Автор: Денис Аветисян
Новый подход позволяет преобразовывать сложные рассуждения искусственного интеллекта в визуальные образы, повышая эффективность и интерпретируемость его работы.
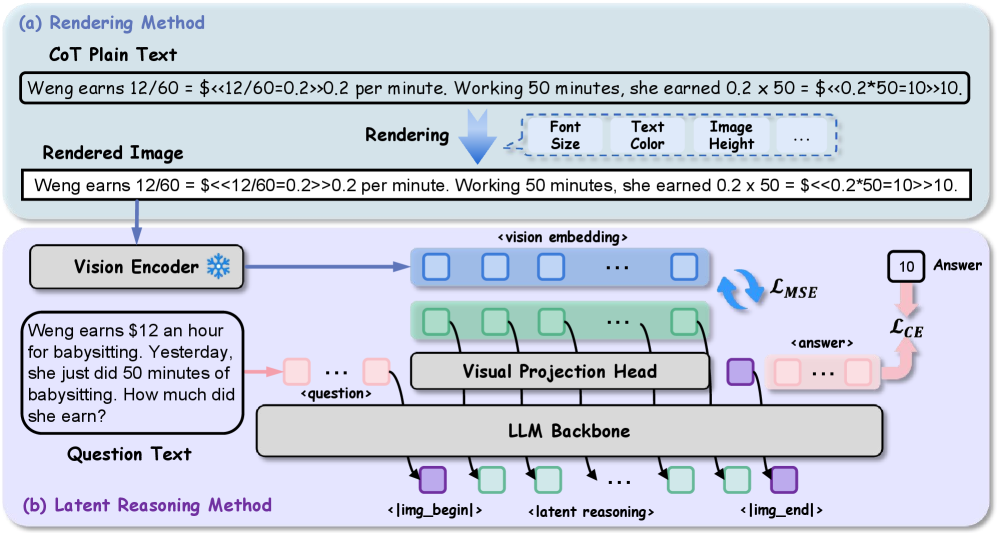
Предложена технология Render-of-Thought, сжимающая текстовые цепочки рассуждений в визуальные представления для улучшения производительности и анализа.
Несмотря на впечатляющие успехи методов цепочки рассуждений (Chain-of-Thought) в повышении эффективности больших языковых моделей, их многословность создает значительные вычислительные издержки и затрудняет анализ скрытых процессов. В данной работе, посвященной разработке фреймворка ‘Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning’, предлагается инновационный подход к визуализации этапов рассуждений, преобразуя текстовые шаги в изображения для повышения эффективности и прозрачности. Данный метод позволяет достичь сжатия токенов в 3-4 раза и ускорить процесс логического вывода, сохраняя при этом сопоставимую производительность с другими подходами. Способно ли такое представление латентных рассуждений открыть новые горизонты в понимании и оптимизации работы сложных языковых моделей?
За пределами текста: Ограничения традиционного рассуждения
Несмотря на впечатляющие возможности, современные языковые модели часто демонстрируют трудности при решении сложных задач, требующих последовательного, многоступенчатого рассуждения. Ограничения масштабируемости глубины рассуждений становятся особенно заметными при увеличении числа необходимых шагов для достижения решения. В то время как модели способны генерировать связные тексты и отвечать на вопросы, их способность к последовательному анализу и логическому выводу в сложных сценариях остается несовершенной. Это связано с тем, что, по сути, модели оперируют вероятностями и паттернами, а не истинным пониманием причинно-следственных связей, что ограничивает их эффективность в задачах, требующих глубокого анализа и стратегического планирования.
Традиционный подход «Цепочка мыслей» (Chain-of-Thought), несмотря на свою эффективность в решении сложных задач, требует создания развернутых текстовых последовательностей, что приводит к значительным вычислительным затратам и проблемам с компрессией информации. Новый метод, получивший название «Отображение мыслей» (Render-of-Thought), направлен на преодоление этих ограничений. В ходе исследований было показано, что он позволяет добиться сжатия информации в 3-4 раза по сравнению с явным текстовым представлением логической цепочки рассуждений. Это достигается за счет более компактного кодирования информации, необходимой для принятия решений, что существенно снижает нагрузку на вычислительные ресурсы и повышает эффективность обработки данных.
Традиционные методы рассуждений, основанные на последовательном изложении текста, зачастую не способны отразить сложность и многогранность человеческого мышления. В отличие от линейной природы текстовых цепочек, человеческий разум склонен к параллельной обработке информации и ассоциативным связям, мгновенно устанавливая связи между различными понятиями и идеями. Эта особенность позволяет человеку решать сложные задачи, опираясь на широкий спектр знаний и опыта, в то время как языковые модели, ограниченные последовательной обработкой текста, испытывают трудности при решении задач, требующих глубокого понимания контекста и установления неявных связей. Именно поэтому, для создания более эффективных систем искусственного интеллекта, необходимо разрабатывать методы, способные моделировать параллельную и ассоциативную природу человеческого мышления, выходя за рамки традиционной линейной логики.
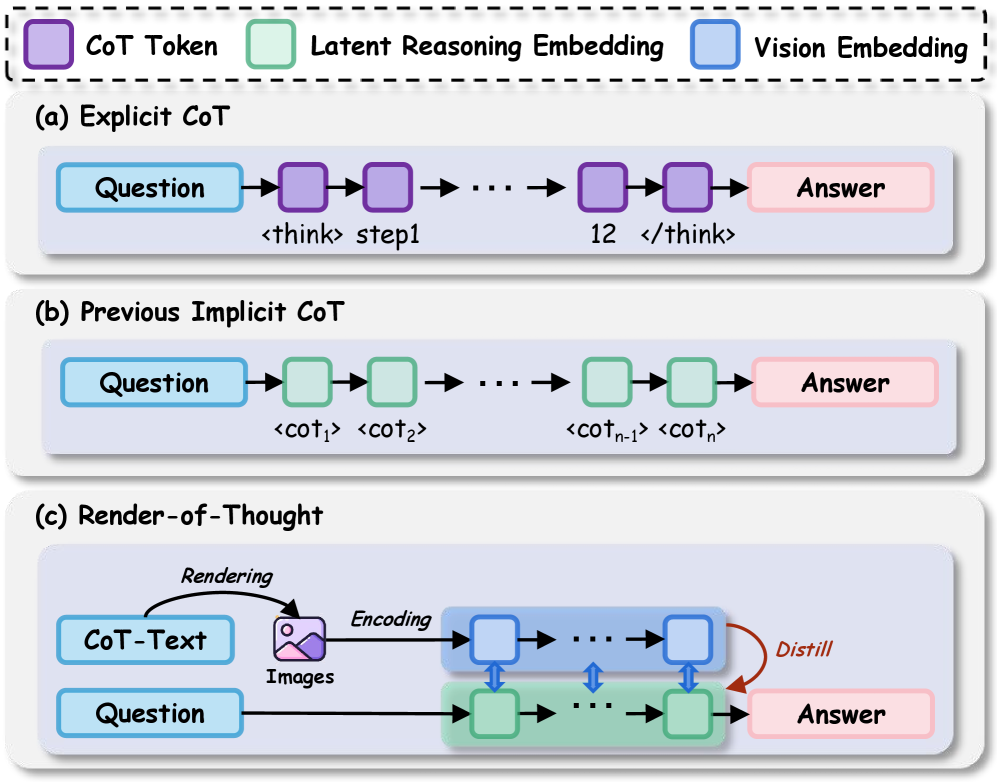
Визуализация процесса рассуждения: Отображение мыслей
Метод Render-of-Thought представляет собой фреймворк, преобразующий шаги текстового рассуждения в плотное визуальное встраивание. Этот процесс позволяет эффективно сжать информацию, сохраняя при этом семантическое значение исходных данных. Преобразование в визуальное пространство осуществляется путем сопоставления текстовых шагов с векторами в многомерном пространстве, что приводит к значительному уменьшению объема данных, необходимых для представления процесса рассуждения. Сохранение семантики обеспечивается за счет использования алгоритмов, которые минимизируют потерю информации при сжатии, гарантируя, что визуальное представление точно отражает логику и смысл исходного текстового рассуждения.
Модель Render-of-Thought использует предварительно обученные энкодеры изображений для представления процесса рассуждений в виде визуального пространства. Это позволяет закрепить логические шаги в уже изученном многомерном пространстве признаков, что способствует обобщению и устойчивости модели к новым задачам. Использование предварительно обученных энкодеров позволяет модели извлекать пользу из знаний, полученных при обработке больших объемов визуальных данных, и эффективно переносить их на задачу текстового рассуждения, повышая производительность и надежность решения.
Визуальный подход к скрытому логическому выводу позволяет преодолеть ограничения, связанные с обработкой длинных текстовых последовательностей, обеспечивая более эффективное и масштабируемое решение задач. Например, применительно к набору данных GSM-Hard, время логического вывода сократилось с 8.55 секунд до 1.84 секунд, что демонстрирует значительное повышение производительности за счет уменьшения вычислительной нагрузки и оптимизации процесса рассуждений.

Двухэтапное обучение: Согласование языка и зрения
В рамках обучения модель использует двухэтапную стратегию, первым шагом которой является визуальная адаптация. Этот процесс заключается в сопоставлении скрытых состояний языковой модели (LLM) с визуальным пространством встраиваний. Для реализации этого сопоставления используется функция потерь среднеквадратичной ошибки (Mean Squared Error, MSE). Суть заключается в минимизации разницы между векторами скрытых состояний LLM и соответствующими векторами визуальных встраиваний, что позволяет модели установить связь между лингвистической и визуальной информацией на начальном этапе обучения.
Второй этап обучения использует авторегрессионное логическое заключение для генерации непрерывных латентных токенов, представляющих шаги рассуждений. Для обеспечения эффективности и снижения вычислительных затрат применяется LoRA (Low-Rank Adaptation) — метод параметрически эффективной тонкой настройки. LoRA позволяет обучать лишь небольшое количество дополнительных параметров, сохраняя при этом большую часть весов предобученной модели неизменными, что существенно снижает требования к памяти и времени обучения при адаптации модели к конкретной задаче визуального рассуждения.
Процесс объединения языка и зрения осуществляется путем представления визуальной информации в виде сжатого латентного пространства. Модель преобразует визуальные данные в векторные представления, которые могут быть сопоставлены с языковыми представлениями, используемыми большой языковой моделью (LLM). Это позволяет модели выполнять рассуждения, оперируя с визуальными концепциями в рамках этого сжатого латентного пространства, что значительно снижает вычислительную сложность по сравнению с обработкой необработанных визуальных данных. Такой подход позволяет модели генерировать ответы, основанные на совместном анализе визуального и текстового входов, эффективно «понимая» визуальную информацию и интегрируя ее в процесс языкового рассуждения.

Результаты и стратегии декодирования
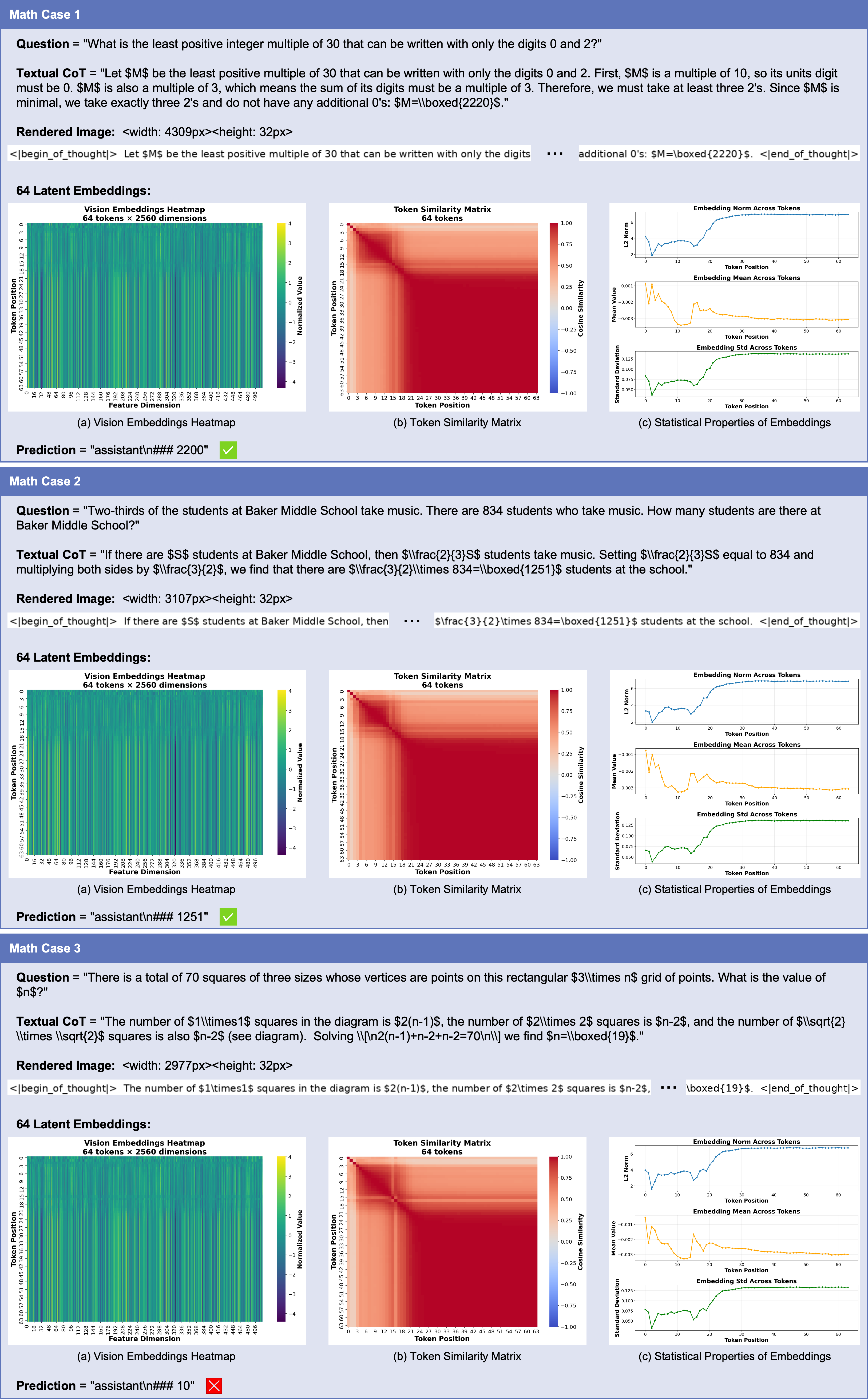
Эксперименты, проведенные на популярных наборах данных, таких как GSM8k и MATH, демонстрируют, что подход Render-of-Thought достигает сопоставимых или превосходящих результатов по сравнению с существующими методами. В частности, модель показала точность в 55.4% на GSM8k-Aug, используя всего 32 скрытых токена. Для сравнения, традиционный подход Explicit CoT, требующий 108.4 токена, достиг точности в 79.3%. Эти результаты указывают на эффективность Render-of-Thought в извлечении и структурировании логических рассуждений, даже при значительном сокращении количества используемых токенов, что делает его перспективным направлением для развития систем искусственного интеллекта, решающих сложные задачи.
Стратегии декодирования, такие как динамическое завершение и фиксированный бюджет токенов, играют решающую роль в управлении длиной и качеством генерируемых шагов рассуждений. Динамическое завершение позволяет модели прекратить генерацию, как только достигнуто достаточное обоснование для ответа, избегая избыточности и снижая вычислительные затраты. В то же время, фиксированный бюджет токенов ограничивает количество генерируемых шагов, предотвращая чрезмерно длинные и потенциально ошибочные цепочки рассуждений. Эффективное использование этих стратегий позволяет достичь оптимального баланса между точностью, краткостью и вычислительной эффективностью, что особенно важно при работе с комплексными задачами, требующими многоэтапного анализа и логических выводов.
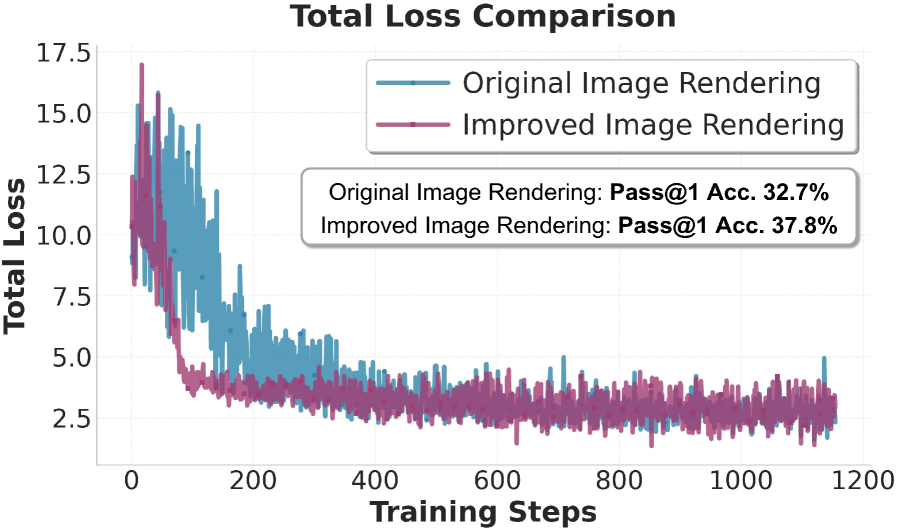
Исследования показали, что способ визуализации промежуточных результатов рассуждений, а именно однострочное отображение (Single-Line Rendering) в сравнении с представлением в виде фиксированного квадратного блока (Fixed-Size Square Rendering), оказывает существенное влияние на эффективность и вычислительные затраты модели. При тестировании на наборе данных MATH, модель Qwen3-VL-4B-Instruct достигла точности в 33.2% при использовании 64 латентных токенов, что демонстрирует зависимость результатов от выбранной стратегии визуализации. Этот результат подчеркивает важность оптимизации не только алгоритма рассуждений, но и способа представления его промежуточных шагов для достижения максимальной производительности и снижения вычислительной сложности.
К визуальному мышлению и за его пределы
Метод «Render-of-Thought» представляет собой существенный прорыв в области визуального мышления для больших языковых моделей. В отличие от традиционных подходов, где модели оперируют исключительно текстовой информацией, данный метод позволяет им генерировать и анализировать визуальные представления промежуточных этапов рассуждений. Это достигается путем преобразования внутренних мысленных процессов модели в изображения, которые затем используются для улучшения понимания и решения сложных задач. По сути, модель «визуализирует» свои мысли, что значительно повышает ее способность к логическому анализу и принятию обоснованных решений, особенно в задачах, требующих пространственного воображения и понимания визуальной информации. Данный подход открывает новые горизонты для развития искусственного интеллекта, приближая его к уровню человеческого когнитивного мышления.
В дальнейшем планируется усовершенствование методов визуализации, применяемых в рамках данной системы, с целью достижения большей реалистичности и детализации генерируемых изображений. Особое внимание будет уделено разработке более сложных алгоритмов рендеринга, способных учитывать физические свойства света и материалов. Помимо этого, ведется работа по расширению возможностей системы для обработки и интеграции информации из различных источников — текста, аудио и других модальностей. Это позволит перейти к многомодальному рассуждению, когда модель сможет не только анализировать визуальные данные, но и сопоставлять их с информацией, полученной из других каналов, что открывает новые перспективы для решения сложных задач и создания интеллектуальных систем нового поколения.
Предлагаемый подход представляет собой принципиальный сдвиг, открывающий перспективы для коренной трансформации различных областей знаний. В научной сфере он способен значительно ускорить процесс открытий, позволяя моделям визуализировать и анализировать сложные данные с беспрецедентной эффективностью. В области решения проблем это может привести к созданию систем, способных не только находить оптимальные решения, но и объяснять ход своих рассуждений. Наконец, в сфере искусственного интеллекта данный подход является важным шагом на пути к созданию действительно разумных систем, способных к гибкому мышлению и адаптации к новым задачам, что в конечном итоге может привести к качественно новому уровню автоматизации и интеллектуальных возможностей.
Представленная работа демонстрирует элегантный подход к сжатию логических цепочек рассуждений, переводя их из текстового формата в визуальное представление. Это напоминает эволюцию инфраструктуры города: вместо перестройки целого квартала для исправления небольшой проблемы, предлагается более гибкое и эффективное решение. Как отмечает Ада Лавлейс: «То, что аналитическая машина может делать, есть лишь то, что мы знаем, как ей приказать делать». Именно это и демонстрирует Render-of-Thought — преобразование сложной логики в визуально сжатый формат, делая процесс рассуждений более понятным и анализируемым, подобно оптимизации городской инфраструктуры для обеспечения более плавного функционирования всей системы.
Что дальше?
Представленная работа, безусловно, демонстрирует элегантность сжатия рассуждений, переводя их из многословных текстовых цепочек в более компактное визуальное представление. Однако, возникает вопрос: не является ли это лишь перекладыванием сложности с одной системы — языка — на другую, визуальную? Визуальное пространство, столь привлекательное своей интуитивностью, требует не менее тщательного структурирования, чтобы избежать потери информации и внести ясность, а не дополнительный шум. Каждая новая зависимость от визуального кодирования — это скрытая цена свободы от лингвистической многозначности.
Перспективы очевидны: углубленное исследование взаимосвязи между структурой визуального представления и качеством рассуждений. Необходимо исследовать, как различные визуальные метафоры и организационные принципы влияют на способность системы к обобщению и решению новых задач. Особый интерес представляет вопрос о возможности «декомпиляции» визуального представления обратно в текстовое, сохраняя при этом всю полноту исходных рассуждений — это будет истинным доказательством эффективности сжатия.
В конечном итоге, успешность подхода «Render-of-Thought» будет определяться не столько достигнутыми показателями производительности, сколько способностью системы к адаптации и самоорганизации. Хорошая система — живой организм; нельзя чинить одну часть, не понимая целого. Важно помнить, что структура определяет поведение, и именно эта структура должна быть прозрачной и понятной, чтобы обеспечить надежность и предсказуемость рассуждений.
Оригинал статьи: https://arxiv.org/pdf/2601.14750.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-22 17:46