Автор: Денис Аветисян
В статье рассматривается возможность автоматизации процесса исследований в области искусственного интеллекта путем создания системы, способной самостоятельно генерировать и проверять новые идеи.
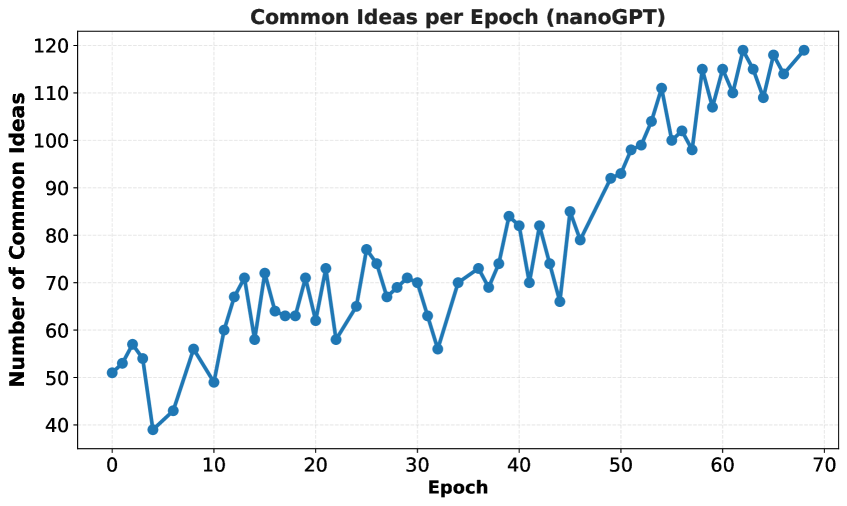
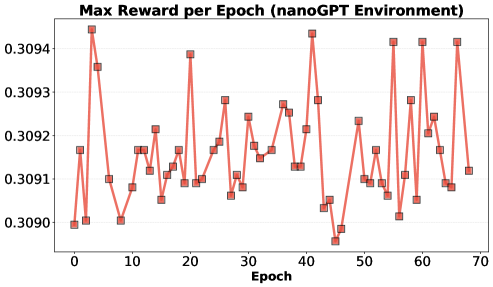
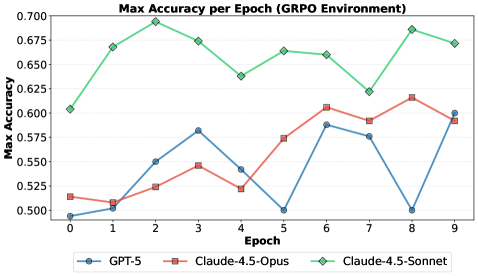
Исследование демонстрирует потенциал эволюционных алгоритмов в автоматизированном поиске, но выявляет проблемы с использованием обучения с подкреплением из-за коллапса разнообразия.
Автоматизация научных исследований в области искусственного интеллекта сталкивается с парадоксом: генерация правдоподобных идей большими языковыми моделями (LLM) не гарантирует их практическую эффективность. В работе ‘Towards Execution-Grounded Automated AI Research’ предложен подход, основанный на автоматизированном выполнении и оценке сгенерированных LLM гипотез, с целью преодоления этого ограничения. Показано, что эволюционный поиск, управляемый результатами выполнения экспериментов, позволяет добиться значительного улучшения производительности в задачах предварительного и постобучения LLM. Какие новые стратегии обучения и архитектуры автоматизированных исполнителей позволят в полной мере реализовать потенциал автоматизированных исследований в области ИИ?
Иллюзии и Реальность: Большие Языковые Модели в XXI Веке
Современные большие языковые модели представляют собой качественно новый этап в развитии искусственного интеллекта, демонстрируя беспрецедентные возможности в области генерации и понимания текста. Эти системы, обученные на колоссальных объемах данных, способны создавать связные и логичные тексты различных жанров — от научных статей и поэзии до компьютерного кода и сценариев. Они демонстрируют способность не просто имитировать человеческую речь, но и адаптироваться к различным стилям, тонам и контекстам, что открывает широкие перспективы для автоматизации контент-создания, улучшения качества машинного перевода и создания более естественных интерфейсов взаимодействия человека и компьютера. Несмотря на существующие ограничения, наблюдаемый прогресс свидетельствует о значительном скачке в развитии систем обработки естественного языка и их потенциале для решения широкого круга задач.
Несмотря на впечатляющие возможности, современные большие языковые модели демонстрируют существенные недостатки. В частности, они склонны к «галлюцинациям» — генерации информации, не основанной на фактах и не имеющей под собой реального основания. Более того, модели зачастую усиливают существующие в обществе предрассудки и стереотипы, воспроизводя их в генерируемых текстах. Это происходит из-за того, что обучение моделей происходит на огромных объемах данных, содержащих исторически сложившиеся, а порой и несправедливые представления о мире. Таким образом, без тщательного контроля и корректировки, эти инструменты могут непреднамеренно увековечивать и распространять дискриминацию, создавая серьезные этические и социальные проблемы.
Одной из ключевых проблем в развитии больших языковых моделей является обеспечение их соответствия человеческим ценностям и намерениям, задача, получившая название “выравнивание”. Суть проблемы заключается в том, что модели обучаются на огромных массивах данных, которые могут содержать предвзятости, стереотипы и даже откровенно вредоносную информацию. Вследствие этого, модель может генерировать текст, который, хотя и грамматически верен, является морально неприемлемым, дискриминационным или просто не соответствующим ожиданиям человека. Разработка эффективных методов “выравнивания” требует не только технических решений, таких как улучшение алгоритмов обучения и фильтрации данных, но и глубокого понимания этических принципов и социальных норм, а также постоянного мониторинга и корректировки поведения моделей.
Укрощение Хаоса: Методы Настройки Поведения Моделей
Метод обучения, известный как “тонкая настройка по инструкциям” (instruction tuning), является одним из первых подходов к согласованию поведения языковых моделей с человеческими предпочтениями. Он заключается в дополнительном обучении предварительно обученной модели на наборе данных, состоящем из пар “инструкция — ожидаемый ответ”. Процесс предполагает предоставление модели четких и конкретных инструкций, а затем корректировку её параметров для генерации ответов, максимально соответствующих этим инструкциям. Эффективность этого метода зависит от качества и разнообразия обучающего набора данных, а также от точности сформулированных инструкций. Использование instruction tuning позволяет существенно улучшить способность модели следовать указаниям пользователя и предоставлять более релевантные и полезные ответы.
Обучение с подкреплением на основе обратной связи от человека (Reinforcement Learning from Human Feedback, RLHF) предполагает поощрение желаемого поведения модели посредством системы вознаграждений. Ключевым компонентом данного подхода является моделирование вознаграждений (reward modeling), которое заключается в обучении отдельной модели, способной оценивать качество ответов, сгенерированных основной моделью, и выдавать числовое значение, соответствующее степени соответствия ответа человеческим предпочтениям. Эта оценка затем используется в качестве сигнала вознаграждения для обучения основной модели с использованием алгоритмов обучения с подкреплением, что позволяет ей оптимизировать свои ответы для достижения более высоких оценок и, следовательно, большей согласованности с человеческими ожиданиями.
Методы прямой оптимизации предпочтений (Direct Preference Optimization, DPO) представляют собой альтернативный подход к обучению больших языковых моделей, обходящий этап моделирования вознаграждений (reward modeling). Вместо обучения отдельной модели для оценки качества ответов, DPO напрямую оптимизирует политику модели, используя данные о предпочтениях пользователей. Это достигается путем максимизации вероятности выбора предпочтительного ответа над менее предпочтительным, что позволяет упростить процесс обучения и снизить вычислительные затраты. В отличие от обучения с подкреплением на основе обратной связи от человека (Reinforcement Learning from Human Feedback, RLHF), DPO использует более стабильный и эффективный алгоритм обучения, основанный на классической задаче классификации.
Конституционный ИИ (Constitutional AI) представляет собой подход к управлению поведением моделей, основанный на задании набора заранее определенных принципов, служащих основой для генерации ответов. В отличие от обучения с подкреплением на основе обратной связи от человека (RLHF), данный метод не требует явной оценки человеком качества ответов. Модель обучается самокритике и самосовершенствованию, оценивая собственные ответы на соответствие заданным принципам и корректируя их в соответствии с ними. Этот процесс позволяет снизить зависимость от субъективных оценок и повысить согласованность поведения модели с заранее определенными этическими и функциональными требованиями.
Проверка на Прочность: Идентификация и Смягчение Рисков
Несмотря на предпринимаемые усилия по согласованию (alignment) моделей искусственного интеллекта с человеческими ценностями, сохраняется вероятность возникновения уязвимостей и нежелательных последствий. В связи с этим, критически важным становится применение методов «red teaming» — активного поиска и эксплуатации потенциальных недостатков системы. Данный подход предполагает имитацию атак со стороны злоумышленников для выявления слабых мест и разработки мер по их устранению до развертывания модели, что позволяет снизить риски возникновения вредоносных или непредсказуемых результатов.
Существенная проблема современных моделей машинного обучения заключается в их низкой интерпретируемости. Отсутствие прозрачности в процессах принятия решений затрудняет понимание причин, лежащих в основе генерируемых результатов. Это не позволяет точно определить, какие факторы влияют на выходные данные, что создает риски в критически важных приложениях, где необходима возможность отслеживания и объяснения логики работы модели. Невозможность «заглянуть внутрь» модели также препятствует эффективной отладке и улучшению ее производительности, поскольку сложно выявить и устранить источники ошибок или предвзятости.
Эффективность рассматриваемых моделей тесно связана с закономерностями масштабирования, демонстрируя сложную зависимость между размером модели, объемом обучающих данных и её возможностями. В ходе валидации на постобученной задаче, система достигла точности в 69.4%, что на 21.4 процентных пункта превышает показатели базовой модели. Данный результат подтверждает, что увеличение масштаба модели и данных приводит к существенному улучшению производительности, однако требует внимательного анализа взаимосвязи между этими факторами для оптимизации ресурсов и избежания неэффективного масштабирования.
Взгляд в Будущее: Ответственная Разработка ИИ
Появление открытых языковых моделей (LLM) знаменует собой важный сдвиг в области искусственного интеллекта, предоставляя беспрецедентный доступ к передовым технологиям широкому кругу разработчиков и исследователей. Этот демократизированный подход способствует инновациям и позволяет создавать новые приложения, ранее недоступные из-за ограничений, связанных с проприетарными системами. Однако, расширение доступа к LLM сопряжено с необходимостью разработки и внедрения строгих протоколов безопасности. Открытый исходный код, хотя и способствует прозрачности, также требует повышенного внимания к потенциальным рискам, таким как предвзятость, дезинформация и злоупотребления. Поэтому, параллельно с развитием открытых моделей, критически важно инвестировать в инструменты и методы, обеспечивающие их безопасное и ответственное использование, чтобы максимизировать пользу и минимизировать потенциальный вред.
Исследования в области техник согласования искусственного интеллекта с человеческими ценностями, в сочетании с надежными методологиями оценки, такими как «red teaming» — моделирование атак для выявления уязвимостей — приобретают первостепенное значение. Недавняя разработка продемонстрировала значительное ускорение процесса предварительного обучения: система показала результат в 19.7 минут, что на 16.2 минут быстрее, чем у базовой модели. Такое повышение эффективности не только снижает вычислительные затраты, но и открывает возможности для более оперативного итеративного улучшения алгоритмов, способствуя созданию более безопасных и надежных систем искусственного интеллекта. Данный прогресс подчеркивает важность непрерывных исследований и разработки новых подходов к обучению и оценке моделей, гарантирующих их соответствие этическим нормам и ожиданиям общества.
Понимание принципов работы искусственного интеллекта, или интерпретируемость, становится ключевым фактором для широкого и безопасного внедрения подобных систем. Без возможности проследить логику принятия решений, сложно обеспечить надежность и предсказуемость работы ИИ, что особенно критично в областях, связанных с безопасностью и благополучием человека. Исследования в этой области направлены на разработку методов, позволяющих «заглянуть» внутрь нейронных сетей и понять, какие факторы влияют на тот или иной результат. Достижения в области интерпретируемости не только повышают доверие к ИИ, но и позволяют выявлять и устранять потенциальные ошибки и предвзятости, обеспечивая более справедливое и ответственное использование технологий искусственного интеллекта.
Наблюдатель, повидавший немало архитектур, отмечает, что автоматизация исследований, описанная в статье, неизбежно сталкивается с проблемой коллапса разнообразия. Авторы верно подмечают трудности с Reinforcement Learning, но это лишь закономерность. Всё это уже было — попытки создать самообучающиеся системы, которые быстро приходили к локальным оптимумам. Как говорил Давид Гильберт: «В математике нет знаков препинания, только доказательства». И в автоматизации исследований, как и в математике, рано или поздно «зелёные тесты» начинают означать лишь то, что система научилась избегать сложных случаев, а не решать проблему. Эволюционный поиск, описанный в статье, кажется более жизнеспособным, но и он, вероятно, потребует постоянной «ручной» корректировки, чтобы избежать застревания в узком диапазоне решений.
Куда это всё катится?
Представленные исследования, как и следовало ожидать, лишь аккуратно обозначили горизонт новых проблем. Автоматизация генерации и проверки гипотез, пусть и демонстрирующая потенциал эволюционных алгоритмов, неизбежно упирается в вопрос о разнообразии. Если идея «сломалась» — значит, у нас стабильная система, но когда все идеи сходятся к одному, тривиальному решению, это уже не так весело. Обещания самовосстановления в системах искусственного интеллекта — это всегда признание того, что что-то ещё не сломалось по-настоящему.
Очевидно, что простого масштабирования существующего подхода недостаточно. Необходимы более изощрённые механизмы поддержания разнообразия, возможно, заимствованные из области генетического программирования или даже — что более иронично — из теории игр. И, конечно, документация. Документация — это форма коллективного самообмана, но без неё даже автоматизированный исследователь быстро забудет, зачем он вообще здесь.
В конечном счёте, автоматизация исследований — это не про создание «искусственного учёного», а про создание инструмента, который позволит людям быстрее и эффективнее натыкаться на новые ошибки. А ошибки, как известно, — это двигатель прогресса. И да, каждая «революционная» технология завтра станет техдолгом.
Оригинал статьи: https://arxiv.org/pdf/2601.14525.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Робот-исследователь: новый подход к автономной навигации
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
2026-01-22 19:35