Автор: Денис Аветисян
Новая версия модели RoboBrain расширяет возможности роботов в восприятии окружающего мира и прогнозировании событий, приближая их к более разумному взаимодействию с реальностью.
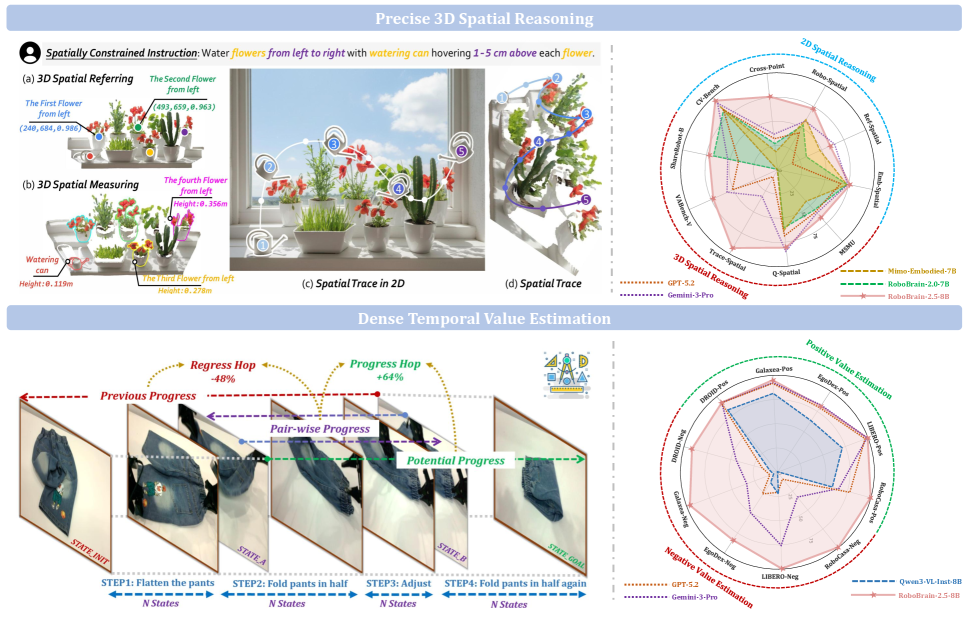
Представлена фундаментальная модель RoboBrain 2.5, улучшающая пространственное мышление, временное моделирование и оценку ценности для робототехники.
Несмотря на значительные успехи в области искусственного интеллекта, наделение роботов полноценным пониманием пространства и времени остается сложной задачей. В статье ‘RoboBrain 2.5: Depth in Sight, Time in Mind’ представлена новая версия фундаментальной модели воплощенного ИИ, существенно расширяющая возможности пространственного и временного рассуждения. Ключевым нововведением является переход к трехмерному восприятию глубины и точной оценке временных интервалов, что позволяет модели генерировать реалистичные траектории манипуляций с объектами и прогнозировать их состояние. Не откроет ли это путь к созданию более адаптивных и надежных роботов, способных эффективно взаимодействовать с физическим миром?
Постижение Сложности: Вызов Воплощенного Интеллекта
Традиционные системы искусственного интеллекта демонстрируют впечатляющие результаты в виртуальных средах, где правила и ограничения четко определены, а данные поступают в идеальном формате. Однако, при столкновении с реальностью, эти системы сталкиваются с непреодолимыми трудностями. Физический мир характеризуется неопределенностью, шумами, неполнотой информации и постоянными изменениями. Простые задачи, такие как захват предмета или навигация в пространстве, требуют от робота не только распознавания объектов, но и учета их веса, текстуры, положения в пространстве, а также предвидения возможных препятствий и изменений. Эта сложность обусловлена тем, что виртуальные модели часто упрощают реальность, игнорируя важные физические параметры и взаимосвязи, что делает перенос алгоритмов из виртуальной среды в физическую проблематичным и требующим значительной адаптации.
Эффективное манипулирование объектами требует не просто их идентификации, но и точного понимания пространственных отношений и гибкого управления движениями. Исследования показывают, что системы, способные лишь распознавать предметы, сталкиваются с трудностями при выполнении задач, требующих адаптации к меняющимся условиям или сложным траекториям. Например, захват объекта, расположенного за препятствием, или перемещение хрупкого предмета без повреждений, требуют не только визуального анализа, но и постоянной корректировки действий на основе обратной связи от сенсоров. Таким образом, способность к пространственному рассуждению и адаптивному контролю является ключевым фактором для создания действительно интеллектуальных систем, способных взаимодействовать с физическим миром.
Существующие методы искусственного интеллекта часто сталкиваются с трудностями при преобразовании абстрактных целей в конкретные моторные команды. Проблема заключается в так называемом “семантическом разрыве” — несоответствии между высокоуровневым пониманием задачи (“взять яблоко”) и низкоуровневыми сигналами, управляющими моторами и манипуляторами. Вместо непосредственного перевода цели в действие, системы часто полагаются на сложные и хрупкие цепочки промежуточных шагов, требующие точного определения последовательности движений. Это приводит к низкой адаптивности в непредсказуемых ситуациях и затрудняет выполнение задач в реальном, динамичном окружении. Преодоление этого разрыва требует разработки новых алгоритмов, способных к более глубокому пониманию намерений и гибкому планированию действий, учитывающих физические ограничения и возможности системы.
Для достижения подлинного воплощенного интеллекта необходима система, способная к комплексному рассуждению о пространстве, времени и действиях. Она должна не просто воспринимать окружающую среду, но и прогнозировать последствия своих действий, планировать последовательности манипуляций и адаптироваться к меняющимся условиям. Такая система требует интеграции различных когнитивных функций — от визуального восприятия и пространственной ориентации до планирования и управления моторикой. Иными словами, необходим механизм, объединяющий понимание “что”, “где” и “когда” с возможностью реализации намеченных действий, создавая единую, непрерывную петлю восприятия, планирования и исполнения, что позволит роботу эффективно взаимодействовать с физическим миром и решать сложные задачи в реальном времени.

RoboBrain 2.5: Основа для Воплощенного Рассуждения
RoboBrain 2.5 представляет собой фундаментальную модель искусственного интеллекта, разработанную для объединения семантического рассуждения и физической манипуляции. В отличие от традиционных моделей, ориентированных исключительно на обработку данных или управление движением, RoboBrain 2.5 стремится к интеграции понимания задач высокого уровня (семантики) с непосредственным управлением физическими действиями. Это достигается за счет архитектуры, позволяющей модели интерпретировать инструкции на естественном языке, планировать последовательность действий и осуществлять их в физическом мире. Фокус на “воплощенном” ИИ означает, что модель функционирует в контексте физического тела (робота), что требует учета ограничений и возможностей этого тела при планировании и выполнении задач.
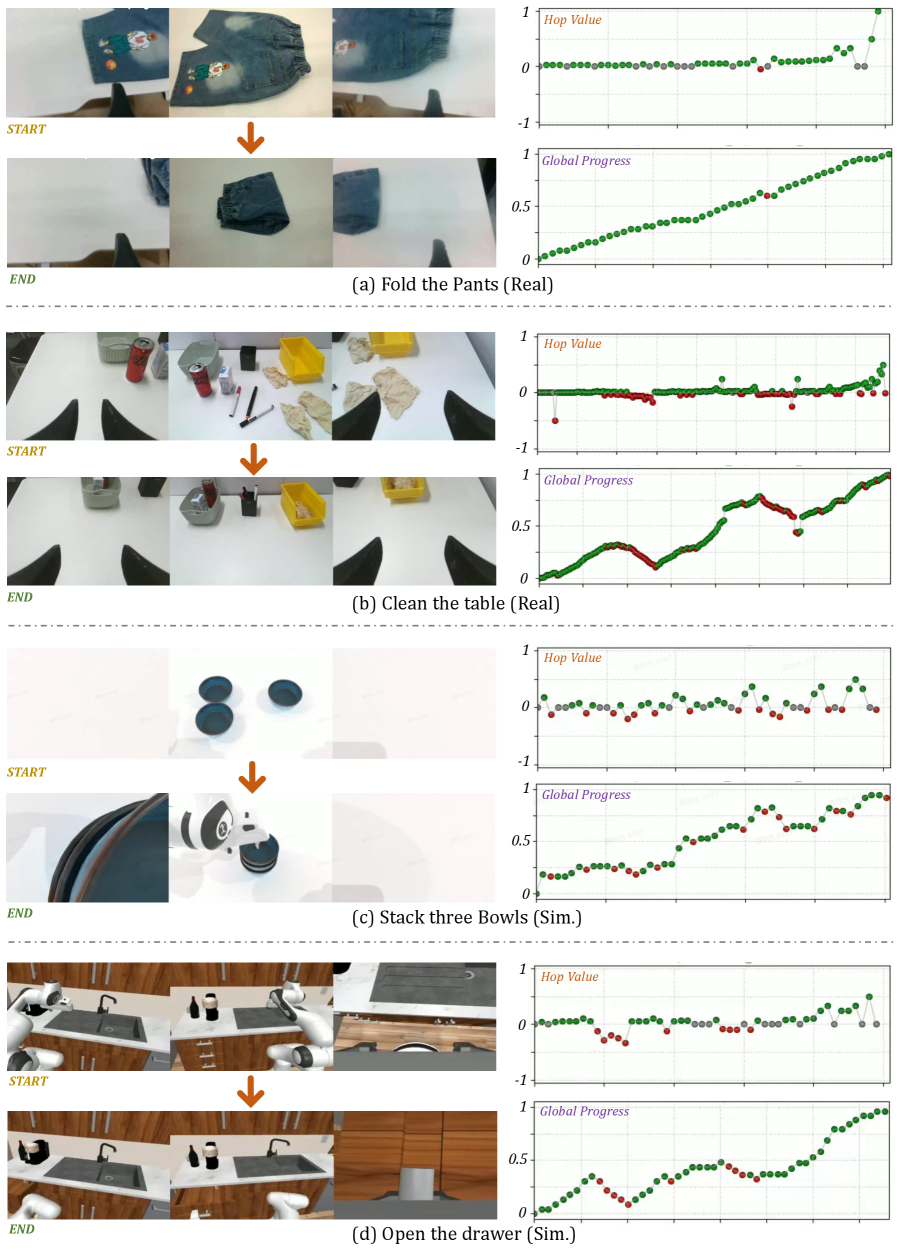
RoboBrain 2.5 использует метод DenseTemporalValueEstimation (DTVE) для обеспечения обратной связи в реальном времени, учитывающей каждый шаг выполнения действия. DTVE позволяет модели оценивать промежуточные результаты и корректировать траекторию движения манипулятора, что критически важно для эффективного управления в замкнутом цикле. В отличие от традиционных методов, которые оценивают только конечный результат, DTVE предоставляет детальную информацию о каждом шаге, позволяя модели адаптироваться к изменяющимся условиям и избегать ошибок. Это особенно важно для сложных задач манипулирования, где даже небольшое отклонение может привести к неудаче, и позволяет значительно повысить надежность и точность выполнения задач.
В RoboBrain 2.5 реализована интеграция трехмерного пространственного рассуждения, что позволило выйти за рамки двухмерных представлений об окружающей среде. Это достигается за счет использования трехмерных моделей объектов и сцен, что обеспечивает более точное восприятие глубины, расстояний и ориентации. В отличие от систем, оперирующих только с двухмерными данными (например, изображениями), RoboBrain 2.5 способен учитывать полный объемный контекст, что критически важно для успешного планирования и выполнения манипулятивных задач, требующих точного позиционирования и взаимодействия с объектами в трехмерном пространстве. Использование трехмерных данных значительно повышает надежность и эффективность выполнения задач в реальном мире.
Модель RoboBrain 2.5 предоставляет надежную основу для генерации и выполнения сложных задач манипулирования. Она позволяет создавать последовательности действий, требующие координации нескольких степеней свободы робота и учета физических свойств объектов. Эта основа включает в себя как планирование высокоуровневых целей, так и детализированное управление траекториями движения, обеспечивая возможность выполнения задач, включающих захват, перемещение, сборку и взаимодействие с различными предметами в реальном времени. Система поддерживает как предопределенные, так и динамически генерируемые последовательности действий, адаптируясь к изменяющимся условиям окружающей среды и непредсказуемым событиям.
Точное Пространственное Рассуждение и Манипулирование
Точное 3D-пространственное рассуждение (Precise3DSpatialReasoning) расширяет возможности пространственного понимания, добавляя предсказание координат с учетом глубины. Это позволяет RoboBrain 2.5 генерировать полные траектории манипуляций, определяя последовательность действий робота в трехмерном пространстве. В отличие от систем, ограничивающихся двумерным анализом, данная технология обеспечивает точное определение местоположения объектов и планирование движений с учетом их взаимного расположения по всем трем осям, что критически важно для сложных задач манипулирования в реальном мире.
Процесс SpatialTracing заключается в генерации упорядоченных последовательностей ключевых точек, которые кодируют пространственное планирование действий робота и обеспечивают их точное выполнение. Эти последовательности представляют собой дискретизированное представление желаемой траектории, определяя последовательность положений, которые робот должен достичь для выполнения поставленной задачи. Каждая ключевая точка в последовательности содержит информацию о координатах в трехмерном пространстве и, возможно, об ориентации, что позволяет роботу точно ориентироваться и перемещаться в окружающей среде. Точность и упорядоченность этих ключевых точек критически важны для обеспечения плавного и безошибочного выполнения манипуляций.
Генерация траектории использует полученные последовательности ключевых точек для создания плавных и безопасных путей движения робота. Данный процесс включает в себя алгоритмы, оптимизирующие как эффективность перемещения, так и предотвращение столкновений с объектами в окружающей среде. Оптимизация траектории включает в себя вычисление минимально необходимого времени и энергии для достижения цели, а также учет кинематических ограничений робота-манипулятора. Реализованные алгоритмы обеспечивают не только достижение конечной точки, но и поддержание стабильности и точности на протяжении всего движения, что критически важно для выполнения сложных манипуляций.
Система продемонстрировала выдающиеся результаты в задачах пространственного анализа и планирования траекторий. Значение метрики 3D Spatial Measurement (MSMU) составило 64.17, что является передовым показателем в данной области. Одновременно с этим, средняя ошибка траектории (Trajectory Error, VABench-V) зафиксирована на уровне 0.1189, подтверждая высокую точность и надежность системы при выполнении манипуляций в трехмерном пространстве. Эти показатели свидетельствуют о значительном улучшении по сравнению с существующими аналогами.
Функционирование системы точного пространственного рассуждения и манипулирования напрямую зависит от надежной метрической осведомленности. Это означает способность системы корректно интерпретировать размеры объектов и пространственные взаимосвязи в окружающей среде. Отсутствие точной оценки метрик приводит к неверному планированию траекторий и, как следствие, к ошибкам при выполнении манипуляций. Надежная метрическая осведомленность является базовым требованием для достижения высокой точности, подтвержденной показателями MSMU (3D Spatial Measurement) в 64.17 и низкой ошибкой траектории VABench-V (0.1189), что обеспечивает надежность и безопасность действий робота.

Валидация и Реальное Внедрение
RoboTwin2.0 представляет собой важнейшую платформу для проверки и валидации роботизированных систем и алгоритмов, значительно снижая риски и затраты, связанные с проведением экспериментов в реальных условиях. Данная виртуальная среда позволяет всесторонне протестировать сложные сценарии и алгоритмы управления, прежде чем они будут развернуты на физических роботах. Это не только экономит ресурсы, но и повышает безопасность, поскольку потенциальные ошибки и уязвимости выявляются и устраняются на этапе моделирования. Благодаря возможности многократного повторения экспериментов и тщательного анализа результатов, RoboTwin2.0 обеспечивает надежность и эффективность роботизированных решений перед их внедрением в практическую деятельность, что особенно важно для работы в динамичных и непредсказуемых средах.
Интеграция RoboTwin2.0 с RoboBrain 2.5 представляет собой мощный инструмент для ускоренного создания и улучшения стратегий манипулирования роботами. Благодаря этой комбинации, исследователи получают возможность быстро разрабатывать, тестировать и совершенствовать алгоритмы управления в виртуальной среде RoboTwin2.0, а затем мгновенно развертывать их на реальном роботе через RoboBrain 2.5. Этот итеративный процесс позволяет значительно сократить время, необходимое для перехода от концепции к функционирующей системе, а также повысить надежность и эффективность алгоритмов за счет обширного тестирования в различных смоделированных сценариях. В результате, разработка сложных манипуляционных задач становится более доступной и эффективной, открывая новые возможности для автоматизации и робототехники.
Платформа AgiLex, представляющая собой робота с двумя манипуляторами, служит ключевой площадкой для внедрения и тестирования алгоритмов, предварительно отлаженных в виртуальной среде RoboTwin2.0. Благодаря своей конструкции, AgiLex позволяет эффективно моделировать сценарии совместной работы человека и робота, что особенно важно для автоматизации задач в производственных и логистических процессах. В ходе реальных испытаний, платформа демонстрирует высокую надежность и адаптивность в сложных условиях, обеспечивая плавную интеграцию робототехники в существующие рабочие процессы и открывая возможности для повышения производительности и безопасности труда.
Практические испытания, проведенные с использованием обучения с подкреплением, продемонстрировали впечатляющий уровень успешности, превышающий 95%, даже при наличии внешних помех и непредсказуемых факторов. Это свидетельствует о высокой надежности и адаптивности разработанных алгоритмов в реальных условиях эксплуатации. Особого внимания заслуживает согласованность оценки прогресса как в прямом, так и в обратном направлении, подтвержденная показателем VOC в 80.67. Данный результат указывает на способность системы точно оценивать текущее состояние и прогнозировать дальнейшее развитие ситуации, что критически важно для обеспечения стабильной и эффективной работы робота в динамичной среде.
В основе адаптивного управления, демонстрируемого системой RoboTwin2.0, лежит механизм HopPrediction, интегрированный в DenseTemporalValueEstimation. Этот подход позволяет роботу не просто реагировать на изменения в окружающей среде, но и предвидеть их, оценивая потенциальные траектории развития ситуации на несколько шагов вперед. Благодаря этому, система способна оптимизировать свои действия, выбирая наиболее эффективную стратегию для достижения цели, даже в условиях динамичных и непредсказуемых сценариев. Использование HopPrediction значительно повышает устойчивость робота к внешним возмущениям и позволяет поддерживать высокую производительность, поскольку он может заранее корректировать свои действия, минимизируя влияние неблагоприятных факторов. Фактически, это создает своего рода «цифровое предвидение», позволяющее роботу действовать проактивно, а не реактивно, обеспечивая надежную и эффективную работу в реальных условиях.

Работа демонстрирует стремление к упрощению взаимодействия робота с миром, что находит отклик в словах Г.Х. Харди: «Чистая математика — это не просто игра, но и необходимость». RoboBrain 2.5, представляя собой основу для развития пространственного и временного мышления, пытается найти элегантное решение сложных задач восприятия. Модель, фокусируясь на оценке ценности информации и построении связей между прошлым, настоящим и будущим, стремится к ясности в интерпретации окружающего мира. Это соответствует принципу, что каждая сложность требует алиби — модель должна демонстрировать эффективность и обоснованность своих решений.
Куда же дальше?
Представленная работа, несомненно, продвигает границы воплощенного искусственного интеллекта. Однако, за кажущимся прогрессом в пространственном и временном рассуждении скрывается извечная проблема — избыточность. Модель, стремясь охватить все возможные сценарии взаимодействия с миром, рискует утонуть в деталях, теряя способность к гибкому и эффективному решению задач. Упрощение, а не добавление новых слоев сложности, должно стать следующим шагом.
Особое внимание следует уделить не столько увеличению объема данных для обучения, сколько разработке принципиально новых методов извлечения существенной информации. Необходимо найти способы, позволяющие модели отличать важное от несущественного, игнорировать шум и сосредотачиваться на ключевых аспектах окружающей среды. Иначе, даже самая мощная модель останется лишь сложным эмулятором, неспособным к истинному пониманию.
Попытки создать универсального робота, способного ко всему, обречены на неудачу. Более перспективным представляется путь специализации, создание узкопрофильных моделей, оптимизированных для решения конкретных задач. Простота — не ограничение, а доказательство глубокого понимания сути проблемы. И в этом заключается истинная ценность научного поиска.
Оригинал статьи: https://arxiv.org/pdf/2601.14352.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Моделирование биомолекул: новый импульс от нейросетей
- Мгновенная расшифровка: Voxtral Realtime на службе у скорости
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
2026-01-22 07:35