Автор: Денис Аветисян
Исследователи представили Typhoon OCR — открытую модель, способную эффективно извлекать информацию из документов на тайском и английском языках.
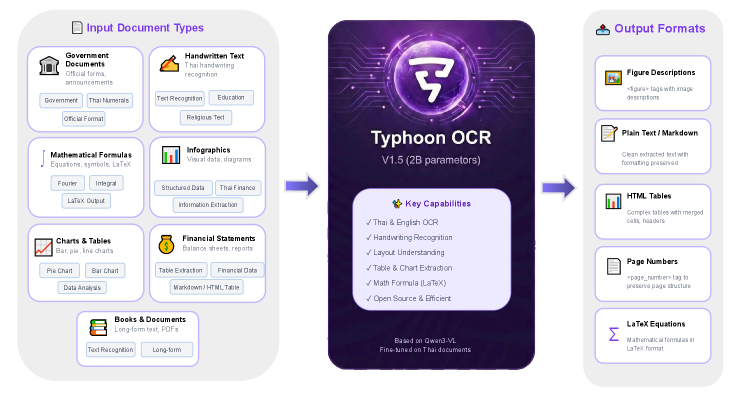
Открытая vision-language модель для комплексной обработки документов на тайском языке, разработанная для преодоления проблемы нехватки данных.
Несмотря на значительный прогресс в области извлечения информации из документов, существующие мультимодальные модели зачастую демонстрируют ограниченную эффективность при работе с языками с нелатинской письменностью и сложной структурой. В данной работе представлена модель ‘Typhoon OCR: Open Vision-Language Model For Thai Document Extraction’ — открытая нейросетевая система, предназначенная для комплексного анализа тайских и английских документов. Модель обеспечивает высокую точность распознавания текста, реконструкцию структуры и поддержание консистентности на уровне всего документа, используя специально разработанный и тщательно отобранный обучающий корпус. Сможет ли Typhoon OCR стать основой для создания доступных и эффективных систем обработки документов на тайском языке, сопоставимых по производительности с проприетарными решениями?
Преодолевая Затруднения в Распознавании Документов
Традиционные методы оптического распознавания символов (OCR) сталкиваются с серьезными трудностями при обработке документов реального мира, особенно когда речь идет о языках со сложной письменностью, таких как тайский. В отличие от машинописного текста с четкой структурой, реальные документы часто характеризуются сложными макетами, включающими таблицы, колонки, изображения и различный размер и стиль шрифтов. Это приводит к ошибкам в распознавании символов и затрудняет точное извлечение информации. Специфика тайского языка, с его сложными глифами и отсутствием явных разделителей слов, усугубляет проблему, поскольку стандартные алгоритмы OCR, разработанные для латиницы, не способны эффективно анализировать и интерпретировать эту сложную структуру. В результате, точность распознавания тайского текста существенно снижается, что ограничивает возможности автоматизации обработки документов и требует значительных ручных усилий для исправления ошибок.
Существующие модели, объединяющие компьютерное зрение и обработку естественного языка, зачастую демонстрируют недостаточную устойчивость при извлечении информации из документов различных типов. Это связано с тем, что реальные документы редко соответствуют идеализированным условиям, в которых обучаются модели — в них часто встречаются нечеткие изображения, сложные макеты, разнообразие шрифтов и языков. В результате, ошибки при распознавании и интерпретации данных могут существенно повлиять на работу последующих приложений, таких как автоматизированная обработка счетов, извлечение данных из юридических документов или цифровая архивация. Неспособность надежно обрабатывать разнообразие документов ограничивает возможности цифровой трансформации и требует разработки более устойчивых и адаптивных моделей.
Для успешной цифровой трансформации предприятий и организаций остро требуется решение, способное надежно обрабатывать как структурированные, так и неструктурированные данные, содержащиеся в документах. Традиционные подходы часто оказываются неэффективными при работе с разнородными форматами и сложными макетами, что приводит к ошибкам при извлечении информации и затрудняет автоматизацию бизнес-процессов. Способность системы к адаптации к различным типам документов — от табличных данных и счетов-фактур до сканированных рукописных текстов и неформальных отчетов — является ключевым фактором для повышения эффективности работы и снижения затрат. Разработка подобных технологий позволит организациям в полной мере использовать потенциал своих данных, автоматизировать рутинные задачи и принимать более обоснованные решения, что в конечном итоге способствует их конкурентоспособности и росту.
Typhoon OCR: Новый Взгляд на Визуально-Языковое Анализ
Typhoon OCR использует возможности семейства моделей Qwen2.5-VL, прошедших специализированную тонкую настройку для комплексного анализа документов. В отличие от традиционных подходов, требующих отдельных этапов обработки изображения и распознавания текста, Qwen2.5-VL позволяет выполнять все операции — от понимания визуальной структуры документа до извлечения текстовой информации — в рамках единой нейронной сети. Это обеспечивает более высокую точность и эффективность, особенно в задачах, требующих учета контекста и сложных макетов. Тонкая настройка модели была произведена на большом объеме данных, содержащих документы различных типов и форматов, что позволило значительно улучшить её способность к обобщению и адаптации к новым задачам.
Typhoon OCR использует фреймворк olmOCR в качестве базовой платформы, обеспечивающей надёжную и эффективную основу для извлечения текста и реконструкции макета документов. Фреймворк olmOCR предоставляет инструменты для предобработки изображений, обнаружения текста, а также для восстановления логической структуры документа, что позволяет Typhoon OCR точно определять и восстанавливать расположение текстовых блоков, таблиц и других элементов. Это обеспечивает высокую производительность и точность при обработке документов различной сложности и качества, включая отсканированные изображения и цифровые документы.
Модель Typhoon OCR использует архитектуру Vision-Language Transformer, что позволяет ей одновременно обрабатывать визуальную и текстовую информацию, содержащуюся в документах. Данная архитектура объединяет возможности компьютерного зрения и обработки естественного языка, позволяя модели понимать не только сами символы, но и их контекст, а также структуру документа. В процессе обработки изображения документа, Vision-Language Transformer преобразует визуальные признаки в векторные представления, которые затем объединяются с текстовыми эмбеддингами. Это обеспечивает более точное распознавание текста, особенно в сложных документах с различными шрифтами, макетами и шумами.
Повышение Надежности с Помощью Синтетических Данных и Гибких Режимов
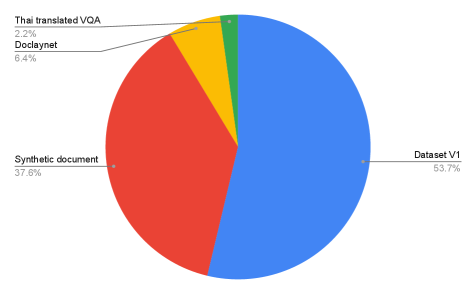
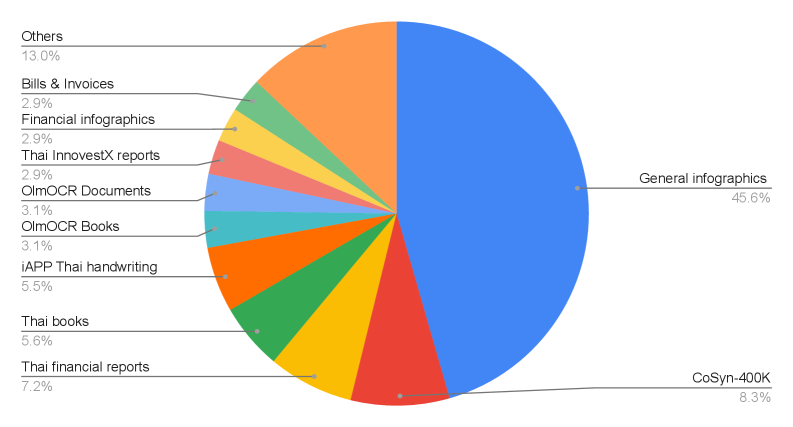
Обучение Typhoon OCR осуществляется с использованием комбинированного набора данных, включающего реальные документы и CoSyn-400K. CoSyn-400K представляет собой синтетический набор данных, содержащий 400 тысяч изображений документов с контролируемыми вариациями макета. Использование синтетических данных позволяет целенаправленно расширить обучающую выборку и повысить устойчивость модели к различным искажениям и изменениям в структуре документов, что особенно важно для обработки документов сложного формата и низкого качества.
Модель Typhoon OCR поддерживает два режима работы: «Структурный» и «По умолчанию», что позволяет адаптироваться к документам различной сложности структуры. В «Структурном» режиме модель предполагает наличие четко определенной структуры документа и использует эту информацию для повышения точности распознавания. «Режим по умолчанию» предназначен для обработки документов со сложной или нестандартной разметкой, где предварительное знание структуры отсутствует или ограничено. Переключение между режимами позволяет оптимизировать производительность в зависимости от характеристик входного документа, обеспечивая более надежное распознавание текста в различных сценариях.
Обучение Typhoon OCR проводилось на корпусе из 77 029 образцов документов, включающем как реальные документы, так и синтетические данные. Использование синтетических данных в сочетании с возможностью переключения между режимами обработки позволило добиться повышения производительности OCR для различных типов документов, в том числе тайских книг. Гибкость режимов позволяет адаптировать процесс распознавания к документам с различной степенью сложности структуры и компоновки, что положительно сказывается на точности результатов.
Количественная Оценка и Показатели Эффективности
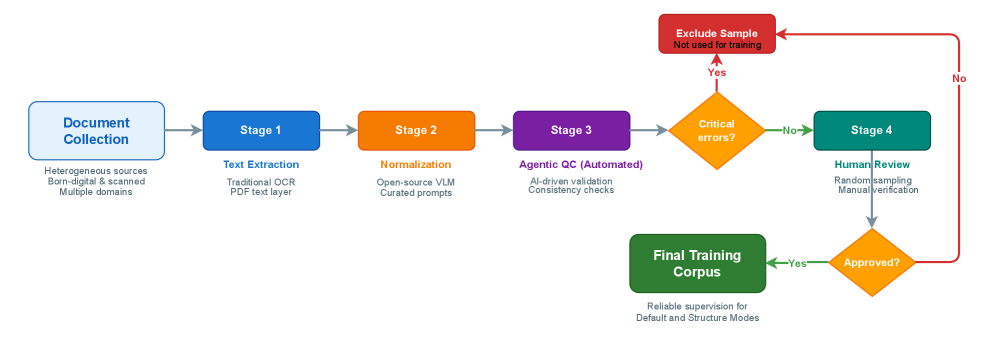
Для обеспечения точной и надежной оценки работы системы оптического распознавания символов Typhoon OCR использовался набор стандартных метрик, широко применяемых в области обработки естественного языка. В частности, метрика BLEU (Bilingual Evaluation Understudy) измеряет степень совпадения с эталонными текстами, ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation) оценивает перекрытие последовательностей слов, а расстояние Левенштейна определяет минимальное количество изменений, необходимых для преобразования одной строки в другую. Комбинация этих метрик позволяет всесторонне оценить качество распознавания и исправить ошибки, обеспечивая объективную оценку эффективности Typhoon OCR по сравнению с другими системами.
Модель Typhoon OCR демонстрирует впечатляющую производительность при обработке как английского, так и тайского языков, что свидетельствует о её высокой универсальности и способности к адаптации к различным лингвистическим структурам. Результаты, представленные в Таблице 2, наглядно подтверждают эффективность алгоритмов распознавания символов в обеих языковых системах. Данная многоязычность позволяет использовать модель в широком спектре приложений, от автоматизированной обработки документации до извлечения информации из многоязычных источников, значительно расширяя область её применимости и делая её ценным инструментом для задач, связанных с анализом текста.
Результаты исследований подтверждают, что Typhoon OCR демонстрирует конкурентоспособные показатели на эталонных наборах данных тайского языка, что представляет собой значительный прогресс в области понимания документов. Достигнутая точность и эффективность обработки позволяют существенно улучшить автоматизацию задач, связанных с извлечением информации из отсканированных документов и изображений на тайском языке. Данное достижение открывает новые возможности для цифровизации архивов, автоматизации делопроизводства и повышения доступности информации на тайском языке, что особенно важно в контексте растущего объема цифрового контента и необходимости его эффективной обработки.
Разработка модели Typhoon OCR демонстрирует закономерность, присущую любой сложной системе. Подобно тому, как архитектура со временем устаревает, и существующие решения нуждаются в адаптации, задача распознавания документов на тайском языке требовала нового подхода. Недостаток размеченных данных, описанный в статье, — это не препятствие, а скорее естественная фаза в эволюции системы. Джон Маккарти однажды сказал: «Все системы стареют — вопрос лишь в том, делают ли они достойно». Typhoon OCR, используя методы аугментации данных и тщательно подобранный корпус, стремится к элегантности и эффективности, обеспечивая достойную эволюцию в области распознавания документов. Модель демонстрирует, что улучшение существующих подходов не всегда достаточно, и иногда требуется принципиально новый взгляд на задачу.
Куда Ведет Этот Шторм?
Представленная работа, как и любой инструмент, лишь временно отсрочила неизбежное — старение системы распознавания документов. Появление Typhoon OCR, несомненно, расширяет возможности обработки тайского языка, но следует помнить: упрощение задачи распознавания посредством создания специализированных моделей неизбежно влечет за собой увеличение технического долга. Эффективность модели напрямую зависит от качества и объема курируемого корпуса данных, а значит, будущее развитие будет связано не только с архитектурой нейронных сетей, но и с трудоемким процессом постоянного обновления и аугментации данных.
Наиболее сложной задачей остается не столько само распознавание символов, сколько понимание контекста и структуры документа. Модель демонстрирует успехи в извлечении информации, но истинное понимание требует преодоления разрыва между синтаксисом и семантикой. Будущие исследования, вероятно, будут направлены на интеграцию моделей обработки естественного языка с более глубоким пониманием визуальной информации, возможно, с использованием механизмов внимания, способных выделять ключевые элементы документа.
В конечном итоге, любой прогресс в области оптического распознавания символов — это лишь временное облегчение. Со временем появятся новые шрифты, новые форматы документов, новые способы сокрытия информации. Задача не в том, чтобы создать идеальную модель, а в том, чтобы создать систему, способную адаптироваться к постоянно меняющейся среде, не теряя при этом своей способности к извлечению знаний.
Оригинал статьи: https://arxiv.org/pdf/2601.14722.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
2026-01-22 14:30