Автор: Денис Аветисян
Новое исследование предлагает всесторонний анализ различных методов квантования для больших языковых моделей, используемых в llama.cpp.
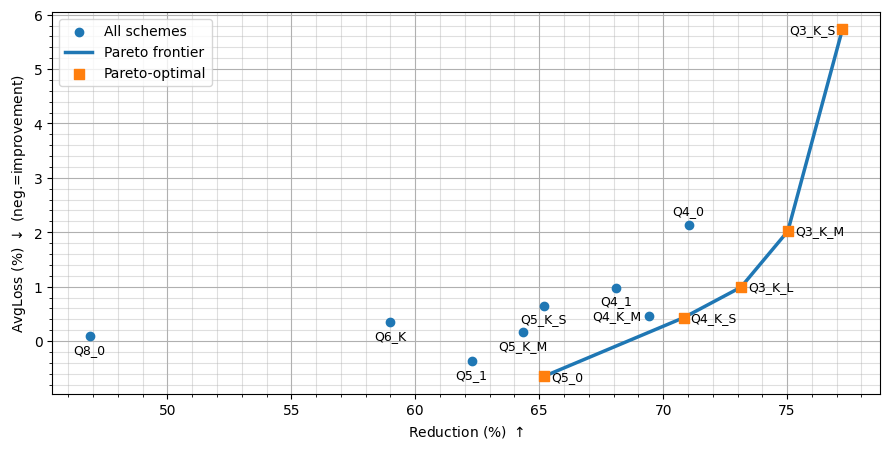
Оценка влияния различных форматов квантования GGUF на производительность и эффективность инференса модели Llama-3.1-8B-Instruct.
Квантование, хотя и является эффективным способом снижения требований к ресурсам больших языковых моделей, часто оценивается непоследовально, затрудняя выбор оптимальной схемы. В работе ‘Which Quantization Should I Use? A Unified Evaluation of llama.cpp Quantization on Llama-3.1-8B-Instruct’ представлено всестороннее эмпирическое исследование различных форматов квантования в экосистеме llama.cpp, показавшее, что квантование средней точности (около 5 бит) обеспечивает наилучший баланс между сжатием модели, производительностью в задачах и эффективностью инференса. Какие стратегии квантования окажутся наиболее перспективными для дальнейшей оптимизации развертывания больших языковых моделей на потребительском оборудовании?
Эффективность и узкие места больших языковых моделей
Современные большие языковые модели, такие как Llama-3.1-8B-Instruct, демонстрируют впечатляющие возможности в обработке и генерации текста, однако их эффективность напрямую связана с огромными вычислительными ресурсами. Для полноценной работы этих моделей требуется значительный объем памяти и высокая производительность процессоров, что обусловлено количеством параметров, определяющих сложность и гибкость системы. Увеличение числа параметров позволяет моделям улавливать более тонкие нюансы языка и генерировать более связные и релевантные тексты, но одновременно увеличивает требования к инфраструктуре. Это создает существенные ограничения для широкого внедрения подобных моделей, особенно в условиях ограниченных ресурсов или необходимости работы на мобильных устройствах и периферийных системах, где доступность вычислительной мощности является критическим фактором.
Значительная вычислительная нагрузка, требуемая современными большими языковыми моделями, представляет собой серьезное препятствие для их широкого распространения. Развертывание этих моделей на периферийных устройствах, таких как смартфоны или встроенные системы, становится затруднительным из-за ограниченных ресурсов памяти и вычислительной мощности. Более того, высокая стоимость обучения и эксплуатации ограничивает доступ к передовым языковым технологиям для многих исследователей и разработчиков, особенно в академической среде и стартапах с ограниченным бюджетом. Эта ситуация создает своего рода цифровой разрыв, замедляя прогресс в области искусственного интеллекта и лишая общество потенциальных выгод от инноваций в сфере обработки естественного языка.
Квантование представляет собой перспективный подход к снижению габаритов и ускорению работы больших языковых моделей, однако эта оптимизация часто сопровождается неизбежной потерей точности. Суть метода заключается в уменьшении разрядности числовых представлений параметров модели — например, с 32-битных чисел с плавающей точкой до 8-битных целых чисел. Хотя это значительно сокращает объем памяти, необходимый для хранения модели, и увеличивает скорость вычислений, упрощение числовых представлений приводит к округлению и, следовательно, к некоторой деградации производительности. Разрабатываются различные стратегии квантования, направленные на минимизацию этих потерь, включая обучение с учетом квантования и использование смешанной точности, но поиск оптимального баланса между размером модели, скоростью и точностью остается актуальной задачей в области машинного обучения.
`llama.cpp` и техники квантования: решение проблемы
llama.cpp — это движок, разработанный на языках C и C++ для эффективного выполнения логического вывода больших языковых моделей (LLM), в особенности на центральных процессорах (CPU) и аппаратных платформах с ограниченными ресурсами. Архитектура движка оптимизирована для минимизации использования памяти и обеспечения высокой скорости обработки, что позволяет запускать LLM на устройствах с ограниченной оперативной памятью, таких как ноутбуки, одноплатные компьютеры и даже мобильные устройства. В отличие от решений, ориентированных исключительно на графические процессоры (GPU), llama.cpp предоставляет возможность локального запуска и использования LLM без необходимости в специализированном аппаратном обеспечении.
Квантизация в llama.cpp заключается в снижении точности представления весов модели с использованием меньшего количества бит. Традиционно, веса моделей больших языковых моделей (LLM) хранятся в формате с плавающей точкой (например, FP16 или FP32). Переход к целочисленным форматам (INT8, INT4 и т.д.) позволяет значительно уменьшить объем занимаемой памяти, что критично для развертывания моделей на устройствах с ограниченными ресурсами. Уменьшение точности также способствует ускорению вычислений, поскольку операции с целочисленными данными выполняются быстрее, чем с числами с плавающей точкой. Однако, следует учитывать, что чрезмерное снижение точности может привести к незначительной потере качества генерируемого текста.
Для снижения требований к памяти и ускорения вычислений в `llama.cpp` применяются различные схемы квантования. Стандартные методы, такие как Q4_0, Q5_0 и Q8_0, используют целочисленное представление весов модели с разной разрядностью (4, 5 и 8 бит соответственно). Более продвинутый метод, K-Quant, обеспечивает дополнительную оптимизацию, группируя веса и применяя квантование на уровне групп, что позволяет достичь лучшего компромисса между точностью и скоростью работы модели. Выбор конкретной схемы зависит от доступных ресурсов и требуемой производительности.
Сравнение производительности квантованных моделей
Для оценки эффективности различных схем квантизации (Q3_K_S, Q4_K_M, Q5_K_M, Q6_K и другие) был проведен сравнительный анализ производительности на разнообразном наборе эталонных тестов, включающем MMLU, GSM8K, HellaSwag, IFEval и TruthfulQA. Данный набор бенчмарков позволяет всесторонне оценить влияние квантизации на различные типы задач, охватывающие понимание естественного языка, решение математических задач, логические рассуждения и проверку правдивости ответов. Использование широкого спектра тестов необходимо для выявления потенциальных узких мест и обеспечения надежности квантованных моделей в различных сценариях применения.
Для оценки базового качества языкового моделирования, помимо оценки на downstream задачах, использовался датасет WikiText-2. В качестве метрики использовалась перплексия (perplexity), которая количественно оценивает неопределенность модели при предсказании следующего токена в тексте. Низкая перплексия указывает на более точное моделирование языка. Использование WikiText-2 позволило установить базовый уровень производительности модели перед оценкой ее эффективности на более сложных задачах, таких как ответы на вопросы и логическое мышление, а также сравнить влияние различных схем квантизации на фундаментальные способности модели к языковому моделированию.
Результаты исследований показывают, что схемы K-Quant последовательно превосходят стандартную целочисленную квантизацию при сопоставимой разрядности, минимизируя потери точности и максимизируя степень сжатия. Особо выделяется, что 5-битные схемы квантизации обеспечивают оптимальный компромисс, поддерживая или незначительно улучшая производительность в задачах, требующих обработки естественного языка. В частности, схема Q5_0 достигла средней производительности в downstream задачах на уровне 69.92%, что представляет собой небольшое улучшение по сравнению с базовой линией FP16.
В ходе тестирования было установлено, что схема квантизации Q5_0 демонстрирует среднюю производительность в задачах, составляя 69.92%, что незначительно превосходит показатели базовой FP16 модели. Схема Q3_K_S обеспечила максимальное сжатие модели — снижение размера на 77.23% — однако сопровождалось существенной потерей точности. Применение схем с пониженной разрядностью также привело к значительному увеличению скорости генерации токенов, что свидетельствует об улучшении эффективности инференса.
Влияние и перспективы квантования больших языковых моделей
Квантование, как метод значительного уменьшения размера языковых моделей, открывает новые перспективы для их применения на устройствах с ограниченными ресурсами. Это позволяет развертывать большие языковые модели не только в облачных сервисах, но и непосредственно на смартфонах, планшетах и других периферийных устройствах, создавая возможности для развития технологий граничного искусственного интеллекта. Возможность локальной обработки данных, без необходимости постоянного подключения к сети, обеспечивает повышенную конфиденциальность и надежность, особенно важную для приложений, требующих мгновенного отклика и работы в условиях отсутствия связи, например, в автономных системах или при обработке конфиденциальной информации.
Ускорение процесса вывода модели, достигнутое благодаря оптимизации, напрямую влияет на снижение задержки ответа, что особенно важно в интерактивных приложениях. Более быстрая обработка запросов позволяет пользователям получать ответы практически мгновенно, улучшая общее впечатление от взаимодействия с системой. Это имеет решающее значение для таких сценариев, как голосовые помощники, чат-боты и приложения, требующие обработки естественного языка в реальном времени, где даже небольшая задержка может существенно снизить удобство использования и эффективность. Снижение времени отклика делает взаимодействие более плавным и естественным, создавая ощущение отзывчивости и повышая удовлетворенность пользователей.
Исследования показали, что схема квантования Q5_0 позволила добиться значительного уменьшения размера моделей — на 65.19% — при этом сохранив производительность на уровне базовой модели. Более того, в некоторых тестах наблюдалось даже незначительное улучшение результатов. Данный подход демонстрирует перспективность агрессивных стратегий квантования для создания компактных и эффективных языковых моделей, которые могут быть развернуты на устройствах с ограниченными ресурсами без существенной потери качества. Это открывает новые возможности для применения искусственного интеллекта в различных областях, где важна скорость и экономия памяти.
Перспективные исследования в области квантования больших языковых моделей направлены на разработку еще более радикальных стратегий уменьшения размера, при этом особое внимание уделяется минимизации потенциальной потери точности. Ученые стремятся найти баланс между агрессивным сжатием и сохранением вычислительной эффективности, что позволит развертывать модели на устройствах с ограниченными ресурсами без существенного ухудшения качества работы. Разработка новых техник, направленных на компенсацию неизбежных потерь при экстремальном квантовании, является ключевой задачей, поскольку это откроет возможности для более широкого применения ИИ на периферийных устройствах и в автономных системах. Оптимизация алгоритмов квантования и исследование инновационных подходов к представлению весов и активаций моделей представляются особенно перспективными направлениями для будущих исследований.
Исследование показывает, что погоня за максимальным сжатием модели неизбежно сталкивается с потерей производительности на конкретных задачах. Этот компромисс, где каждая битовая оптимизация требует пересмотра точности, закономерно. Как заметил Г.Х. Харди: «Математика — это наука о том, что можно доказать, а не о том, что можно вычислить». В данном контексте, «вычислить» — это эффективно запустить модель, а «доказать» — сохранить приемлемый уровень точности. Авторы показали, что квантизация в районе 5-ти бит представляет собой золотую середину, что подтверждает: даже самая элегантная абстракция (в данном случае, модель) рано или поздно сталкивается с суровой реальностью продакшена, где важны не только теоретические возможности, но и практическая эффективность.
Куда Поведёт Нас Это Дальше?
Исследование, демонстрирующее, что компромиссные варианты квантизации — примерно 5 бит — оказываются наиболее практичными, не вызывает особого удивления. В конце концов, всегда находился способ заставить «революционную» технологию работать с ограничениями железа. Заманчивые обещания «бесплатного» сжатия модели неизбежно сталкиваются с реальностью, где каждая битовая экономия — это потенциальная потеря точности, которую придётся как-то маскировать. И, конечно, всегда найдутся энтузиасты, готовые оптимизировать под конкретный чип, пока остальным приходится довольствоваться усреднёнными результатами.
Однако, настоящий вопрос заключается не в поиске оптимальной точки сжатия, а в том, как мы собираемся справляться с экспоненциальным ростом этих самых моделей. Квантизация — это, скорее, временное решение, латка на дыре. В конечном итоге, потребуется переосмысление архитектур, более эффективные алгоритмы обучения, и, возможно, отказ от идеи, что «больше — значит лучше». Вспомните, как «всё работало, пока не пришёл Agile» — каждая новая библиотека, каждая «оптимизация» приносит с собой новую порцию сложностей.
Так что, да, исследование полезно. Но не стоит обольщаться. Всё новое — это просто старое с худшей документацией. И, скорее всего, через пару лет мы будем обсуждать, какая новая схема квантизации «по-настоящему» решает проблему, пока железо снова не отстанет. DevOps, как известно, это когда инженеры смирились.
Оригинал статьи: https://arxiv.org/pdf/2601.14277.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-22 12:58