Автор: Денис Аветисян
Новое исследование представляет комплексный подход к отслеживанию и анализу динамично развивающейся области искусственного интеллекта, выявляя ключевые тенденции и перспективные направления.
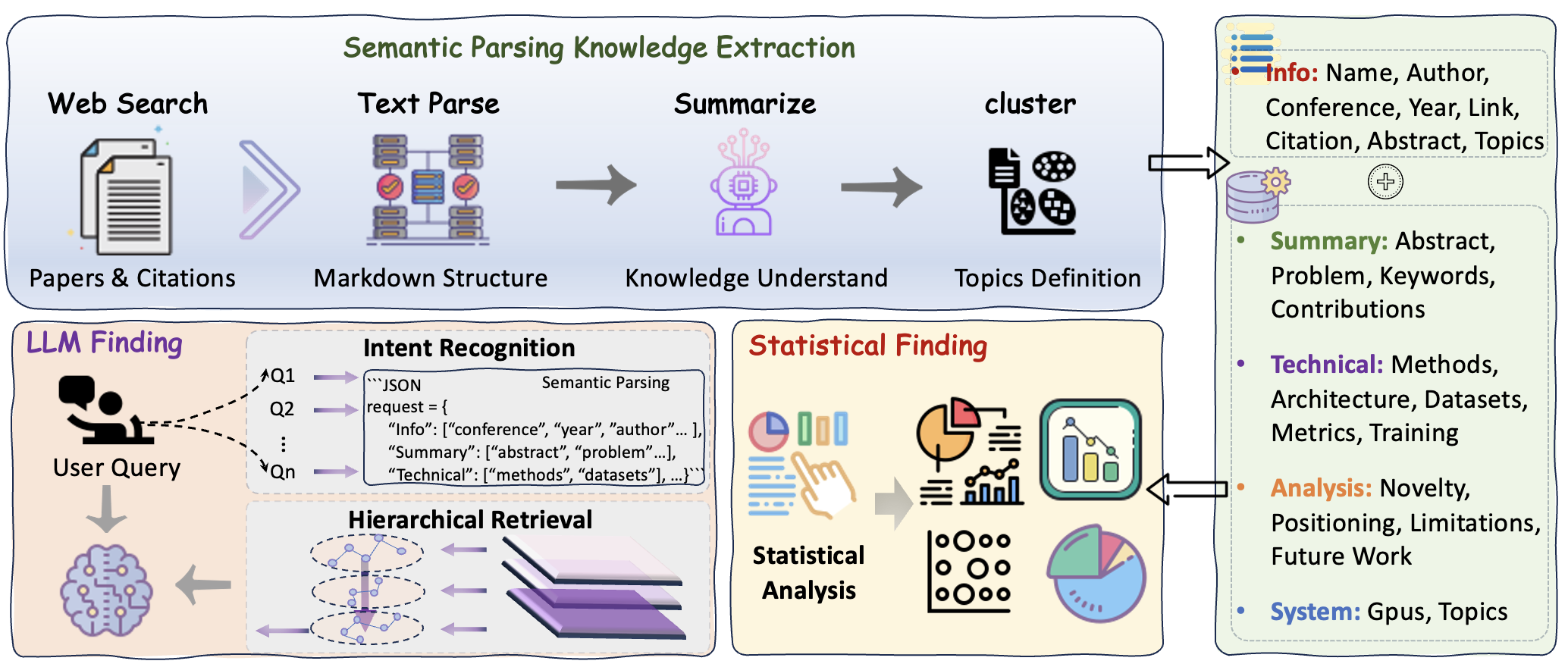
Предложен фреймворк для многомерного профилирования знаний на основе масштабного анализа данных, семантической обработки и иерархического поиска.
Экспоненциальный рост научных публикаций в области машинного обучения и искусственного интеллекта затрудняет синтез и понимание ключевых тенденций. В работе ‘Large-Scale Multidimensional Knowledge Profiling of Scientific Literature’ предложен комплексный подход к анализу более 100 000 научных статей из 22 ведущих конференций за период с 2020 по 2025 год, позволяющий выявить эволюцию тематик и взаимосвязи между различными областями исследований. Используя комбинацию тематического моделирования, LLM-анализа и структурированного поиска, авторы демонстрируют значительные изменения, включая рост интереса к безопасности, мультимодальному обучению и агент-ориентированным системам. Каким образом полученные данные могут способствовать более эффективному планированию научных исследований и выявлению перспективных направлений развития искусственного интеллекта?
Искусственный интеллект: Захлебываясь в море информации
Исследования в области искусственного интеллекта переживают экспоненциальный рост, что приводит к лавинообразному увеличению объема информации и затрудняет формирование целостного понимания текущего состояния дел. Этот стремительный прогресс создает ситуацию, когда даже специалистам становится сложно отслеживать все новые разработки и выявлять ключевые тенденции. Обилие публикаций, конференций и препринтов, охватывающих широкий спектр подходов и направлений, формирует информационную перегрузку, препятствующую как глубокому анализу, так и эффективному применению полученных знаний. В результате, несмотря на впечатляющие достижения, потенциал искусственного интеллекта реализуется не в полной мере из-за трудностей с систематизацией и осмыслением постоянно расширяющегося массива данных.
Традиционные методы обзора литературы, включающие ручной поиск и анализ научных публикаций, всё чаще оказываются неспособны эффективно охватить стремительно растущий объём исследований в области искусственного интеллекта. Этот экспоненциальный рост приводит к фрагментации знаний, когда исследователям становится сложно увидеть общую картину и установить связи между отдельными работами. В результате, ценные инсайты могут оставаться незамеченными, а дублирование усилий — распространенным явлением. Подобная ситуация не только замедляет прогресс в области, но и препятствует формированию целостного понимания текущих тенденций и перспективных направлений исследований. Вместо систематизированного анализа, специалисты сталкиваются с необходимостью обрабатывать огромные массивы информации, что требует значительных временных затрат и не гарантирует полноту охвата.
В связи с экспоненциальным ростом исследований в области искусственного интеллекта возникла потребность в масштабируемых, автоматизированных методах синтеза знаний. Анализ огромного объема публикаций традиционными способами становится невозможным, что приводит к фрагментации информации и упущенным взаимосвязям. Представленная работа направлена на решение этой проблемы посредством разработки специализированного фреймворка, который обработал и проанализировал более 100 000 научных статей, представленных на 22 ведущих конференциях по искусственному интеллекту в период с 2020 по 2025 год. Данный подход позволяет выявлять ключевые тенденции, закономерности и пробелы в исследованиях, предоставляя исследователям и специалистам актуальный и всесторонний обзор состояния дел в области ИИ.
Для эффективного анализа стремительно растущего объема исследований в области искусственного интеллекта необходима структурированная организация знаний и методы их извлечения. Поскольку количество публикаций экспоненциально увеличивается, традиционные подходы к обзору литературы становятся неэффективными и приводят к фрагментации информации. В связи с этим, разработка систематизированных систем категоризации и поиска, позволяющих быстро идентифицировать ключевые тенденции, взаимосвязи и пробелы в исследованиях, является критически важной задачей. Такой подход способствует более глубокому пониманию текущего состояния области, ускоряет инновации и позволяет исследователям избежать дублирования усилий, фокусируясь на перспективных направлениях развития.
База знаний «ResearchDB»: Организуя хаос исследований
В основе нашего подхода лежит база данных ‘ResearchDB’ — структурированная система, предназначенная для организации и представления информации об исследованиях в области искусственного интеллекта. База данных спроектирована с использованием реляционной модели данных, что обеспечивает эффективное хранение и извлечение информации о публикациях, авторах, ключевых понятиях и взаимосвязях между ними. ‘ResearchDB’ включает в себя метаданные о каждой публикации, такие как название, авторы, год публикации, абстракт и полный текст, а также структурированные данные, полученные в результате контент-майнинга, включая извлеченные концепции и их связи. Данная структура позволяет осуществлять сложные запросы и анализировать тенденции в исследованиях ИИ, а также обеспечивает масштабируемость и возможность интеграции с другими системами обработки информации.
Для извлечения ключевых концепций и взаимосвязей из научных публикаций мы применяем методы контент-майнинга, включающие в себя автоматизированный анализ текста, выделение именованных сущностей (например, алгоритмов, наборов данных, метрик), и определение семантических отношений между ними. Этот процесс опирается на комбинацию методов обработки естественного языка (NLP), включая частичную разметку речи, разрешение кореференции и извлечение отношений. Полученные данные структурируются и сохраняются в базе знаний, что позволяет проводить дальнейший анализ и синтез информации, а также выявлять тренды и пробелы в исследованиях.
Многомерное профилирование знаний, основанное на извлеченных данных, позволяет классифицировать и анализировать исследовательские темы путем представления их в виде структурированных профилей. Каждый профиль включает в себя ключевые концепции, связи между ними и их релевантность в контексте определенной исследовательской области. Извлеченная информация используется для создания векторных представлений тем, что позволяет сравнивать и ранжировать их по различным критериям, таким как новизна, влияние и актуальность. Это обеспечивает возможность автоматизированного анализа трендов, выявления пробелов в исследованиях и формирования целостной картины развития конкретной научной области.
В рамках предложенной системы, иерархический поиск (Hierarchical Retrieval) и кластеризация текста (Text Clustering) используются для оптимизации процесса обнаружения и синтеза знаний. Иерархический поиск позволяет последовательно сужать область поиска, начиная с общих категорий и переходя к более специфичным подтемам, что значительно повышает эффективность извлечения релевантной информации. Кластеризация текста, в свою очередь, автоматически группирует документы и концепции на основе семантической близости, выявляя скрытые связи и закономерности. Комбинация этих двух методов обеспечивает не только быстрый доступ к нужным данным, но и возможность формирования целостной картины исследуемой области знаний, что особенно важно для анализа больших объемов научной литературы.
Большие языковые модели на службе науки: Семантическое понимание исследований
Для преобразования естественно-языковых аннотаций к научным статьям в формальное, машиночитаемое представление используются большие языковые модели (LLM) и семантический парсинг. Процесс включает в себя анализ текста LLM, таким как Deepseek-R1-32B или ChatGPT-5, для выявления ключевых элементов и их взаимосвязей. Семантический парсинг затем структурирует эту информацию в формальный формат, например, в виде триплетов “субъект-предикат-объект”, или в виде графа знаний, что позволяет автоматизировать анализ и категоризацию научных исследований, а также облегчает дальнейшую обработку данных машиной.
Модели, такие как Deepseek-R1-32B и ChatGPT-5, играют ключевую роль в извлечении значимой информации и установлении взаимосвязей в сложных текстовых данных. Эти большие языковые модели (LLM) используют архитектуры глубокого обучения для анализа семантической структуры текста, выявления ключевых сущностей, отношений между ними и последующего представления этих данных в структурированном формате. Способность моделей к пониманию контекста и многослойному анализу позволяет эффективно обрабатывать научные абстракты, выявлять основные аргументы, методы исследования и полученные результаты, что существенно превосходит возможности традиционных методов обработки естественного языка.
Использование технологии ‘Retrieval-Augmented Generation’ (RAG) значительно повышает точность и релевантность генерируемых резюме и аналитических отчетов. RAG предполагает поиск наиболее подходящей информации из внешних источников знаний на основе входного запроса, а затем использование этой информации для дополнения и уточнения ответа, генерируемого языковой моделью. В результате, генерируемые тексты становятся более обоснованными, содержат актуальные данные и лучше отражают контекст исследуемой темы, снижая вероятность галлюцинаций и неточностей, характерных для автономно работающих больших языковых моделей.
Автоматизированный анализ научных абстрактов с использованием больших языковых моделей позволяет выявлять зарождающиеся тенденции в исследованиях с повышенной точностью. Процесс категоризации тем исследований, основанный на семантическом анализе, обеспечивает более структурированный и последовательный подход к организации информации. Кроме того, стандартизация анализа, обеспечиваемая моделью, существенно повышает согласованность оценок, предоставляемых экспертами-людьми, что важно для обеспечения надежности и воспроизводимости результатов анализа и оценки.

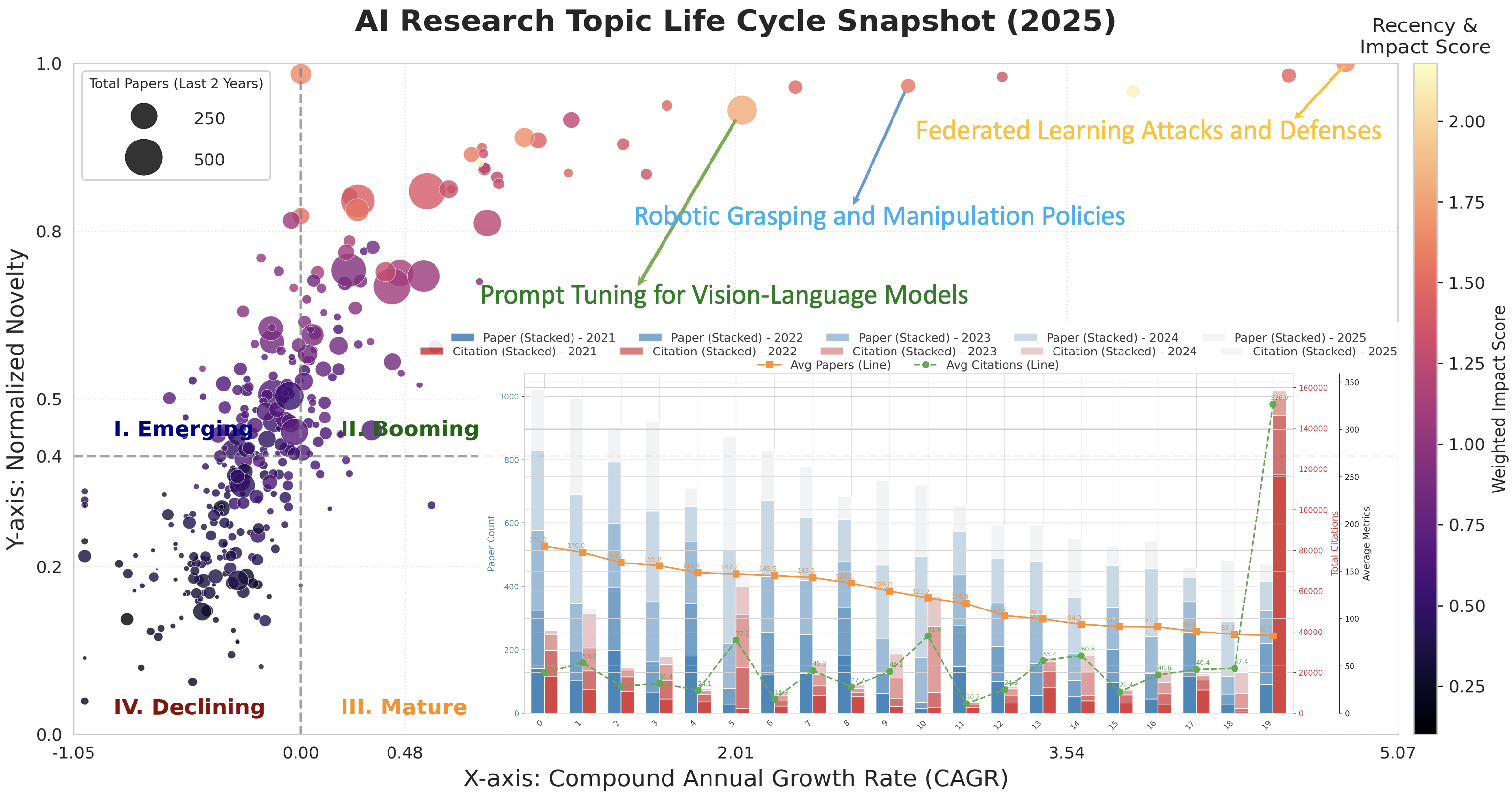
Жизненный цикл научных тем: От зарождения до угасания
Предлагаемая методика позволяет отслеживать жизненный цикл научных тем в области искусственного интеллекта, начиная с момента их появления и заканчивая стадией зрелости и последующего угасания. Этот подход позволяет увидеть, как новые направления исследований возникают из существующих, как они развиваются и конкурируют друг с другом, и когда их актуальность начинает снижаться. Выделение стадий жизненного цикла темы дает возможность оценить динамику развития всей области, прогнозировать будущие тренды и эффективно распределять ресурсы для поддержки наиболее перспективных направлений. Анализ показывает, что некоторые темы быстро достигают зрелости и выходят из употребления, в то время как другие демонстрируют устойчивый интерес и продолжают развиваться на протяжении многих лет, что подтверждает необходимость постоянного мониторинга и адаптации стратегий исследований.
Для анализа взаимосвязей между различными направлениями исследований в области искусственного интеллекта применяются алгоритмы HDBSCAN и UMAP. HDBSCAN, будучи алгоритмом плотностной кластеризации, позволяет выявлять группы связанных тем, не требуя предварительного задания количества кластеров, что особенно важно при изучении динамично развивающихся областей знаний. В свою очередь, UMAP (Uniform Manifold Approximation and Projection) служит для снижения размерности данных и визуализации этих кластеров в двух- или трехмерном пространстве. Благодаря этому подходу становится возможным наглядно представить структуру исследовательского поля, определить ключевые тренды и выявить перспективные области для дальнейших исследований, отображая сложные взаимосвязи в доступной для анализа форме.
Анализ жизненного цикла исследовательских тем в области искусственного интеллекта выявил тесную взаимосвязь между различными направлениями научных изысканий. Исследование продемонстрировало, что инновации редко возникают в изоляции, а чаще всего являются результатом конвергенции идей из смежных областей. В частности, выявленные связи позволяют определить перспективные пути для дальнейших исследований, где синергия между дисциплинами может привести к прорывным открытиям. Наблюдается тенденция к интеграции методов, ранее считавшихся относящимися к разным сферам, что открывает возможности для создания более эффективных и комплексных решений. Такой подход позволяет не только углубить понимание существующих проблем, но и выявить новые, ранее скрытые возможности для инноваций.
Анализ динамики развития исследований в области искусственного интеллекта позволяет выявлять существующие пробелы и рационально распределять инвестиции. Наблюдается устойчивый тренд к увеличению доли работ, посвященных созданию эталонных наборов данных и метрик оценки — с 10,07% в 2022 году до 18,16% в 2025 году. Этот рост указывает на возрастающую потребность в стандартизированных инструментах для объективной оценки новых алгоритмов и моделей, а также на стремление к повышению воспроизводимости результатов исследований. Подобная тенденция подчеркивает важность инвестиций в создание качественных бенчмарков и открытых наборов данных для ускорения прогресса в данной области.
Автоматизация обзора литературы: Взгляд в будущее
Представленный в работе фреймворк служит основой для создания автоматизированных конвейеров генерации обзоров литературы, таких как ‘AutoSurvey’, ‘SurveyX’, ‘SurveyForge’ и ‘SurveyG’. Эти системы используют подход Retrieval-Augmented Generation (RAG) для эффективного синтеза информации из базы данных научных работ ‘ResearchDB’, позволяя создавать всесторонние и структурированные обзоры. Разработанная архитектура обеспечивает модульность и расширяемость, что делает её применимой к различным предметным областям и позволяет адаптировать её к конкретным потребностям исследователей, значительно упрощая процесс анализа большого объема научной информации.
Представленные конвейеры автоматизированного обзора литературы используют подход Retrieval-Augmented Generation (RAG) для эффективного синтеза информации из базы данных научных исследований ‘ResearchDB’. Суть метода заключается в извлечении релевантных фрагментов текста из базы данных, которые затем используются для формирования связных и всесторонних сводок. Благодаря этому, сложные научные работы анализируются и обобщаются значительно быстрее, чем при традиционных методах, позволяя исследователям концентрироваться на более творческих аспектах работы.
Автоматизация процесса составления обзоров литературы значительно снижает временные и трудовые затраты исследователей. Благодаря этому, специалисты получают возможность переключиться с рутинной работы по сбору и систематизации информации на более творческие и стратегически важные задачи — формулирование новых гипотез, анализ полученных данных и разработку инновационных подходов к решению научных проблем. Освобождение от необходимости вручную просматривать десятки или сотни статей позволяет более эффективно использовать время и ресурсы, что, в свою очередь, способствует ускорению научного прогресса и повышению качества исследований.
Дальнейшие исследования направлены на усовершенствование существующих конвейеров автоматизированного обзора литературы и расширение их функциональных возможностей для решения более широкого спектра исследовательских задач. Особое внимание уделяется повышению точности и связности генерируемых резюме, а также адаптации систем к различным предметным областям и типам научных публикаций. Планируется разработка алгоритмов, способных учитывать контекст исследования, выявлять ключевые аргументы и противоречия в литературе, и представлять информацию в структурированном и понятном виде. Кроме того, ведется работа над интеграцией с другими научными инструментами и базами данных, что позволит автоматизировать процесс поиска релевантной литературы и повысить эффективность обзора.
Исследование, представленное в статье, демонстрирует амбициозную попытку систематизировать хаос современной AI-литературы. Авторы стремятся выявить не только текущие тренды, но и предсказать будущие направления развития, используя сложные методы семантического анализа и моделирования тем. Однако, как справедливо заметил Дэвид Марр: «Любая система, которую можно описать, вероятно, уже устарела». Эта фраза особенно актуальна в контексте стремительно меняющейся области искусственного интеллекта, где новые открытия и подходы возникают практически ежедневно. Использование больших языковых моделей для профилирования знаний — это, безусловно, прогрессивный шаг, но необходимо помнить, что даже самые передовые инструменты имеют ограниченный срок годности, особенно когда речь идет о попытке зафиксировать динамичную картину научно-исследовательского процесса.
Куда Поведёт Нас Этот Цирк?
Представленный подход к профилированию знаний в области ИИ, безусловно, позволит более детально отслеживать изменения в научной литературе. Однако, не стоит забывать, что каждая элегантная иерархия рано или поздно превратится в запутанный клубок из-за нежелания авторов следовать установленным классификациям. Сейчас это назовут «естественной эволюцией семантики» и получат финансирование. Вполне вероятно, что через пару лет система начнёт выдавать противоречивые результаты, а отладка превратится в поиск иголки в стоге данных. Документация, разумеется, уже соврала.
Очевидной проблемой остаётся субъективность оценки «значимости» того или иного направления. Автоматически выявляемые тренды могут оказаться лишь отражением модных веяний, а не реальным прогрессом. Начинаю подозревать, что они просто повторяют модные слова. Будет интересно посмотреть, как система справится с ситуацией, когда «прорывные» исследования впоследствии окажутся методологической ошибкой или, что вероятнее, банальной фальсификацией.
В конечном итоге, технический долг — это просто эмоциональный долг с коммитами. Каждая попытка автоматизировать анализ научного знания неизбежно столкнётся с человеческим фактором — желанием упростить, обобщить или просто проигнорировать сложные нюансы. И рано или поздно, эта система, как и все остальные, превратится в сложный bash-скрипт, который никто не понимает, но боится трогать.
Оригинал статьи: https://arxiv.org/pdf/2601.15170.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Облачные вычисления для науки: гибкость и масштабируемость
2026-01-22 17:49