых моделей, позволяющий значительно сократить количество изменяемых параметров. Вместо модификации всех весов модели, LoRA фокусируется на обучении лишь небольшого числа низкоранговых матриц, что существенно снижает вычислительные затраты и потребность в больших объемах данных. Такой подход не только ускоряет процесс дообучения, но и делает его более доступным для исследователей и организаций с ограниченными ресурсами. Сокращение числа обучаемых параметров также снижает риск переобучения и улучшает обобщающую способность модели на новых данных, обеспечивая высокую производительность при минимальных изменениях исходных весов.
Метод адаптации с низким рангом (LoRA) существенно снижает риск раскрытия конфиденциальной информации при дообучении больших языковых моделей. Традиционное дообучение требует модификации значительного числа параметров модели, что делает её уязвимой к атакам, направленным на извлечение данных, использованных при обучении. LoRA, напротив, фокусируется на обучении лишь небольшой части параметров, сохраняя большую часть весов модели неизменными. Это ограничивает возможность злоумышленникам восстановить информацию о тренировочных данных, поскольку изменения, вносимые в модель, минимальны и не отражают полную картину исходного набора данных. Таким образом, LoRA обеспечивает более высокий уровень конфиденциальности данных, не жертвуя при этом производительностью модели.
Метод адаптации с низким рангом (LoRA) представляет собой компромисс между эффективностью, конфиденциальностью и вычислительными затратами. В отличие от полной тонкой настройки, требующей модификации огромного количества параметров, LoRA фокусируется на оптимизации лишь небольшой части, что значительно снижает потребность в вычислительных ресурсах и времени обучения. При этом, минимизируя объем изменяемых данных, снижается и риск утечки конфиденциальной информации, содержащейся в обучающем наборе. Такой подход позволяет достичь сопоставимой производительности с полной тонкой настройкой, сохраняя при этом баланс между скоростью, стоимостью и уровнем защиты данных, что особенно важно при работе с чувствительной информацией и ограниченными ресурсами.
Исследования показывают, что объединение адаптации с низким рангом (LoRA) с методами дифференциальной приватности способно значительно усилить защиту данных при обучении моделей. В частности, применение алгоритмов SAGE и SAGE-R демонстрирует существенное снижение показателей AUC (Area Under the Curve) по сравнению с полным дообучением. Это указывает на заметное уменьшение утечки информации о членстве в обучающей выборке — то есть, снижение вероятности определения, использовался ли конкретный пример данных при обучении модели. Таким образом, предложенный подход позволяет достичь баланса между эффективностью дообучения, сохранением конфиденциальности данных и снижением риска несанкционированного доступа к информации, содержащейся в обучающей выборке.
Исследование показывает, что существующие методы выявления принадлежности к обучающей выборке подвержены уязвимостям при использовании семантически сохраняющих перефразировок. Это подрывает надежность подобных атак для аудита авторских прав больших языковых моделей. Как отметил Бертран Рассел: «Всё ломается по границам ответственности — если их не видно, скоро будет больно». Подобно тому, как нечетко определенные границы ответственности приводят к системным сбоям, так и уязвимости в алгоритмах аудита подрывают доверие к системам защиты авторских прав. Очевидно, что необходимы более устойчивые методы, учитывающие возможность намеренного искажения данных для обхода существующих проверок, чтобы обеспечить целостность и надежность систем машинного обучения.
Куда двигаться дальше?
Представленная работа демонстрирует, что существующие методы выявления членства, кажущиеся столь элегантными в своей простоте, оказываются уязвимы перед даже умеренными преобразованиями текста. Эта уязвимость, проистекающая из сохранения семантики, наводит на мысль, что надеяться на них в качестве надежного инструмента для аудита авторских прав в больших языковых моделях — все равно что строить крепость из песка. Недостаточно просто обнаружить, что модель «видела» определенный фрагмент; необходимо понимать, как глубоко этот фрагмент интегрирован в ее внутреннюю структуру.
Неизбежно возникает вопрос: где искать истинные маркеры членства? Возможно, ключ кроется не в поверхностном анализе выходных данных, а в исследовании латентного пространства модели, в поиске тонких изменений в ее параметрах, вызванных включением конкретного фрагмента данных. Или, возможно, сама концепция «членства» нуждается в пересмотре; модель, обучающаяся на огромном корпусе текстов, редко сохраняет их в неизменном виде, и попытка обнаружить точное совпадение может быть принципиально ошибочной.
Дальнейшие исследования должны сосредоточиться на разработке методов, устойчивых к семантическому парафразированию, и на изучении более глубоких свойств моделей, определяющих их способность воспроизводить или адаптировать защищенный авторским правом материал. В конечном итоге, создание действительно надежного инструмента аудита потребует не только технического совершенства, но и философского понимания того, как информация хранится и обрабатывается в этих сложных системах.
Оригинал статьи: https://arxiv.org/pdf/2601.12937.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Белки-хамелеоны: Пределы предсказания гибкости структуры
- Сердце музыки: открытые модели для создания композиций
- Энергоэффективность сотовой сети: обучение с подкреплением и управление режимами сна
- Пространственное мышление: новый взгляд на 3D-рассуждения
- Ускорение сжатия изображений: новый взгляд на оптимизацию второго порядка
- Думай глубже: как искусственный интеллект помогает нам мыслить критически
- Самообучающиеся модели мира: логика и постоянное совершенствование
- Метаповерхностный интерферометр: управление светом нового поколения
- Первый кадр: Ключ к персонализации видео
- Маленькие модели – большие возможности: Искусственный интеллект в поиске онкологических исследований
2026-01-21 17:39