Автор: Денис Аветисян
Новый подход к построению крупномасштабного графа синонимов для турецкого языка позволяет значительно повысить точность и преодолеть распространенные проблемы, связанные с изменением значений слов и проникновением антонимов.
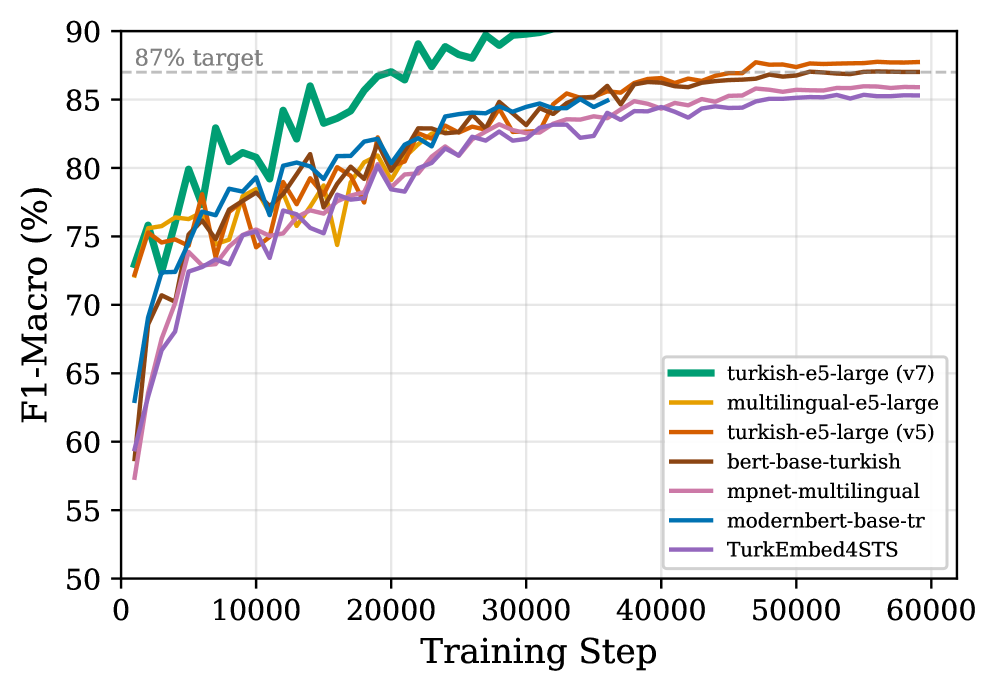
Предложена методика создания 15-миллионного графа синонимов турецкого языка с применением алгоритмов кластеризации, учитывающих семантический дрейф, и аугментации данных с помощью больших языковых моделей.
Нейронные сети часто испытывают трудности в различении синонимов и антонимов, что приводит к неточностям при построении семантических графов. В работе «Beyond Cosine Similarity: Taming Semantic Drift and Antonym Intrusion in a 15-Million Node Turkish Synonym Graph» представлен новый подход к созданию крупномасштабного турецкого синонимического графа, включающего 15 миллионов узлов. Предложенная методология, основанная на аугментации данных с помощью LLM, специализированном классификаторе семантических связей и алгоритме кластеризации, устойчивом к семантическому дрейфу, обеспечивает высокую точность и позволяет эффективно решать проблему вторжения антонимов. Сможет ли данная технология существенно улучшить качество семантического поиска и генерации текста для языков с богатой морфологией и ограниченными лингвистическими ресурсами?
Ограничения Традиционного Семантического Сходства
Несмотря на свою основополагающую роль в создании векторных представлений слов, такие методы, как Word2Vec и FastText, зачастую не способны адекватно различать семантические связи. В результате, при определении синонимов, эти модели склонны к ошибкам, объединяя слова, связанные по-разному — например, путая близкие по значению понятия с антонимами или гипонимами. Эта проблема особенно актуальна при работе с языками, обладающими сложной морфологией, где нюансы значений могут быть замаскированы вариативностью словоформ, что приводит к неточным результатам при анализе семантической близости и затрудняет выявление истинных синонимов.
Простая косинусная мера схожести, широко используемая для определения семантической близости слов, зачастую оказывается недостаточной для точного различения синонимов, антонимов и когипонимов. Особенно ярко эта проблема проявляется в языках с богатой морфологией, таких как турецкий, где одно и то же понятие может быть выражено множеством различных форм слов, различающихся по суффиксам и другим морфологическим признакам. Использование исключительно косинусного сходства игнорирует эти нюансы, приводя к ошибочной интерпретации семантических отношений и снижая точность анализа текста. В результате, слова с противоположным значением могут быть ошибочно классифицированы как синонимы, а слова, относящиеся к одной категории, — как семантически далёкие.
Отсутствие надежных, машиночитаемых ресурсов синонимов для языков, таких как турецкий, значительно усугубляет проблемы эффективного семантического анализа. Это особенно заметно при попытках точного определения семантических связей между словами, когда стандартные методы часто дают неверные результаты. Разработанная система успешно решает эту проблему, достигая показателя F1-macro в 0.90 при классификации семантических отношений. Такой высокий результат свидетельствует о способности системы корректно различать различные типы семантической близости и удаленности, предоставляя более точные и надежные данные для дальнейшей обработки естественного языка.
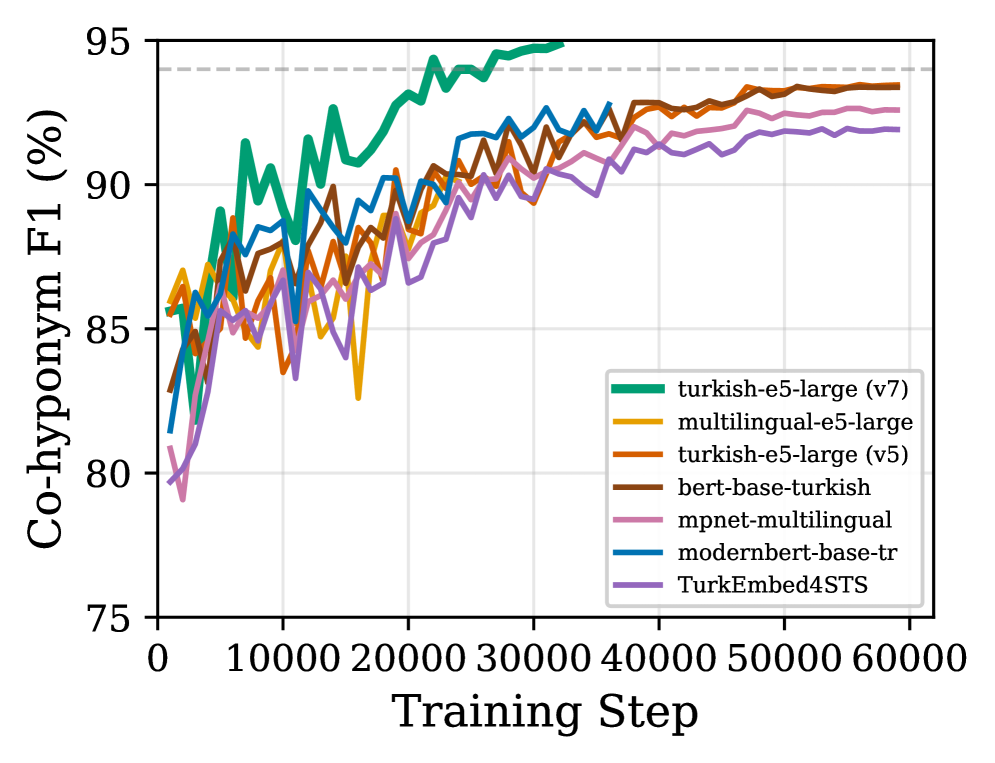
LLM-Усиленный Семантический Синтез
Для решения проблемы недостатка размеченных данных о семантических связях, предложен метод LLM-Усиленного Синтеза, использующий языковую модель Gemini 2.5-Flash для автоматической генерации пар слов и соответствующих им семантических отношений. Данный подход позволяет создавать размеченные данные в больших объемах, компенсируя ограниченность существующих ресурсов и обеспечивая основу для обучения моделей, способных различать различные типы семантических связей, такие как синонимия, антонимия и когипонимия. Автоматически сгенерированные данные дополняются извлечением информации из словарей для обеспечения баланса между автоматической генерацией и экспертной оценкой.
Для обеспечения баланса между автоматической генерацией данных и использованием проверенных знаний, процесс дополняется извлечением данных из словарей. Этот метод позволяет создать начальный набор обучающих данных, служащий основой для последующей работы с LLM. Извлеченные из словарей пары слов и их семантические связи используются для предварительного обучения и валидации модели, что повышает надежность и точность автоматически сгенерированных данных. Такой подход позволяет уменьшить зависимость от исключительно синтетических данных и обеспечить более качественное обучение модели, способной различать синонимы, антонимы и когипонимы.
Для обучения модели многоклассовой дискриминации используется архитектура Turkish-e5-large, демонстрирующая повышенную точность в различении синонимов, антонимов и когипонимов. В ходе тестирования модель достигла показателя F1-score в 0.948 для когипонимов и 0.831 для синонимов, что свидетельствует о высокой эффективности в задачах семантической классификации и понимания взаимосвязей между словами.

Мягкая Кластеризация для Нюансированного Семантического Представления
В нашей системе используется метод мягкой кластеризации (Soft Clustering), позволяющий терминам одновременно принадлежать к нескольким кластерам. Это необходимо для отражения полисемии — способности слов иметь множественные значения. Начальное распределение терминов по кандидатам в кластеры осуществляется на этапе расширения (Expansion Stage), после чего применяется алгоритм мягкой кластеризации для определения степени принадлежности каждого термина к различным семантическим группам. Такой подход позволяет более точно моделировать семантические связи, избегая жесткого отнесения термина к единственному значению, что особенно важно при работе с большим объемом текстовых данных.
Для идентификации и уточнения семантических групп в нашей системе используются методы, основанные на модульности, такие как алгоритмы Лейдена и Лувена. Эти алгоритмы стремятся максимизировать модульность графа, определяемую как плотность связей внутри сообществ по сравнению с плотностью связей между сообществами. Алгоритм Лейдена, в частности, обеспечивает более устойчивые иерархические кластеры по сравнению с классическим алгоритмом Лувена, за счет оптимизации разрешения и обработки небольших сообществ. Оба алгоритма характеризуются высокой вычислительной эффективностью, что позволяет применять их к графам, содержащим миллионы узлов и связей, и обеспечивает масштабируемость решения.
В результате применения разработанного подхода был сформирован граф синонимов, состоящий из 2 905 071 кластера, построенных на основе 15 миллионов терминов. Медианный размер кластера составляет 3, средний — 4,58. Для предотвращения избыточной кластеризации и устранения слабых транзитивных связей на этапе редукции вводится пороговое значение коэффициента пересечения (Intersection-Ratio Threshold). Для разрешения неоднозначностей при этом используется метод топологического голосования, позволяющий оптимизировать структуру графа и повысить его точность.
Эффективная Реализация и Масштабируемость
Для обеспечения быстрой обработки больших объемов данных используется библиотека FAISS, предназначенная для эффективного поиска ближайших соседей и кластеризации плотных векторов. FAISS позволяет значительно ускорить операции сравнения и группировки данных, что особенно важно при работе с высокоразмерными векторными представлениями, полученными, например, из моделей глубокого обучения. Благодаря оптимизированным алгоритмам и индексации, FAISS обеспечивает масштабируемость и производительность, необходимые для анализа и обработки масштабных наборов семантических данных, открывая возможности для широкого спектра приложений в области обработки естественного языка и анализа информации.
Для повышения эффективности и масштабируемости вычислений применяются методы оптимизации, такие как нормализация векторов по L2-норме и использование 16-битной точности с плавающей точкой (BF16). Нормализация по L2-норме стандартизирует векторы, снижая влияние их величины и упрощая вычисления, что приводит к уменьшению потребляемой памяти. Переход к BF16, в свою очередь, позволяет сократить размер данных, используемых в вычислениях, вдвое по сравнению с традиционной 32-битной точностью, значительно ускоряя обработку данных и снижая требования к вычислительным ресурсам. Сочетание этих методов обеспечивает возможность эффективной работы с большими объемами семантических данных и позволяет масштабировать систему для решения более сложных задач.
Оптимизация вычислительных процессов позволила эффективно обрабатывать и кластеризовать большие объемы семантических данных, достигнув общего значения F1-меры макро 0.90. Этот результат свидетельствует о высокой точности и надежности разработанного подхода к анализу семантических связей. Успешное масштабирование алгоритмов открывает возможности для применения в широком спектре задач обработки естественного языка, включая интеллектуальный поиск, анализ тональности и автоматическую классификацию текстов, значительно расширяя горизонты применения в различных областях, от анализа социальных медиа до создания интеллектуальных помощников.
В представленной работе авторы стремятся к созданию максимально ясного и точного синонимического графа для турецкого языка, тщательно отсеивая семантический шум и нежелательные антонимические включения. Этот подход находит отклик в словах Брайана Кернигана: «Простота — высшая степень совершенства». Истинное мастерство проявляется не в сложности алгоритмов или объеме данных, а в способности достичь желаемого результата с минимальными издержками. Как и в кодировании, где каждый комментарий свидетельствует о недостаточной ясности, в построении семантических графов каждая ошибка требует пересмотра базовых принципов. Авторы, используя LLM-дополненную генерацию данных и алгоритм кластеризации, ориентированный на семантический дрейф, демонстрируют стремление к этой простоте и элегантности.
Куда же дальше?
Создание графа синонимов, претендующего на точность в пятнадцати миллионах узлов, неизбежно обнажает границы нашего понимания семантики. Авторы, безусловно, справились с острыми углами — антонимической интрузией и семантическим дрейфом — но они назвали это «фреймворком», чтобы скрыть панику, свойственную любой попытке формализации изменчивого языка. Проблема не в усовершенствовании алгоритмов кластеризации, а в осознании того, что сама концепция «синонима» — это упрощение, удобная фикция для машинного разума, но чуждая человеческому.
Будущие исследования, вероятно, сосредоточатся на динамической природе семантики. Статичный граф, каким бы точным он ни был на момент создания, быстро устареет. Более плодотворным представляется подход к моделированию скорости семантического дрейфа, к оценке вероятности того, что слово приобретет новое значение или утратит старое. И, возможно, пора признать, что истинная сложность языка не в количестве синонимов, а в контексте, в тонких оттенках, которые ускользают от любого формального представления.
Простота, как всегда, остаётся идеалом. Стремление к совершенству не в добавлении новых слоёв абстракции, а в отбрасывании всего лишнего. Истинное мастерство заключается в умении выразить сложную мысль в нескольких лаконичных словах — задача, непосильная даже для самых мощных языковых моделей.
Оригинал статьи: https://arxiv.org/pdf/2601.13251.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
2026-01-22 02:31